原文出处,字节大佬的文字,非常精彩
一、简介
笔顺后台的目标是只要对于给定的字体文件(WOFF, OTF, TTF )以及需要的字形(汉字,字母 or 其他各国的语言),就能产出与之对应的笔顺动画数据。是对开源项目Make me han zi[1]的实践。
二、效果演示
展示效果
大力硬件端展示效果

后台数据资源

后台产出笔顺动画的 json 文件,并通过 CDN 资源分发。确定字体的情况下,一个字形对应唯一一个数据资源(字形通过encodeURI,并去除"%“进行编码,即"我” -> “E68891”)。业务方可以通过拼接 URL 直接获取到对应的笔顺静态资源。

亮点功能一
|笔画的拆解

-
防止算法生成的笔画数量有误,提供人工干预能力
-
左边图同一颜色代表同一笔
-
可以通过增减右边的红色连线,来做到将字形结构进行笔画的拆解或者是合并
亮点功能二
|笔顺方向调节

-
防止算法生成的笔画顺序有误,提供人工干预能力
-
可以灵活调节笔顺的先后顺序,或者是描红的方向
亮点功能三
|缩放&平移功能

-
当字形渲染出来位置或者大小不符合要求的时候,提供人工修改能力
-
字形的大小以及在田字格的位置,在数据生成的时候,已经进行过统一调整
-
拖动右上角红点进行大小缩放
-
拖动字形进行位置平移
三、动画实现介绍
这里主要是解释如何去使用笔顺后台生产的数据
/** 笔顺动画原数据 */
{"strokes":["M 350 571 Q 380 593 449 614 Q 465 615 468 623 Q 471 633 458 643 Q 439 656 396 668 Q 381 674 370 672 Q 363 668 363 657 Q 364 621 200 527 Q 196 518 201 516 Q 213 516 290 546 Q 303 550 316 556 L 350 571 Z","M 584 466 Q 666 485 734 497 Q 746 496 754 511 Q 755 524 729 533 Q 693 554 622 527 Q 598 520 575 511 L 537 499 Q 518 495 500 488 Q 442 472 386 457 L 337 446 Q 327 446 179 416 Q 148 409 173 392 Q 212 365 241 376 Q 287 389 339 404 L 387 416 Q 460 438 545 457 L 584 466 Z","M 386 457 Q 387 493 398 517 Q 405 535 390 548 Q 371 564 350 571 C 323 583 303 583 316 556 Q 315 556 316 555 Q 338 519 337 478 Q 337 462 337 446 L 339 404 Q 340 343 339 289 L 338 241 Q 337 180 334 133 Q 333 115 323 109 Q 317 105 250 119 Q 238 122 239 114 Q 240 108 249 100 Q 309 42 328 6 Q 341 -10 357 3 Q 390 36 390 126 Q 387 169 387 265 L 387 306 Q 387 355 387 416 L 386 457 Z","M 339 289 Q 254 261 161 229 Q 139 222 101 221 Q 86 220 85 207 Q 84 192 94 184 Q 119 166 157 147 Q 169 144 182 154 Q 239 199 338 241 L 387 265 Q 477 314 484 318 Q 499 327 498 337 Q 492 343 479 340 Q 434 324 387 306 L 339 289 Z","M 635 195 Q 690 75 797 -14 Q 876 -62 898 -47 Q 920 -37 914 3 Q 905 34 899 152 Q 900 174 894 178 Q 890 179 884 160 Q 857 75 838 60 Q 823 56 785 88 Q 710 155 670 226 L 644 279 Q 599 381 584 466 L 575 511 Q 547 659 576 752 Q 586 779 543 805 Q 509 827 489 825 Q 470 824 479 795 Q 503 752 507 707 Q 517 601 537 499 L 545 457 Q 573 334 612 245 L 635 195 Z","M 612 245 Q 558 197 452 138 Q 442 132 448 128 Q 455 124 468 126 Q 523 135 574 160 Q 608 175 635 195 L 670 226 Q 706 260 747 317 Q 762 336 778 354 Q 788 361 785 374 Q 781 386 753 410 Q 734 428 723 428 Q 708 427 707 411 Q 701 354 644 279 L 612 245 Z","M 687 669 Q 718 648 754 623 Q 770 613 786 615 Q 798 618 801 632 Q 802 648 789 678 Q 780 697 746 708 Q 665 726 651 715 Q 647 711 651 697 Q 655 687 687 669 Z"],"medians":[[[458,627],[392,631],[336,588],[274,552],[258,550],[253,542],[220,530],[212,532],[203,522]],[[174,404],[215,398],[241,402],[672,514],[742,512]],[[323,556],[351,542],[365,522],[361,116],[340,67],[246,113]],[[100,206],[124,195],[163,189],[492,334]],[[492,807],[537,760],[538,627],[569,435],[612,299],[676,170],[717,112],[779,48],[817,22],[859,12],[880,78],[891,140],[886,147],[894,173]],[[723,412],[737,365],[664,259],[594,198],[489,142],[454,132]],[[657,710],[750,668],[781,634]]],"strokeInfos":[{"strokeMode":29,"strokeName":"撇"},{"strokeMode":27,"strokeName":"横"},{"strokeMode":40,"strokeName":"竖钩"},{"strokeMode":1,"strokeName":"提"},{"strokeMode":4,"strokeName":"斜钩"},{"strokeMode":29,"strokeName":"撇"},{"strokeMode":31,"strokeName":"点"}]}
如何渲染字形
原数据中
strokes对应的字形中每一笔的笔画轮廓数据
<svg version="1.1" viewBox="0 0 1024 1024">
{/* 田字格绘制 */}
<g
key="wordBg"
stroke="var(--color-text-4)"
strokeDasharray="1,1"
strokeWidth="1"
transform="scale(4, 4)"
>
<line x1="0" y1="0" x2="256" y2="0"></line>
<line x1="0" y1="0" x2="0" y2="256"></line>
<line x1="256" y1="0" x2="256" y2="256"></line>
<line x1="0" y1="256" x2="256" y2="256"></line>
<line x1="0" y1="0" x2="256" y2="256"></line>
<line x1="256" y1="0" x2="0" y2="256"></line>
<line x1="128" y1="0" x2="128" y2="256"></line>
<line x1="0" y1="128" x2="256" y2="128"></line>
</g>
{/* 文字svg路径 */}
<g transform="scale(1, -1) translate(0, -900)">
{strokes.map((strokePath, idx) => (
<path key={strokePath} d={strokePath} />
))}
</g>
</svg>
-
设置
svg的viewBox为"0 0 1024 1024";因为,在获取TTF字体字形的指令数据的时候,我们将对数据做统一化的处理,将字体单位长度都转化至 1024 单位长度,保证了输出的动画数据在使用的时候不需要再做适配。 -
在绘制文字路径的时候,注意需要做一个变换
transform="scale(1, -1) translate(0, -900)";因为,这里svg的坐标系方向跟字体字形所在的坐标系是不一样的。 -
先放一个不做
transform的效果

transform="scale(1, -1)"后,会将g内的元素,沿着 x 轴做一个反转,可以看出要将字形移到田字格的中间,还需要将字形下移

- *
transform="scale(1, -1) translate(0, -900)"*后

这里为什么不是移动 1024 单位长度呢?因为,TTF字体规范中有一个baseline的概念;在当前的坐标系里面,红色线为字体的基准线;yMax = 900, yMin=-124。因此,需要将字形往下移动到baseline的位置。 从图中坐标系(原点在baseline与左边界的交点处,y 轴正方向朝上)可以看出,跟svg原本的坐标系(原点在左上角,y 轴正方向朝下)是有差别的,所以一开始需要transform的变换,对齐我们选择的标准字体的坐标系。

