今天給大家寫廣義混合效應模型Generalised Linear Random Intercept Model的第一部分 ,混合效應logistics回歸模型,這個和線性混合效應模型一樣也有好幾個叫法:
Mixed Effects Logistic Regression is sometimes also called Repeated Measures Logistic Regression, Multilevel Logistic Regression and Multilevel Binary Logistic Regression .
之后如果你遇到重復測量logistics回歸,多水平logistics回歸,你就應該知道他們都是指的是混合效應logistics回歸模型這一個東西。
模型介紹
重復測量和嵌套數據是科研中很常見的,此時需要考慮多水平模型來更好地分解變異,因變量是二分類變量的時候我們會用logistics回歸,多水平模型和logistics模型兩個一結合就是非常經典的廣義線性混合模型之一-----------多水平logistics回歸。
就是這么簡單。
為了更好地幫助大家理解,我們先回顧一下混合效應的一般寫法,以隨機截距為例子,當我們的因變量是連續的,此時我們可以做混合效應模型,比如我們的隨機截距混合效應模型就是如下,其中uj就叫做隨機截距(去翻翻之前的文章哈):
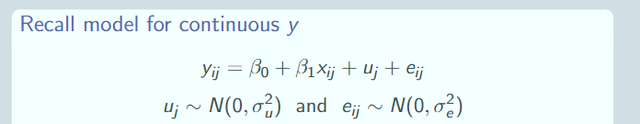
再擴展一下,當我們的因變量Y不是正態分布的時候,我們就有廣義線性隨機效應模型如下:
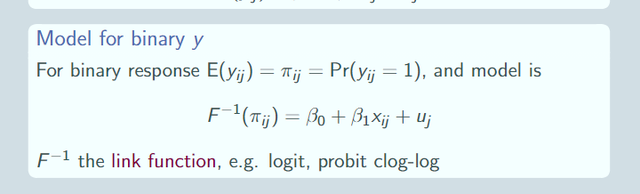
多了一個鏈接函數link funtion,其余都一樣的。這個鏈接函數可以是logit,可以是probit等等。
那么具體到因變量是二分類的時候我們就要用logit鏈接函數了。

此時我們的混合logistics模型的圖示如下:
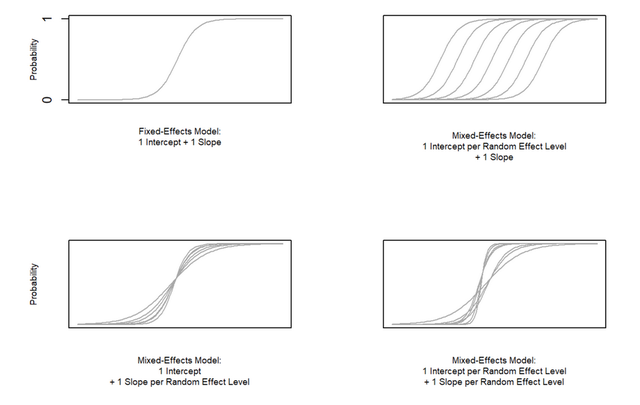
左上角就是大家都知道的logistics回歸模型,右上角是隨機截距logistics模型,左下角是隨機斜率logistics回歸模型,右下角就是既有隨機截距又有隨機斜率的logistics模型啦,和之前給大家寫的線性混合模型一模一樣的。
然后對於這么一個隨機截距模型,我們有固定效應部分的系數如下表:

其中β0就是截距,是x取0的時候y取1的log-odds(看不明白log-odds的同學去瞅瞅logistics機器學習的文章哈),β1是在控制了其余變量的情況下x每增長一個單位,log-odds的增長量;我們要報告的expβ1,這個就是odds ratio,就是論文中常見的風險相對於參考組增加多少多少倍的意思。
我們還有隨機效應部分的系數:

