原文出處,字節大佬的文字,非常精彩
一、簡介
筆順后台的目標是只要對於給定的字體文件(WOFF, OTF, TTF )以及需要的字形(漢字,字母 or 其他各國的語言),就能產出與之對應的筆順動畫數據。是對開源項目Make me han zi[1]的實踐。
二、效果演示
展示效果
大力硬件端展示效果

后台數據資源

后台產出筆順動畫的 json 文件,並通過 CDN 資源分發。確定字體的情況下,一個字形對應唯一一個數據資源(字形通過encodeURI,並去除"%“進行編碼,即"我” -> “E68891”)。業務方可以通過拼接 URL 直接獲取到對應的筆順靜態資源。

亮點功能一
|筆畫的拆解

-
防止算法生成的筆畫數量有誤,提供人工干預能力
-
左邊圖同一顏色代表同一筆
-
可以通過增減右邊的紅色連線,來做到將字形結構進行筆畫的拆解或者是合並
亮點功能二
|筆順方向調節

-
防止算法生成的筆畫順序有誤,提供人工干預能力
-
可以靈活調節筆順的先后順序,或者是描紅的方向
亮點功能三
|縮放&平移功能

-
當字形渲染出來位置或者大小不符合要求的時候,提供人工修改能力
-
字形的大小以及在田字格的位置,在數據生成的時候,已經進行過統一調整
-
拖動右上角紅點進行大小縮放
-
拖動字形進行位置平移
三、動畫實現介紹
這里主要是解釋如何去使用筆順后台生產的數據
/** 筆順動畫原數據 */
{"strokes":["M 350 571 Q 380 593 449 614 Q 465 615 468 623 Q 471 633 458 643 Q 439 656 396 668 Q 381 674 370 672 Q 363 668 363 657 Q 364 621 200 527 Q 196 518 201 516 Q 213 516 290 546 Q 303 550 316 556 L 350 571 Z","M 584 466 Q 666 485 734 497 Q 746 496 754 511 Q 755 524 729 533 Q 693 554 622 527 Q 598 520 575 511 L 537 499 Q 518 495 500 488 Q 442 472 386 457 L 337 446 Q 327 446 179 416 Q 148 409 173 392 Q 212 365 241 376 Q 287 389 339 404 L 387 416 Q 460 438 545 457 L 584 466 Z","M 386 457 Q 387 493 398 517 Q 405 535 390 548 Q 371 564 350 571 C 323 583 303 583 316 556 Q 315 556 316 555 Q 338 519 337 478 Q 337 462 337 446 L 339 404 Q 340 343 339 289 L 338 241 Q 337 180 334 133 Q 333 115 323 109 Q 317 105 250 119 Q 238 122 239 114 Q 240 108 249 100 Q 309 42 328 6 Q 341 -10 357 3 Q 390 36 390 126 Q 387 169 387 265 L 387 306 Q 387 355 387 416 L 386 457 Z","M 339 289 Q 254 261 161 229 Q 139 222 101 221 Q 86 220 85 207 Q 84 192 94 184 Q 119 166 157 147 Q 169 144 182 154 Q 239 199 338 241 L 387 265 Q 477 314 484 318 Q 499 327 498 337 Q 492 343 479 340 Q 434 324 387 306 L 339 289 Z","M 635 195 Q 690 75 797 -14 Q 876 -62 898 -47 Q 920 -37 914 3 Q 905 34 899 152 Q 900 174 894 178 Q 890 179 884 160 Q 857 75 838 60 Q 823 56 785 88 Q 710 155 670 226 L 644 279 Q 599 381 584 466 L 575 511 Q 547 659 576 752 Q 586 779 543 805 Q 509 827 489 825 Q 470 824 479 795 Q 503 752 507 707 Q 517 601 537 499 L 545 457 Q 573 334 612 245 L 635 195 Z","M 612 245 Q 558 197 452 138 Q 442 132 448 128 Q 455 124 468 126 Q 523 135 574 160 Q 608 175 635 195 L 670 226 Q 706 260 747 317 Q 762 336 778 354 Q 788 361 785 374 Q 781 386 753 410 Q 734 428 723 428 Q 708 427 707 411 Q 701 354 644 279 L 612 245 Z","M 687 669 Q 718 648 754 623 Q 770 613 786 615 Q 798 618 801 632 Q 802 648 789 678 Q 780 697 746 708 Q 665 726 651 715 Q 647 711 651 697 Q 655 687 687 669 Z"],"medians":[[[458,627],[392,631],[336,588],[274,552],[258,550],[253,542],[220,530],[212,532],[203,522]],[[174,404],[215,398],[241,402],[672,514],[742,512]],[[323,556],[351,542],[365,522],[361,116],[340,67],[246,113]],[[100,206],[124,195],[163,189],[492,334]],[[492,807],[537,760],[538,627],[569,435],[612,299],[676,170],[717,112],[779,48],[817,22],[859,12],[880,78],[891,140],[886,147],[894,173]],[[723,412],[737,365],[664,259],[594,198],[489,142],[454,132]],[[657,710],[750,668],[781,634]]],"strokeInfos":[{"strokeMode":29,"strokeName":"撇"},{"strokeMode":27,"strokeName":"橫"},{"strokeMode":40,"strokeName":"豎鈎"},{"strokeMode":1,"strokeName":"提"},{"strokeMode":4,"strokeName":"斜鈎"},{"strokeMode":29,"strokeName":"撇"},{"strokeMode":31,"strokeName":"點"}]}
如何渲染字形
原數據中
strokes對應的字形中每一筆的筆畫輪廓數據
<svg version="1.1" viewBox="0 0 1024 1024">
{/* 田字格繪制 */}
<g
key="wordBg"
stroke="var(--color-text-4)"
strokeDasharray="1,1"
strokeWidth="1"
transform="scale(4, 4)"
>
<line x1="0" y1="0" x2="256" y2="0"></line>
<line x1="0" y1="0" x2="0" y2="256"></line>
<line x1="256" y1="0" x2="256" y2="256"></line>
<line x1="0" y1="256" x2="256" y2="256"></line>
<line x1="0" y1="0" x2="256" y2="256"></line>
<line x1="256" y1="0" x2="0" y2="256"></line>
<line x1="128" y1="0" x2="128" y2="256"></line>
<line x1="0" y1="128" x2="256" y2="128"></line>
</g>
{/* 文字svg路徑 */}
<g transform="scale(1, -1) translate(0, -900)">
{strokes.map((strokePath, idx) => (
<path key={strokePath} d={strokePath} />
))}
</g>
</svg>
-
設置
svg的viewBox為"0 0 1024 1024";因為,在獲取TTF字體字形的指令數據的時候,我們將對數據做統一化的處理,將字體單位長度都轉化至 1024 單位長度,保證了輸出的動畫數據在使用的時候不需要再做適配。 -
在繪制文字路徑的時候,注意需要做一個變換
transform="scale(1, -1) translate(0, -900)";因為,這里svg的坐標系方向跟字體字形所在的坐標系是不一樣的。 -
先放一個不做
transform的效果

transform="scale(1, -1)"后,會將g內的元素,沿着 x 軸做一個反轉,可以看出要將字形移到田字格的中間,還需要將字形下移

- *
transform="scale(1, -1) translate(0, -900)"*后

這里為什么不是移動 1024 單位長度呢?因為,TTF字體規范中有一個baseline的概念;在當前的坐標系里面,紅色線為字體的基准線;yMax = 900, yMin=-124。因此,需要將字形往下移動到baseline的位置。 從圖中坐標系(原點在baseline與左邊界的交點處,y 軸正方向朝上)可以看出,跟svg原本的坐標系(原點在左上角,y 軸正方向朝下)是有差別的,所以一開始需要transform的變換,對齊我們選擇的標准字體的坐標系。

