閱讀本文需要有基礎的pytorch編程經驗,目標檢測框架相關知識,不用很深入,大致了解概念即可。
本章簡要介紹如何如何用C++實現一個目標檢測器模型,該模型具有訓練和預測的功能。本文的分割模型架構使用yolov4-tiny結構,代碼結構參考了bubbliiiing yolov4-tiny,本文分享的c++模型幾乎完美復現了pytorch的版本,且具有速度優勢,30-40%的速度提升。
模型簡介
簡單介紹一下yolov4-tiny模型。yolov4-tiny模型是YOLO(you only look once)系列模型中,version 4的輕巧版,相比於yolov4,它犧牲了部分精度以實現速度上的大幅提升。yolov4_tiny模型結構如圖(圖片來源自這):
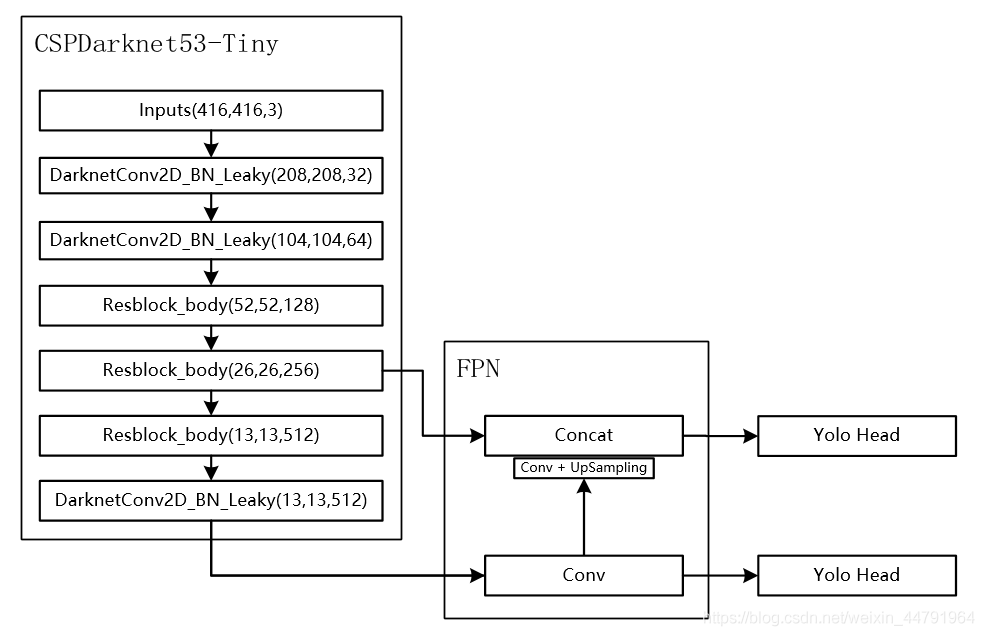
可以發現模型結構非常簡單,以CSPDarknet53-tiny為骨干網絡,FPN為頸部(neck),Yolo head為頭部。最后輸出兩個特征層,分別是原圖下采樣32倍和下采樣16倍的特征圖。訓練時,以這兩個特征圖分別輸入損失計算中計算損失,再將損失求和(或平均,怎么都好),后做反向傳播,預測時將兩個特征圖解碼出的結果做並集再做NMS(非極大值抑制)。
骨干網絡
CSPDarknet53-tiny是CSPNet的一種,CSPNet發表於CVPR2019,是用於提升目標檢測模型檢測性能的一種骨干網絡。感興趣的同學可以去看原文,簡單理解該論文貢獻,就是將特征層沿着通道維度切成兩片,兩片分別做不同的卷積,然后再拼接起來,這樣做相比於直接對原圖做特征提取,能減少計算量。
默認看過我的libtorch系列教程的前部分,直接上代碼。首先是基本單元,由Conv2d + BatchNorm2d + LeakyReLU構成。
//Conv2d + BatchNorm2d + LeakyReLU
class BasicConvImpl : public torch::nn::Module {
public:
BasicConvImpl(int in_channels, int out_channels, int kernel_size, int stride = 1);
torch::Tensor forward(torch::Tensor x);
private:
// Declare layers
torch::nn::Conv2d conv{ nullptr };
torch::nn::BatchNorm2d bn{ nullptr };
torch::nn::LeakyReLU acitivation{ nullptr };
}; TORCH_MODULE(BasicConv);
BasicConvImpl::BasicConvImpl(int in_channels, int out_channels, int kernel_size,
int stride) :
conv(conv_options(in_channels, out_channels, kernel_size, stride,
int(kernel_size / 2), 1, false)),
bn(torch::nn::BatchNorm2d(out_channels)),
acitivation(torch::nn::LeakyReLU(torch::nn::LeakyReLUOptions().negative_slope(0.1)))
{
register_module("conv", conv);
register_module("bn", bn);
}
torch::Tensor BasicConvImpl::forward(torch::Tensor x)
{
x = conv->forward(x);
x = bn->forward(x);
x = acitivation(x);
return x;
}
該層作為基本模塊,將在后期作為搭積木的基本塊,搭建yolo4_tiny。
然后是Resblock_body模塊,
class Resblock_bodyImpl : public torch::nn::Module {
public:
Resblock_bodyImpl(int in_channels, int out_channels);
std::vector<torch::Tensor> forward(torch::Tensor x);
private:
int out_channels;
BasicConv conv1{ nullptr };
BasicConv conv2{ nullptr };
BasicConv conv3{ nullptr };
BasicConv conv4{ nullptr };
torch::nn::MaxPool2d maxpool{ nullptr };
}; TORCH_MODULE(Resblock_body);
Resblock_bodyImpl::Resblock_bodyImpl(int in_channels, int out_channels) {
this->out_channels = out_channels;
conv1 = BasicConv(in_channels, out_channels, 3);
conv2 = BasicConv(out_channels / 2, out_channels / 2, 3);
conv3 = BasicConv(out_channels / 2, out_channels / 2, 3);
conv4 = BasicConv(out_channels, out_channels, 1);
