利用dockerc創建機器學習環境
學習機器學習以來,最讓我感到頭疼的就是環境配置:每個不同的模型可能使用完全不同的環境,並且很可能還是彼此沖突的,用conda也不能很好的管理,每次復現時候都需要很大的力氣來搭建環境,但是這樣的環境往往用了幾次就沒有了,放在機器中反而成為以后無用的累贅。此外,因為實驗室的服務器是共用的,每次使用管理員賬號都很小心,生怕一個操作改變了其他人的環境。這些問題其實都能用docker解決,特別是nvidia-docker允許在docker中使用CUDA。
docker一般服務於基於cpu 的應用,而我們的深度學習模型是跑在gpu上面的.最開始的解決方法是在容器內部安裝nvidia driver,然后通過設置相應的設備參數來啟動container,但是這樣做帶來一個弊端就是可能導致image無法共享,因為宿主機的driver的版本必須完全匹配容器內的driver版本,很可能本地機器的不一致導致每台機器都需要去重復操作,這很大的違背了docker的初衷。nvidia docker實際上是一個docker plugin,它在docker上做了一層封裝,對docker進行調用,類似一個守護進程,發現宿主機驅動文件以及gpu 設備,並且將這些掛載到來自docker守護進程的請求中,以此來支持docker gpu的使用。
https://blog.csdn.net/weixin_42749767/article/details/82934294
docker在機器學習中應用的優點:
- 真*一站式解決復現時的依賴問題,極大地提高了復現效率
- 在docker中操作不需要擔心對他人環境的改變,並且因為docker之間是隔離的,不需要擔心環境之間相互影響。
- 可以同時准備多個可用環境(caffe\pytorch\tf等),想用哪個用哪個
- docker中可以放心用管理員賬號
- docker效率損失遠小於虛擬機,性能損失不大
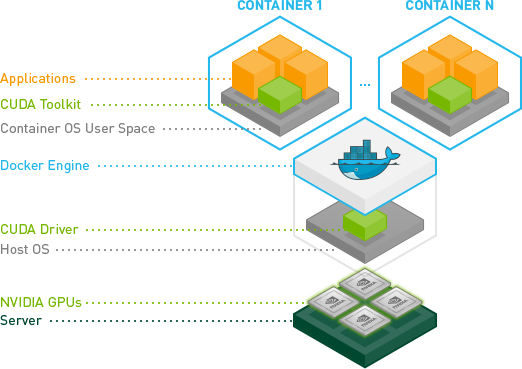
這里以一個caffe-gpu為例展示過程
安裝步驟:
-
安裝顯卡驅動和CUDA。不需要安裝CUDA Toolkit。
-
安裝docker,版本要在19.03及以上
-
# Add the package repositories distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit sudo systemctl restart docker -
此時我們就可以啟動一個示例docker鏡像了,這里還是看github上的原文指導
#### Test nvidia-smi with the latest official CUDA image docker run --gpus all nvidia/cuda:10.0-base nvidia-smi # Start a GPU enabled container on two GPUs docker run --gpus 2 nvidia/cuda:10.0-base nvidia-smi # Starting a GPU enabled container on specific GPUs docker run --gpus '"device=1,2"' nvidia/cuda:10.0-base nvidia-smi docker run --gpus '"device=UUID-ABCDEF,1"' nvidia/cuda:10.0-base nvidia-smi # Specifying a capability (graphics, compute, ...) for my container # Note this is rarely if ever used this way docker run --gpus all,capabilities=utility nvidia/cuda:10.0-base nvidia-smi-
所以,如果我們想要啟用所有的GPU,參數就填all
-
測試的鏡像要和你CUDA的版本對應,比如我的CUDA是9.0的,那么pull的鏡像就應該是nvidia/cuda:9.0-base
-
這里可以看出啟動的命令還是docker而不是nvidia-docker,之前看的一個教程上寫的是nvidia-docker,應該是舊版的,現在已經不適用了
-
-
測試程序如果沒問題的話,就可以用我們自己需要的鏡像了。這里我舉個例子:
sudo docker run --gpus all -it -v /home/jiading/Face-detection:/data --name caffeGPU bvlc/caffe:gpu /bin/bash這個命令熟悉docker的同學應該不難理解
- 我們可以使用ctrl+P+Q暫時退出容器(退出后容器依然在后台運行),然后查詢
docker ps找到容器的id,輸入docker attach <id>重新進入。對於我們配置好的環境,我們可以使用docker commit id name保存為新的容器
- 我們可以使用ctrl+P+Q暫時退出容器(退出后容器依然在后台運行),然后查詢
-
這里還要再提一個事情,就是有些鏡像為了減少體積做了許多的刪減,我見到的大多數都沒有vim,有的甚至連vi都沒有。這就給apt更新帶來了很大的問題(因為要先換源),所以沒辦法的話可以通過docker的共享文件夾將sources.list傳進去然后替換掉。此外,有可能還會遇到apt 卡在0%的情況:
產生問題的原因在於docker的容器下實在是太干凈簡潔了,很多東西都沒有,這里是因為缺少apt-transport-https包導致的,先在自己電腦上下載這個包(針對ubuntu 16.04 64位的下載地址為:http://archive.ubuntu.com/ubuntu/pool/main/a/apt/apt-transport-https_1.2.32_amd64.deb),下載好后使用dpkg -i /path/to/apt-transport-https_1.2.32_amd64.deb安裝即可。
在apt-get update可以發現問題解決了,又可以愉快的使用apt-get裝軟件了
————————————————
版權聲明:本文為CSDN博主「lhanchao」的原創文章,遵循 CC 4.0 BY-SA 版權協議,轉載請附上原文出處鏈接及本聲明。
原文鏈接:https://blog.csdn.net/lhanchao/java/article/details/104353847