我要把人生變成科學的夢,然后再把夢變成現實。——居里夫人
概述
關鍵詞是代表文章重要內容的一組詞,在文獻檢索、自動文摘、文本聚類/分類等方面有着重要的應用。現實中大量的文本不包含關鍵詞,這使得便捷得獲取文本信息更困難,所以自動提取關鍵詞技術具有重要的價值和意義。
關鍵詞提取分類
- 有監督
- 無監督
有監督雖然精度高,但需要維護一個內容豐富的詞表,需要大量的標注數據,人工成本過高。
無監督不需要標注數據,因此這類算法在關鍵詞提取領域應用更多。比如TF-IDF算法、TextRank算法和主題模型LDA算法等。
TF-IDF算法
TF-IDF(Term Frequency - Inverse Document Frequency)是一種基於統計的計算方法,常用於反映一個詞對於語料中某篇文檔的重要性。
TF是詞頻(Term Frequency),IDF是逆文本頻率指數(Inverse Document Frequency)。TF-IDF 的主要思想就是:如果某個詞在一篇文檔中出現的頻率高,也即 TF 高;並且在語料庫中其他文檔中很少出現,即DF低,也即IDF高,則認為這個詞具有很好的類別區分能力。
TF 為詞頻(Term Frequency),表示詞 t 在文檔 d 中出現的頻率,計算公式:
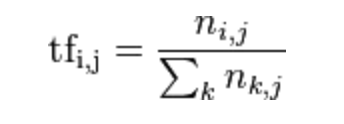
其中,分子是該詞在文件中的出現次數,而分母則是在文件中所有字詞的出現次數之和。
IDF 為逆文檔頻率(Inverse Document Frequency),表示語料庫中包含詞 t 的文檔的數目的倒數,計算公式:

其中,|D|:語料庫中的文件總數,|{j:ti∈dj}| 包含詞 ti 的文件數目,如果該詞語不在語料庫中,就會導致被除數為零,因此一般情況下使用 1+|{j:ti∈dj}|。
然后再計算TF與IDF的乘積:

因此,TF-IDF傾向於過濾掉常見的詞語,保留重要的詞語。比如:有些詞“的”,“了”,“地”等出現在每篇文章中都比較多,但是不具有區分文章類別的能力。
TextRank算法
TextRank算法脫離語料庫,僅對單篇文檔進行分析就可以提取該文檔的關鍵詞,此算法最早應用於文檔的自動摘要,基於句子維度的分析,利用TextRank對每個句子進行打分,挑選出分數最高的n個句子作為文檔的關鍵句,以達到自動摘要的效果。
TextRank基本思想來源於Google創始人拉里·佩奇和謝爾蓋·布林1997年構建的PageRank算法。核心思想將文本中的詞看作圖中的節點,通過邊相互連接,這里就形成了圖,不同的節點會有不同的權重,權重高的節點可以作為關鍵詞。
PageRank思想:
- 鏈接數量。一個網頁被越多的其他網頁鏈接,說明這個網頁越重要。
- 鏈接質量。一個網頁被一個越高權重的網頁鏈接,也能表明這個網頁越重要。
TextRank用PageRank的思想來解釋它:
- 一個單詞被很多單詞指向的話,則說明這個單詞比較重要。
- 一個單詞被很高TextRank值的單詞指向,則這個單詞的TextRank值會相應地提高。
公式如下:
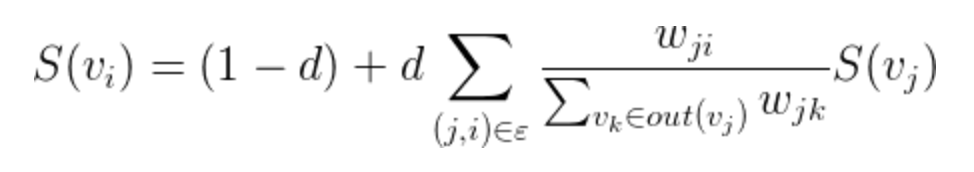
TextRank中一個單詞i的權重取決於在i相連的各個點j組成的(j,i)這條邊的權重,以及j這個點到其他邊的權重之和,阻尼系數 d 一般取 0.85。
TextRank關鍵詞提取步驟:
- 把給定的文本按照完整句子進行分割。
- 對每個句子,進行分詞和詞性標注處理,並過濾掉停用詞,只保留指定詞性的單詞,如名詞、動詞等。
- 構建關鍵詞圖 G = (V,E),其中V 為節點集,由步驟2中生成的候選關鍵詞組成,然后采用共現關系構造任兩點之間的邊,兩個節點之間存在邊僅當它們對應的詞匯在長度為 K 的窗口中共現,K 表示窗口大小。