maxpool = torch::nn::MaxPool2d(maxpool_options(2, 2));
register_module("conv1", conv1);
register_module("conv2", conv2);
register_module("conv3", conv3);
register_module("conv4", conv4);
}
std::vector<torch::Tensor> Resblock_bodyImpl::forward(torch::Tensor x) {
auto c = out_channels;
x = conv1->forward(x);
auto route = x;
x = torch::split(x, c / 2, 1)[1];
x = conv2->forward(x);
auto route1 = x;
x = conv3->forward(x);
x = torch::cat({ x, route1 }, 1);
x = conv4->forward(x);
auto feat = x;
x = torch::cat({ route, x }, 1);
x = maxpool->forward(x);
return std::vector<torch::Tensor>({ x,feat });
}
最后是骨干網絡主體
class CSPdarknet53_tinyImpl : public torch::nn::Module
{
public:
CSPdarknet53_tinyImpl();
std::vector<torch::Tensor> forward(torch::Tensor x);
private:
BasicConv conv1{ nullptr };
BasicConv conv2{ nullptr };
Resblock_body resblock_body1{ nullptr };
Resblock_body resblock_body2{ nullptr };
Resblock_body resblock_body3{ nullptr };
BasicConv conv3{ nullptr };
int num_features = 1;
}; TORCH_MODULE(CSPdarknet53_tiny);
CSPdarknet53_tinyImpl::CSPdarknet53_tinyImpl() {
conv1 = BasicConv(3, 32, 3, 2);
conv2 = BasicConv(32, 64, 3, 2);
resblock_body1 = Resblock_body(64, 64);
resblock_body2 = Resblock_body(128, 128);
resblock_body3 = Resblock_body(256, 256);
conv3 = BasicConv(512, 512, 3);
register_module("conv1", conv1);
register_module("conv2", conv2);
register_module("resblock_body1", resblock_body1);
register_module("resblock_body2", resblock_body2);
register_module("resblock_body3", resblock_body3);
register_module("conv3", conv3);
}
std::vector<torch::Tensor> CSPdarknet53_tinyImpl::forward(torch::Tensor x) {
// 416, 416, 3 -> 208, 208, 32 -> 104, 104, 64
x = conv1(x);
x = conv2(x);
// 104, 104, 64 -> 52, 52, 128
x = resblock_body1->forward(x)[0];
// 52, 52, 128 -> 26, 26, 256
x = resblock_body2->forward(x)[0];
// 26, 26, 256->xΪ13, 13, 512
# // -> feat1Ϊ26,26,256
auto res_out = resblock_body3->forward(x);
x = res_out[0];
auto feat1 = res_out[1];
// 13, 13, 512 -> 13, 13, 512
x = conv3->forward(x);
auto feat2 = x;
return std::vector<torch::Tensor>({ feat1, feat2 });
}
至此,yolo4_tiny中的骨干網絡已經搭建好。接下來將搭建yolo4_tiny模型。
yolov4_tiny
骨干網絡得到的特征圖,將經過FPN,需要上采樣模塊。
//conv+upsample
class UpsampleImpl : public torch::nn::Module {
public:
UpsampleImpl(int in_channels, int out_channels);
torch::Tensor forward(torch::Tensor x);
private:
// Declare layers
torch::nn::Sequential upsample = torch::nn::Sequential();
}; TORCH_MODULE(Upsample);