如何做出動畫效果
-
通過
strokes能夠畫出字形的輪廓了,然后怎么加入描紅效果呢? -
這個時候需要用到原數據中的
medians字段對應的數據了。medians對應的數據,是中位線的數組,而中位線是中點的數組集合。如下圖

-
如何將
medians數據轉換成動畫數據呢? -
計算每個中位線的長度
const lengths = medians
.map((x) => getMedianLength(x))
.map(Math.round);
- 計算每一筆中位線的動畫
duration&delay
let totalDuration = 0;
for (let i = 0; i < medians.length; i++) {
const offset = lengths[i] + kWidth;
const duration = (delay + offset) / speed / 60;
const fraction = Math.round((100 * offset) / (delay + offset));
animations.push({
animationId: `animation-${i}`,
clipId: `clip-${i}`,
keyframeId: `keyframes${i}`,
path: paths[i],
delay: totalDuration,
duration,
fraction,
length: lengths[i],
offset,
spacing: 2 * lengths[i],
stroke: strokes[i],
width: kWidth,
});
totalDuration += duration;
}
-
利用
stroke-dashoffset,stroke-dasharray&keyframe&clip-path制作動畫 -
stroke-dashoffset, stroke-dasharray 解析[2]
-
MDN clip-path 解析[3]
const animationStyle = `@keyframes ${keyframeId} {
0% {
stroke: blue;
stroke-dashoffset: ${animation.offset};
stroke-width: ${animation.width};
}
${animation.fraction}% {
/* animation-timing-function: step-end; */
stroke: blue;
stroke-dashoffset: 0;
stroke-width: ${animation.width};
}
100% {
stroke: var(--color-text-1);
stroke-width: ${STANDARD_LEN};
}
}
#${animationId} {
animation: ${keyframeId} ${duration}s linear ${delay}s both;
}
`;
<g key={${animationId}${playCount}}>
<path
id={animationId}
clipPath={
url(#${clipId})}
d={path}
fill=“none”
strokeDasharray={
${length} ${spacing}}
strokeLinecap=“round”
/>
* `stroke-dashoffset`,`stroke-dasharray`&`keyframe`動畫效果;像是拿了一把大刷子,按照方向一把刷過去。

* 優化動畫效果,只需要字形對應的輪廓效果,利用`clip-path`只保留字形輪廓內的動畫效果

四、數據生產原理
--------
### 字形點位信息獲取
#### TTF 字體文件規范
* 官方-字體配置規定\[4\]
* `TTF`字體生產主要流程(從設計稿原件到數字化字形,再到字體文件中數字化輪廓)
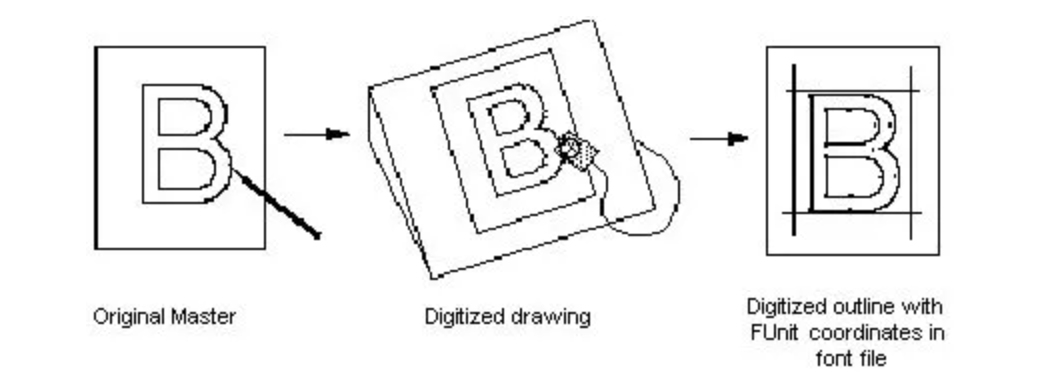
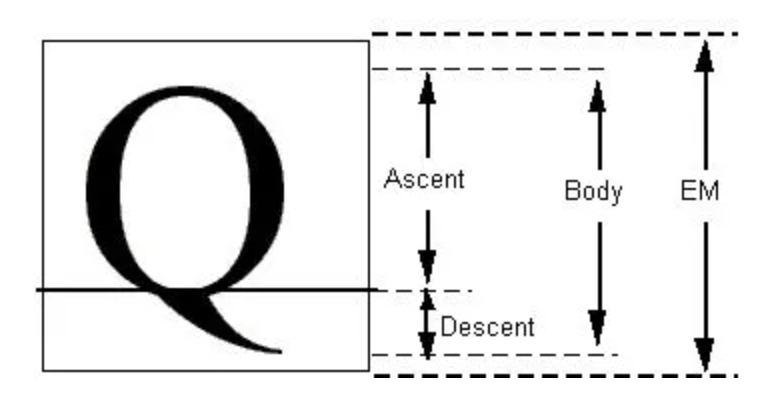
* 每個字體都會規定一個`EM`基准字體框(虛擬的),這個`em`框一般為長寬相等的正方形;其中`Asecent`和`Descent`分別代表字形相對 baseline 的一個距離
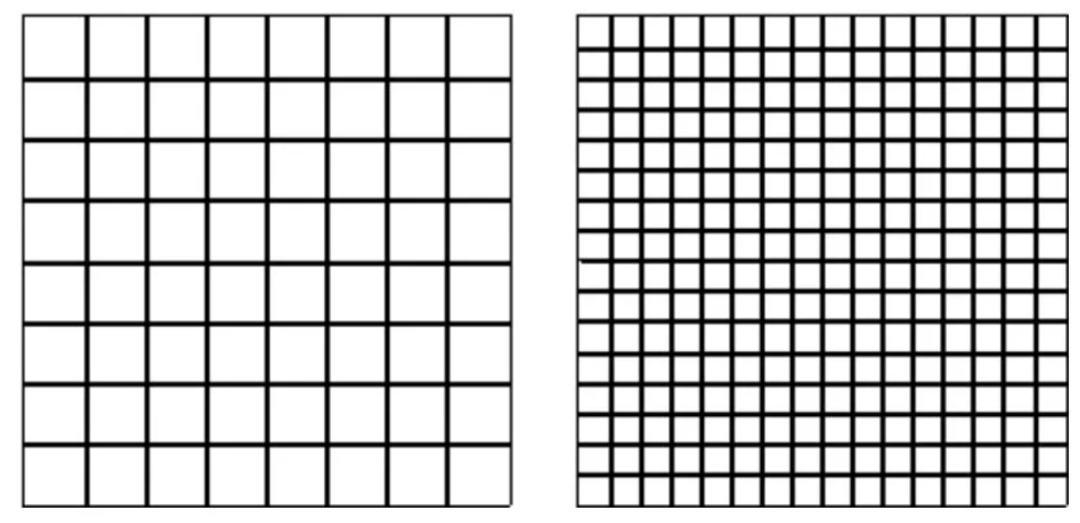
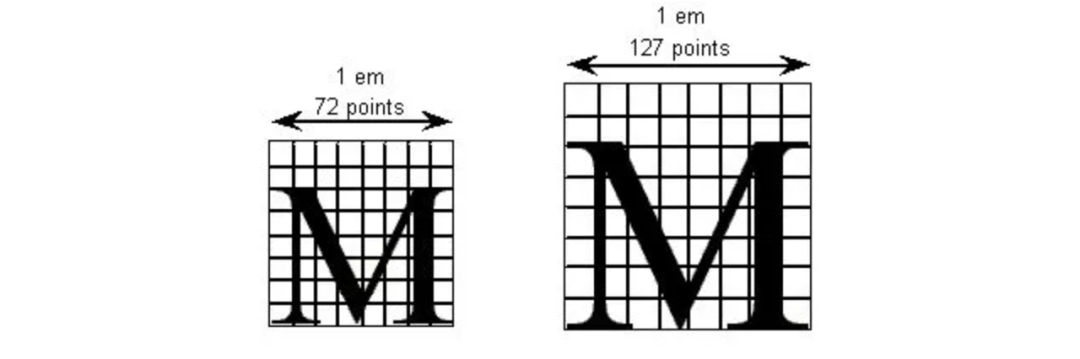
* 同時這里會有一個`FUnit`,如:512,1024,2048,來描述`em`框的相對大小。兩個 em 方塊的網格:左側每`em`包含 8 個單位,右側每`em`包含 16 個單位。當這個單位數字越大的時候,對應的字體分辨率就越高,越不容易失真
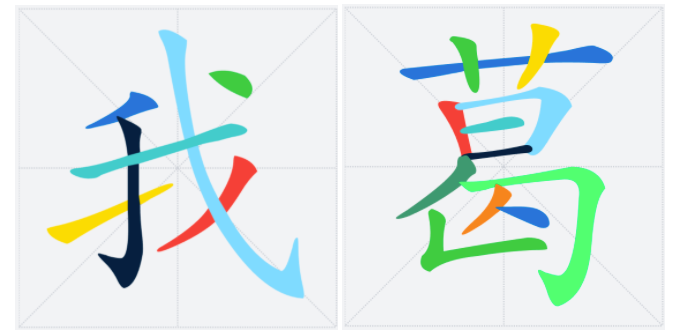
* `TTF`的字形由一個或者多個輪廓(`contour`)組成,例如:對於“我”字,這里有兩個`contours`:綠色部分+藍色部分