此部分就體現出來整個模型的變異分解,Uj就是組(嵌套的高水平)j對log-odds的作用,這就體現了嵌套數據的影響。這個uj也是服從正態分布的,標准差σ就是組水平上的效應擾動。
模型設定
在R語言中具體的隨機效應的設定,請大家參考下表(建議大家收藏起來,自己試試哈):
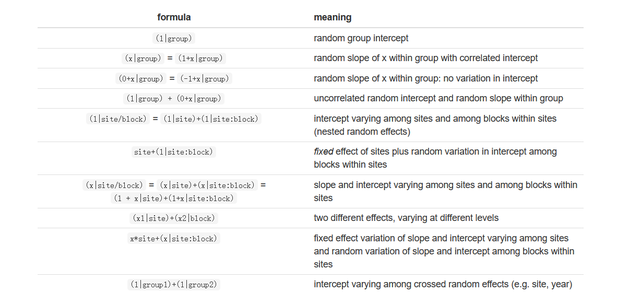

依然是給大家寫一個例子:
實例解析
首先還是先介紹一下手上的數據,一個醫院不同醫生接診的肺癌患者的數據庫,很明顯我們知道,病人是嵌套在醫生水平的,我現在感興趣病人病情恢復情況remission的相關因素,包括病人的特征和醫生的特征:
數據大概長這樣:
超級簡單的一個示例數據哈,其中DID是醫生編號,Experience是醫生的經驗,我現在簡單的認為,醫生經驗和病人病情都會對恢復結局產生影響,我就想跑跑回歸看看結果,考慮到數據的嵌套特性我得使用多水平模型,remission是一個二分類變量,於是我們得考慮用多水平的logistics模型。
擬合模型的代碼如下:
m_ri <- glmer(remission ~ CancerStage * Experience + (1 | DID), data = d, family = binomial, control = glmerControl(optimizer = "bobyqa"))我們用到的函數是glmer,這個是專門的廣義線性混合模型的擬合函數,其參數一般形式如下:
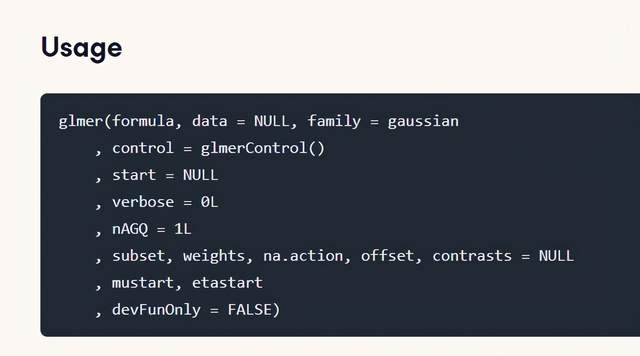
在使用該函數的時候,我需要在formula參數中設定模型的固定效應和隨機效應,family參數用來設定模型鏈接函數的分布族,control參數用來設定模型優化器,nAGQ越大模型擬合越慢同時也越精確。
運行我們剛剛的代碼輸出結果如下圖:
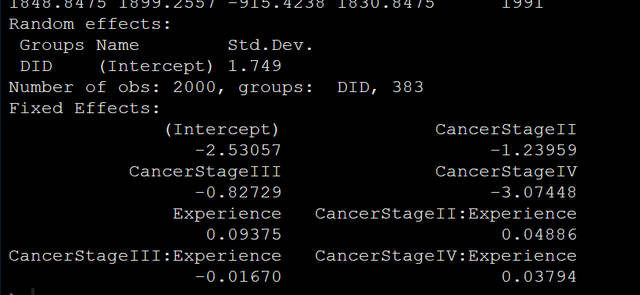
看固定效應的系數:Experience的系數是正的0.09,內在的意思就是提示我們看病的時候還是得去找老大夫。哈哈哈。
其實這個模型還是有交互項的,就是相同的病情在不同經驗的大夫手上結果會不會有差異,看圖:
plot_model(m_ri, type = "int")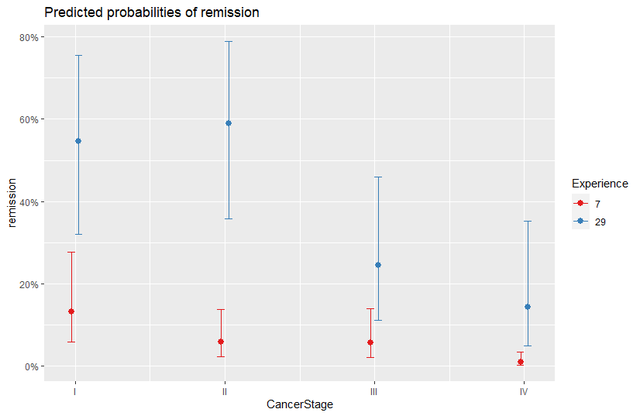
我們的分析結果再一次應證了得肺癌了應該去看經驗豐富的老大夫才好。
模型的輸出結果中是有擬合優度指標的:

比如有同學好奇,這個數據我就用普通的logistics回歸,它的結果和多水平logistics回歸到底差異有多大?
好的,我們來把兩個結果放一起看看:
m2 <- glm(remission ~ CancerStage * Experience, data = d, family = binomial)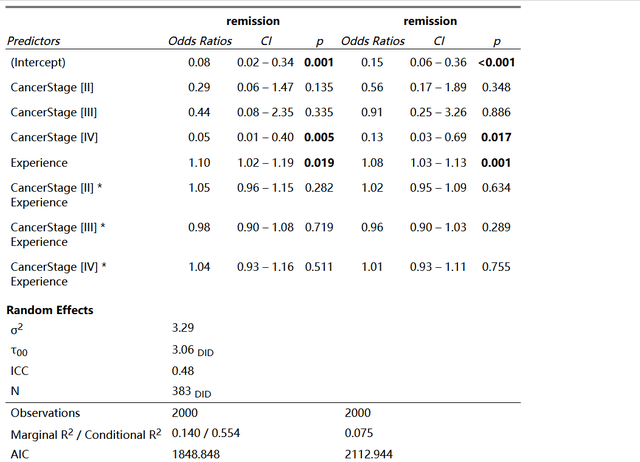
從輸出結果看,兩個模型對系數的結論似乎都是一致的,但是,一定注意R方,多水平模型的R方是普通logistics回歸的2倍,模型的AIC也小很多;ICC這個是看有沒有嵌套的指標,此例中icc達到了快0.5,也提示組內相關很大,我們有必要考慮數據的嵌套特性。
上面的優勢就導致多水平logistics回歸的系數估計一定是比普通回歸更為准確的。
當然,你還可以進行模型間的Likelihood ratio test似然比檢驗:
anova(m_ri, m2)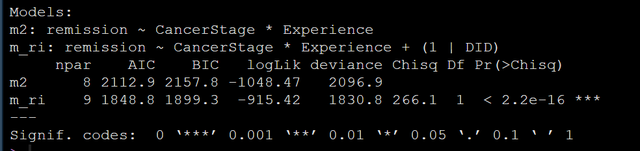
模型比較的結果也顯示多水平模型是顯著地優於普通logistics回歸模型的。
以上就是多水平logistics模型的做法。上面的例子中我只跑了隨機截距模型,大家可以用同樣的設定自己跑跑隨機斜率模型,然后進行模型比較,練練手。
小結
今天給大家寫了logistics多水平模型的做法,希望能給大家以啟發,感謝大家耐心看完,自己的文章都寫的很細,代碼都在原文中,希望大家都可以自己做一做,請轉發本文到朋友圈后私信回復“數據鏈接”獲取所有數據和本人收集的學習資料。如果對您有用請先收藏,再點贊分享。
也歡迎大家的意見和建議,大家想了解什么統計方法都可以在文章下留言,說不定我看見了就會給你寫教程哦,另歡迎私信。
如果你是一個大學本科生或研究生,如果你正在因為你的統計作業、數據分析、模型構建等發愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何問題,都可以聯系我。因為我可以給您提供最好的,最詳細和耐心的數據分析服務。
如果你對Z檢驗,t檢驗,方差分析,多元方差分析,回歸,卡方檢驗,相關,多水平模型,結構方程模型,中介調節,量表信效度等等統計技巧有任何問題,請私信我,獲取詳細和耐心的指導。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #Reports, #Composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...