
論文地址: https://arxiv.org/abs/2002.10137
概述
Talking face generation, 給定一段語音, 我們需要生成一段視頻, 這段視頻中的人的表情, 姿勢要和語音中相互對應, 該任務的核心在於, 將語音信息轉化為視頻中人嘴唇和表情的變化, 一些姿勢也要考慮在其中. 這和DeepFake的換臉操作其實有不少重疊的地方, 但也有不同, 換臉並不是生成工作, 其背景也更加復雜, 生成的目標圖片也更加逼真.
- 本文提出, 當前的talking face generation方法都沒有考慮人在說話時頭部的pose, 而單純的考慮固定的頭部姿勢之下的面部動畫. 而本文則通過同時處理人的音源A和較短的視頻源V來處理這個問題. 主要的處理方法是先用3D模型重組人臉並將其重新渲染, 為了讓圖片更加平滑逼真, 作者使用了GAN模型在公開數據集上訓練再fine-tuning的方法. 本文的最大挑戰在於, 人在說話時頭部pose的變化可能會出現in-plane and out-of-plane頭部轉動, 這也是3D重組方法提出的motivation.

本文的的主要貢獻在於: 1) 第一次提出可以將任意音源轉化為具有個性化pose的人臉talking視頻. 2) 一個memory-augmented GAN, 可以生成逼真的視頻幀. 3) 需求數據很小, 300幀的目標視頻數據即可生成有效的目標.
方法