* 將所有的點位,在`FUnit`坐標系里面進行定位。最終,轉換成在對應坐標系下的一系列繪制指令
#### 利用開源工具opentype.js\[5\]解析 TTF 字體文件
* 拿到需求字體的坐標系信息(`ascender`: 最頂部距離`baseline`的距離;`descender`: 最底部距離 baseline 的距離,一般為負數;`unitsPerEm`:`FUnit`的單位格子數,也可以認為是`TTF`字體所在的坐標系大小)
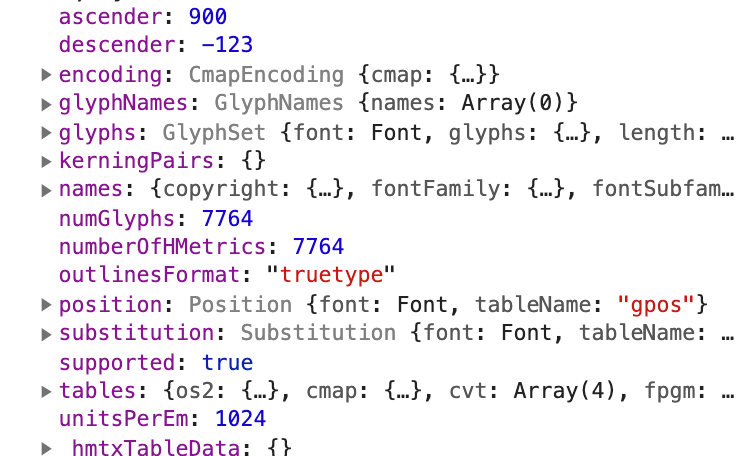
* 獲取所有輪廓的點位信息以及點位之間的相連關系 (TTF 連接點位常見命令:MLQZ)

