本文始發於:https://www.cnblogs.com/wildmelon/p/16159189.html
一、前言
本文為常見的以圖作為數據結構的尋路算法筆記,再次推薦該文章:
https://www.redblobgames.com/pathfinding/a-star/introduction.html
既有可交互的可視化界面,又有由淺到深的尋路算法講解。
二、廣度優先搜索(BFS)
廣度優先搜索的循環,是所有尋路算法(基於圖節點)的關鍵。實際上會從起點開始,像在 Minecraft 游戲里倒一桶水般蔓延開來,遍歷到圖中的每個節點:
// 待搜索隊列
Queue<TileNode> frontier = new Queue<TileNode>();
// 已搜索節點
HashSet<TileNode> reached = new HashSet<TileNode>();
// 從起點開始
TileNode start = TotalTileModels[character.cellPosition];
frontier.Enqueue(start);
reached.Add(start);
// 遍歷搜索上下左右的鄰節點
while (frontier.Count != 0)
{
TileNode current = frontier.Dequeue();
foreach (TileNode neighbor in current.neighbors)
{
if (!reached.Contains(neighbor))
{
frontier.Enqueue(neighbor);
reached.Add(neighbor);
}
}
}
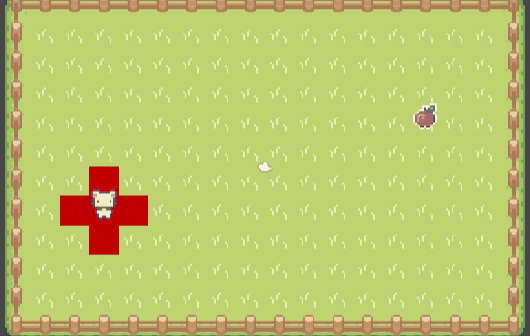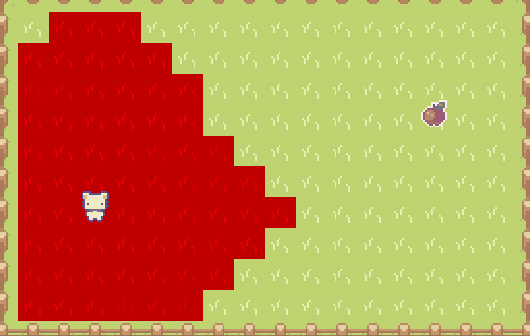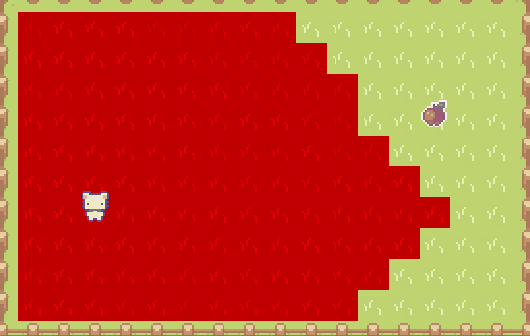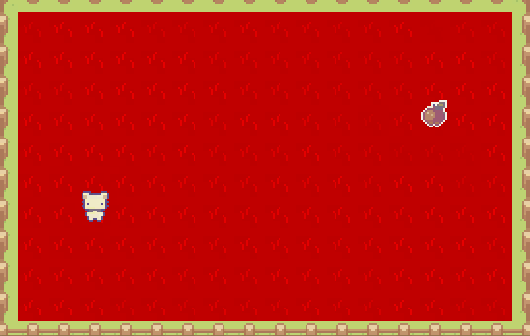
如果需要找到路徑,則用字典記錄每個節點的“父節點”,找到目的地之后,從尾節點向上返回到起點:
private void BFS()
{
Queue<TileNode> frontier = new Queue<TileNode>();
// 若 cameFrom[B]=A,說明B的上一節點為A,B是在A的鄰居中找到的
Dictionary<TileNode, TileNode> cameFrom = new Dictionary<TileNode, TileNode>();
TileNode start = TotalTileModels[character.cellPosition];
TileNode target = TotalTileModels[destination.cellPosition];
frontier.Enqueue(start);
cameFrom.Add(start, null);
while (frontier.Count != 0)
{
TileNode current = frontier.Dequeue();
foreach (TileNode neighbor in current.neighbors)
{
if (!cameFrom.ContainsKey(neighbor))
{
frontier.Enqueue(neighbor);
cameFrom.Add(neighbor, current);
// 找到目標,提前退出
if (neighbor == target) break;
}
}
}
TileNode link = target;
while (cameFrom[link] != null)
{
path.Add(link);
link = cameFrom[link];
}
path.reverse();
}
如果 path 為空,即字典 cameFrom 不存在 target。則說明沒有從終點返回起點的路徑。
三、Dijkstra 算法
廣度優先搜索對於所有的節點采取一視同仁的態度,但許多游戲都存在地形的概念,如沙漠、森林等地點可能會消耗更多的步行時間。