如何做出动画效果
-
通过
strokes能够画出字形的轮廓了,然后怎么加入描红效果呢? -
这个时候需要用到原数据中的
medians字段对应的数据了。medians对应的数据,是中位线的数组,而中位线是中点的数组集合。如下图

-
如何将
medians数据转换成动画数据呢? -
计算每个中位线的长度
const lengths = medians
.map((x) => getMedianLength(x))
.map(Math.round);
- 计算每一笔中位线的动画
duration&delay
let totalDuration = 0;
for (let i = 0; i < medians.length; i++) {
const offset = lengths[i] + kWidth;
const duration = (delay + offset) / speed / 60;
const fraction = Math.round((100 * offset) / (delay + offset));
animations.push({
animationId: `animation-${i}`,
clipId: `clip-${i}`,
keyframeId: `keyframes${i}`,
path: paths[i],
delay: totalDuration,
duration,
fraction,
length: lengths[i],
offset,
spacing: 2 * lengths[i],
stroke: strokes[i],
width: kWidth,
});
totalDuration += duration;
}
-
利用
stroke-dashoffset,stroke-dasharray&keyframe&clip-path制作动画 -
stroke-dashoffset, stroke-dasharray 解析[2]
-
MDN clip-path 解析[3]
const animationStyle = `@keyframes ${keyframeId} {
0% {
stroke: blue;
stroke-dashoffset: ${animation.offset};
stroke-width: ${animation.width};
}
${animation.fraction}% {
/* animation-timing-function: step-end; */
stroke: blue;
stroke-dashoffset: 0;
stroke-width: ${animation.width};
}
100% {
stroke: var(--color-text-1);
stroke-width: ${STANDARD_LEN};
}
}
#${animationId} {
animation: ${keyframeId} ${duration}s linear ${delay}s both;
}
`;
<g key={${animationId}${playCount}}>
<path
id={animationId}
clipPath={
url(#${clipId})}
d={path}
fill=“none”
strokeDasharray={
${length} ${spacing}}
strokeLinecap=“round”
/>
* `stroke-dashoffset`,`stroke-dasharray`&`keyframe`动画效果;像是拿了一把大刷子,按照方向一把刷过去。

