AIOps探索:基於VAE模型的周期性KPI異常檢測方法
作者:林錦進
前言
在智能運維領域中,由於缺少異常樣本,有監督方法的使用場景受限。因此,如何利用無監督方法對海量KPI進行異常檢測是我們在智能運維領域探索的方向之一。最近學習了清華裴丹團隊發表在WWW 2018會議上提出利用VAE模型進行周期性KPI無監督異常檢測的論文:《Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications 》[1](以下簡稱為Dount)。基於Dount論文的學習,本文將介紹如何使用Keras庫,實現基於VAE模型的周期性KPI異常檢測方法,包括其思路、原理與代碼實現,幫助大家理解這個方法。
背景介紹:
在AI in All的時代,工業界中的運維領域提出了:智能運維(AIOps, Artificial Intelligence for IT Operations)這個概念,即采用機器學習、數據挖掘或深度學習等方法,來解決KPI異常檢測、故障根因分析、容量預測等運維領域中的關鍵問題。
其中KPI異常檢測是在運維領域中非常重要的一個環節。KPI(key performance indicators)指的是對服務、系統等運維對象的監控指標(如延遲、吞吐量等)。其存儲的形式是按其發生的時間先后順序排列而成的數列,也就是我們通常所說的時間序列。從運維的角度來看,存在多種不同類型的KPI,周期性KPI是其中一種典型的KPI,其特點表現為具有周期性,如下圖:
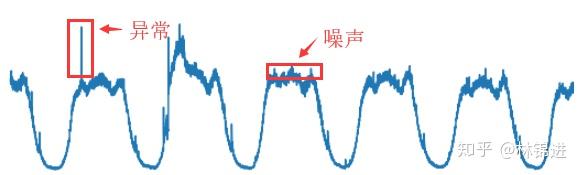
要進行KPI異常檢測,首先我們要定義一下什么是異常。如上圖所示,我們將KPI的異常點定義為超過期望值一定范圍的點,而在期望值的小范圍內波動的點我們將其認為是噪聲。對周期性KPI的異常檢測在工業界和學術界已有不少探索,本文將介紹基於深度學習模型VAE的無監督周期性KPI異常檢測方法。
正文:
- AutoEncoder
因為VAE跟AutoEncoder在網絡整體結構上相似,都分為Encoder和Decoder模型,那么在了解VAE之前,我們先了解什么是AutoEncoder模型。
AutoEncoder的意思是自編碼器,這個模型主要由兩個部分組成:encoder和decoder,可以把它理解為兩個函數:z = encoder(x), x = decoder(z)。在AutoEncoder模型的思想中,我們期望能夠利用encoder模型,將我們的輸入X轉換到一個對應的z,利用decoder模型,我們能夠將z還原為原來的x,可以把AutoEncoder理解為有損的壓縮與解壓。
AutoEncoder模型有什么用呢?有兩個主要功能:
- 降噪
- 將高緯的特征轉為低緯度的特征(從X到z)。
要實現一個AutoEncoder其實非常簡單(其實就是單個隱藏層的神經網絡),有接觸過深度學習的人應該都可以理解:
input = Input(shape=(seq_len,)) encoded = Dense(encoding_dim, activation='relu')(input) decoded = Dense(seq_len)(encoded) autoencoder = Model(input, decoded) 我們先來考慮一下能否用AutoEncoder進行KPI異常檢測,以及它有什么缺點。因為AutoEncoder具有降噪的功能,那它理論上也有過濾異常點的能力,因此我們可以考慮是否可以用AutoEncoder對原始輸入進行重構,將重構后的結果與原始輸入進行對比,在某些點上相差特別大的話,我們可以認為原始輸入在這個時間點上是一個異常點。
下面是一個簡單的實驗結果展示,我們訓練了一個輸入層X的維度設置為180(1分鍾1個點,3小時數據),Z的維度設置為5(可以理解為原始輸入降維后表達),輸出成X的維度設置為180的AutoEncoder模型,並且測試集的數據進行重構(滑動窗口形式,每次重構后只記錄最后一個點,然后窗口滑動到下一個時間點),能夠得到以下結果:
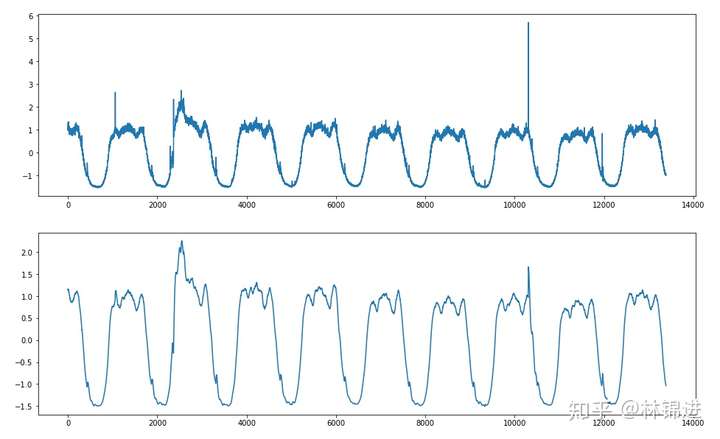
- 基於AutoEncoder的周期性KPI異常檢測:
上面提到,AutoEncoder具有降噪功能,那它怎么降噪呢?這里簡單舉一個例子:假設我們現在訓練出來的模型可以得到這樣的映射關系[1, 2](X)->[1](z)->[1 ,2]X_r, 其中[1, 2]表示二維向量, [1]表示一維向量,X_r表示重構后的X。這個例子表示了一個理想的AutoEncoder模型,它能將[1,2]降維到[1], 並且能從[1]重構為[1,2]。接下來,假設我們的輸入為[1, 2.1],其中第二維度的0.1表示一個噪聲,將其輸入到encoder部分后得到的Z為[1],並且重構后得到的X_r是[1, 2], 這也就達到了一個對原始輸入去噪的作用。
而我們的當前的目標是進行KPI異常檢測,從上圖可以看到,一些肉眼可見的異常在重構后被去除掉了(類似降噪了),通過對比與原始輸入的差距,我們可以判斷是否為異常。
然而,AutoEncoder模型本身沒有什么多少正則化手段,容易過擬合,當訓練數據存在較多異常點的時候,可能模型的效果就不會特別好,而我們要做的是無監督異常檢測(要是有label的話就用有監督模型了),因此我們的場景是訓練的時候允許數據存在少量異常值的,但當異常值占比較大的話,AutoEncoder可能會過擬合(學習到異常模式)。
- Variational AutoEncoder(VAE)
接下來介紹一些VAE模型,如果不需要對VAE有比較清楚的了解,也可以直接跳過這部分內容。
對於VAE模型的基本思想,下面內容主要引用自我覺得講得比較清楚的一篇知乎文章,並根據我的理解將文中一些地方進行修改,保留核心部分,這里假設讀者知道判別模型與生成模型的相關概念。
原文地址:https://zhuanlan.zhihu.com/p/27865705
VAE 跟傳統 AutoEncoder關系並不大,只是思想及架構上也有 Encoder 和 Decoder 兩個結構而已。VAE 理論涉及到的主要背景知識包括:隱變量(Latent Variable Models)、變分推理(Variational Inference)、Reparameterization Trick 等等。
首先,先定義問題:我們希望學習出一個生成模型,能產生訓練樣本中沒有,但與訓練集相似的數據。換一種說法,對於樣本空間  ,當以
,當以  抽取數據時,我們希望以較高概率抽取到與訓練樣本近似的數據。對於手寫數字的場景,則表現為生成像手寫數字的圖像。對於數據
抽取數據時,我們希望以較高概率抽取到與訓練樣本近似的數據。對於手寫數字的場景,則表現為生成像手寫數字的圖像。對於數據  的產生,我們假設它受一些隱含因素的影響,即隱變量(Latent Variables),寫作
的產生,我們假設它受一些隱含因素的影響,即隱變量(Latent Variables),寫作  ,並且假設
,並且假設  服從標准正態分布
服從標准正態分布  。則原來對 建模轉為對
。則原來對 建模轉為對  進行建模,同時有
進行建模,同時有

接下來我們可以開始解決最大化 的問題,如果我們知道 的分布,我們就可以利用采樣來計算積分,即
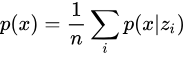
我們發現,當  時,對估計 沒有幫助,所以其實我們只需要采樣那些對 有貢獻的 。此時,可以反過來求
時,對估計 沒有幫助,所以其實我們只需要采樣那些對 有貢獻的 。此時,可以反過來求  ,然而,是intractable的,VAE中利用Variational Inference,引入
,然而,是intractable的,VAE中利用Variational Inference,引入  分布來近似。
分布來近似。
最終,可以得到需要優化的目標 ELBO(Evidence Lower Bound),此處其定義為

其中,第一項是我們希望最大化的目標;第二項是在數據 下真實分布  與假想分布
與假想分布  的距離,當 的選擇合理時此項會接近為0。但公式中仍然含有intractable的
的距離,當 的選擇合理時此項會接近為0。但公式中仍然含有intractable的  ,於是將其化簡后得到
,於是將其化簡后得到
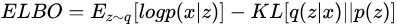
於是,對於某個樣本  ,其損失函數可以表示為,每次輸入為一個xi,
,其損失函數可以表示為,每次輸入為一個xi,
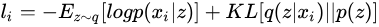
其中,  意味着在樣本 下隱變量 的分布,對應於AutoEncoder中的Encoder部分;
