論文閱讀-Hierarchical Cross-Modal Talking Face Generation with Dynamic Pixel-Wise Loss

論文鏈接: http://openaccess.thecvf.com/content_CVPR_2019/html/Chen_Hierarchical_Cross-Modal_Talking_Face_Generation_With_Dynamic_Pixel-Wise_Loss_CVPR_2019_paper.html
概述
關鍵詞: 高級空間, 像素抖動, GAN模型
作者在本文中不由音頻直接生成talking face, 而是將音頻映射到高級空間, 也就是人臉的landmarks上, 再通過landmarks生成人臉. 這是個還不錯的想法. 作者生成這種方法相比於直接生成, 有助於模型不會學習到視聽信號和音頻的偽相關性.
此外, 在對像素抖動和圖像清晰度方面作者也給出了貢獻.
本文是為數不多的相關論文里面在第一段就給出任務定義的:
"本文考慮了這樣一個任務:給定目標臉部圖像和任意語音錄音,生成目標對象的逼真的有聲面部,說出具有自然唇同步的語音,同時保持面部圖像隨時間的平穩過渡。"
這是talking face生成任務的經典定義.
作者提出了本文克服了這個領域的兩個挑戰:
-
視頻幀之間的不流暢(偽影, 不連續), 並選擇了GAN模型處理這種不流暢性
-
模型需要推斷與視聽信號無關的相機角度, 頭部姿勢等特征, 而這些特征是無法直接從音頻中獲得的. 因此作者選擇將音頻先轉化為landmarks, 再轉化為人臉的方法.
方法

模型示意, 左半邊轉化, 右半邊生成.
1 整體結構
論文提出的模型輸入為, 一個音源序列\(a_{1:T}\), 一個樣例幀\(i_p\)和這個幀的landmarks\(p_p\). 模型會針對音源序列\(a_{1:T}\)生成其landmarks序列\(\hat{p}_{1:T}\)並生成連續的幀
\(\hat{v}_{1:T}\). 用公式表示就是:
\[\begin{array}{l} \hat{p}_{1: T}=\Psi\left(a_{1: T}, p_{p}\right) \\ \hat{v}_{1: T}=\Phi\left(\hat{p}_{1: T}, i_{p}, p_{p}\right) \end{array} \]
AT-net是一個encoder-decoder模型, VG-net則是一個多媒體CNN-RNN網絡.
AT-net的任務是接受\(a_{1:T}\)和\(p_p\)並生成\(\hat{p}_{1:T}\). 公式定義為:
\[\begin{aligned} \left[h_{t}, c_{t}\right] &=\varphi_{\text {lmark }}\left(\mathrm{LSTM}\left(f_{\text {audio }}\left(a_{t}\right), f_{\text {lmark }}\left(h_{p}\right), c_{t-1}\right)\right), \\ \hat{p}_{t} &=\mathrm{PCA}_{\mathrm{R}}\left(h_{t}\right)=h_{t} \odot \omega * \mathrm{U}^{T}+\mathrm{M} \end{aligned} \]
其中, \(a_t\)是音頻的MFCC特征. \(f_{audio}\), \(f_{lmark}\)和$$\varphi_{\text {Imark }}$$分別為audio的encoder, landmarks的encoder和decoder. \(h_p\)和\(h_t\)分別為輸入圖片和輸出的landmarks PCA.
\(PCA_R\)是PCA重構,而ω是增強PCA功能的升壓矩陣。 U對應於最大特征值,M對應於訓練集landmarks的平均形狀。
VG-net是一個應用注意力機制的CRNN, 公式定義為:
\[\begin{array}{l} v_{t}^{\prime \prime}=f_{\operatorname{img}\left(i_{p}\right)} \oplus\left(f_{\text {lmark }}\left(p_{t}\right)-f_{\text {Imark }}\left(p_{p}\right)\right) \\ a t t_{p_{t}}=\sigma\left(f_{\text {Imark }}\left(p_{t}\right) \oplus f_{\text {lmark }}\left(p_{p}\right)\right) \\ v_{t}^{\prime}=\left(\operatorname{CRNN}\left(v_{t}^{\prime \prime}\right)\right) \odot \text { att }_{p_{t}}+i_{p}^{\prime} \odot\left(1-\operatorname{att}_{p_{t}}\right) \end{array} \]
2 基於注意力的動態像素級loss
現有工作, 不管是基於GAN還是encoder-decoder, 都會出現像素抖動問題:

如圖所示, 相鄰的幀之間, 同區域的像素出現了明顯的不連貫, 而人對這種不連貫是非常敏感的. 一般的GAN loss或者L1/L2 loss都不能解決這個問題. 這也是本文着重解決的一個問題.
本文最終生成的幀要符合如下公式約束:
\[\hat{v}_{t}=\boldsymbol{\alpha}_{t} \odot m_{t}+\left(\mathbf{1}-\boldsymbol{\alpha}_{t}\right) \odot i_{p} \]
\(\alpha_t\)是在\(v'_t\)上進行卷積和sigmod激活之后獲得的, \(m_t\)在\(v'_t\)上卷積和進行hyperbolic tangent activation(其實就是tanh). 這樣會約束模型在於音頻無關的區域(頭發, 背景等)持續的生成統一的像素點.
3 基於回歸的判別器 Regression-Based Discriminator
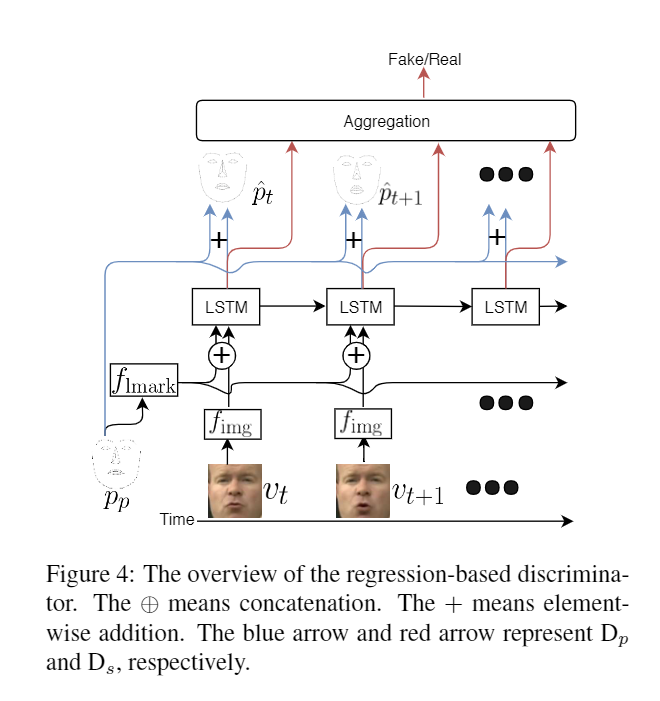
結構不是很難, 原始圖片和生成圖片或者和ground truth作為輸入, 通過LSTM預測landmarks, 並給整個序列給出一個分數\(s\):
\[\begin{aligned} \hat{p}_{t} &=\mathrm{D}_{p}\left(p_{p}, v_{t}\right) \\ &=p_{p}+\mathrm{L} \mathrm{S} \operatorname{TM}\left(f_{\text {lmark }}\left(p_{p}\right) \oplus f_{\text {img }}\left(v_{t}\right)\right) \end{aligned} \]
\[\begin{aligned} s &=\mathrm{D}_{s}\left(p_{p}, v_{1: T}\right) \\ &=\sigma\left(\frac{1}{T} \sum_{t=1}^{T}\left(\mathrm{LSTM}\left(f_{\text {Imark }}\left(p_{p}\right) \oplus f_{\text {img }}\left(v_{t}\right)\right)\right)\right) \end{aligned} \]
總結
本文比較讓我眼前一亮的是:
-
將音頻轉化為高級特征表示而不是直接生成, 這相當於預處理了一波特征, 相當有效.
-
連續幀之間的像素抖動解決.