本章簡要介紹如何如何用C++實現一個語義分割器模型,該模型具有訓練和預測的功能。本文的分割模型架構使用簡單的U-Net結構,代碼結構參考了qubvel segmentation中的U-Net部分,該項目簡稱SMP,是基於pytorch實現的開源語義分割項目。本文分享的c++模型幾乎完美復現了python的版本。
模型簡介
簡單介紹一下U-Net模型。U-Net模型的提出是在醫學圖像分割中,相比於當時的其他模型結構,U-Net的分割能力具有明顯優勢。一個經典的U-Net結構圖如下:
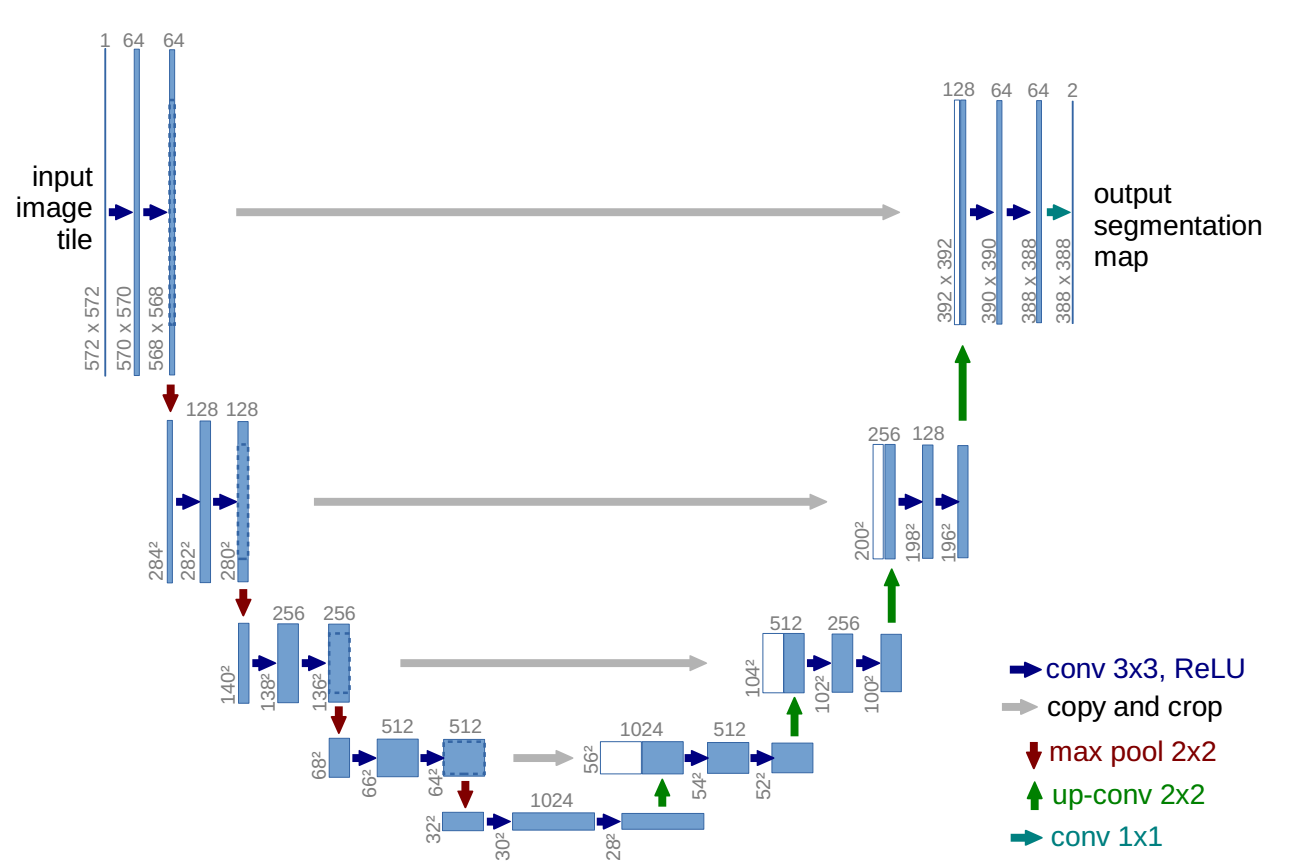
U-Net模型采用典型的編碼器-解碼器結構,左邊的編碼部分類似VGG模型,是雙卷積+下采樣的多次堆疊。U-Net模型右邊的解碼部分同樣是雙卷積,但是為了得到接近原始輸入圖像大小的輸出圖像,針對編碼的下采樣實施了對應的上采樣。最重要的是,U-Net之所以效果突出,重要原因在於其在解碼部分利用了編碼環節的特征圖,拼接編碼和解碼的特征圖,再對拼接后特征圖卷積上采樣,重復多次得到解碼輸出。
編碼器——ResNet
本文介紹的編碼器使用ResNet網絡,同時可以像第五章一樣加載預訓練權重,即骨干網絡為ImageNet預訓練的ResNet。話不多說,直接上c++的ResNet代碼。
Block搭建
建議看本文代碼時打開pytorch的torchvision中的resnet.py,對比閱讀。
首先是基礎模塊,pytorch針對resnet18,resne34和resnet50,resnet101,resnet152進行分類,resnet18與resnet34均使用BasicBlock,而更深的網絡使用BottleNeck。我不想使用模板類編程,就直接將兩個模塊合為一體。聲明如下:
class BlockImpl : public torch::nn::Module {
public:
BlockImpl(int64_t inplanes, int64_t planes, int64_t stride_ = 1,
torch::nn::Sequential downsample_ = nullptr, int groups = 1, int base_width = 64, bool is_basic = true);
torch::Tensor forward(torch::Tensor x);
torch::nn::Sequential downsample{ nullptr };
private:
bool is_basic = true;
int64_t stride = 1;
torch::nn::Conv2d conv1{ nullptr };
torch::nn::BatchNorm2d bn1{ nullptr };
torch::nn::Conv2d conv2{ nullptr };
torch::nn::BatchNorm2d bn2{ nullptr };
torch::nn::Conv2d conv3{ nullptr };
torch::nn::BatchNorm2d bn3{ nullptr };
};
TORCH_MODULE(Block);
可以發現,其實是直接聲明了三個conv結構和一個is_basic標志位判斷定義時進行BasicBlock定義還是BottleNeck定義。下面時其定義
BlockImpl::BlockImpl(int64_t inplanes, int64_t planes, int64_t stride_,
torch::nn::Sequential downsample_, int groups, int base_width, bool _is_basic)
{
downsample = downsample_;
stride = stride_;
int width = int(planes * (base_width / 64.)) * groups;
conv1 = torch::nn::Conv2d(conv_options(inplanes, width, 3, stride_, 1, groups, false));
bn1 = torch::nn::BatchNorm2d(torch::nn::BatchNorm2dOptions(width));
conv2 = torch::nn::Conv2d(conv_options(width, width, 3, 1, 1, groups, false));
bn2 = torch::nn::BatchNorm2d(torch::nn::BatchNorm2dOptions(width));
is_basic = _is_basic;
if (!is_basic) {
conv1 = torch::nn::Conv2d(conv_options(inplanes, width, 1, 1, 0, 1, false));
conv2 = torch::nn::Conv2d(conv_options(width, width, 3, stride_, 1, groups, false));
conv3 = torch::nn::Conv2d(conv_options(width, planes * 4, 1, 1, 0, 1, false));
bn3 = torch::nn::BatchNorm2d(torch::nn::BatchNorm2dOptions(planes * 4));
}
register_module("conv1", conv1);
register_module("bn1", bn1);
register_module("conv2", conv2);
register_module("bn2", bn2);
if (!is_basic) {
register_module("conv3", conv3);
