
论文地址: https://arxiv.org/abs/2002.10137
概述
Talking face generation, 给定一段语音, 我们需要生成一段视频, 这段视频中的人的表情, 姿势要和语音中相互对应, 该任务的核心在于, 将语音信息转化为视频中人嘴唇和表情的变化, 一些姿势也要考虑在其中. 这和DeepFake的换脸操作其实有不少重叠的地方, 但也有不同, 换脸并不是生成工作, 其背景也更加复杂, 生成的目标图片也更加逼真.
- 本文提出, 当前的talking face generation方法都没有考虑人在说话时头部的pose, 而单纯的考虑固定的头部姿势之下的面部动画. 而本文则通过同时处理人的音源A和较短的视频源V来处理这个问题. 主要的处理方法是先用3D模型重组人脸并将其重新渲染, 为了让图片更加平滑逼真, 作者使用了GAN模型在公开数据集上训练再fine-tuning的方法. 本文的最大挑战在于, 人在说话时头部pose的变化可能会出现in-plane and out-of-plane头部转动, 这也是3D重组方法提出的motivation.

本文的的主要贡献在于: 1) 第一次提出可以将任意音源转化为具有个性化pose的人脸talking视频. 2) 一个memory-augmented GAN, 可以生成逼真的视频帧. 3) 需求数据很小, 300帧的目标视频数据即可生成有效的目标.
方法