- 根據TextRank公式,迭代收斂,選出權重topK個詞為關鍵詞。
- 由步驟4得到最重要的k個單詞,在原始文本中進行標記,若形成相鄰詞組,則組合成多詞關鍵詞。
基於 LDA 主題模型進行關鍵詞提取
大多數情況,TF-IDF算法和TextRank算法就能滿足,但某些場景不能從字面意思提取出關鍵詞,比如:一篇講健康飲食的,里面介紹了各種水果、蔬菜等對身體的好處,但全篇未顯式的出現健康二字,這種情況前面的兩種算法顯然不能提取出健康這個隱含的主題信息,這時候主題模型就派上用場了。
LDA(隱含狄利克雷分布)是由David Blei等人在2003年提出的,理論基礎為貝葉斯理論,LDA根據詞的共現信息的分析,擬合出詞——文檔——主題的分布,進而將詞、文本都映射到一個語義空間中。
實戰
- jieba 已經實現了基於 TF-IDF 算法的關鍵詞抽取,如下:
import jieba.analyse
text = '城市綠化是栽種植物以改善城市環境的活動。 城市綠化作為城市生態系統中的還原組織 城市生態系統具有受到外來干擾和破壞而恢復原狀的能力,就是通常所說的城市生態系統的還原功能。'
#獲取關鍵詞
tags = jieba.analyse.extract_tags(text, topK=3)
print(u"關鍵詞:")
print(" ".join(tags))
執行結果:
關鍵詞:
生態系統 城市綠化 城市
- jieba也已經實現了基於 TextRank算法的關鍵詞抽取,如下:
import jieba.analyse
text = '城市綠化是栽種植物以改善城市環境的活動。 城市綠化作為城市生態系統中的還原組織 城市生態系統具有受到外來干擾和破壞而恢復原狀的能力,就是通常所說的城市生態系統的還原功能。'
result = " ".join(jieba.analyse.textrank(text, topK=3, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')))
print(u"關鍵詞:")
print(result)
執行結果:
關鍵詞:
城市 破壞 還原
- 通過 Gensim 庫完成基於 LDA 的關鍵字提取,如下:
import jieba
import jieba.analyse as analyse
import gensim
from gensim import corpora, models, similarities
text = '城市綠化是栽種植物以改善城市環境的活動。 城市綠化作為城市生態系統中的還原組織 城市生態系統具有受到外來干擾和破壞而恢復原狀的能力,就是通常所說的城市生態系統的還原功能。'
# 停用詞
stop_word = ['的', '。', '是', ' ']
# 分詞
sentences=[]
segs=jieba.lcut(text)
segs = list(filter(lambda x:x not in stop_word, segs))
sentences.append(segs)
# 構建詞袋模型
dictionary = corpora.Dictionary(sentences)
corpus = [dictionary.doc2bow(sentence) for sentence in sentences]
# lda模型,num_topics是主題的個數
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=8)
print(lda.print_topic(1, topn=3))
執行結果:
0.037*"城市" + 0.037*"城市綠化" + 0.037*"生態系統"