UpsampleImpl::UpsampleImpl(int in_channels, int out_channels)
{
upsample = torch::nn::Sequential(
BasicConv(in_channels, out_channels, 1)
//torch::nn::Upsample(torch::nn::UpsampleOptions().scale_factor(std::vector<double>({ 2 })).mode(torch::kNearest).align_corners(false))
);
register_module("upsample", upsample);
}
torch::Tensor UpsampleImpl::forward(torch::Tensor x)
{
x = upsample->forward(x);
x = at::upsample_nearest2d(x, { x.sizes()[2] * 2 , x.sizes()[3] * 2 });
return x;
}
然后是yolo_head模塊
torch::nn::Sequential yolo_head(std::vector<int> filters_list, int in_filters);
torch::nn::Sequential yolo_head(std::vector<int> filters_list, int in_filters) {
auto m = torch::nn::Sequential(BasicConv(in_filters, filters_list[0], 3),
torch::nn::Conv2d(conv_options(filters_list[0], filters_list[1], 1)));
return m;
}
以及yolo_body
class YoloBody_tinyImpl : public torch::nn::Module {
public:
YoloBody_tinyImpl(int num_anchors, int num_classes);
std::vector<torch::Tensor> forward(torch::Tensor x);
private:
// Declare layers
CSPdarknet53_tiny backbone{ nullptr };
BasicConv conv_for_P5{ nullptr };
Upsample upsample{ nullptr };
torch::nn::Sequential yolo_headP5{ nullptr };
torch::nn::Sequential yolo_headP4{ nullptr };
}; TORCH_MODULE(YoloBody_tiny);
YoloBody_tinyImpl::YoloBody_tinyImpl(int num_anchors, int num_classes) {
backbone = CSPdarknet53_tiny();
conv_for_P5 = BasicConv(512, 256, 1);
yolo_headP5 = yolo_head({ 512, num_anchors * (5 + num_classes) }, 256);
upsample = Upsample(256, 128);
yolo_headP4 = yolo_head({ 256, num_anchors * (5 + num_classes) }, 384);
register_module("backbone", backbone);
register_module("conv_for_P5", conv_for_P5);
register_module("yolo_headP5", yolo_headP5);
register_module("upsample", upsample);
register_module("yolo_headP4", yolo_headP4);
}
std::vector<torch::Tensor> YoloBody_tinyImpl::forward(torch::Tensor x) {
//return feat1 with shape of {26,26,256} and feat2 of {13, 13, 512}
auto backbone_out = backbone->forward(x);
auto feat1 = backbone_out[0];
auto feat2 = backbone_out[1];
//13,13,512 -> 13,13,256
auto P5 = conv_for_P5->forward(feat2);
//13, 13, 256 -> 13, 13, 512 -> 13, 13, 255
auto out0 = yolo_headP5->forward(P5);
//13,13,256 -> 13,13,128 -> 26,26,128
auto P5_Upsample = upsample->forward(P5);
//26, 26, 256 + 26, 26, 128 -> 26, 26, 384
auto P4 = torch::cat({ P5_Upsample, feat1 }, 1);
//26, 26, 384 -> 26, 26, 256 -> 26, 26, 255
auto out1 = yolo_headP4->forward(P4);