register_module("bn3", bn3);
}
if (!downsample->is_empty()) {
register_module("downsample", downsample);
}
}
torch::Tensor BlockImpl::forward(torch::Tensor x) {
torch::Tensor residual = x.clone();
x = conv1->forward(x);
x = bn1->forward(x);
x = torch::relu(x);
x = conv2->forward(x);
x = bn2->forward(x);
if (!is_basic) {
x = torch::relu(x);
x = conv3->forward(x);
x = bn3->forward(x);
}
if (!downsample->is_empty()) {
residual = downsample->forward(residual);
}
x += residual;
x = torch::relu(x);
return x;
}
然后不要忘了熟悉的conv_options函數,定義如下:
inline torch::nn::Conv2dOptions conv_options(int64_t in_planes, int64_t out_planes, int64_t kerner_size,
int64_t stride = 1, int64_t padding = 0, int groups = 1, bool with_bias = true) {
torch::nn::Conv2dOptions conv_options = torch::nn::Conv2dOptions(in_planes, out_planes, kerner_size);
conv_options.stride(stride);
conv_options.padding(padding);
conv_options.bias(with_bias);
conv_options.groups(groups);
return conv_options;
}
和之前章節中的相比,增加了groups參數,同時with_bias默認打開,使用需要注意修改。
ResNet主體搭建
定義好Block模塊后就可以設計ResNet了,c++中ResNet模型聲明類似pytorch中的ResNet。但是初始化參數增加一個model_type,輔助判斷采用哪種Block。
class ResNetImpl : public torch::nn::Module {
public:
ResNetImpl(std::vector<int> layers, int num_classes = 1000, std::string model_type = "resnet18",
int groups = 1, int width_per_group = 64);
torch::Tensor forward(torch::Tensor x);
std::vector<torch::Tensor> features(torch::Tensor x);
torch::nn::Sequential _make_layer(int64_t planes, int64_t blocks, int64_t stride = 1);
private:
int expansion = 1; bool is_basic = true;
int64_t inplanes = 64; int groups = 1; int base_width = 64;
torch::nn::Conv2d conv1{ nullptr };
torch::nn::BatchNorm2d bn1{ nullptr };
torch::nn::Sequential layer1{ nullptr };
torch::nn::Sequential layer2{ nullptr };
torch::nn::Sequential layer3{ nullptr };
torch::nn::Sequential layer4{ nullptr };
torch::nn::Linear fc{nullptr};
};
TORCH_MODULE(ResNet);
在實現初始化函數之前,需要實現_make_layer函數。實現好_make_layer函數后再實現ResNet初始化函數,代碼如下:
torch::nn::Sequential ResNetImpl::_make_layer(int64_t planes, int64_t blocks, int64_t stride) {
torch::nn::Sequential downsample;
if (stride != 1 || inplanes != planes * expansion) {
downsample = torch::nn::Sequential(
torch::nn::Conv2d(conv_options(inplanes, planes * expansion, 1, stride, 0, 1, false)),
torch::nn::BatchNorm2d(planes * expansion)
);
}
torch::nn::Sequential layers;
layers->push_back(Block(inplanes, planes, stride, downsample, groups, base_width, is_basic));
inplanes = planes * expansion;
for (int64_t i = 1; i < blocks; i++) {