此時我們引入成本記錄跟蹤,來得到 Dijkstra 算法,為了在待搜索節點中先計算當前成本最低的節點,需使用優先級隊列:
private void Dijkstra()
{
// 優先級隊列
PriorityQueue frontier = new PriorityQueue();
Dictionary<TileNode, TileNode> cameFrom = new Dictionary<TileNode, TileNode>();
// 當前節點已消耗的成本
Dictionary<TileNode, int> costSoFar = new Dictionary<TileNode, int>();
TileNode start = TotalTileModels[character.cellPosition];
TileNode target = TotalTileModels[destination.cellPosition];
// 從起點開始搜索
frontier.Push(start, 0);
costSoFar.Add(start, 0);
cameFrom.Add(start, null);
while (frontier.GetCount() != 0)
{
TileNode current = (TileNode)frontier.Out();
// 到達目標,提前退出
if (current == target) break;
foreach (TileNode neighbor in current.neighbors)
{
int newCost = costSoFar[current] + neighbor.cost;
// 未計算過該節點,或有新成本更低的路徑時,才進行計算
if (!costSoFar.ContainsKey(neighbor) || newCost < costSoFar[neighbor])
{
frontier.Push(neighbor, newCost);
costSoFar[neighbor] = newCost;
cameFrom.Add(neighbor, current);
mClickableTilemap.mTilemap.SetColor(neighbor.position, Color.blue);
}
}
}
while (cameFrom[target] != null)
{
mClickableTilemap.mTilemap.SetColor(target.position, Color.red);
target = cameFrom[target];
}
}
Dijkstra 算法,會跳過中間消耗更高的水路:
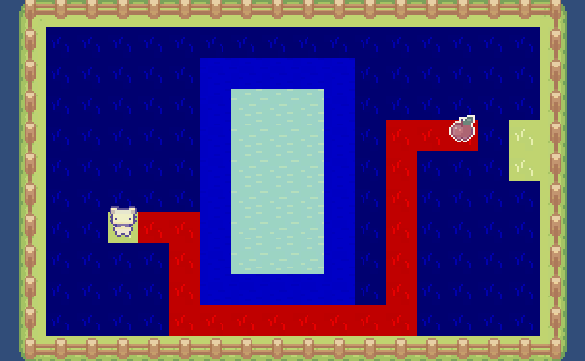
同時可以發現,如果每個地塊的移動成本都是一致的(比如都是平原),那么 Dijkstra 算法和廣度優先搜索其實是一樣的。
四、啟發式函數(Heuristic function)
無論是廣度優先搜索還是 Dijkstra 算法,都是以一種往外輻射的方式進行擴散的。但路徑尋找通常是有明確的方向性的(從起點指向終點方向),Dijkstra 算法會往相反的方向擴散,對性能造成較大影響。
Dijkstra 算法,只記錄了從起點到當前點的已消耗成本。我們將定義一個啟發式函數,對距離目標還有多遠進行評估,來得到(預估成本)。
某個節點的總成本=已消耗成本+預估成本,在待搜索隊列中,優先選取總成本最低的節點進行計算。
預估成本可以由距離、時間或者其他游戲特定因素來決定的。
以距離為例,常用的啟發式函數有兩種:
- 曼哈頓距離:h(node) = |node.x-target.x| + |node.y-target.y|
- 歐幾里得距離:h(x) = sqrt(pow(node.x-target.x, 2) + pow(node.y-target.y, 2))
理想情況下,啟發式結果與真實結果越相近越好,上面兩個距離相關的啟發式函數,在節點離終點越近時,預估成本都越小。
舉例來說,同樣是一片平原,已消耗成本為6時,有多種方案可選,既可以往終點走6步,也可以遠離終點。而在加入了啟發式函數進行預估成本評估后,顯然離終點更近的節點的預估成本和總成本會更低,並優先選取計算。