* 統一轉換成我們的標准坐標系(1024 \* 1024,baseline 到上下距離分別為 900, 124)
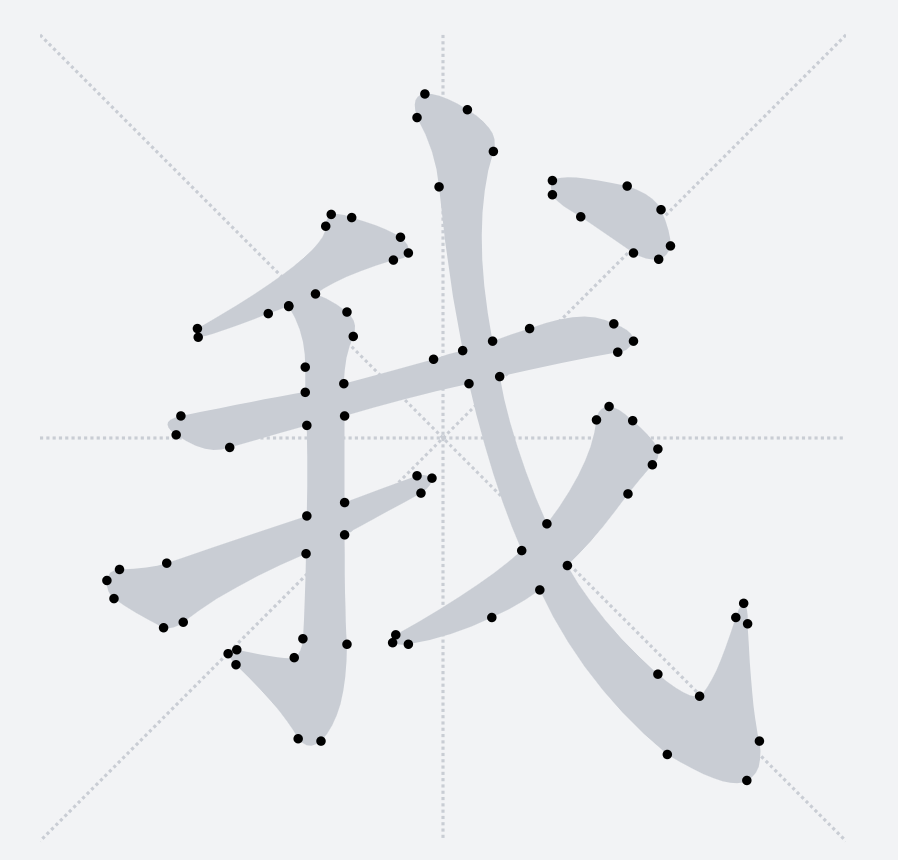
### 筆畫拆分
之前提到過,`TTF`字形只會包含多個輪廓,並不感知當前字形具體的筆畫細分。下圖釋義了當前輪廓點將和后面哪一個輪廓點連接成一條路徑
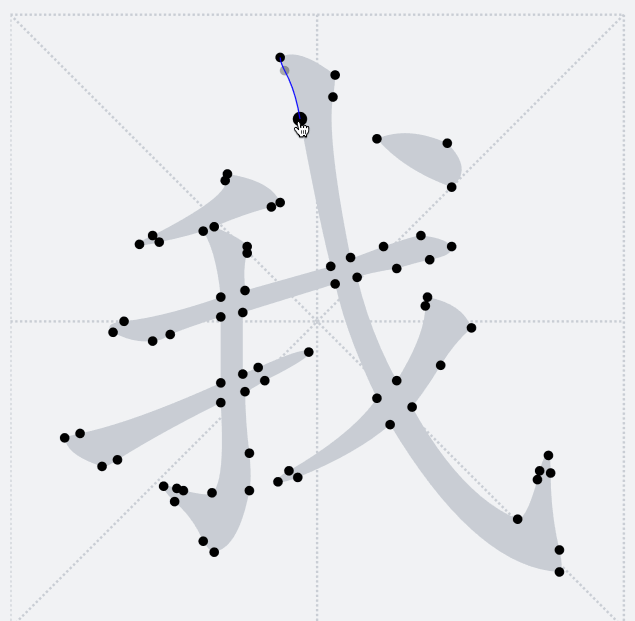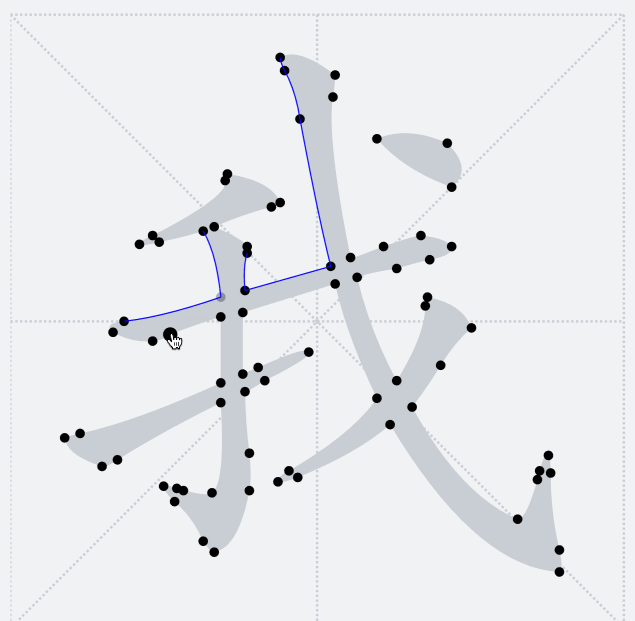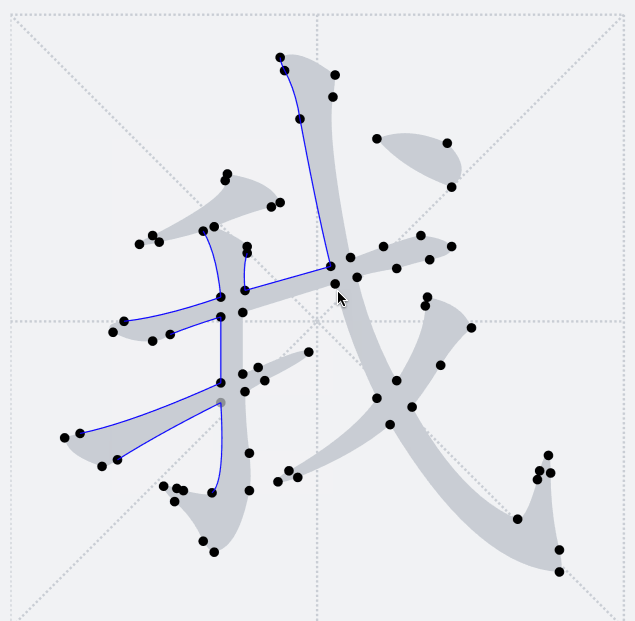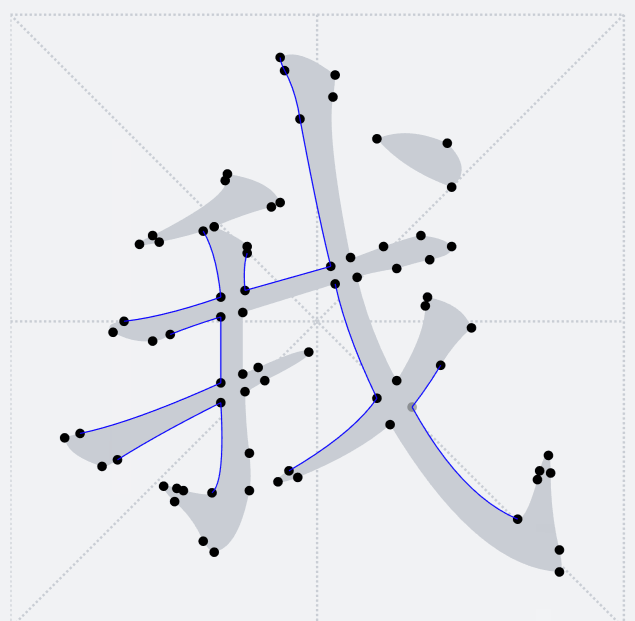
因此,這里我們希望在筆畫交界處讓路徑橫穿過去,於是需要其他的方法來將我們需要的漢字筆畫拆解出來。將筆畫拆解出來的關鍵是要識別筆畫公共交界處。
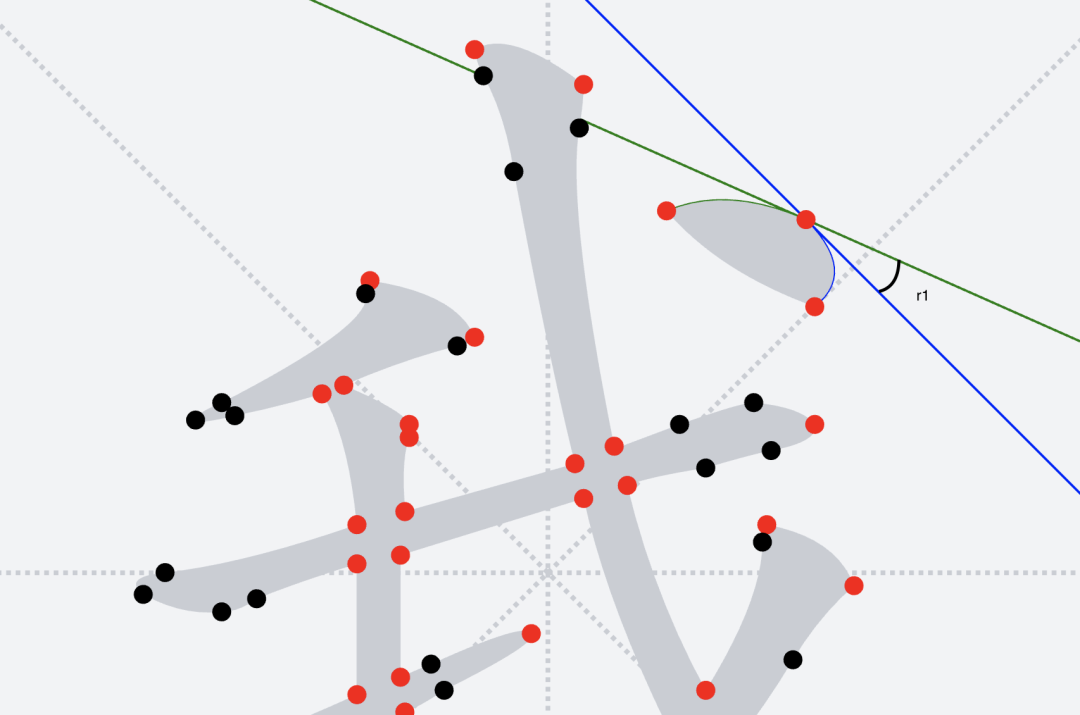
#### 提取 corner 點位
* 通過比較當前點位在前后路徑中分別作為終點和起點時候,穿過它的切線角度差(如圖中的`r1`),如果這個角度差大於`18°`,則將此點判斷為拐點(_`corner`_),代表字形輪廓在此處有比較大的幅度轉折,有一定可能是多筆的交界點。
#### 深度學習拿到`corners`之間的匹配度
* 那么如何判斷這個`corner`點是不是多筆的交界點呢?這個時候需要比較所有`corner`點,尋找他們之間是否有關聯關系。要拿到`corners`中 點與點的關系,需要借助神經網絡(模型下載地址\[6\])convnetjs\[7\]進行深度學習,獲取`corners`之間的匹配度
* 得到`corners`點與點之間的特征信息
const getFeatures = (ins: EndPoint, out: EndPoint) => {
const diff = out.subtract(ins);
const trivial = diff.equal(new Point([0, 0]));
const angle = Math.atan2(diff[1], diff[0]); // 兩點之間斜率的弧度
const distance = Math.sqrt(out.distance2(ins)); // 兩點之間的距離
return [
subtractAngle(angle, ins.angles[0]),
subtractAngle(out.angles[1], angle),
subtractAngle(ins.angles[1], angle),
subtractAngle(angle, out.angles[0]),
subtractAngle(ins.angles[1], ins.angles[0]),
subtractAngle(out.angles[1], out.angles[0]),
trivial ? 1 : 0,
distance / MAX_BRIDGE_DISTANCE,
];
};
* 通過模型訓練`corners`之間的特征信息,得到對應的匹配分數
const input = new convnetjs.Vol(1, 1, 8 /* feature vector dimensions */ );
const net = new convnetjs.Net();
net.fromJSON(NEURAL_NET_TRAINED_FOR_STROKE_EXTRACTION);
const weight = 0.8;
const trainedClassifier = (features: number[]) => {
input.w = features;
const softmax = net.forward(input).w;
return softmax[1] - softmax[0];
};
* 通過上述,最后得到一個帶權重的二分圖\[8\]
