前面給大家寫的關於結構方程模型的文章都是基於變量的方差協方差矩陣來探討變量間關系的,叫做covariance-based SEM,今天給大家介紹一下另外一個類型的SEM,叫做偏最小二乘結構方差模型。一般來講covariance-based SEM大家會用的更多,但是了解一下PLSSEM也挺好,所以本篇文章肯定依然值得您收藏。
它兩的區別在哪?
Whereas CBSEM estimates model parameters so that the discrepancy between the estimated and sample covariance matrices is minimized, in PLS path models the explained variance of the endogenous latent variables is maximized by estimating partial model relationships in an iterative sequence of ordinary least squares (OLS) regressions.
CBSEM是讓理論和數據吻合的原則來估計相應參數的,我們通過看模型的擬合優度可以知道我們設定的理論和收集來數據是不是吻合,從而判斷理論是不是符合實際,是不是站得住腳,是一種非常典型的驗證性思維;而PLSSEM則更強調解釋更多因變量(內生變量)的變異,所以如果你做研究的主要目的不是要驗證一個理論,就是說你對潛變量的測量和變量關系的理論結構已經有十足的把握,主要目的是探討哪些外生變量是因變量的影響因素,這個時候PLSSEM相對來講就更加適合。並且,PLS對數據分布沒有要求,所以相對於CBSEM來講它又被稱為軟結構方程模型。
PLSSEM本質上是通過循環迭代各個潛變量的權重的方法來估計模型參數的,它期望通過迭代達到解釋因變量變異最大。所以一個完整的PLSSEM包括3個部分,1.測量模型,2.結構模型,還有一個叫加權策略weighting scheme,加權策略是PLSSEM獨有的。
PLS path models consists of three components: the structural model, the measurement model and the weighting scheme.
與CBSEM不同,PLSSEM的測量模型又可以分為兩種,一種是reflective measurements,叫做反映型測量模型,另外一種叫做構成型測量模型formative measurements
A model with all arrows pointing outwards is called a Mode A model – all LVs have reflective measurements. A model with all arrows pointing inwards is called a Mode B model – all LVs have formative measurements. A model containing both, formative and reflective LVs is referred to as MIMIC or a mode C model.
大家看一眼下面的圖就可以明白兩種測量模型的區別了:
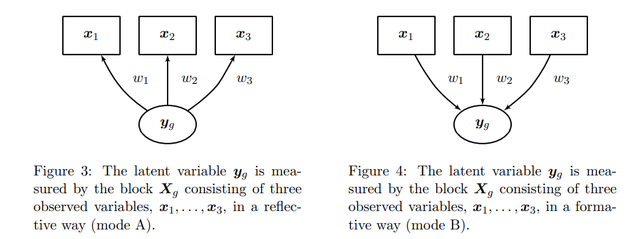
在反映型測量模型中,我們認為指標是潛變量導致的,潛變量通過指標反映出來;而在形成型測量模型中,我們認為是指標導致了潛變量,潛變量是由指標形成的:
Latent variables can be measured in two ways: • through their consequences or effects reflected on their indicators • through different indicators that are assumed to cause the latent variables
論文報告方法
今天我們看的論文是一篇已經公開發表的博士學位論文,作者是用SmartPLS軟件做出來,在原文的結果部分作者報告了潛變量唯一度檢驗的兩個特征根:

測量變量的信效度,具體指標有AVE,CR,α系數,communality:

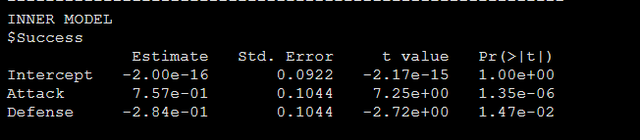
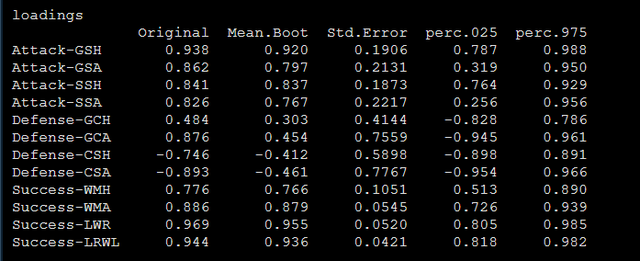
還有各個顯變量的載荷,還有bootstrap檢驗的結果,具體包括外部模型的檢驗和路徑系數的檢驗,檢驗既報告統計量也報告p值:


上面很多指標的具體意思是什么大家可以自行去查閱文獻,本文依然是重在實操,我現在要做的就是使用R語言和自己的數據對標上述報告內容,看看模型中需要報告的這些東西如何做出來。
實例操練
我現在有如下數據:
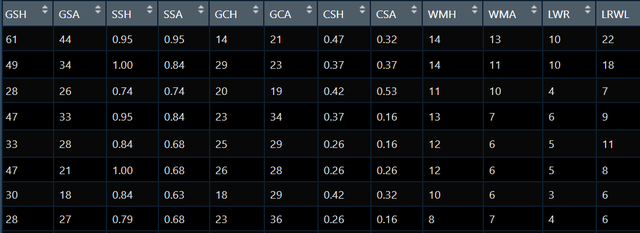
我自己想構建的理論模型如下圖:
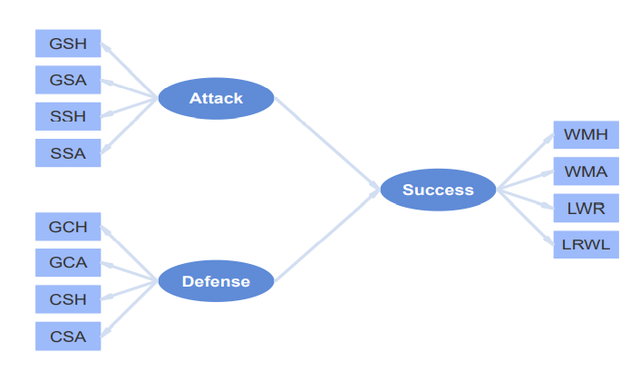
可以看到,上圖中有3個潛變量,所有潛變量的測量變量都在我的數據集中,測量模型都是反映型測量。
怎么做呢?我們需要首先加載plspm包,然后設定測量模型和結構模型
一、結構模型的設定
我們已經知道我們的結構模型是Attack和Defense都會影響Success,這個結構我們需要用矩陣表示出來:
Attack = c(0, 0, 0) Defense = c(0, 0, 0) Success = c(1, 1, 0) foot_path = rbind(Attack, Defense, Success)
形成如下矩陣:
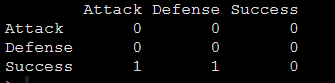
上圖矩陣中為1的地方則是有關系的表示,上圖的意思就是Attack和Defense都會影響Success。我們可以用innerplot()將我們的結構模型畫出來
innerplot(foot_path)
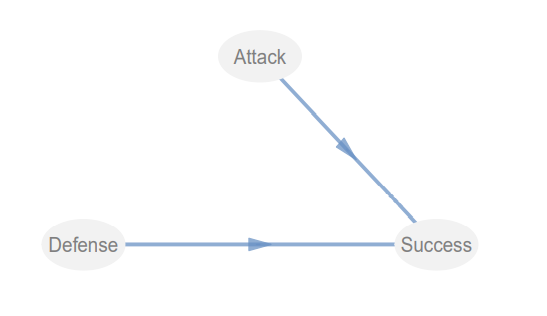
我們可以看到結構模型是沒有問題的,到這兒我們的結構模型就算做好了。
二、測量模型的設定
我們需要指定數據集中的列的變量和潛變量的對應關系,比如1到4列測量指標對應一個潛變量,5到8對應第二個,9到12對應第三個,那么我們就可以寫出代碼:
foot_blocks = list(1:4, 5:8, 9:12)
具體的順序和結構模型中設定的潛變量順序需要一致,也就是說1到4應該對應的Attack這個潛變量,5到8和9到12則對應Defense和Sucess這兩個潛變量。
我們還需要設定測量模型的類型,因為我們3個潛變量都是反映型的測量模型,我們全部設定為A就行,如果是形成型測量模型的就應該設定為B,函數運行時默認取A,所以本例中我們也可以選擇不設定直接默認就好。
結構模型和測量模型都設定好了我們就可以進行模型擬合了。
三、模型擬合
模型擬合需要用到的函數是plspm,大家可以去搜搜函數的說明:

可以看到,這個函數需要的主要參數為Data,就是我們的原始數據,還需要path_matrix,就是我們剛剛設定的結構模型的矩陣,還需要blocks,就是我們的潛變量對應的顯變量,scheme這個是結構模型的加權策略,策略有3種,我們也可以直接默認。
擬合模型的時候我們按照函數說明寫出如下代碼:
foot_pls = plspm(data, foot_path, foot_blocks) summary(foot_pls)
運行代碼后我們看輸出,首先是需要報告的唯一度檢驗的兩個特征根在圖1種:
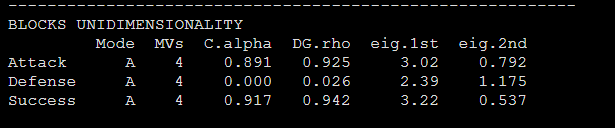
圖1
然后是測量變量的信效度,包括AVE,communality在下圖(圖2)中:

圖2
CR,α系數也在圖1中。
還有顯變量的載荷,以及路徑系數的檢驗結果如下圖:

還有載荷系數的bootstrap檢驗結果:
還有路徑系數的bootstrap檢驗結果:

到這兒,一篇博士學位論文中的PLSsem分析部分就算完成了,其實R的結果中還有R方,總效應和效應分解等等如下,也可以選擇性報告:
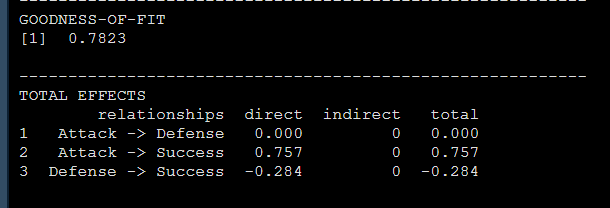
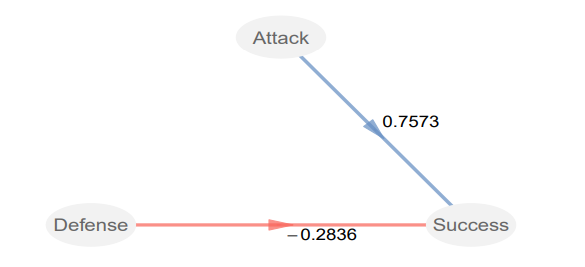
而且R還可以給我們的模型出圖,直接把模型對象喂給plot函數就行:
plot(foot_pls)
文章的最后再給大家分享一個模型圖,與大家共勉:
小結
今天給大家寫了PLS結構方程模型的做法和報告內容,希望對大家有所啟發,感謝大家耐心看完,自己的文章都寫的很細,重要代碼都在原文中,希望大家都可以自己做一做,請轉發本文到朋友圈后私信回復“數據鏈接”獲取所有數據和本人收集的學習資料。如果對您有用請先記得收藏,再點贊分享。
也歡迎大家的意見和建議,大家想了解什么統計方法都可以在文章下留言,說不定我看見了就會給你寫教程哦,有疑問歡迎私信。