實驗一 文法產生語言
一、實驗目的
掌握文法的表示方式,理解文法產生語言的過程,並理解有窮文法產生無窮語言。
二、實驗內容
1.文法的存儲
可以使用兩種存儲方式:程序方式和文件方式;
程序方式是指將文法的四元組固定保存在程序中, 即一個程序處理一個文法。
文件方式是指將文法的四元組用文本方式存儲,並定義格式,相應程序可以處理任意文法。
2.文法的表示
例如四元式表示:采用字符數組表示字母表和變量表,字符表示開始符號,字符串表示產生式組。(產生式符號向右箭頭沒有可以用“->”表示)
3.句子的產生
根據給定句子長度L生成所有長度不超過L的句子。
核心不詳細步驟
首先理解:文法👇:一個四元組(變量,終結字符,產生式,開始字符)

主要就是理解“遞歸”
文法產生句子的遞歸程序的框架:
寫了偽代碼,盡量通過閱讀 “每一行的代碼注釋,來理解每一行代碼內容。”
開始時,句子是 文法的開始符號
然后遞歸程序,主要就是下面三部分:
1.遞歸出口1(句子不合法時,即句子長度大於給定長度L時,結束遞歸);
2.遞歸出口2(句子長度等於L時,檢查句子合法性,如果合法輸出句子,如果不合法就繼續嘗試dfs當前句子,再結束遞歸) ;
3.遞歸核心(替換句子中的非終結符變量):使用每個非終結符變量對應的產生式,替換當前句子中的非終結符變量
看程序前,畫了個圖,可以結合代碼看👇