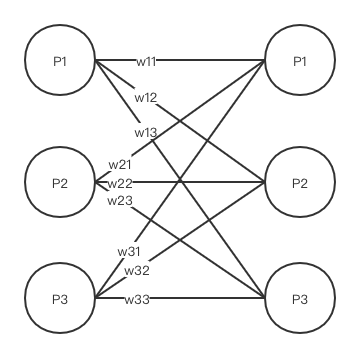
* 利用匈牙利算法\[9\],得到一個最大權重匹配圖。當`corner`點最大匹配的對象不是本身的時候,就將它們連接起來形成一個`bridge`(兩個`corner`點相連形成的一個線段),當然也要注意去重不要重復連接`bridge`
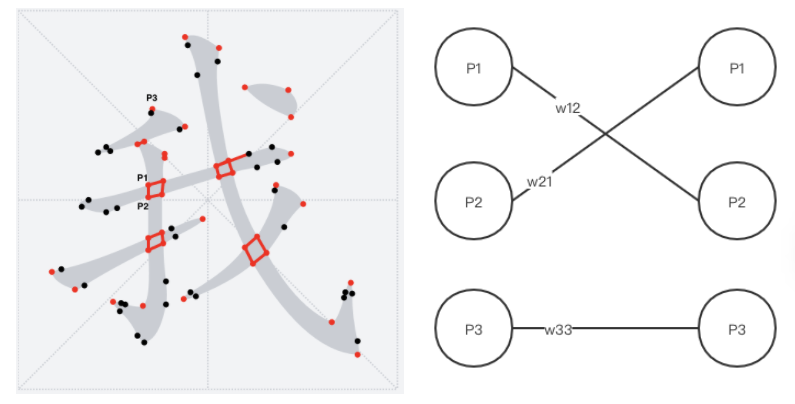
#### 筆畫拆分算法
現在我們通過生成`bridge`,能夠識別出了筆畫的公共交界處了,下一步就需要借助`bridge`來對筆畫進行拆分。【下面通過代碼片段,以及對應的動畫進行解釋】
…
const visited = [];
while (true) {
/**
- 直接將目前的路徑片段添加到result中
/
result.push(paths[current[0]][current[1]]);
/* 記錄當前這一筆visited過的點,到一個局部變量中 /
visited[get2LenArrKey(current)] = true;
/* 去到下一個片段路徑的起始點 /
current = advance(current);
const key = get2LenArrKey(current);
/* 判斷是否是bridge /
if (bridgeAdjacency.hasOwnProperty(key)) {
endpoint = endpointMap[key];
/*
* 如果當前點位是多個bridge的公共點,
* 則按照“bridge的切線,直線的切線的斜率等於自己的斜率”與“當前路徑前進的切線方向”角度差大小 從小到達排列,
* 優先選擇與當前路徑方向切線角度差最小的
/
const options = bridgeAdjacency[key].sort(
(a, b) => angle(endpoint!.pos, a) - angle(endpoint!.pos, b),
);
const next = options[0];
…
result.push({
start: current,
end: next,
control: undefined,
})
/*
* 這里要注意一個點,current被加入到了路徑中,但是沒有被打上visited標簽就直接到下一個點了,
* 目的是拆解下一筆的時候,這個bridge點就是下一筆的起始點
/
current = next;
}
const newKey = get2LenArrKey(current);
if (comp2LenArr(current, start)) {
/* 當走回到start的點的時候,這一筆就結束了 /
let numSegmentsOnPath = 0;
/* 局部visited 同步到 全局的vistied中 /
for (const index in visited) {
extractedIndices[index] = true;
numSegmentsOnPath += 1;
}
/* 只有一個點的時候,不形成筆畫 /
if (numSegmentsOnPath === 1) {
return undefined;
}
return result;
} else if (extractedIndices[newKey] || visited[newKey]) {
/* 訪問過的點直接跳過,在這里判斷是不允許以被訪問過的點開啟一下次局部循環判斷 */
return undefined;
}
}
…
* 對算法的解釋動畫
原始輪廓指令有一個默認的順序【嚴格有序,`ttf`保證】,所以對於不是`bridge`的點,很容易知道當前點的下一個點是哪一個
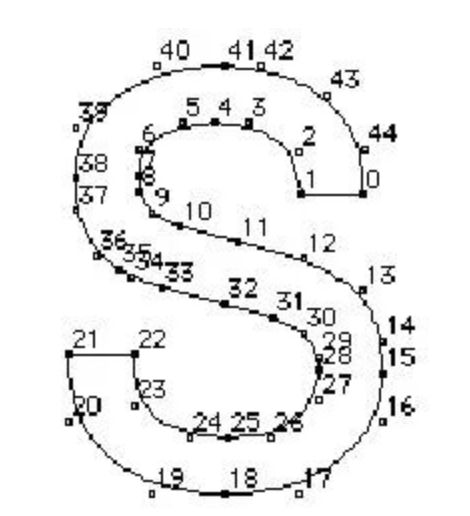
1. 藍色點代表被標記為`visited`的點【首次碰到`bridge`的一個端點的時候,直接將此點加入路徑,並**跳過**`visited`標記,然后走到下一個點】