return std::vector<torch::Tensor>({ out0, out1 });
}
代碼寫到這一步,其實只要細心就會發現基本是對pytorch代碼到libtorch的遷移,除了少數bug需要調試,大部分簡單遷移到c++即可。可以說是非常簡便了。
像前面章節中一樣,生成torchscript模型。bubbliiiing yolov4-tiny中有提供一個coco訓練版本,通過下述代碼生成.pt文件:
import torch
from torchsummary import summary
import numpy as np
from nets.yolo4_tiny import YoloBody
from train import get_anchors, get_classes,YOLOLoss
device = torch.device('cpu')
model = YoloBody(3,80).to(device)
model_path = "model_data/yolov4_tiny_weights_coco.pth"
print('Loading weights into state dict...')
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=torch.device("cpu"))
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
model_dict.update(pretrained_dict)
model.load_state_dict(model_dict)
print('Finished!')
#生成pt模型,按照官網來即可
model=model.to(torch.device("cpu"))
model.eval()
var=torch.ones((1,3,416,416))
traced_script_module = torch.jit.trace(model, var)
traced_script_module.save("yolo4_tiny.pt")
然后在c++中使用下述代碼測試是否能夠正確加載:
auto model = YoloBody_tiny(3, 80);
torch::load(model, "weights/yolo4_tiny.pt");
執行通過即表明加載成功。
預測
預測需要將YOLO4_tiny模型輸出的張量進行解碼,根據源代碼解碼函數,寫出c++版本的解碼函數,此時將發現,libtorch教程第二章的重要性了。
torch::Tensor DecodeBox(torch::Tensor input, torch::Tensor anchors, int num_classes, int img_size[])
{
int num_anchors = anchors.sizes()[0];
int bbox_attrs = 5 + num_classes;
int batch_size = input.sizes()[0];
int input_height = input.sizes()[2];
int input_width = input.sizes()[3];
//計算步長
//每一個特征點對應原來的圖片上多少個像素點
//如果特征層為13x13的話,一個特征點就對應原來的圖片上的32個像素點
//416 / 13 = 32
auto stride_h = img_size[1] / input_height;
auto stride_w = img_size[0] / input_width;
//把先驗框的尺寸調整成特征層大小的形式
//計算出先驗框在特征層上對應的寬高
auto scaled_anchors = anchors.clone();
scaled_anchors.select(1, 0) = scaled_anchors.select(1, 0) / stride_w;
scaled_anchors.select(1, 1) = scaled_anchors.select(1, 1) / stride_h;
//bs, 3 * (5 + num_classes), 13, 13->bs, 3, 13, 13, (5 + num_classes)
//cout << "begin view"<<input.sizes()<<endl;
auto prediction = input.view({ batch_size, num_anchors,bbox_attrs, input_height, input_width }).permute({ 0, 1, 3, 4, 2 }).contiguous();
//cout << "end view" << endl;
//先驗框的中心位置的調整參數
auto x = torch::sigmoid(prediction.select(-1, 0));
auto y = torch::sigmoid(prediction.select(-1, 1));
//先驗框的寬高調整參數
auto w = prediction.select(-1, 2); // Width
auto h = prediction.select(-1, 3); // Height
//獲得置信度,是否有物體
auto conf = torch::sigmoid(prediction.select(-1, 4));
//種類置信度
auto pred_cls = torch::sigmoid(prediction.narrow(-1, 5, num_classes));// Cls pred.