layers->push_back(Block(inplanes, planes, 1, torch::nn::Sequential(), groups, base_width,is_basic));
}
return layers;
}
ResNetImpl::ResNetImpl(std::vector<int> layers, int num_classes, std::string model_type, int _groups, int _width_per_group)
{
if (model_type != "resnet18" && model_type != "resnet34")
{
expansion = 4;
is_basic = false;
}
groups = _groups;
base_width = _width_per_group;
conv1 = torch::nn::Conv2d(conv_options(3, 64, 7, 2, 3, 1, false));
bn1 = torch::nn::BatchNorm2d(torch::nn::BatchNorm2dOptions(64));
layer1 = torch::nn::Sequential(_make_layer(64, layers[0]));
layer2 = torch::nn::Sequential(_make_layer(128, layers[1], 2));
layer3 = torch::nn::Sequential(_make_layer(256, layers[2], 2));
layer4 = torch::nn::Sequential(_make_layer(512, layers[3], 2));
fc = torch::nn::Linear(512 * expansion, num_classes);
register_module("conv1", conv1);
register_module("bn1", bn1);
register_module("layer1", layer1);
register_module("layer2", layer2);
register_module("layer3", layer3);
register_module("layer4", layer4);
register_module("fc", fc);
}
前向傳播及特征提取
前向傳播相對簡單,直接根據定義好的層往下傳播即可。
torch::Tensor ResNetImpl::forward(torch::Tensor x) {
x = conv1->forward(x);
x = bn1->forward(x);
x = torch::relu(x);
x = torch::max_pool2d(x, 3, 2, 1);
x = layer1->forward(x);
x = layer2->forward(x);
x = layer3->forward(x);
x = layer4->forward(x);
x = torch::avg_pool2d(x, 7, 1);
x = x.view({ x.sizes()[0], -1 });
x = fc->forward(x);
return torch::log_softmax(x, 1);
}
但是本文是介紹分割用的,所以需要對不同的特征層進行提取,存儲到std::vectortorch::Tensor中。
std::vector<torch::Tensor> ResNetImpl::features(torch::Tensor x){
std::vector<torch::Tensor> features;
features.push_back(x);
x = conv1->forward(x);
x = bn1->forward(x);
x = torch::relu(x);
features.push_back(x);
x = torch::max_pool2d(x, 3, 2, 1);
x = layer1->forward(x);
features.push_back(x);
x = layer2->forward(x);
features.push_back(x);
x = layer3->forward(x);
features.push_back(x);
x = layer4->forward(x);
features.push_back(x);
return features;
}
U-Net解碼
上面的ResNet部分其實可以開單章詳細講解,但是參照源碼讀者應該容易理解,就直接放一起。如果上面的內容是對torchvision在libtorch中的優化,下面的部分可以看成直接對SMP中U-Net解碼的c++復制。
直接上聲明:
//attention and basic
class SCSEModuleImpl: public torch::nn::Module{
public:
SCSEModuleImpl(int in_channels, int reduction=16, bool use_attention = false);
torch::Tensor forward(torch::Tensor x);
private:
bool use_attention = false;
torch::nn::Sequential cSE{nullptr};
torch::nn::Sequential sSE{nullptr};
};TORCH_MODULE(SCSEModule);
class Conv2dReLUImpl: public torch::nn::Module{
public:
Conv2dReLUImpl(int in_channels, int out_channels, int kernel_size = 3, int padding = 1);