2. 當遇到的`corner`點處有多個`bridge`的時候,選擇`bridge`的斜率角度應該與當前筆畫路徑前進方向的切線斜率角度差最小
3. 紅色的`bridge`可以讓筆畫直接穿過筆畫交界處,並以\*\*線段(`Line`)\*\*將`bridge`的兩點相連
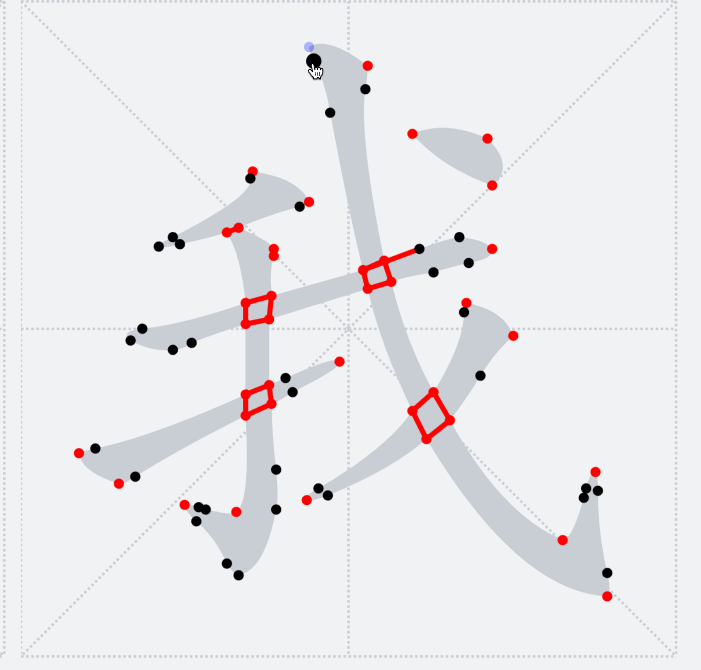
#### 筆畫修復
通過`bridge`將筆畫拆分以后,可以得到下圖的展示,看似完美的背后其實還是有一點兒小瑕疵的:那是因為在`bridge`連接的地方都是通過直線連接,會導致筆鋒的位置看上去好像被刀削過一樣
* 將所有直線,換用三次貝塞爾曲線替代
1. `L1`與以`P1`為終點的上一條路徑片段相切於`P1`點
2. `L2`與以`P2`為起點的下一條路徑片段相切於`P2`點
3. `L1`與`L2`交於`CP`點
4. `MP1`為`P1`與`CP`間的中點;`MP2`為`P2`與`CP`間的中點。這兩點將作為貝塞爾曲線的控制點
5. 畫三次貝塞爾曲線,即字形圖中黑色的曲線
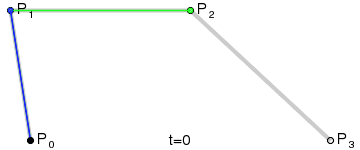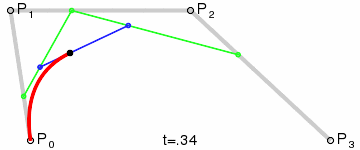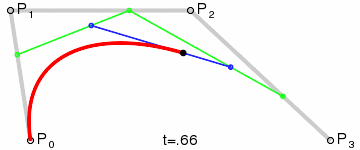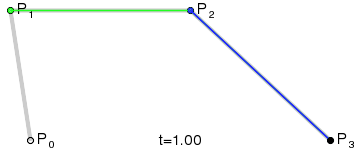
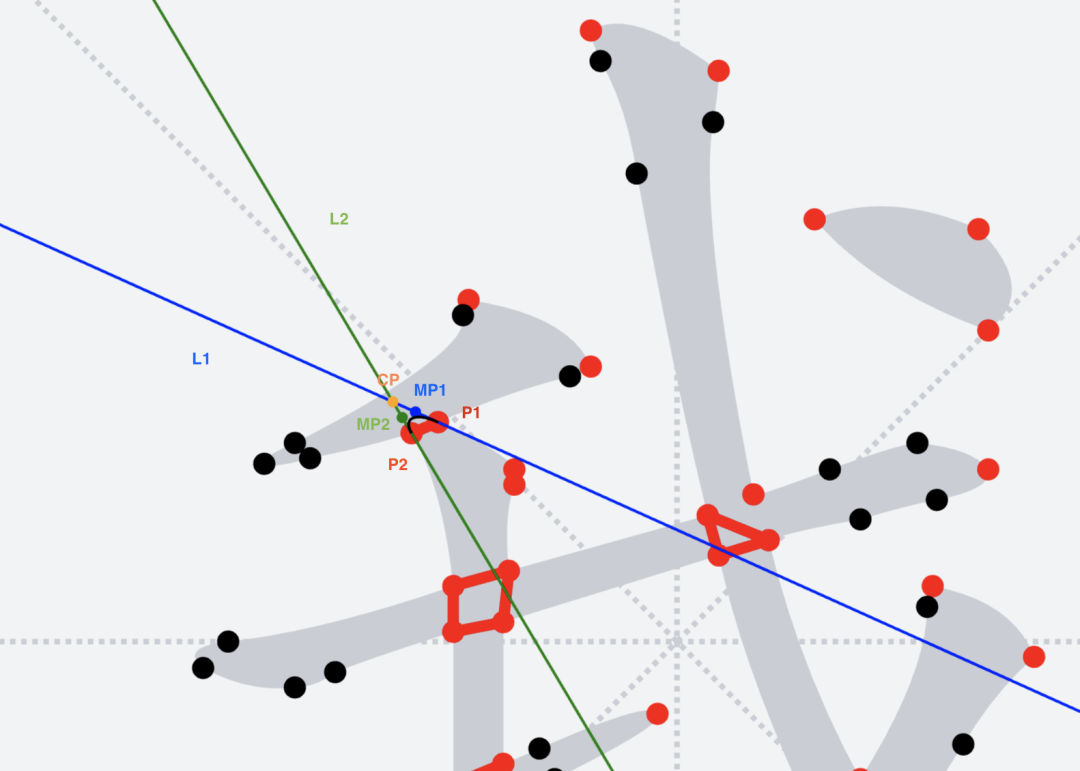
* 修復后的效果
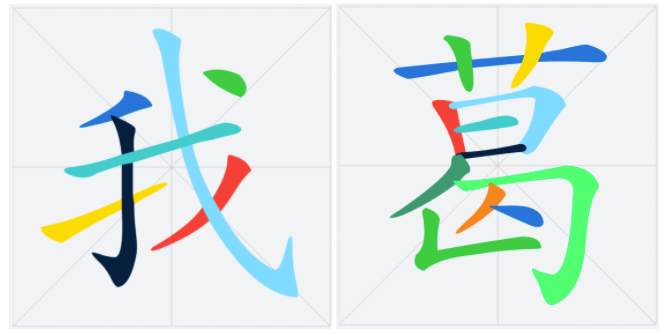
### 筆順動畫
> 拆分完筆畫以后,此時便到了確定筆順動畫的時候
#### 獲取筆畫中位線骨干
* 增加每一筆筆畫上的采樣點(運用二次貝賽爾曲線公式,拿到更多筆畫上的關鍵點)
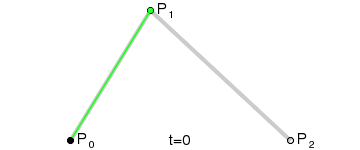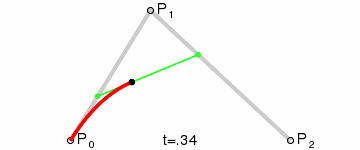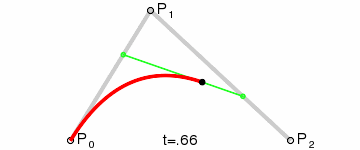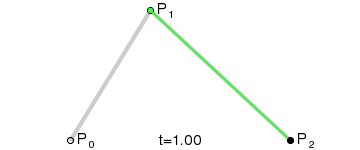
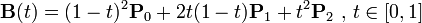
export function getPolygonApproximation(
path: SVGPathType[],
approximationError = 64,
): PolygonType {
const result: Point[] = [];
for (const segment of path) {
const control = segment.control || segment.start.midpoint(segment.end);
const distance = Math.sqrt(segment.start.distance2(segment.end));
const numPoints = Math.floor(distance / approximationError);
for (let i = 0; i < numPoints; i++) {
const t = (i + 1) / (numPoints + 1)
const s = 1 - t;
result.push(
new Point([
s * s * segment.start[0] +
2 * s * t * control[0] +
t * t * segment.end[0],
s * s * segment.start[1] +
2 * s * t * control[1] +
t * t * segment.end[1],
]),
);
}
result.push(segment.end);
}
return result;
}

