- 本文首發自公眾號:RAIS,期待你的關注。
前言
本系列文章為 《Deep Learning》 讀書筆記,可以參看原書一起閱讀,效果更佳。
概率論
機器學習中,往往需要大量處理不確定量,或者是隨機量,這與我們傳統所需要解決掉問題是大不一樣的,因此我們在機器學習中往往很難給出一個百分百的預測或者判斷,基於此種原因,較大的可能性往往就是所要達到的目標,概率論有用武之地了。
概念
離散型
- 概率質量函數:是一個數值,概率,\(0\leq P(x)\leq 1\);
- 邊緣概率分布:\(P(X=x)=\sum_{y} P(X=x, Y=y)\)
- 期望:\(EX=\sum_xP(x)f(x)\)
連續型
- 概率密度函數:是一個積分,\(F_X(x)=\int_{-\infty}^xf_X(t)dt\);
- 邊緣概率分布:\(p(x)=\int p(x,y)dy\)
- 期望:\(EX=\int P(x)f(x)dx\)
條件概率
相互獨立
條件獨立
方差
標准差
協方差
相關系數
常用分布
| 分布 | 分布律或概率密度 | 期望 | 方差 |
|---|---|---|---|
| (0-1)分布 | \(P\{X=k\}=p^k(1-p)^{1-k},k=0,1\) | \(p\) | \(p(1-p)\) |
| 二項分布 | \(P\{X=k\}=\left(\begin{matrix}n\\k\end{matrix}\right)p^k(1-p)^{n-k}\) | \(np\) | \(np(1-p)\) |
| 均勻分布 | \(f(x)=\begin{cases}\frac{1}{b-1},\,\,\,\,\,a<x<b\\0,\,\,\,\,\,\,\,\,\,\,\,其他\end{cases}\) | \(\frac{a+b}{2}\) | \(\frac{(b-a)^2}{12}\) |
| 幾何分布 | \(P\{X=k\}=(1-p)^{k-1}p\) | \(\frac{1}{p}\) | \(\frac{1-p}{p^2}\) |
| 泊松分布 | \(P\{X=k\}=\frac{\lambda^ke^{-\lambda}}{k!}\) | \(\lambda\) | \(\lambda\) |
| 指數分布 | \(f(x)=\begin{cases}\frac{1}{\theta}e^{-\frac{x}{\theta}},\,\,x>0\\0,\,\,\,\,\,\,\,\,\,\,\,\,其他\end{cases}\) | \(\theta\) | \(\theta^2\) |
| 正態分布 | \(f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\) | \(\mu\) | \(\sigma^2\) |
這里需要特別說一下 正態分布,也叫 高斯分布。當我們先驗知識不足而不知道該選擇什么樣的分布時,正態分布是比較好的默認分布:第一,由 中心極限定理 知道,許多隨機變量在大量重復試驗時都會近似服從正態分布;第二,在具有相同方差的所有可能分布中,正態分布在實數上具有最大的不確定性,因此我們認為正態分布是對模型加入先驗知識最少的分布。
以上這些是大學概率論中就已經介紹過的了,下面這些是大學較少接觸的,但是在機器學習的領域是很有用的。
范疇分布(Multinoulli 分布)
范疇分布是指在具有 k 個不同狀態的單個離散型隨機變量上的分布。什么意思呢?我們對比來說這個問題:
| 分布 | 英文名 | 試驗次數 | 結果可能數 | 例子 |
|---|---|---|---|---|
| 伯努利分布 | Bernoulli distribution | 1 | 2 | 扔一次硬幣,正面向上概率 |
| 二項分布 | Binomial distribution | 多次 | 2 | 扔多次硬幣,正面向上次數 |
| 范疇分布 | Multinoulli distribution | 1 | 多個 | 扔一次骰子,3點向上概率 |
| 多項式分布 | Multinmial distribution | 多次 | 多個 | 扔3次骰子,分別為1,2,3點 |
Laplace 分布
拉普拉斯分布。與指數分布可以對比着來看,看圖:

Dirac delta 函數
狄拉克δ函數 或簡稱 δ函數,定義是在除 0 外其他點都為0,積分為 1 的函數。原點處無限高無限細,總面積為 1。

經驗分布
是統計學中一種方法,簡要概括為:用樣本估計總體,總體是未知的,我們拿到了一些樣本,用這些樣本去估計總體。不懂可以查看:這里

高斯混合模型
混合分布的定義為將一些簡單的已有的概率分布來定義新的概率分布。其中非常強大且常見的混合模型是高斯混合模型。它的混合的組件是高斯分布(正態分布)。這個話題展開來說問題太多了,不適合在本處展開,但是要記住這個問題非常重要。
常用函數有用性質
logistic sigmoid 函數
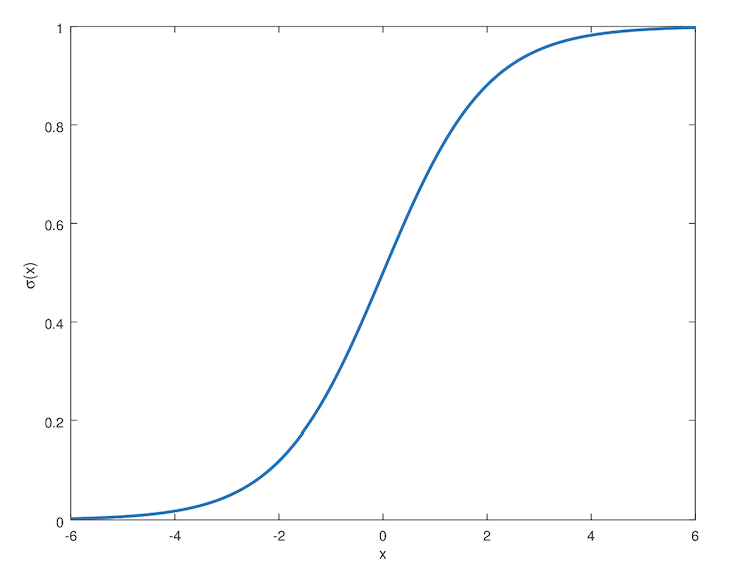
邏輯回歸函數。logistic 函數或者 sigmoid 函數對應的圖像是 sigmoid 曲線,是一條 S 形曲線。值域:(0, 1),從這里是不是就可以理解為什么我們之前的電影評論是好是壞二分類問題的最后一層激活函數用 sigmoid 了。
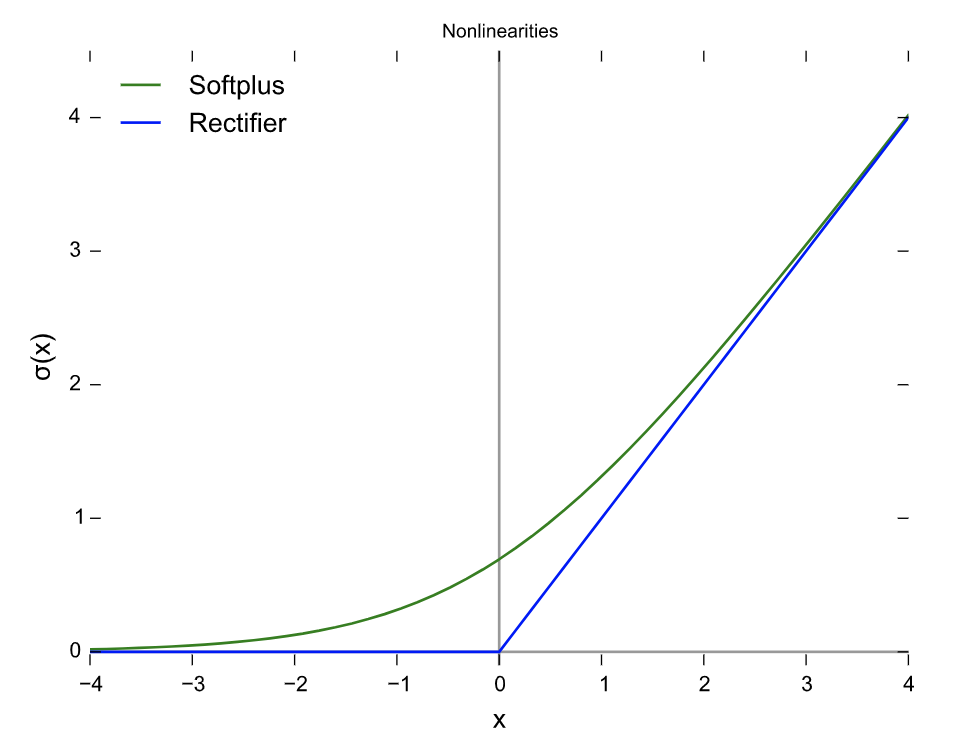
softplus 函數
值域是 0 到正無窮。它的作用是用來產生正態分布的參數,在處理 sigmoid 函數的表達式時,也會出現。
貝葉斯規則
總結
如上這些內容是《Deep Learning》中涉及到的概率論相關的知識,內容有些分散,但是要記住,日后發現弄不懂的問題可以回來查看。這一篇就到這里。
- 本文首發自公眾號:RAIS,期待你的關注。