意味着在樣本 下隱變量 的分布,對應於AutoEncoder中的Encoder部分;  意味着將隱變量 恢復成 ,對應着 Decoder。於是,VAE 的結構可以表示為
意味着將隱變量 恢復成 ,對應着 Decoder。於是,VAE 的結構可以表示為
但是,上面這種方式需要在前向傳播時進行采樣,而這種采樣操作是無法進行后向反饋梯度的。於是,作者提出一種“Reparameterization Trick”:將對 采樣的操作移到輸入層進行。於是就有了下面的VAE最終形式
采樣的操作移到輸入層進行。於是就有了下面的VAE最終形式
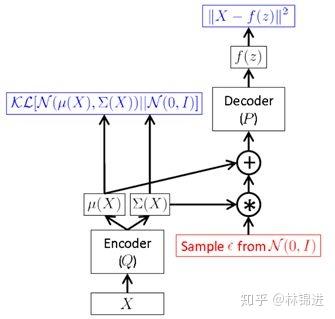
采樣時,先對輸入的 進行采樣,然后計算
進行采樣,然后計算 ,間接對 采樣。
,間接對 采樣。
我們再結合兩個圖梳理一下VAE的過程。
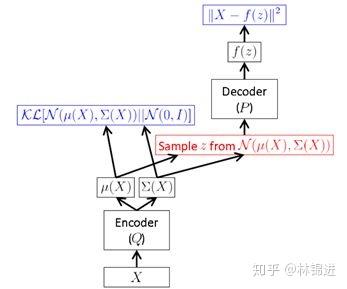
下圖表示了VAE整個過程。即首先通過Encoder 得到 的隱變量分布參數;然后采樣得到隱變量 。接下來按公式,應該是利用 Decoder 求得 的分布參數,而實際中一般就直接利用隱變量恢復 。

下圖展示了一個具有3個隱變量的 VAE 結構示意圖。
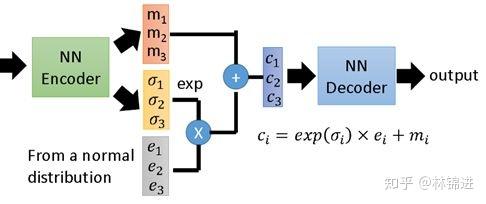
- 基於VAE的周期性KPI異常檢測
上面介紹了VAE的原理,看起來很復雜,其實最終VAE也實現了跟AutoEncoder類似的作用,輸入一個序列,得到一個隱變量(從隱變量的分布中采樣得到),然后將隱變量重構成原始輸入。不同的是,VAE學習到的是隱變量的分布(允許隱變量存在一定的噪聲和隨機性),因此可以具有類似正則化防止過擬合的作用。
以下的構建一個VAE模型的keras代碼,修改自keras的example代碼,具體參數參考了Dount論文:
def sampling(args): """Reparameterization trick by sampling fr an isotropic unit Gaussian. # Arguments: args (tensor): mean and log of variance of Q(z|X) # Returns: z (tensor): sampled latent vector """ z_mean, z_log_var = args batch = K.shape(z_mean)[0] dim = K.int_shape(z_mean)[1] # by default, random_normal has mean=0 and std=1.0 epsilon = K.random_normal(shape=(batch, dim)) std_epsilon = 1e-4 return z_mean + (z_log_var + std_epsilon) * epsilon input_shape = (seq_len,) intermediate_dim = 100 latent_dim = latent_dim # VAE model = encoder + decoder # build encoder model inputs = Input(shape=input_shape, name='encoder_input') x = Dense(intermediate_dim, activation='relu', kernel_regularizer=regularizers.l2(0.001))(inputs) x = Dense(intermediate_dim, activation='relu', kernel_regularizer=regularizers.l2(0.001))(x) z_mean = Dense(latent_dim, name='z_mean')(x) z_log_var = Dense(latent_dim, name='z_log_var', activation='softplus')(x) # use reparameterization trick to push the sampling out as input # note that "output_shape" isn't necessary with