* 优化动画效果,只需要字形对应的轮廓效果,利用`clip-path`只保留字形轮廓内的动画效果

四、数据生产原理
--------
### 字形点位信息获取
#### TTF 字体文件规范
* 官方-字体配置规定\[4\]
* `TTF`字体生产主要流程(从设计稿原件到数字化字形,再到字体文件中数字化轮廓)
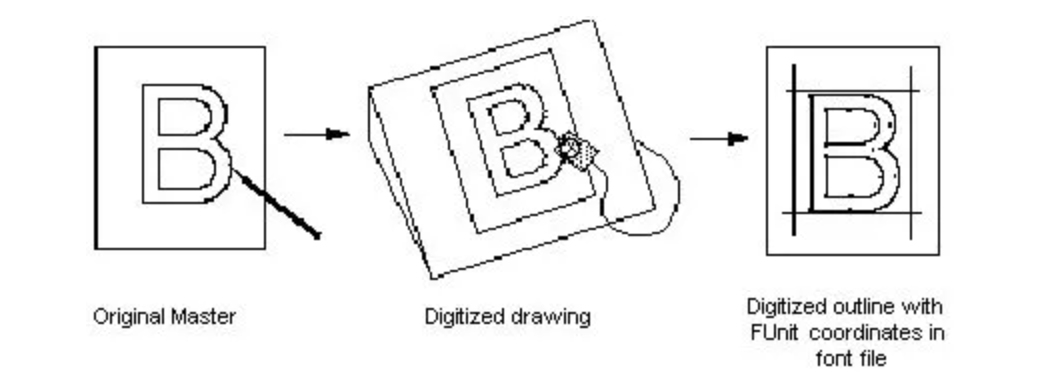
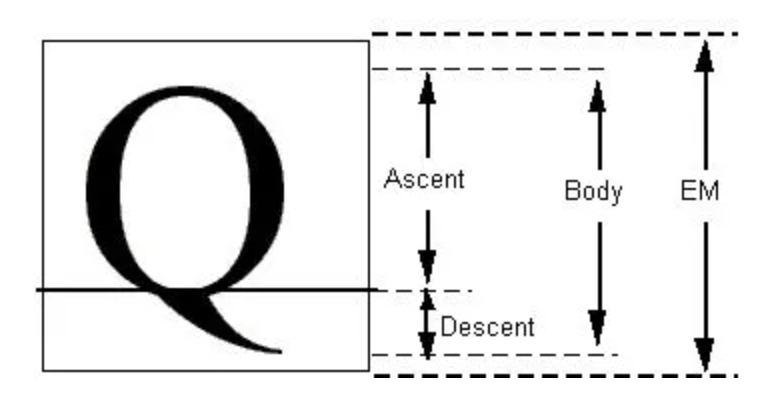
* 每个字体都会规定一个`EM`基准字体框(虚拟的),这个`em`框一般为长宽相等的正方形;其中`Asecent`和`Descent`分别代表字形相对 baseline 的一个距离
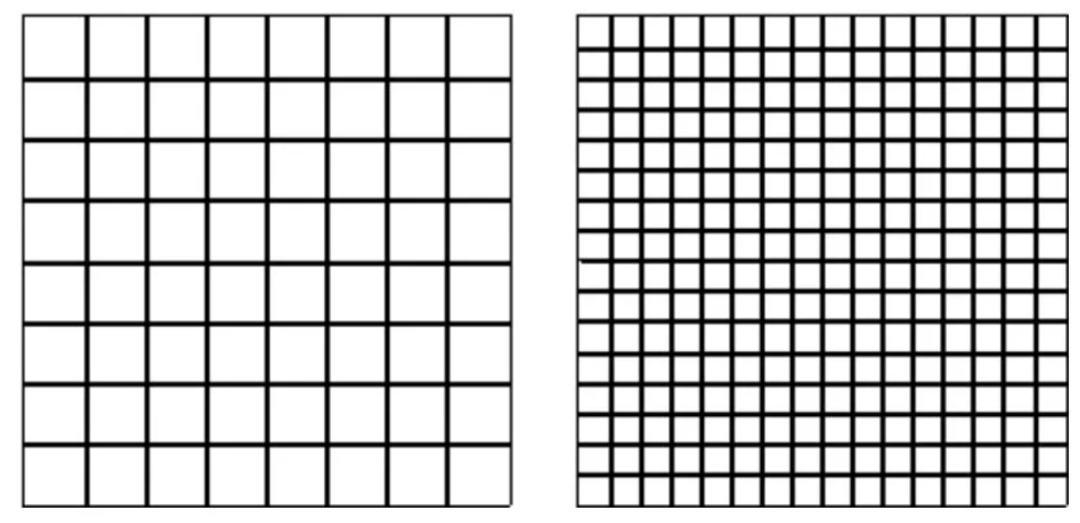
* 同时这里会有一个`FUnit`,如:512,1024,2048,来描述`em`框的相对大小。两个 em 方块的网格:左侧每`em`包含 8 个单位,右侧每`em`包含 16 个单位。当这个单位数字越大的时候,对应的字体分辨率就越高,越不容易失真
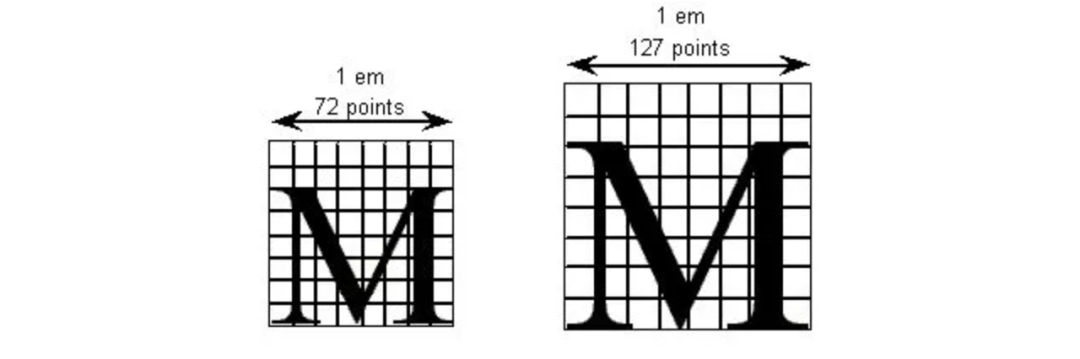
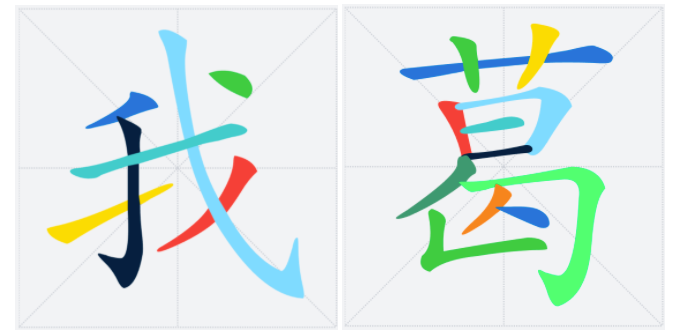
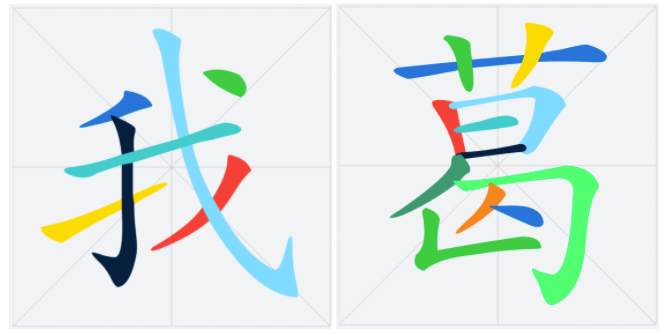
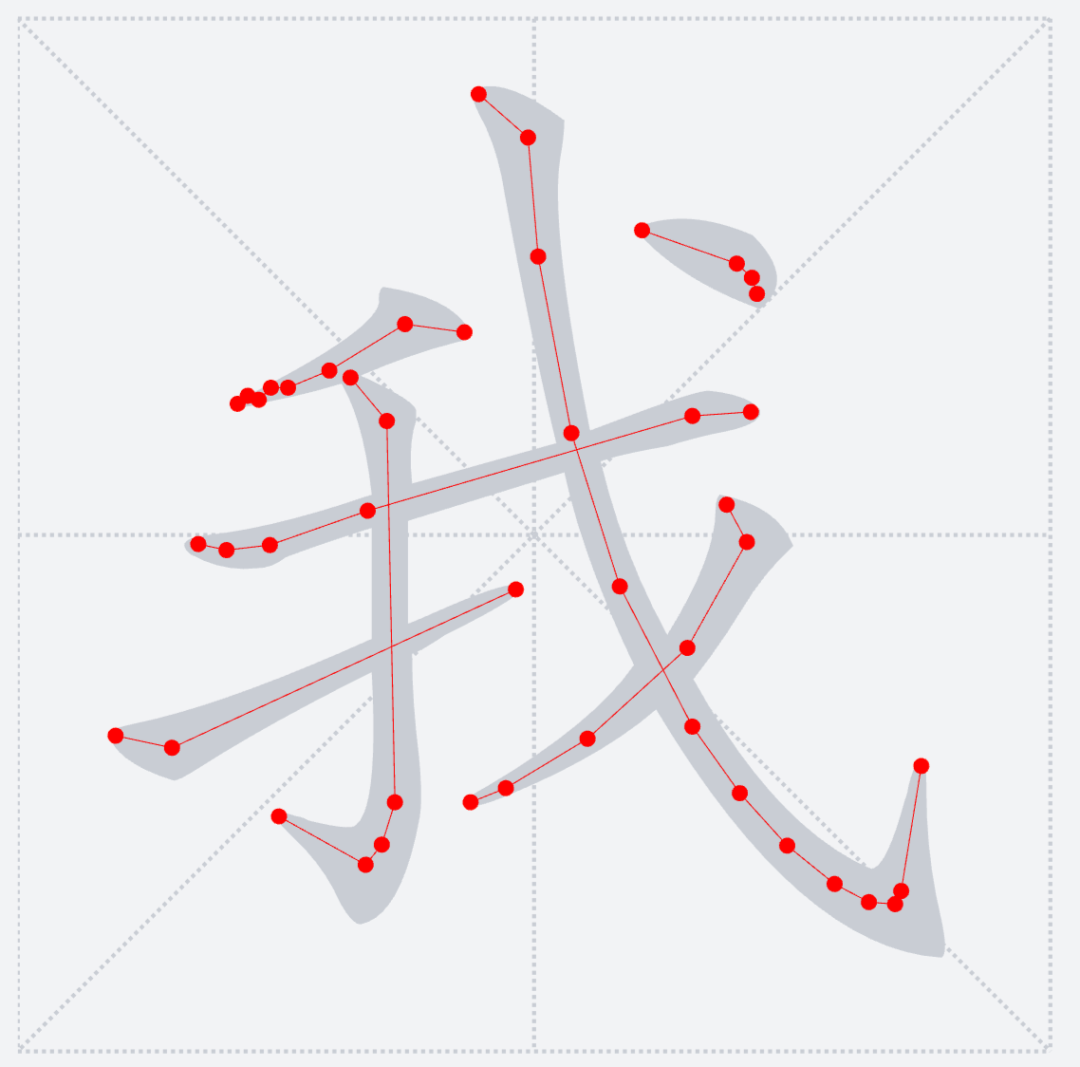
* `TTF`的字形由一个或者多个轮廓(`contour`)组成,例如:对于“我”字,这里有两个`contours`:绿色部分+蓝色部分

