✓ 詞向量
✗Adam,sgd
✗ 梯度消失和梯度爆炸
✗初始化的方法
✗ 過擬合&欠擬合
✗ 評價&損失函數的說明
✗ 深度學習模型及常用任務說明
✗ RNN的時間復雜度
✗ neo4j圖數據庫
分詞、詞向量

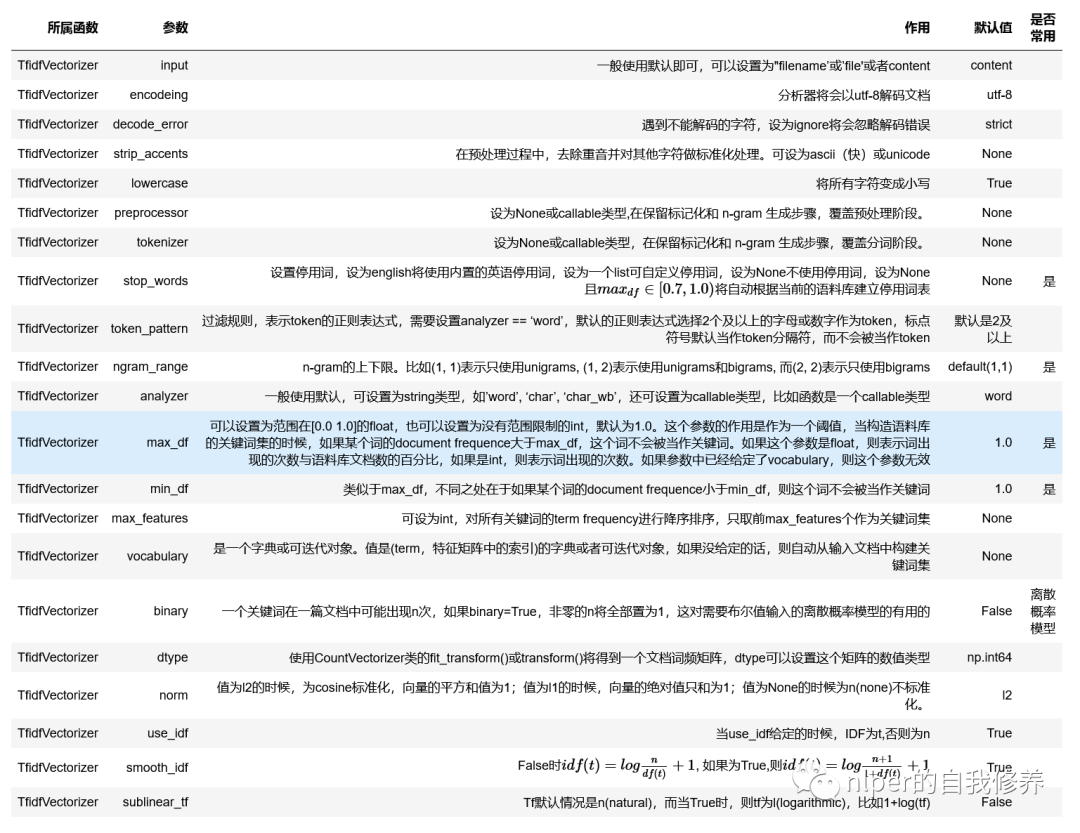
TfidfVectorizer
基本介紹
-
TF-IDF是一種統計方法,用以評估一字詞對於一個文件集或一個語料庫中的其中一份文件的重要程度。字詞的重要性隨着它在文件中出現的次數成正比增加,但同時會隨着它在語料庫中出現的頻率成反比下降。
-
比如:為了獲得一篇文檔的關鍵詞,我們可以如下進行
-
對給定文檔,我們進行"詞頻"(Term Frequency,縮寫為TF)
-
給每個詞計算一個權重,這個權重叫做"逆文檔頻率"(Inverse Document Frequency,縮寫為IDF),它的大小與一個詞的常見程度成反比。
算法明細
-
基本步驟
-
1、計算詞頻。考慮到文章有長短之分,為了便於不同文章的比較,進行"詞頻"標准化。 詞頻:TF = 文章中某詞出現的頻數 詞頻標准化:

-
2、計算逆文檔頻率。如果一個詞越常見,那么分母就越大,逆文檔頻率就越小越接近0。 逆文檔頻率:
 其中,語料庫(corpus),是用來模擬語言的使用環境。
其中,語料庫(corpus),是用來模擬語言的使用環境。 -
3、計算TF-IDF。可以看到,TF-IDF與一個詞在文檔中的出現次數成正比,與該詞在整個語言中的出現次數成反比 $TF-IDF = TF * IDF$
-
算法優缺點
-
優點:
-
TF-IDF算法的優點是簡單快速,結果比較符合實際情況。
-
-
缺點
-
單純以"詞頻"衡量一個詞的重要性,不夠全面,有時重要的詞可能出現次數並不多。
-
這種算法無法體現詞的位置信息,出現位置靠前的詞與出現位置靠后的詞,都被視為重要性相同,這是不正確的。
-
對於文檔中出現次數較少的重要人名、地名信息提取效果不佳
-
應用場景
-
應用場景簡介
-
1)搜索引擎;
-
2)關鍵詞提取;
-
3)文本相似性;
-
4)文本摘要
-
可執行實例
# python:3.8
# sklearn:0.23.1
# 1、CountVectorizer 的作用是將文本文檔轉換為計數的稀疏矩陣
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
# 查看每個單詞的位置
print(vectorizer.get_feature_names())
#['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
# 查看結果
print(X.toarray())
# [[0 1 1 1 0 0 1 0 1]
# [0 2 0 1 0 1 1 0 1]
# [1 0 0 1 1 0 1 1 1]
# [0 1 1 1 0 0 1 0 1]]
# 2、TfidfTransformer:使用計算 tf-idf
from sklearn.feature_extraction.text import TfidfTransformer
transform = TfidfTransformer()
Y = transform.fit_transform(X)
print(Y.toarray()) # 輸出tfidf的值
# [[0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]
# [0. 0.6876236 0. 0.28108867 0. 0.53864762 0.28108867 0. 0.28108867]
# [0.51184851 0. 0. 0.26710379 0.51184851 0. 0.26710379 0.51184851 0.26710379]
# [0. 0.46979139 0.58028582 0.38408524 0. 0. 0.38408524 0. 0.38408524]]
# 3、TfidfVectorizer:TfidfVectorizer 相當於 CountVectorizer 和 TfidfTransformer 的結合使用
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer() #構建一個計算詞頻(TF)
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
# ['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
print(X.shape)
# (4, 9)
參數項說明

-
TfidfTransformer

-
從函數上來看,咱也可以發現有TfidfVectorizer=CountVectorizer + TfidfTransformer哈
-
TfidfVectorizer