torch::Tensor forward(torch::Tensor x);
private:
torch::nn::Conv2d conv2d{nullptr};
torch::nn::BatchNorm2d bn{nullptr};
};TORCH_MODULE(Conv2dReLU);
//decoderblock and center block
class DecoderBlockImpl: public torch::nn::Module{
public:
DecoderBlockImpl(int in_channels, int skip_channels, int out_channels, bool skip = true, bool attention = false);
torch::Tensor forward(torch::Tensor x, torch::Tensor skip);
private:
Conv2dReLU conv1{nullptr};
Conv2dReLU conv2{nullptr};
SCSEModule attention1{nullptr};
SCSEModule attention2{nullptr};
torch::nn::Upsample upsample{nullptr};
bool is_skip = true;
};TORCH_MODULE(DecoderBlock);
torch::nn::Sequential CenterBlock(int in_channels, int out_channels);
class UNetDecoderImpl:public torch::nn::Module
{
public:
UNetDecoderImpl(std::vector<int> encoder_channels, std::vector<int> decoder_channels, int n_blocks = 5,
bool use_attention = false, bool use_center=false);
torch::Tensor forward(std::vector<torch::Tensor> features);
private:
torch::nn::Sequential center{nullptr};
torch::nn::ModuleList blocks = torch::nn::ModuleList();
};TORCH_MODULE(UNetDecoder);
#endif // UNETDECODER_H
直接上定義:
SCSEModuleImpl::SCSEModuleImpl(int in_channels, int reduction, bool _use_attention){
use_attention = _use_attention;
cSE = torch::nn::Sequential(
torch::nn::AdaptiveAvgPool2d(torch::nn::AdaptiveAvgPool2dOptions(1)),
torch::nn::Conv2d(conv_options(in_channels, in_channels / reduction, 1)),
torch::nn::ReLU(torch::nn::ReLUOptions(true)),
torch::nn::Conv2d(conv_options(in_channels / reduction, in_channels, 1)),
torch::nn::Sigmoid());
sSE = torch::nn::Sequential(torch::nn::Conv2d(conv_options(in_channels, 1, 1)), torch::nn::Sigmoid());
register_module("cSE",cSE);
register_module("sSE",sSE);
}
torch::Tensor SCSEModuleImpl::forward(torch::Tensor x){
if(!use_attention) return x;
return x * cSE->forward(x) + x * sSE->forward(x);
}
Conv2dReLUImpl::Conv2dReLUImpl(int in_channels, int out_channels, int kernel_size, int padding){
conv2d = torch::nn::Conv2d(conv_options(in_channels,out_channels,kernel_size,1,padding));
bn = torch::nn::BatchNorm2d(torch::nn::BatchNorm2dOptions(out_channels));
register_module("conv2d", conv2d);
register_module("bn", bn);
}
torch::Tensor Conv2dReLUImpl::forward(torch::Tensor x){
x = conv2d->forward(x);
x = bn->forward(x);
return x;
}
DecoderBlockImpl::DecoderBlockImpl(int in_channels, int skip_channels, int out_channels, bool skip, bool attention){
conv1 = Conv2dReLU(in_channels + skip_channels, out_channels, 3, 1);
conv2 = Conv2dReLU(out_channels, out_channels, 3, 1);
register_module("conv1", conv1);