“曼哈頓距離”的預估成本通常會高於真實開銷,因為可能存在對角線斜走的可能,有一定概率無法發現最佳路徑。
“歐幾里得距離(兩點之間的直線距離)”的預估成本通常低於真實開銷,則可能會遍歷更多的節點影響性能。
五、貪婪最佳優先算法
在貪婪最佳優先算法中,會忽略已消耗成本,只考慮啟發函數計算的預估成本。
即:某個節點的總成本=預估成本。
以“曼哈頓距離”為啟發式函數為例,貪婪最佳優先算法會優先考慮離目標更近的點:
private void Greedy()
{
PriorityQueue frontier = new PriorityQueue();
Dictionary<TileNode, TileNode> cameFrom = new Dictionary<TileNode, TileNode>();
TileNode start = TotalTileModels[character.cellPosition];
TileNode target = TotalTileModels[destination.cellPosition];
frontier.Push(start, 0);
cameFrom.Add(start, null);
while (frontier.GetCount() != 0)
{
TileNode current = (TileNode)frontier.Out();
// 到達目標,提前退出
if (current == target) break;
foreach (TileNode neighbor in current.neighbors)
{
if (neighbor.nodeType == NodeType.Road && !cameFrom.ContainsKey(neighbor))
{
int cost = heuristic(neighbor, target);
frontier.Push(neighbor, cost);
cameFrom.Add(neighbor, current);
mClickableTilemap.mTilemap.SetColor(neighbor.position, Color.blue);
}
}
}
while (cameFrom[target] != null)
{
mClickableTilemap.mTilemap.SetColor(target.position, Color.red);
target = cameFrom[target];
}
}
在平坦地形上,貪婪算法效率是很高的,因為他會直奔目標而去(優先考慮預估距離更近的點)。但當存在障礙物時,路徑質量可能不太理想,因為會一直先取更近的點,所以可能會得到不太准確的路徑:
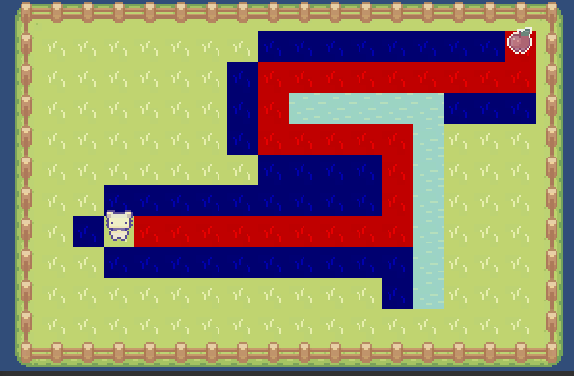
如圖,起點左邊、上邊、下方的方塊由於距離更遠的原因,會排在優先級隊列的尾部,起點右上方的方塊會優先計算並組成路徑。
六、A* 算法
上文可知:
對於 Dijkstra 算法,總成本=已消耗成本,可以很好地找到最短路徑,但在方向不確定的情況下會消耗更多的性能。
對於貪婪最佳優先算法,總成本=預估成本,效率更高,但可能找不到最短路徑。
而 A* 算法,綜合了考慮當下和未來(由啟發式函數決定):總成本=已消耗成本+預估成本。
// 微調 Dijkstra 函數即可
...
int priority = newCost + heuristic(neighbor, target);
frontier.Push(neighbor, priority);
...
由上代碼可知,Dijkstra 算法可當作 heuristic 函數返回 0 的A*算法。
七、總結
三種算法是在“已消耗成本”與“預估成本”之間進行評估,以在效率和路徑質量之間做取舍。
本質上仍舊是開頭的“廣度優先搜索”循環的一種優化。
可視化對比三種算法的不同,可參考 redblobgames 的這篇文章末尾:https://www.redblobgames.com/pathfinding/a-star/introduction.html