auto LongType = x.clone().to(torch::kLong).options();
auto FloatType = x.options();
//生成網格,先驗框中心,網格左上角 batch_size, 3, 13, 13
auto grid_x = torch::linspace(0, input_width - 1, input_width).repeat({ input_height, 1 }).repeat(
{ batch_size * num_anchors, 1, 1 }).view(x.sizes()).to(FloatType);
auto grid_y = torch::linspace(0, input_height - 1, input_height).repeat({ input_width, 1 }).t().repeat(
{ batch_size * num_anchors, 1, 1 }).view(y.sizes()).to(FloatType);
//生成先驗框的寬高
auto anchor_w = scaled_anchors.to(FloatType).narrow(1, 0, 1);
auto anchor_h = scaled_anchors.to(FloatType).narrow(1, 1, 1);
anchor_w = anchor_w.repeat({ batch_size, 1 }).repeat({ 1, 1, input_height * input_width }).view(w.sizes());
anchor_h = anchor_h.repeat({ batch_size, 1 }).repeat({ 1, 1, input_height * input_width }).view(h.sizes());
//計算調整后的先驗框中心與寬高
auto pred_boxes = torch::randn_like(prediction.narrow(-1, 0, 4)).to(FloatType);
pred_boxes.select(-1, 0) = x + grid_x;
pred_boxes.select(-1, 1) = y + grid_y;
pred_boxes.select(-1, 2) = w.exp() * anchor_w;
pred_boxes.select(-1, 3) = h.exp() * anchor_h;
//用於將輸出調整為相對於416x416的大小
std::vector<int> scales{ stride_w, stride_h, stride_w, stride_h };
auto _scale = torch::tensor(scales).to(FloatType);
//cout << pred_boxes << endl;
//cout << conf << endl;
//cout << pred_cls << endl;
pred_boxes = pred_boxes.view({ batch_size, -1, 4 }) * _scale;
conf = conf.view({ batch_size, -1, 1 });
pred_cls = pred_cls.view({ batch_size, -1, num_classes });
auto output = torch::cat({ pred_boxes, conf, pred_cls }, -1);
return output;
}
此外,還需要將輸出進行非極大值抑制。參考我的NMS的幾種寫法寫出非極大值抑制函數:
std::vector<int> nms_libtorch(torch::Tensor bboxes, torch::Tensor scores, float thresh) {
auto x1 = bboxes.select(-1, 0);
auto y1 = bboxes.select(-1, 1);
auto x2 = bboxes.select(-1, 2);
auto y2 = bboxes.select(-1, 3);
auto areas = (x2 - x1)*(y2 - y1); //[N, ] 每個bbox的面積
auto tuple_sorted = scores.sort(0, true); //降序排列
auto order = std::get<1>(tuple_sorted);
std::vector<int> keep;
while (order.numel() > 0) {// torch.numel()返回張量元素個數
if (order.numel() == 1) {// 保留框只剩一個
auto i = order.item();
keep.push_back(i.toInt());
break;
}
else {
auto i = order[0].item();// 保留scores最大的那個框box[i]
keep.push_back(i.toInt());
}
//計算box[i]與其余各框的IOU(思路很好)
auto order_mask = order.narrow(0, 1, order.size(-1) - 1);
x1.index({ order_mask });
x1.index({ order_mask }).clamp(x1[keep.back()].item().toFloat(), 1e10);
auto xx1 = x1.index({ order_mask }).clamp(x1[keep.back()].item().toFloat(), 1e10);// [N - 1, ]
auto yy1 = y1.index({ order_mask }).clamp(y1[keep.back()].item().toFloat(), 1e10);
auto xx2 = x2.index({ order_mask }).clamp(0, x2[keep.back()].item().toFloat());
auto yy2 = y2.index({ order_mask }).clamp(0, y2[keep.back()].item().toFloat());
auto inter = (xx2 - xx1).clamp(0, 1e10) * (yy2 - yy1).clamp(0, 1e10);// [N - 1, ]