模型結構如上圖. 輸入是一組音源A和視頻源V. 模型從A中推測這段音頻中的人的表情和姿勢變化並形成序列. 從V中使用3D人臉重建, 獲取臉的形狀, 打光, 表情, 姿勢等特征, 接着去掉3D人臉重建中獲取的表情姿勢特征(源視頻中的表情肯定是不需要的), 並整合A中獲取的表情和姿勢(LSTM推測出來的表情才是目標視頻所需的), 這樣就獲得了目標視頻片段所期望具有的人臉信息+表情特征. 經過渲染, 模型獲取了轉換后的人臉, 此時的人臉還很不自然. 作者講這些轉換后的人臉送入一個GAN中進行二次渲染, 使其更為逼真.
下面詳細介紹模型工作:
1 3D人臉重建
這一塊作者直接用了別人的工作, Accurate 3D face reconstruction with weakly-supervised learning: From single image to image set, 這個模型應用CNN將生成的3D圖像擬合到原始圖片中, 保留人臉的形狀, 紋理和照明. 模型最后給出一個257維的向量, 分別表示人臉的特征(80), 表情(64), 紋理(80), 照明(27), 姿勢(6, 包含旋轉和翻轉). 然后通過PCA basis計算獲得3D臉部的特征.
(大致是這樣, 具體的看不懂, 以前真沒接觸過)
2 音頻信息轉化為表情和姿勢
表情和姿勢特征由原始的音頻和3D人臉的特征聯合獲得. 模型提取原始音頻的Mel-frequency cepstral coefficients, 梅爾頻率倒譜系數, MFCC, 這是常用於語音識別的特征信息, 該特征和上文人臉的表情特征輸入到經典的LSTM中, 預測每一步的表情和動作特征. 沒什么特別大的創新.
3 渲染和背景匹配
3.1 渲染
渲染引擎也是用的現成的, Unsupervised training for 3D morphable model regression, 也不難理解, 圖形學的東西還是得交給專業的人搞. 做法上, 從原始音頻獲取表情和pose, 從原始視頻獲取紋理和形狀, 然后進行渲染. 這種渲染會導致圖片不夠平滑, 不像人臉. 在生成最終幀之前, 作者選擇忍受這種不夠自然的渲染結果. 論文也給出了獲取更自然渲染結果的方法(映射到二維並為每個像素賦色), 並在general mapping中使用(不過真的有這一步嗎論文到現在沒怎么提).
3.2 背景匹配
前面的操作都只能生成一張臉, 而不包含頭發和背景信息. 本文獲取背景信息的方法比較粗暴(數據過少也是一個限制), 作者從視頻中找到頭部姿勢最大(比如最左或最右)的幀, 稱其為關鍵幀, 並只匹配關鍵幀的背景. 其他幀的背景由線性插值獲得.
4 Memory-augmented GAN for refining freams
作者的主要貢獻. 前面三步使用的圖像渲染引擎是輕量級的, 不能獲取足夠真實的幀. 作者生成本文提出的GAN和之前的面部重建GAN的區別在於:
- 本模型可以處理任意目標的渲染, 而之前的工作只能針對特定人臉.
- 本模型使用數據更少, 之前的模型需要數千幀來訓練網絡, 本文只需要在general mapping中使用幾幀, 隨后在target face的生成中再使用幾幀微調.
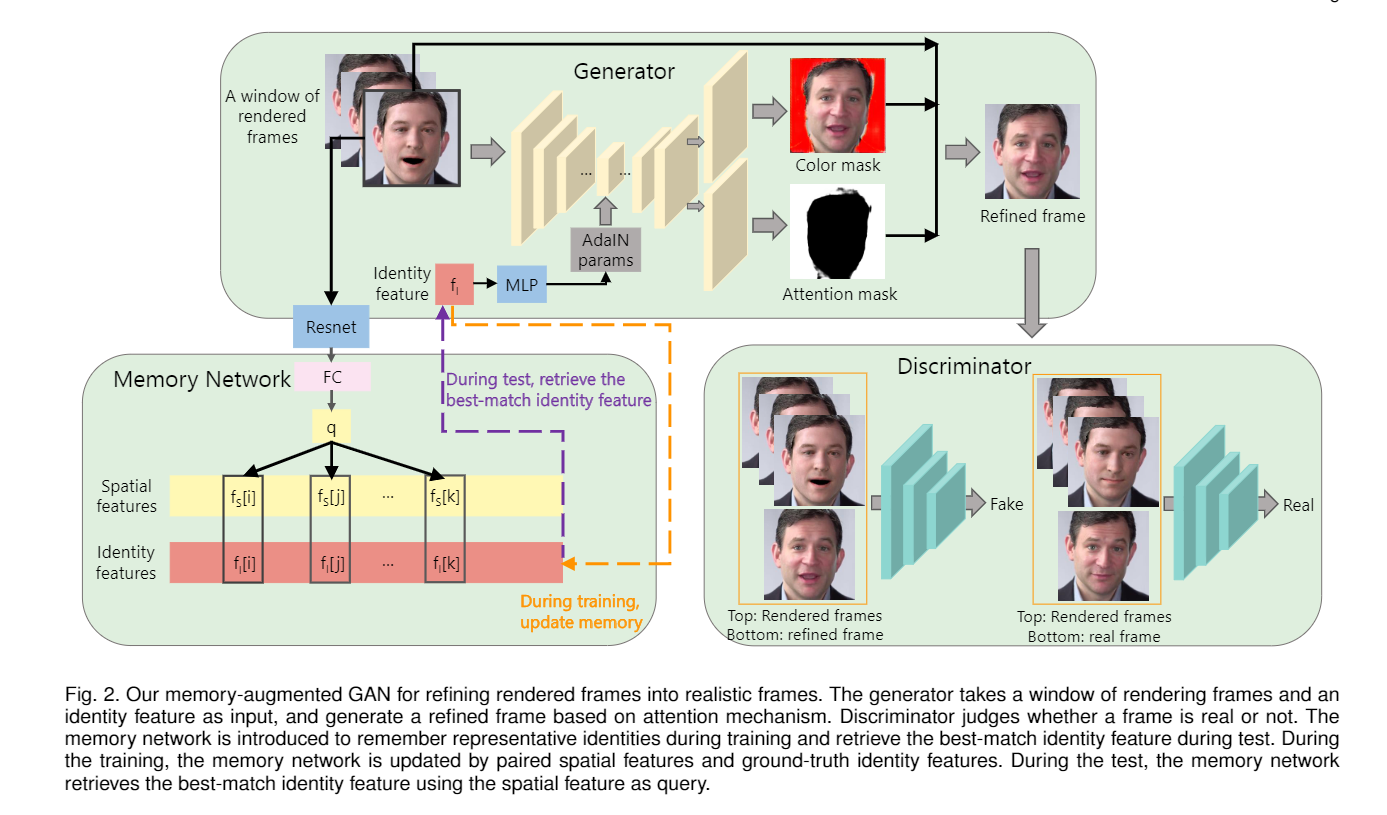
模型框架如上圖. generator和discriminator, 以及一個附加的memory network.
generator負責從連續的三幀中生成refined frame, 生成方法是使用AdaIN的U-net. discriminator接受連續的三幀和refined frame或者real frame, 用以判別幀是否是生成的.
memory network存儲的是成對的信息, 分別為空間特征和身份特征, 主要是記住比較有代表性的身份, 並在測試時尋找最佳匹配.
具體來說,
generator的計算公式如下:
\(r_t\)是輸入的三幀中的中間幀, 也是我們希望渲染的幀. \(A_t\)和\(C_t\)是generator中U-net生成的兩個mask, 這里作者將傳統的U-net的最后一層改成了兩個平行的層, 分別生成不同的mask. U-net在生成中使用了AdaIN參數, 這個參數來自memory network.
然后是memory network, 這個網絡用來記憶人臉的身份特征, 在test中則是尋找和test樣例最相似的一個身份. memory network中存儲的數據成對存在, 分別較spatial feature和identity feature. spatial feature由原始的三幀經由resnet和全連接層獲取. identity feature則將groundtruth放到ArcFace中獲取.
成對的feature會在訓練中不斷更新--很好理解的, 每次訓練都是三幀, 都會獲取一對feature, 這些feature要么會成為memory network中的新的一對特征, 要么會替換舊的一對. 替換原則是計算cos距離, 低於閾值替換, 高於閾值更新.
loss函數為:
包含了GAN的loss, L1 loss和attention loss.
實驗

總結
非常典型的任務驅動的論文, 其實模型上講, 本文沒有什么巨大創新, 但通過任務的定義, 作者有機的組合了不同領域的工具, 成果的完成了這個任務.