* 将所有的点位,在`FUnit`坐标系里面进行定位。最终,转换成在对应坐标系下的一系列绘制指令
#### 利用开源工具opentype.js\[5\]解析 TTF 字体文件
* 拿到需求字体的坐标系信息(`ascender`: 最顶部距离`baseline`的距离;`descender`: 最底部距离 baseline 的距离,一般为负数;`unitsPerEm`:`FUnit`的单位格子数,也可以认为是`TTF`字体所在的坐标系大小)
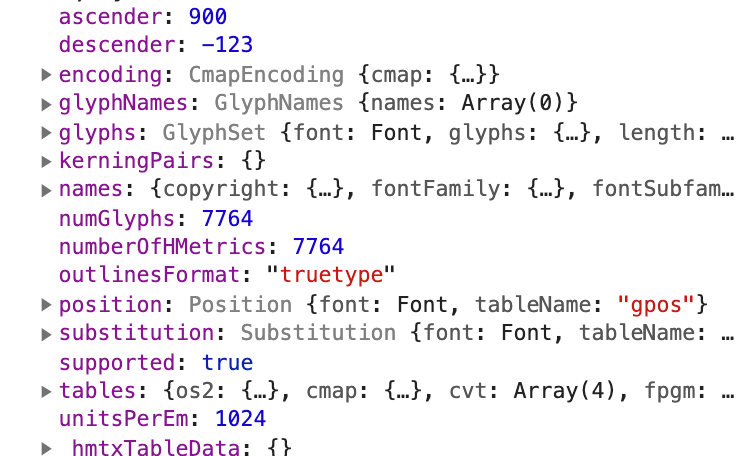
* 获取所有轮廓的点位信息以及点位之间的相连关系 (TTF 连接点位常见命令:MLQZ)