auto iou = inter / (areas[keep.back()] + areas.index({ order.narrow(0,1,order.size(-1) - 1) }) - inter);//[N - 1, ]
auto idx = (iou <= thresh).nonzero().squeeze();//注意此時idx為[N - 1, ] 而order為[N, ]
if (idx.numel() == 0) {
break;
}
order = order.index({ idx + 1 }); //修補索引之間的差值
}
return keep;
}
std::vector<torch::Tensor> non_maximum_suppression(torch::Tensor prediction, int num_classes, float conf_thres, float nms_thres) {
prediction.select(-1, 0) -= prediction.select(-1, 2) / 2;
prediction.select(-1, 1) -= prediction.select(-1, 3) / 2;
prediction.select(-1, 2) += prediction.select(-1, 0);
prediction.select(-1, 3) += prediction.select(-1, 1);
std::vector<torch::Tensor> output;
for (int image_id = 0; image_id < prediction.sizes()[0]; image_id++) {
auto image_pred = prediction[image_id];
auto max_out_tuple = torch::max(image_pred.narrow(-1, 5, num_classes), -1, true);
auto class_conf = std::get<0>(max_out_tuple);
auto class_pred = std::get<1>(max_out_tuple);
auto conf_mask = (image_pred.select(-1, 4) * class_conf.select(-1, 0) >= conf_thres).squeeze();
image_pred = image_pred.index({ conf_mask }).to(torch::kFloat);
class_conf = class_conf.index({ conf_mask }).to(torch::kFloat);
class_pred = class_pred.index({ conf_mask }).to(torch::kFloat);
if (!image_pred.sizes()[0]) {
output.push_back(torch::full({ 1, 7 }, 0));
continue;
}
//獲得的內容為(x1, y1, x2, y2, obj_conf, class_conf, class_pred)
auto detections = torch::cat({ image_pred.narrow(-1,0,5), class_conf, class_pred }, 1);
//獲得種類
std::vector<torch::Tensor> img_classes;
for (int m = 0, len = detections.size(0); m < len; m++)
{
bool found = false;
for (size_t n = 0; n < img_classes.size(); n++)
{
auto ret = (detections[m][6] == img_classes[n]);
if (torch::nonzero(ret).size(0) > 0)
{
found = true;
break;
}
}
if (!found) img_classes.push_back(detections[m][6]);
}
std::vector<torch::Tensor> temp_class_detections;
for (auto c : img_classes) {
auto detections_class = detections.index({ detections.select(-1,-1) == c });
auto keep = nms_libtorch(detections_class.narrow(-1, 0, 4), detections_class.select(-1, 4)*detections_class.select(-1, 5), nms_thres);
std::vector<torch::Tensor> temp_max_detections;
for (auto v : keep) {
temp_max_detections.push_back(detections_class[v]);
}
auto max_detections = torch::cat(temp_max_detections, 0);
temp_class_detections.push_back(max_detections);
}
auto class_detections = torch::cat(temp_class_detections, 0);
output.push_back(class_detections);
}
return output;
}
這些函數准備好后,寫出預測函數:
void show_bbox_coco(cv::Mat image, torch::Tensor bboxes, int nums) {
//設置繪制文本的相關參數
int font_face = cv::FONT_HERSHEY_COMPLEX;
double font_scale = 0.4;
int thickness = 1;
float* bbox = new float[bboxes.size(0)]();
std::cout << bboxes << std::endl;
memcpy(bbox, bboxes.cpu().data_ptr(), bboxes.size(0) * sizeof(float));
for (int i = 0; i < bboxes.size(0); i = i + 7)