the TensorFlow backend z = Lambda(sampling, output_shape=(latent_dim,), name='z')([z_mean, z_log_var]) # build decoder model x = Dense(intermediate_dim, activation='relu', kernel_regularizer=regularizers.l2(0.001))(z) x = Dense(intermediate_dim, activation='relu', kernel_regularizer=regularizers.l2(0.001))(x) x_mean = Dense(seq_len, name='x_mean')(x) x_log_var = Dense(seq_len, name='x_log_var', activation='softplus')(x) outputs = Lambda(sampling, output_shape=(seq_len,), name='x')([x_mean, x_log_var]) vae = Model(inputs, outputs, name='vae_mlp') # add loss reconstruction_loss = mean_squared_error(inputs, outputs) reconstruction_loss *= seq_len kl_loss = 1 + z_log_var - K.square(z_mean) - K.exp(z_log_var) kl_loss = K.sum(kl_loss, axis=-1) kl_loss *= -0.5 vae_loss = K.mean(reconstruction_loss + kl_loss) vae.add_loss(vae_loss) vae.compile(optimizer='adam') 基於VAE的周期性KPI異常檢測方法其實跟AutoEncoder基本一致,可以使用重構誤差來判斷異常,來下面是結果,上圖是原始輸入,下圖是重構結果,我們能夠看到VAE重構的結果比AutoEncoder的更好一些。

缺陷:
基於AutoEncoder和VAE模型在工業界上的使用面臨的2個最大問題是:
- 理論上它只能對一個KPI訓練單獨一個模型,不同類型的KPI需要使用不同的模型,為了解決這個問題,裴丹團隊后面又發表了一篇關於KPI聚類的論文《Robust and Rapid Clustering of KPIs for Large-Scale Anomaly Detection》,先對不同的KPI進行模板提取,然后進行聚類,對每個類訓練單獨一個模型。
- 需要設置異常閾值。因為我們檢測異常是通過對比重構后的結果與原始輸入的差距,而這個差距多少就算是異常需要人為定義,然而對於大量的不同類型的KPI,我們很難去統一設置閾值,這也是采用VAE模型比較大的一個缺陷。雖然在Dount論文中,采用的是重構概率而不是重構誤差來判斷異常,然而重構概率也需要設置閾值才能得到比較精確的結果。
總結
本文分別介紹了AutoEncoder和VAE模型以及基於這些模型的周期性KPI異常檢測方法。裴丹的論文Dount中對原始的VAE做了一些改進,針對KPI異常檢測這個場景增加了一些細節上的優化,如missing data injection、MCMC等等,這部分細節就不在本文中討論了,有興趣的同學可以看一下他們的開源代碼 haowen-xu/donut。
最后,為了讓對AIOps有興趣的同學能夠交流與學習,我創建了一個Awesome-AIOps的倉庫,匯總一些AIOps相關的學習資料、算法/工具庫等等,歡迎大家進行一起補充,互相進步。
linjinjin123/awesome-AIOpsgithub.com
如果文中有什么解釋不清或者說錯的地方,歡迎批評指正。
參考文獻
[1] Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications
[2] https://blog.keras.io/building-autoencoders-in-keras.html
[3] 當我們在談論 Deep Learning:AutoEncoder 及其相關模型