//調用遞歸程序
dfs(文法的開始符);
replace()//自己編寫的函數,用於把當前sentence句子中的 "非終結符變量",每次使用對應的一個產生式來替換
check()//自己編寫的函數,用於檢查這個句子是否合法(合法的判斷條件是: 當前句子不存在非終結符變量了);
//文法產生句子 "偽偽"代碼
void dfs(string sentence){
//1.遞歸出口1
if(sentence.length() > L) { //遞歸出口: 當句子的長度>L時 直接return 結束這一層遞歸,就是不往下替換非終結符了
return; //return 就是結束遞歸,返回上一層
}
//2.遞歸出口2 可能滿足我們要找的句子條件
if(sentence.length() == L){
if( check() == true ){ //check()是自己編寫的函數,用於檢查這個句子是否合法(合法的判斷條件是: 當前句子不存在非終結符變量了);
//如果滿足句子合法 執行下面語句
print(sentence)// 輸出當前的合法句子
return; //當前句子全是終結符了,無需再用非終結符替換了; 直接return 結束這一層遞歸,就是不往下替換非終結符了
}
}
//3.核心: 替換句子中的非終結符變量部分
for(int i=0;i<sentence.length();i++){ //遍歷當前的句子
if( sentence[i] 是 非終結符){
for( 遍歷sentence[i]這個變量的每一個產生式){
string newSentence = replace(sentence[i]非終結符變量,產生式右端) //把當前sentence句子中的 "非終結符變量",每次使用一個產生式來替換
dfs(newSentence) //遞歸新的句子
}
}
}
}
下面正式寫代碼了
##1-1.文法存儲,面向對象編程,Grammer類 ###其實不需要按照我這樣,只使用數組存儲,也可以的;使用集合、map映射是為了在查找的時候更加簡便;如果只用數組存就只能暴力的遍歷查找不優雅。 Java中遍歷集合的方法(List集合、Set集合和Map集合) 使用set集合(HashSet)存儲“變量集合” 使用set集合(HashSet)存儲“終結符集合” 使用map雙列映射(HashMap)存儲(產生式左端,產生式右端的集合)映射。“ (key:value)鍵值對,其中‘產生式左端’是key,產生式右端的集合是‘value’ ” 代碼如下👇 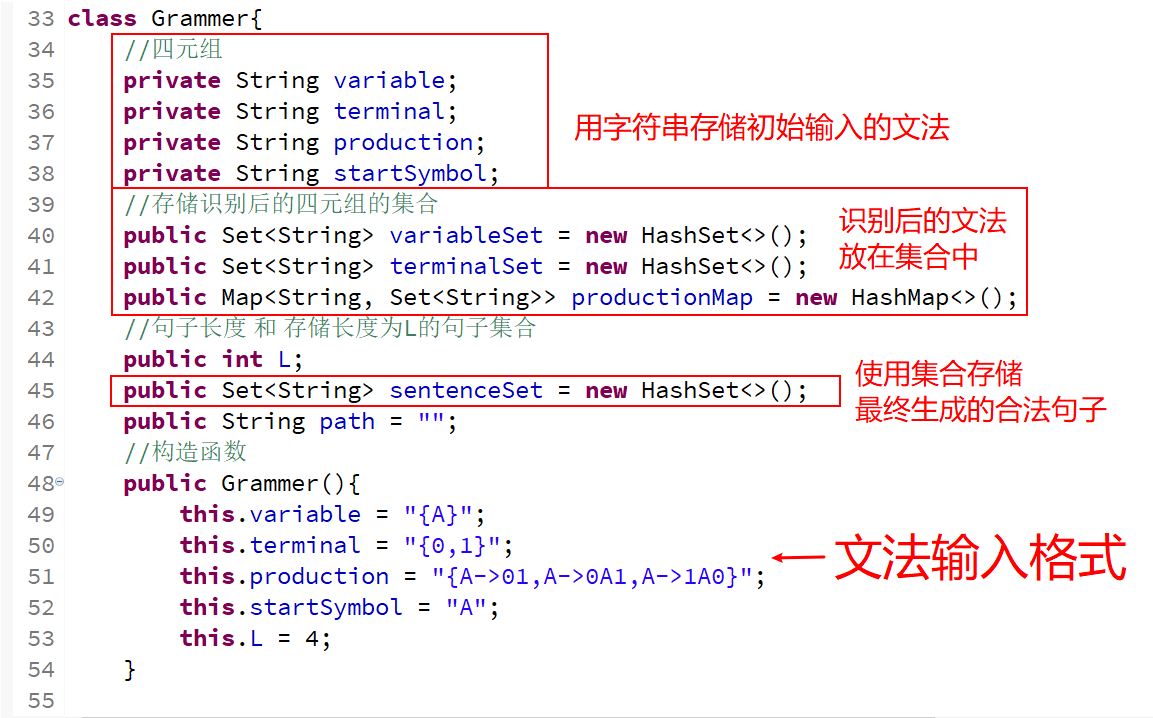
1-2.程序方式初始化文法(固定文法產生句子)
一個程序處理一個文法,用一個固定的文法產生長度為L的句子
隨便選一個固定的文法四元組。
可以看下面代碼,一個函數對應一個文法,就是在這個函數中構造好它的四元組

1-3.文法遞歸產生句子
同上述,文法遞歸程序的框架。
👇

run函數,初始化句子參數是 “文法的開始符號”

##1-4.輸出所有合法的句子

主函數運行:👇

2-1.從文件中讀入文法
路徑👇

文件格式👇

從文件加載文法代碼👇

2-2.文法識別,從文件中加載文法
給出的是4元組,需要把變量、終結符、產生式、開始符這些字符串給區分出來
以,{ -> 這些字符來把變量、終結符、產生式分隔


變量識別👇

終結符識別👇

產生式識別👇,集合映射表hashMap,使得每一個產生式左端變量,對應一個產生式右端集合


##2-3.文法合法性檢測(可省略) 1.檢查產生式左端每一個字符是否都是 “當前文法的,非終結符變量集合的字符”; 2.檢查產生式右端每一個字符是否都是 “當前文法的,非終結符變量集合 U 終結符變量集合” 代碼如下👇

##2-4.文法遞歸產生句子 同上述,文法遞歸程序的框架。 👇
2-5.輸出所有合法的句子
首先面向對象編程,編寫Grammer文法類
然后從程序中固定的手動構造四元組,或者從文件讀入文法字符串,
然后識別文法,
最后核心就是上面的“文法遞歸程序的框架”。