{
cv::rectangle(image, cv::Rect(bbox[i + 0], bbox[i + 1], bbox[i + 2] - bbox[i + 0], bbox[i + 3] - bbox[i + 1]), cv::Scalar(0, 0, 255));
//將文本框居中繪制
cv::Point origin;
origin.x = bbox[i + 0];
origin.y = bbox[i + 1] + 8;
cv::putText(image, std::to_string(int(bbox[i + 6])), origin, font_face, font_scale, cv::Scalar(0, 0, 255), thickness, 1, 0);
}
delete bbox;
cv::imshow("test", image);
cv::waitKey(0);
cv::destroyAllWindows();
}
void Predict(YoloBody_tiny detector, cv::Mat image, bool show, float conf_thresh, float nms_thresh) {
int origin_width = image.cols;
int origin_height = image.rows;
cv::resize(image, image, { 416,416 });
auto img_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte);
img_tensor = img_tensor.permute({ 2, 0, 1 }).unsqueeze(0).to(torch::kFloat) / 255.0;
float anchor[12] = { 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 };
auto anchors_ = torch::from_blob(anchor, { 6,2 }, torch::TensorOptions(torch::kFloat32));
int image_size[2] = { 416,416 };
img_tensor = img_tensor.cuda();
auto outputs = detector->forward(img_tensor);
std::vector<torch::Tensor> output_list = {};
auto tensor_input = outputs[1];
auto output_decoded = DecodeBox(tensor_input, anchors_.narrow(0, 0, 3), 80, image_size);
output_list.push_back(output_decoded);
tensor_input = outputs[0];
output_decoded = DecodeBox(tensor_input, anchors_.narrow(0, 3, 3), 80, image_size);
output_list.push_back(output_decoded);
//std::cout << tensor_input << anchors_.narrow(0, 3, 3);
auto output = torch::cat(output_list, 1);
auto detection = non_maximum_suppression(output, 80, conf_thresh, nms_thresh);
float w_scale = float(origin_width) / 416;
float h_scale = float(origin_height) / 416;
for (int i = 0; i < detection.size(); i++) {
for (int j = 0; j < detection[i].size(0) / 7; j++)
{
detection[i].select(0, 7 * j + 0) *= w_scale;
detection[i].select(0, 7 * j + 1) *= h_scale;
detection[i].select(0, 7 * j + 2) *= w_scale;
detection[i].select(0, 7 * j + 3) *= h_scale;
}
}
cv::resize(image, image, { origin_width,origin_height });
if (show)
show_bbox_coco(image, detection[0], 80);
return;
}
使用VOC數據集中一張圖片,測試一下函數准確性。直接將上述代碼用於測試.pt文件,如輸入下述代碼:
cv::Mat image = cv::imread("2007_005331.jpg");
auto model = YoloBody_tiny(3, 80);
torch::load(model, "weights/yolo4_tiny.pt");
model->to(torch::kCUDA);
Predict(model, image, true, 0.1, 0.3);
使用的圖片如下圖

將會發現,預測結果如下:

結果分析有以下兩點結論:
- 輸出了檢測框,預測函數大概率正確;
- 存在部分誤檢,提高置信度閾值可能改善,但是會漏檢。這是由於.pt文件訓練時采用的預處理策略,和本文代碼預測時采用的預處理策略不一致導致的。
使用訓練和預測一致的預處理方式處理圖片,得到的結果應該要好很多。下面時一張,以coco預訓練權重做遷移學習,只訓練yolo_head,訓練voc數據集一個周期后,預測該圖的效果:

繼續訓練,數據增強,訓練全部權重應該可以將結果提升更多。
訓練
訓練代碼比較多,博客就不再介紹。可以移步到LibtorchTutorials中。同時,LibtorchTutorials中的代碼實現的功能都比較基礎,我將分開在LibtorchSegment項目和LibtorchDetection中將功能提升完善。有幫助到的話請點個star資瓷下。
分享不易,如果有用請不吝給我一個👍,轉載注明出處:https://allentdan.github.io/
代碼見LibtorchTutorials