register_module("conv2", conv2);
upsample = torch::nn::Upsample(torch::nn::UpsampleOptions().scale_factor(std::vector<double>({2,2})).mode(torch::kNearest));
attention1 = SCSEModule(in_channels + skip_channels, 16, attention);
attention2 = SCSEModule(out_channels, 16, attention);
register_module("attention1", attention1);
register_module("attention2", attention2);
is_skip = skip;
}
torch::Tensor DecoderBlockImpl::forward(torch::Tensor x, torch::Tensor skip){
x = upsample->forward(x);
if (is_skip){
x = torch::cat({x, skip}, 1);
x = attention1->forward(x);
}
x = conv1->forward(x);
x = conv2->forward(x);
x = attention2->forward(x);
return x;
}
torch::nn::Sequential CenterBlock(int in_channels, int out_channels){
return torch::nn::Sequential(Conv2dReLU(in_channels, out_channels, 3, 1),
Conv2dReLU(out_channels, out_channels, 3, 1));
}
UNetDecoderImpl::UNetDecoderImpl(std::vector<int> encoder_channels, std::vector<int> decoder_channels, int n_blocks,
bool use_attention, bool use_center)
{
if (n_blocks != decoder_channels.size()) throw "Model depth not equal to your provided `decoder_channels`";
std::reverse(std::begin(encoder_channels),std::end(encoder_channels));
// computing blocks input and output channels
int head_channels = encoder_channels[0];
std::vector<int> out_channels = decoder_channels;
decoder_channels.pop_back();
decoder_channels.insert(decoder_channels.begin(),head_channels);
std::vector<int> in_channels = decoder_channels;
encoder_channels.erase(encoder_channels.begin());
std::vector<int> skip_channels = encoder_channels;
skip_channels[skip_channels.size()-1] = 0;
if(use_center) center = CenterBlock(head_channels, head_channels);
else center = torch::nn::Sequential(torch::nn::Identity());
//the last DecoderBlock of blocks need no skip tensor
for (int i = 0; i< in_channels.size()-1; i++) {
blocks->push_back(DecoderBlock(in_channels[i], skip_channels[i], out_channels[i], true, use_attention));
}
blocks->push_back(DecoderBlock(in_channels[in_channels.size()-1], skip_channels[in_channels.size()-1],
out_channels[in_channels.size()-1], false, use_attention));
register_module("center", center);
register_module("blocks", blocks);
}
torch::Tensor UNetDecoderImpl::forward(std::vector<torch::Tensor> features){
std::reverse(std::begin(features),std::end(features));
torch::Tensor head = features[0];
features.erase(features.begin());
auto x = center->forward(head);
for (int i = 0; i<blocks->size(); i++) {
x = blocks[i]->as<DecoderBlock>()->forward(x, features[i]);
}
return x;
}
不展開說了,內容較多。后續還有U-Net整體和封裝...