模型结构如上图. 输入是一组音源A和视频源V. 模型从A中推测这段音频中的人的表情和姿势变化并形成序列. 从V中使用3D人脸重建, 获取脸的形状, 打光, 表情, 姿势等特征, 接着去掉3D人脸重建中获取的表情姿势特征(源视频中的表情肯定是不需要的), 并整合A中获取的表情和姿势(LSTM推测出来的表情才是目标视频所需的), 这样就获得了目标视频片段所期望具有的人脸信息+表情特征. 经过渲染, 模型获取了转换后的人脸, 此时的人脸还很不自然. 作者讲这些转换后的人脸送入一个GAN中进行二次渲染, 使其更为逼真.
下面详细介绍模型工作:
1 3D人脸重建
这一块作者直接用了别人的工作, Accurate 3D face reconstruction with weakly-supervised learning: From single image to image set, 这个模型应用CNN将生成的3D图像拟合到原始图片中, 保留人脸的形状, 纹理和照明. 模型最后给出一个257维的向量, 分别表示人脸的特征(80), 表情(64), 纹理(80), 照明(27), 姿势(6, 包含旋转和翻转). 然后通过PCA basis计算获得3D脸部的特征.
(大致是这样, 具体的看不懂, 以前真没接触过)
2 音频信息转化为表情和姿势
表情和姿势特征由原始的音频和3D人脸的特征联合获得. 模型提取原始音频的Mel-frequency cepstral coefficients, 梅尔频率倒谱系数, MFCC, 这是常用于语音识别的特征信息, 该特征和上文人脸的表情特征输入到经典的LSTM中, 预测每一步的表情和动作特征. 没什么特别大的创新.
3 渲染和背景匹配
3.1 渲染
渲染引擎也是用的现成的, Unsupervised training for 3D morphable model regression, 也不难理解, 图形学的东西还是得交给专业的人搞. 做法上, 从原始音频获取表情和pose, 从原始视频获取纹理和形状, 然后进行渲染. 这种渲染会导致图片不够平滑, 不像人脸. 在生成最终帧之前, 作者选择忍受这种不够自然的渲染结果. 论文也给出了获取更自然渲染结果的方法(映射到二维并为每个像素赋色), 并在general mapping中使用(不过真的有这一步吗论文到现在没怎么提).
3.2 背景匹配
前面的操作都只能生成一张脸, 而不包含头发和背景信息. 本文获取背景信息的方法比较粗暴(数据过少也是一个限制), 作者从视频中找到头部姿势最大(比如最左或最右)的帧, 称其为关键帧, 并只匹配关键帧的背景. 其他帧的背景由线性插值获得.
4 Memory-augmented GAN for refining freams
作者的主要贡献. 前面三步使用的图像渲染引擎是轻量级的, 不能获取足够真实的帧. 作者生成本文提出的GAN和之前的面部重建GAN的区别在于:
- 本模型可以处理任意目标的渲染, 而之前的工作只能针对特定人脸.
- 本模型使用数据更少, 之前的模型需要数千帧来训练网络, 本文只需要在general mapping中使用几帧, 随后在target face的生成中再使用几帧微调.
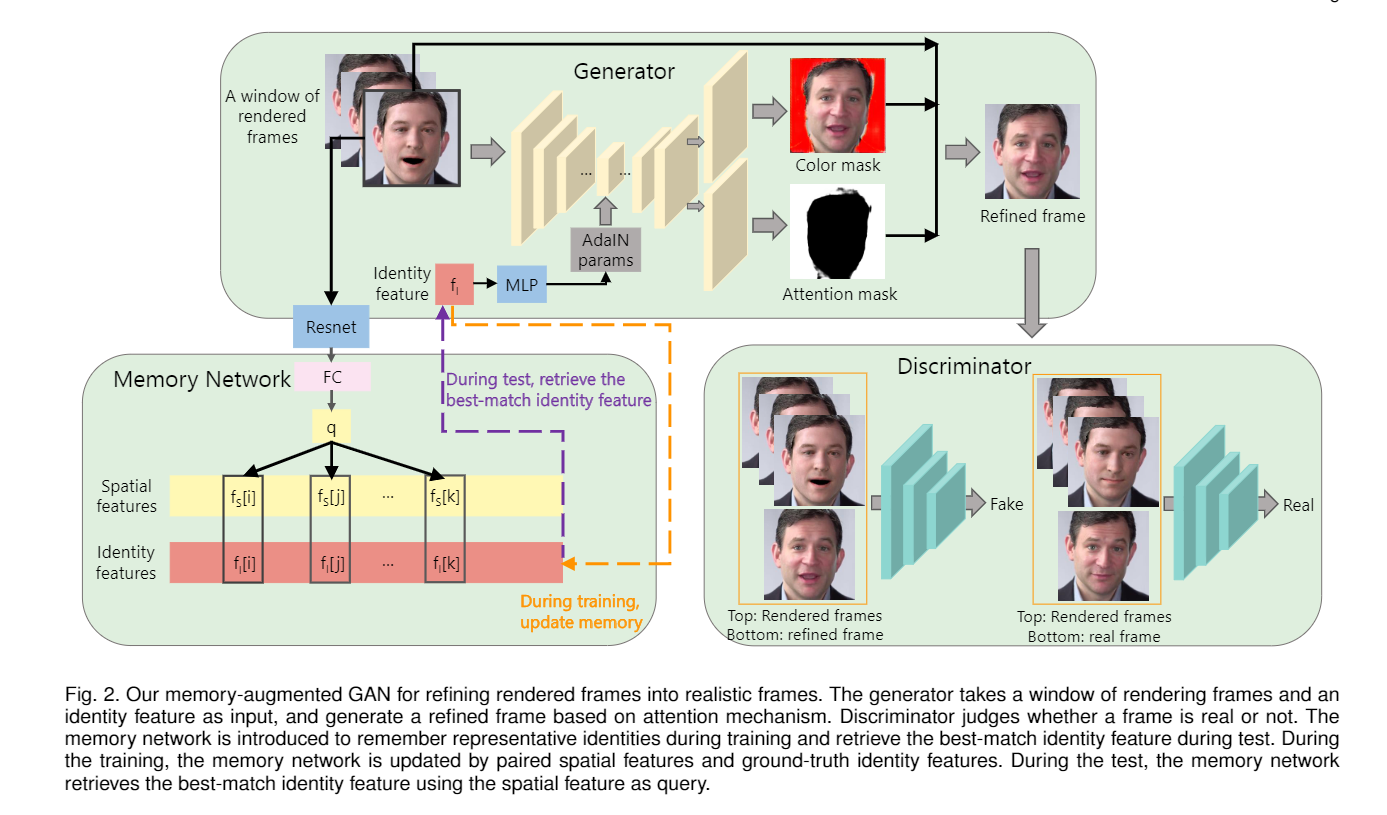
模型框架如上图. generator和discriminator, 以及一个附加的memory network.
generator负责从连续的三帧中生成refined frame, 生成方法是使用AdaIN的U-net. discriminator接受连续的三帧和refined frame或者real frame, 用以判别帧是否是生成的.
memory network存储的是成对的信息, 分别为空间特征和身份特征, 主要是记住比较有代表性的身份, 并在测试时寻找最佳匹配.
具体来说,
generator的计算公式如下:
\(r_t\)是输入的三帧中的中间帧, 也是我们希望渲染的帧. \(A_t\)和\(C_t\)是generator中U-net生成的两个mask, 这里作者将传统的U-net的最后一层改成了两个平行的层, 分别生成不同的mask. U-net在生成中使用了AdaIN参数, 这个参数来自memory network.
然后是memory network, 这个网络用来记忆人脸的身份特征, 在test中则是寻找和test样例最相似的一个身份. memory network中存储的数据成对存在, 分别较spatial feature和identity feature. spatial feature由原始的三帧经由resnet和全连接层获取. identity feature则将groundtruth放到ArcFace中获取.
成对的feature会在训练中不断更新--很好理解的, 每次训练都是三帧, 都会获取一对feature, 这些feature要么会成为memory network中的新的一对特征, 要么会替换旧的一对. 替换原则是计算cos距离, 低于阈值替换, 高于阈值更新.
loss函数为:
包含了GAN的loss, L1 loss和attention loss.
实验

总结
非常典型的任务驱动的论文, 其实模型上讲, 本文没有什么巨大创新, 但通过任务的定义, 作者有机的组合了不同领域的工具, 成果的完成了这个任务.