* 统一转换成我们的标准坐标系(1024 \* 1024,baseline 到上下距离分别为 900, 124)
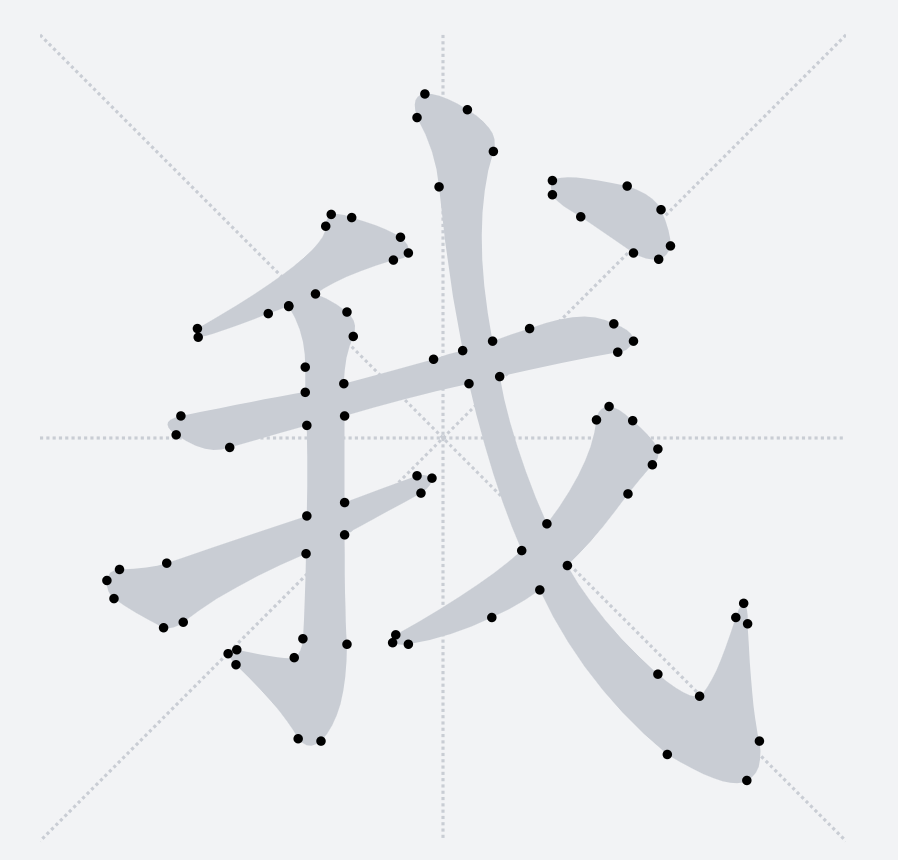
### 笔画拆分
之前提到过,`TTF`字形只会包含多个轮廓,并不感知当前字形具体的笔画细分。下图释义了当前轮廓点将和后面哪一个轮廓点连接成一条路径
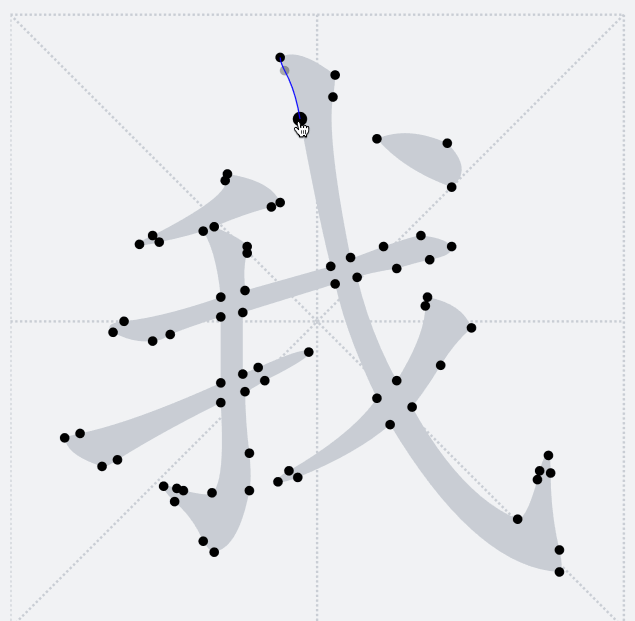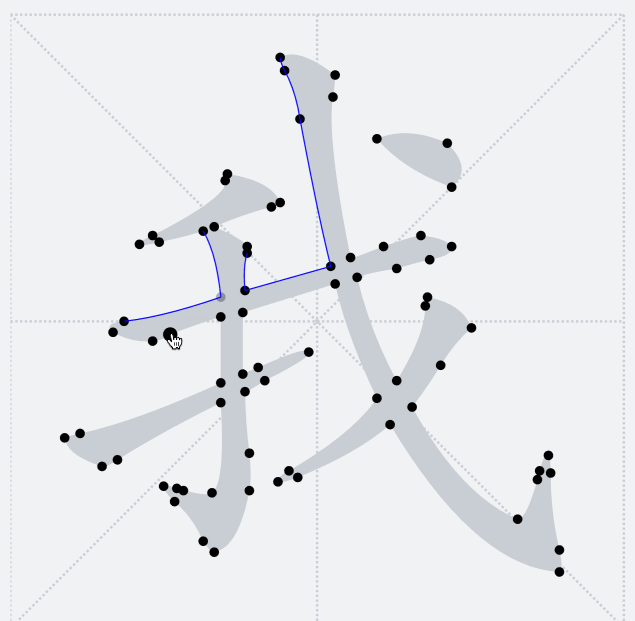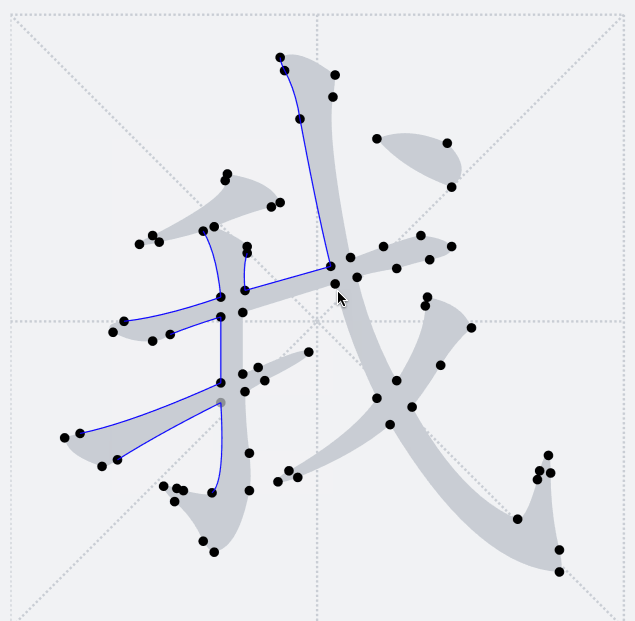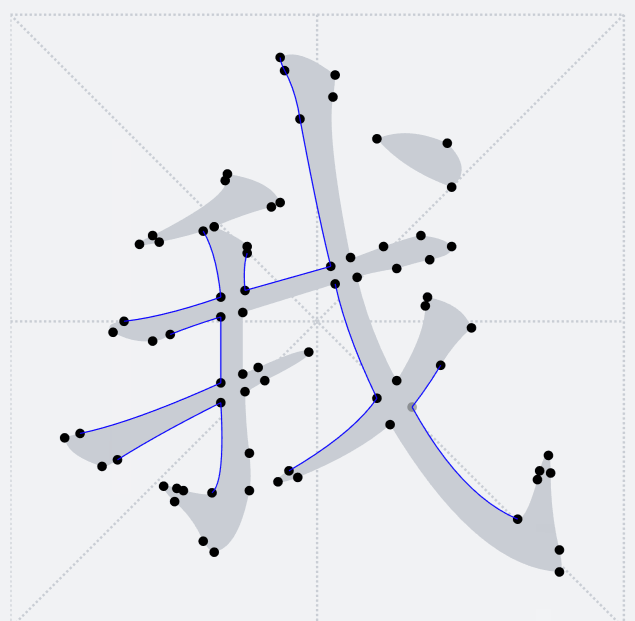
因此,这里我们希望在笔画交界处让路径横穿过去,于是需要其他的方法来将我们需要的汉字笔画拆解出来。将笔画拆解出来的关键是要识别笔画公共交界处。
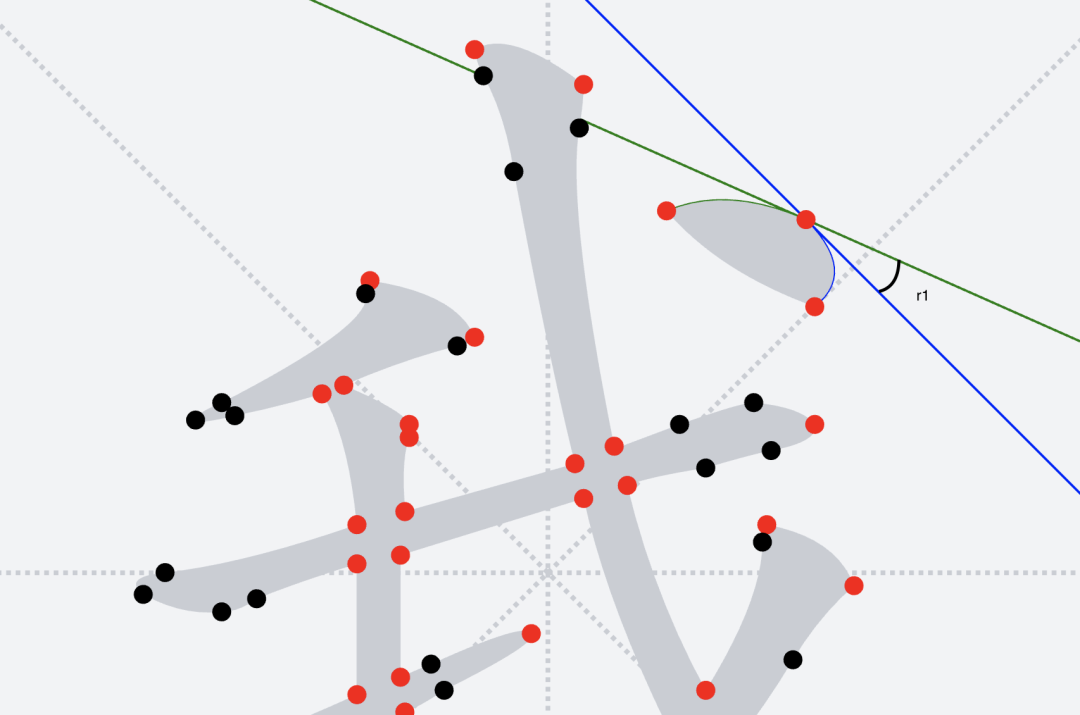
#### 提取 corner 点位
* 通过比较当前点位在前后路径中分别作为终点和起点时候,穿过它的切线角度差(如图中的`r1`),如果这个角度差大于`18°`,则将此点判断为拐点(_`corner`_),代表字形轮廓在此处有比较大的幅度转折,有一定可能是多笔的交界点。
#### 深度学习拿到`corners`之间的匹配度
* 那么如何判断这个`corner`点是不是多笔的交界点呢?这个时候需要比较所有`corner`点,寻找他们之间是否有关联关系。要拿到`corners`中 点与点的关系,需要借助神经网络(模型下载地址\[6\])convnetjs\[7\]进行深度学习,获取`corners`之间的匹配度
* 得到`corners`点与点之间的特征信息
const getFeatures = (ins: EndPoint, out: EndPoint) => {
const diff = out.subtract(ins);
const trivial = diff.equal(new Point([0, 0]));
const angle = Math.atan2(diff[1], diff[0]); // 两点之间斜率的弧度
const distance = Math.sqrt(out.distance2(ins)); // 两点之间的距离
return [
subtractAngle(angle, ins.angles[0]),
subtractAngle(out.angles[1], angle),
subtractAngle(ins.angles[1], angle),
subtractAngle(angle, out.angles[0]),
subtractAngle(ins.angles[1], ins.angles[0]),
subtractAngle(out.angles[1], out.angles[0]),
trivial ? 1 : 0,
distance / MAX_BRIDGE_DISTANCE,
];
};
* 通过模型训练`corners`之间的特征信息,得到对应的匹配分数
const input = new convnetjs.Vol(1, 1, 8 /* feature vector dimensions */ );
const net = new convnetjs.Net();
net.fromJSON(NEURAL_NET_TRAINED_FOR_STROKE_EXTRACTION);
const weight = 0.8;
const trainedClassifier = (features: number[]) => {
input.w = features;
const softmax = net.forward(input).w;
return softmax[1] - softmax[0];
};
* 通过上述,最后得到一个带权重的二分图\[8\]
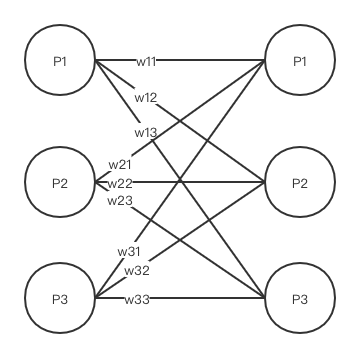
* 利用匈牙利算法\[9\],得到一个最大权重匹配图。当`corner`点最大匹配的对象不是本身的时候,就将它们连接起来形成一个`bridge`(两个`corner`点相连形成的一个线段),当然也要注意去重不要重复连接`bridge`
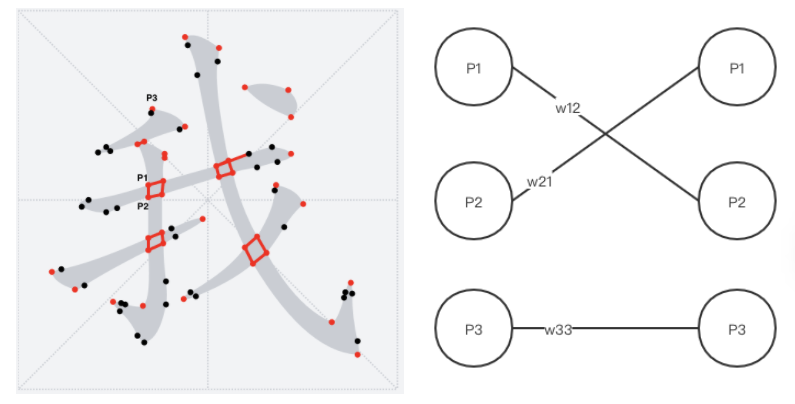
#### 笔画拆分算法
现在我们通过生成`bridge`,能够识别出了笔画的公共交界处了,下一步就需要借助`bridge`来对笔画进行拆分。【下面通过代码片段,以及对应的动画进行解释】
…
const visited = [];
while (true) {
/**
- 直接将目前的路径片段添加到result中
/
result.push(paths[current[0]][current[1]]);
/* 记录当前这一笔visited过的点,到一个局部变量中 /
visited[get2LenArrKey(current)] = true;
/* 去到下一个片段路径的起始点 /
current = advance(current);
const key = get2LenArrKey(current);
/* 判断是否是bridge /
if (bridgeAdjacency.hasOwnProperty(key)) {
endpoint = endpointMap[key];
/*
* 如果当前点位是多个bridge的公共点,
* 则按照“bridge的切线,直线的切线的斜率等于自己的斜率”与“当前路径前进的切线方向”角度差大小 从小到达排列,
* 优先选择与当前路径方向切线角度差最小的
/
const options = bridgeAdjacency[key].sort(