U-Net整體設計
這是U-Net的聲明,分為編碼器,解碼器和分割頭。
class UNetImpl : public torch::nn::Module
{
public:
UNetImpl(int num_classes, std::string encoder_name = "resnet18", std::string pretrained_path = "", int encoder_depth = 5,
std::vector<int> decoder_channels={256, 128, 64, 32, 16}, bool use_attention = false);
torch::Tensor forward(torch::Tensor x);
private:
ResNet encoder{nullptr};
UNetDecoder decoder{nullptr};
SegmentationHead segmentation_head{nullptr};
int num_classes = 1;
std::vector<int> BasicChannels = {3, 64, 64, 128, 256, 512};
std::vector<int> BottleChannels = {3, 64, 256, 512, 1024, 2048};
std::map<std::string, std::vector<int>> name2layers = getParams();
};TORCH_MODULE(UNet);
這是實現:
UNetImpl::UNetImpl(int _num_classes, std::string encoder_name, std::string pretrained_path, int encoder_depth,
std::vector<int> decoder_channels, bool use_attention){
num_classes = _num_classes;
std::vector<int> encoder_channels = BasicChannels;
if(!name2layers.count(encoder_name)) throw "encoder name must in {resnet18, resnet34, resnet50, resnet101}";
if(encoder_name!="resnet18" && encoder_name!="resnet34"){
encoder_channels = BottleChannels;
}
encoder = pretrained_resnet(1000, encoder_name, pretrained_path);
decoder = UNetDecoder(encoder_channels,decoder_channels, encoder_depth, use_attention, false);
segmentation_head = SegmentationHead(decoder_channels[decoder_channels.size()-1], num_classes, 1, 1);
register_module("encoder",encoder);
register_module("decoder",decoder);
register_module("segmentation_head",segmentation_head);
}
torch::Tensor UNetImpl::forward(torch::Tensor x){
std::vector<torch::Tensor> features = encoder->features(x);
x = decoder->forward(features);
x = segmentation_head->forward(x);
return x;
}
分割頭:
class SegmentationHeadImpl: public torch::nn::Module{
public:
SegmentationHeadImpl(int in_channels, int out_channels, int kernel_size=3, double upsampling=1);
torch::Tensor forward(torch::Tensor x);
private:
torch::nn::Conv2d conv2d{nullptr};
torch::nn::Upsample upsampling{nullptr};
};TORCH_MODULE(SegmentationHead);
SegmentationHeadImpl::SegmentationHeadImpl(int in_channels, int out_channels, int kernel_size, double _upsampling){
conv2d = torch::nn::Conv2d(conv_options(in_channels, out_channels, kernel_size, 1, kernel_size / 2));
upsampling = torch::nn::Upsample(upsample_options(std::vector<double>{_upsampling,_upsampling}));
register_module("conv2d",conv2d);
}
torch::Tensor SegmentationHeadImpl::forward(torch::Tensor x){
x = conv2d->forward(x);
x = upsampling->forward(x);
return x;
}
內容過於多,博客寫得比較費勁。直接將封裝和測試代碼放到GitHub上了,在這里。里面集成了包括ResNet,ResNext和可能的ResNest為骨干網絡,目前網絡架構實現了FPN,U-Net,PAN,LinkNet,DeepLabV3,DeepLabV3+。如果項目內容有幫到你請務必給個star,作者需要這份支持作為動力,實在沒錢做推廣呀...大家牛年快樂!!!
實際測試U-Net在c++代碼執行效率,發現與python在cpu下速度一致,GPU下快35%+。c++真香。
分享不易,如果有用請不吝給我一個👍,轉載注明出處:https://allentdan.github.io/
代碼見LibtorchTutorials