* voronoijs 泰森多邊形 npm 庫\[10\](根據擴充后的采樣點構成泰森多邊形\[11\])
1. 藍色點為筆畫輪廓上的輪廓點(也相當於泰森多邊形的采樣點)
2. 泰森多邊形中每一個多邊形內的點到對應的采樣點的距離是最短的;也就是說多個多邊形的交界點是距離這些多邊形中采樣點的距離都最短的一個點(也就是圖中黑色的點)
3. 留下所有筆畫內的黑色點,連接黑色點便可以形成控制該筆畫方向的中位線

4. 控制中位線中關鍵點的數量(保證中位線長度最長,但是點位盡量最少),最終形成下圖
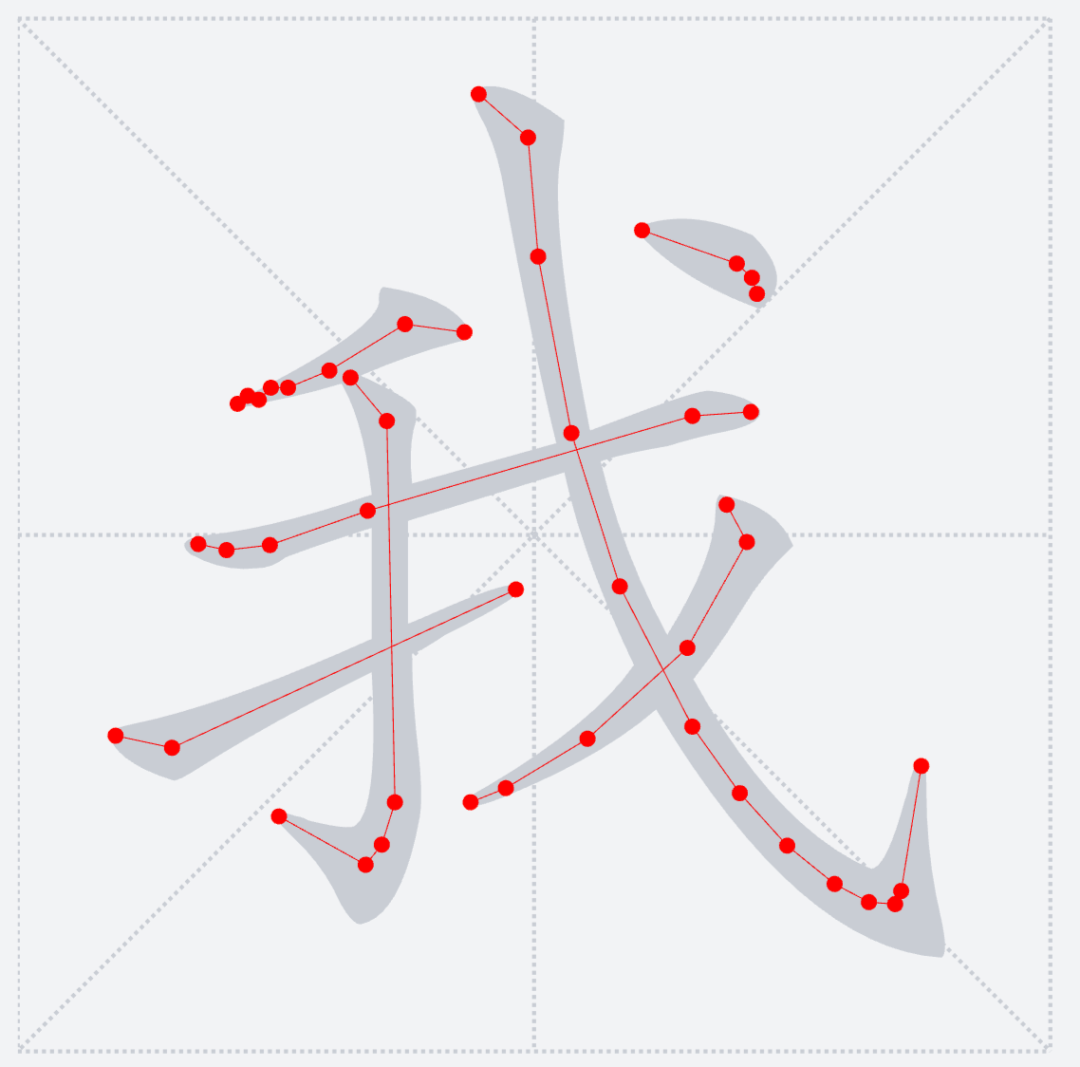
#### 筆順動畫排序
> 當拿到所有筆畫對應的方向中位線以后,還需要確定筆順的先后順序
* 漢字結構梳理:表意文字描述字符\[12\]
| 編碼 | 字符 | 意義 | 例字 | 序列 |
| --- | --- | --- | --- | --- |
| U+2FF0 | ⿰ | 兩個部件由左至右組成 | 相 | ⿰ 木目 |
| U+2FF1 | ⿱ | 兩個部件由上至下組成 | 杏 | ⿱ 木口 |
| U+2FF2 | ⿲ | 三個部件由左至右組成 | 衍 | ⿲ 彳氵亍 |
| U+2FF3 | ⿳ | 三個部件由上至下組成 | 京 | ⿳ 亠口小 |
| U+2FF4 | ⿴ | 兩個部件由外而內組成 | 回 | ⿴ 囗口 |
| U+2FF5 | ⿵ | 三面包圍,下方開口 | 凰 | ⿵ 幾皇 |
| U+2FF6 | ⿶ | 三面包圍,上方開口 | 凶 | ⿶ 凵㐅 |
| U+2FF7 | ⿷ | 三面包圍,右方開口 | 匠 | ⿷ 匚斤 |
| U+2FF8 | ⿸ | 兩面包圍,兩個部件由左上至右下組成 | 病 | ⿸ 疒丙 |
| U+2FF9 | ⿹ | 兩面包圍,兩個部件由右上至左下組成 | 戒 | ⿹ 戈廾 |
| U+2FFA | ⿺ | 兩面包圍,兩個部件由左下至右上組成 | 超 | ⿺ 走召 |
| U+2FFB | ⿻ | 兩個部件重疊 | 巫 | ⿻ 工從 |
* 對於給定的字形,查漢字結構表\[13\]獲得該字形的結構拆分,構成結構樹
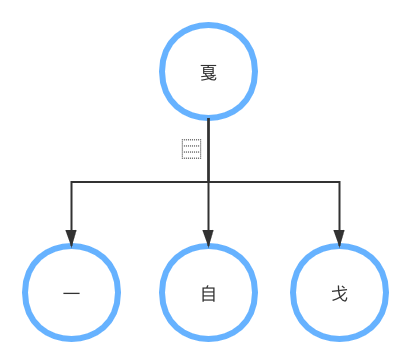
* 中位線
1. ```
將所有子結構的`medians`添加到一個集合(按照結構的拆解順序加入),
```
```
方便和當前字形生成的`medians`做對比
```
2. ```
對比子字形結構和當前字形結構的`medians`,並對應打上匹配分數,
```
```
轉換成帶權重的二分圖匹配問題
```
const scoreMedians = (median1: number[][], median2: number[][]) => {
assert(median1.length === median2.length);
/** 這里要記兩個分值,因為對比的兩個median可能剛好只是順序反了,最后取距離差最小的那個 */
let option1 = 0;
let option2 = 0;
range(median1.length).forEach((i) => {
option1 -= dist2(median1[i], median2[i]);
option2 -= dist2(median1[i], median2[median2.length - i - 1]);
});
return Math.max(option1, option2);
};
3. 利用匈牙利算法,找出最大權重匹配關系,拿到該字形相對子字形結構的筆畫順序排列。
五、總結
----
1. 通過上述算法過后,可以將筆順數據生成為 json 格式的文件並存儲在 CDN 上,文件的平均大小在 4 kB 左右。
2. 筆順動畫數據的生產過程中,用了比較多的推測對比算法,能滿足很多字形的 case;但是依然不能百分之百保證數據的准確性(字形復雜的時候,算法很容易誤判)。所以,在新字體的數據生成過程中,依然需要人工干預的方式去保證數據的准確性。
3. 目前筆順后台也是提供了半自動半人工的方式去生產給定字體以及給定字形情況下的筆順數據。為了降低人工成本,需要探索糾錯算法;這樣在做批量生成的時候,可以有針對性的進行錯誤定位。
團隊招聘
----
我們團隊隸屬於字節跳動大力智能部門,一方面從事大力智能作業燈/大力輔導APP以及相關海內外教育產品的前端研發工作,業務場景包含 H5,Flutter,小程序以及各種 Hybrid 場景;另外我們團隊在 monorepo,微前端,serverless 等各種前沿前端技術也有一定實踐與沉淀。常用的技術棧包括但是不限於 React、TS、Nodejs。掃描下方二維碼獲取內推碼:


**字節前端 ByteFE**
字節前端的技術實踐分享
62篇原創內容
公眾號
參考資料
\[1\]
Make me han zi: _https://github.com/skishore/makemeahanzi_
\[2\]
stroke-dashoffset, stroke-dasharray 解析: _https://www.cnblogs.com/daisygogogo/p/11044353.html_
\[3\]
MDN clip-path 解析: _https://developer.mozilla.org/zh-CN/docs/Web/CSS/clip-path_
\[4\]
官方-字體配置規定: _https://docs.microsoft.com/zh-cn/typography/opentype/spec/otff#required-tables_
\[5\]
opentype.js: _https://github.com/opentypejs/opentype.js_
\[6\]
模型下載地址: _https://p3.daliapp.net/obj/character-stroke/net.json_
\[7\]
convnetjs: _https://www.npmjs.com/package/convnetjs-ts_
\[8\]
二分圖: _https://baike.baidu.com/item/%E4%BA%8C%E5%88%86%E5%9B%BE/9089095?fr=aladdin_
\[9\]
匈牙利算法: _https://zhuanlan.zhihu.com/p/96229700_
\[10\]
voronoijs 泰森多邊形 npm 庫: _https://www.npmjs.com/package/voronoijs?activeTab=readme_
\[11\]
泰森多邊形: _https://zh.wikipedia.org/wiki/%E6%B2%83%E7%BD%97%E8%AF%BA%E4%BC%8A%E5%9B%BE_
\[12\]
表意文字描述字符: _https://zh.wikipedia.org/wiki/%E8%A1%A8%E6%84%8F%E6%96%87%E5%AD%97%E6%8F%8F%E8%BF%B0%E5%AD%97%E7%AC%A6_
\[13\]
漢字結構表: _http://p3.daliapp.net/obj/character-stroke/characterdecomposition.csv_