(a, b) => angle(endpoint!.pos, a) - angle(endpoint!.pos, b),
);
const next = options[0];
…
result.push({
start: current,
end: next,
control: undefined,
})
/*
* 这里要注意一个点,current被加入到了路径中,但是没有被打上visited标签就直接到下一个点了,
* 目的是拆解下一笔的时候,这个bridge点就是下一笔的起始点
/
current = next;
}
const newKey = get2LenArrKey(current);
if (comp2LenArr(current, start)) {
/* 当走回到start的点的时候,这一笔就结束了 /
let numSegmentsOnPath = 0;
/* 局部visited 同步到 全局的vistied中 /
for (const index in visited) {
extractedIndices[index] = true;
numSegmentsOnPath += 1;
}
/* 只有一个点的时候,不形成笔画 /
if (numSegmentsOnPath === 1) {
return undefined;
}
return result;
} else if (extractedIndices[newKey] || visited[newKey]) {
/* 访问过的点直接跳过,在这里判断是不允许以被访问过的点开启一下次局部循环判断 */
return undefined;
}
}
…
* 对算法的解释动画
原始轮廓指令有一个默认的顺序【严格有序,`ttf`保证】,所以对于不是`bridge`的点,很容易知道当前点的下一个点是哪一个
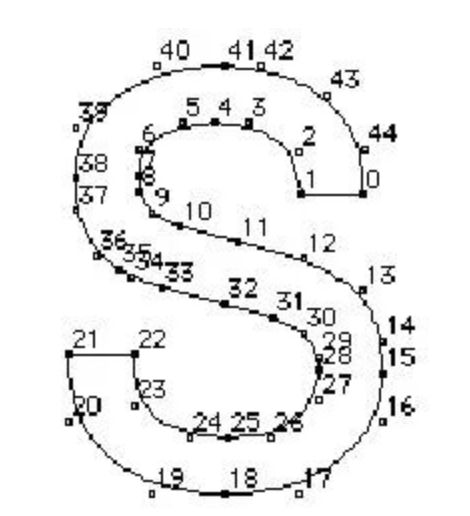
1. 蓝色点代表被标记为`visited`的点【首次碰到`bridge`的一个端点的时候,直接将此点加入路径,并**跳过**`visited`标记,然后走到下一个点】
2. 当遇到的`corner`点处有多个`bridge`的时候,选择`bridge`的斜率角度应该与当前笔画路径前进方向的切线斜率角度差最小
3. 红色的`bridge`可以让笔画直接穿过笔画交界处,并以\*\*线段(`Line`)\*\*将`bridge`的两点相连
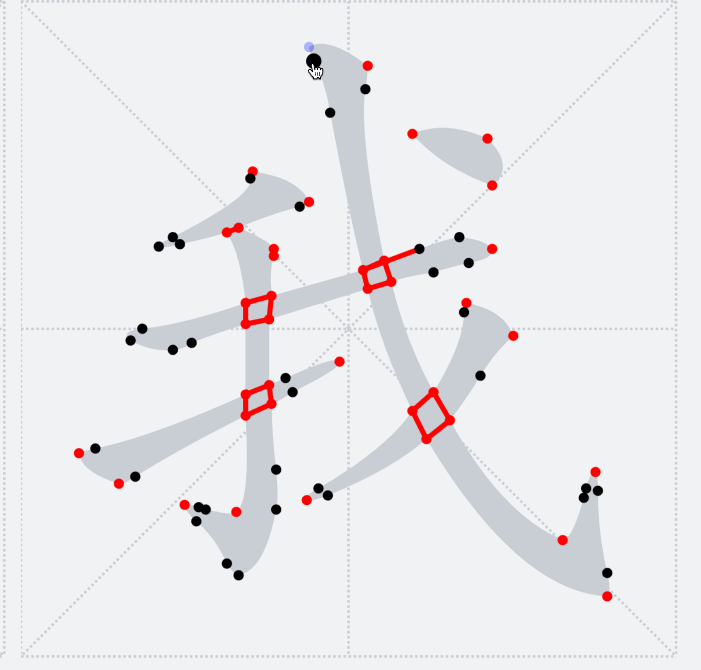
#### 笔画修复
通过`bridge`将笔画拆分以后,可以得到下图的展示,看似完美的背后其实还是有一点儿小瑕疵的:那是因为在`bridge`连接的地方都是通过直线连接,会导致笔锋的位置看上去好像被刀削过一样
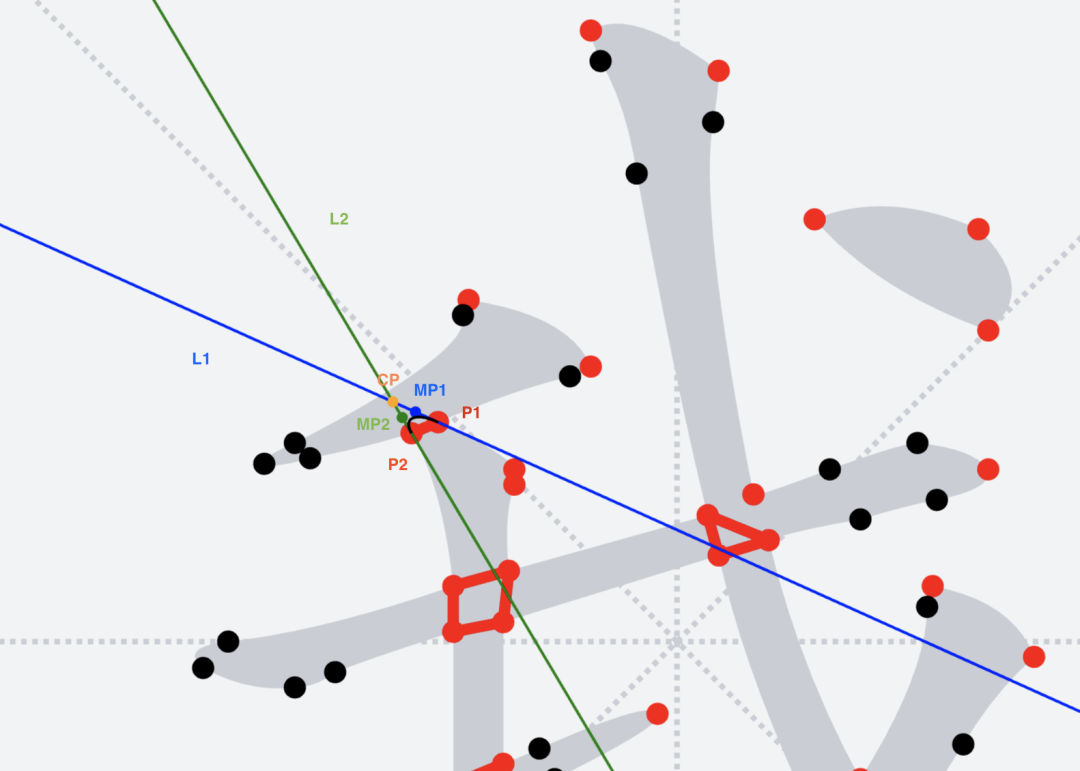
* 将所有直线,换用三次贝塞尔曲线替代
1. `L1`与以`P1`为终点的上一条路径片段相切于`P1`点
2. `L2`与以`P2`为起点的下一条路径片段相切于`P2`点
3. `L1`与`L2`交于`CP`点
4. `MP1`为`P1`与`CP`间的中点;`MP2`为`P2`与`CP`间的中点。这两点将作为贝塞尔曲线的控制点
5. 画三次贝塞尔曲线,即字形图中黑色的曲线
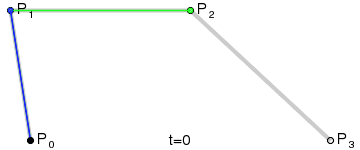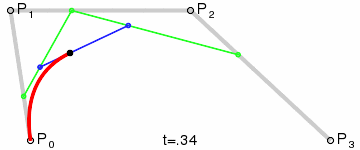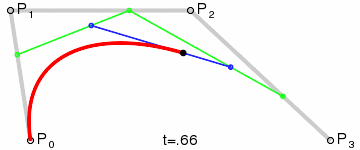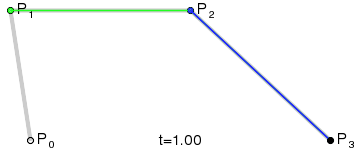
* 修复后的效果
### 笔顺动画
> 拆分完笔画以后,此时便到了确定笔顺动画的时候
#### 获取笔画中位线骨干
* 增加每一笔笔画上的采样点(运用二次贝赛尔曲线公式,拿到更多笔画上的关键点)
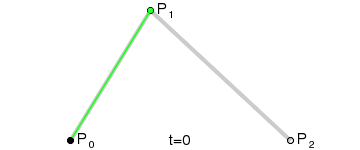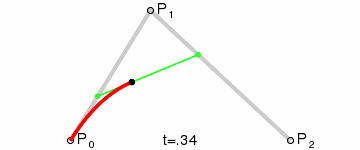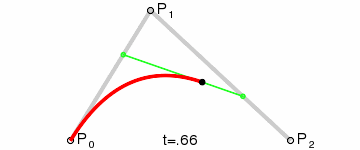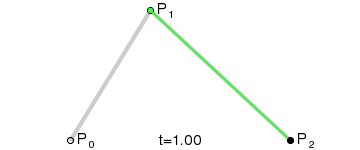
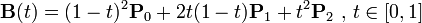
export function getPolygonApproximation(
path: SVGPathType[],
approximationError = 64,
): PolygonType {
const result: Point[] = [];
for (const segment of path) {
const control = segment.control || segment.start.midpoint(segment.end);
const distance = Math.sqrt(segment.start.distance2(segment.end));
const numPoints = Math.floor(distance / approximationError);
for (let i = 0; i < numPoints; i++) {
const t = (i + 1) / (numPoints + 1)
const s = 1 - t;
result.push(
new Point([
s * s * segment.start[0] +
2 * s * t * control[0] +
t * t * segment.end[0],
s * s * segment.start[1] +
2 * s * t * control[1] +
t * t * segment.end[1],
]),
);
}
result.push(segment.end);
}
return result;
}

* voronoijs 泰森多边形 npm 库\[10\](根据扩充后的采样点构成泰森多边形\[11\])
1. 蓝色点为笔画轮廓上的轮廓点(也相当于泰森多边形的采样点)
2. 泰森多边形中每一个多边形内的点到对应的采样点的距离是最短的;也就是说多个多边形的交界点是距离这些多边形中采样点的距离都最短的一个点(也就是图中黑色的点)
3. 留下所有笔画内的黑色点,连接黑色点便可以形成控制该笔画方向的中位线

4. 控制中位线中关键点的数量(保证中位线长度最长,但是点位尽量最少),最终形成下图
#### 笔顺动画排序
> 当拿到所有笔画对应的方向中位线以后,还需要确定笔顺的先后顺序
* 汉字结构梳理:表意文字描述字符\[12\]
| 编码 | 字符 | 意义 | 例字 | 序列 |
| --- | --- | --- | --- | --- |
| U+2FF0 | ⿰ | 两个部件由左至右组成 | 相 | ⿰ 木目 |
| U+2FF1 | ⿱ | 两个部件由上至下组成 | 杏 | ⿱ 木口 |
| U+2FF2 | ⿲ | 三个部件由左至右组成 | 衍 | ⿲ 彳氵亍 |
| U+2FF3 | ⿳ | 三个部件由上至下组成 | 京 | ⿳ 亠口小 |
| U+2FF4 | ⿴ | 两个部件由外而内组成 | 回 | ⿴ 囗口 |
| U+2FF5 | ⿵ | 三面包围,下方开口 | 凰 | ⿵ 几皇 |
| U+2FF6 | ⿶ | 三面包围,上方开口 | 凶 | ⿶ 凵㐅 |
| U+2FF7 | ⿷ | 三面包围,右方开口 | 匠 | ⿷ 匚斤 |
| U+2FF8 | ⿸ | 两面包围,两个部件由左上至右下组成 | 病 | ⿸ 疒丙 |
| U+2FF9 | ⿹ | 两面包围,两个部件由右上至左下组成 | 戒 | ⿹ 戈廾 |
| U+2FFA | ⿺ | 两面包围,两个部件由左下至右上组成 | 超 | ⿺ 走召 |
| U+2FFB | ⿻ | 两个部件重叠 | 巫 | ⿻ 工从 |
* 对于给定的字形,查汉字结构表\[13\]获得该字形的结构拆分,构成结构树
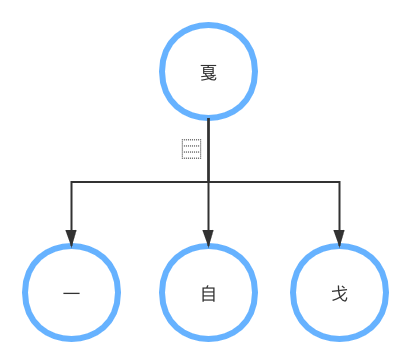
* 中位线
1. ```
将所有子结构的`medians`添加到一个集合(按照结构的拆解顺序加入),
```
```
方便和当前字形生成的`medians`做对比
```
2. ```
对比子字形结构和当前字形结构的`medians`,并对应打上匹配分数,
```
```
转换成带权重的二分图匹配问题
```
const scoreMedians = (median1: number[][], median2: number[][]) => {
assert(median1.length === median2.length);
/** 这里要记两个分值,因为对比的两个median可能刚好只是顺序反了,最后取距离差最小的那个 */
let option1 = 0;
let option2 = 0;
range(median1.length).forEach((i) => {
option1 -= dist2(median1[i], median2[i]);
option2 -= dist2(median1[i], median2[median2.length - i - 1]);
});
return Math.max(option1, option2);
};
3. 利用匈牙利算法,找出最大权重匹配关系,拿到该字形相对子字形结构的笔画顺序排列。
五、总结
----
1. 通过上述算法过后,可以将笔顺数据生成为 json 格式的文件并存储在 CDN 上,文件的平均大小在 4 kB 左右。
2. 笔顺动画数据的生产过程中,用了比较多的推测对比算法,能满足很多字形的 case;但是依然不能百分之百保证数据的准确性(字形复杂的时候,算法很容易误判)。所以,在新字体的数据生成过程中,依然需要人工干预的方式去保证数据的准确性。
3. 目前笔顺后台也是提供了半自动半人工的方式去生产给定字体以及给定字形情况下的笔顺数据。为了降低人工成本,需要探索纠错算法;这样在做批量生成的时候,可以有针对性的进行错误定位。
团队招聘
----
我们团队隶属于字节跳动大力智能部门,一方面从事大力智能作业灯/大力辅导APP以及相关海内外教育产品的前端研发工作,业务场景包含 H5,Flutter,小程序以及各种 Hybrid 场景;另外我们团队在 monorepo,微前端,serverless 等各种前沿前端技术也有一定实践与沉淀。常用的技术栈包括但是不限于 React、TS、Nodejs。扫描下方二维码获取内推码:


**字节前端 ByteFE**
字节前端的技术实践分享
62篇原创内容
公众号
参考资料
\[1\]
Make me han zi: _https://github.com/skishore/makemeahanzi_
\[2\]
stroke-dashoffset, stroke-dasharray 解析: _https://www.cnblogs.com/daisygogogo/p/11044353.html_
\[3\]
MDN clip-path 解析: _https://developer.mozilla.org/zh-CN/docs/Web/CSS/clip-path_
\[4\]
官方-字体配置规定: _https://docs.microsoft.com/zh-cn/typography/opentype/spec/otff#required-tables_
\[5\]
opentype.js: _https://github.com/opentypejs/opentype.js_
\[6\]
模型下载地址: _https://p3.daliapp.net/obj/character-stroke/net.json_
\[7\]
convnetjs: _https://www.npmjs.com/package/convnetjs-ts_
\[8\]
二分图: _https://baike.baidu.com/item/%E4%BA%8C%E5%88%86%E5%9B%BE/9089095?fr=aladdin_
\[9\]
匈牙利算法: _https://zhuanlan.zhihu.com/p/96229700_
\[10\]
voronoijs 泰森多边形 npm 库: _https://www.npmjs.com/package/voronoijs?activeTab=readme_
\[11\]
泰森多边形: _https://zh.wikipedia.org/wiki/%E6%B2%83%E7%BD%97%E8%AF%BA%E4%BC%8A%E5%9B%BE_
\[12\]
表意文字描述字符: _https://zh.wikipedia.org/wiki/%E8%A1%A8%E6%84%8F%E6%96%87%E5%AD%97%E6%8F%8F%E8%BF%B0%E5%AD%97%E7%AC%A6_
\[13\]
汉字结构表: _http://p3.daliapp.net/obj/character-stroke/characterdecomposition.csv_