基於Hive和Spark的淘寶雙11數據分析與預測
1.系統和環境要求(版本僅供參考):
- Linux: centos7
- MySQL: 5.7.16
- Hadoop: 2.7.1
- Hive: 1.2.1
- Sqoop: 1.4.6
- Spark: 2.1.0
- Eclipse: 3.8
- ECharts: 3.4.0
2.數據上傳到Hive( Hive的安裝配置 )
2.1數據集格式內容
數據集壓縮包為 data_format.zip
,該數據集壓縮包是淘寶2015年雙11前6個月(包含雙11)的交易數據(交易數據有偏移,但是不影響實驗的結果),里面包含3個文件,分別是用戶行為日志文件user_log.csv
、回頭客訓練集train.csv 、回頭客測試集test.csv. 下面列出這3個文件的數據格式定義:
1.用戶行為日志user_log.csv,日志中的字段定義如下:
- user_id | 買家id
- item_id | 商品id
- cat_id | 商品類別id
- merchant_id | 賣家id
- brand_id | 品牌id
- month | 交易時間:月
- day | 交易事件:日
- action | 行為,取值范圍{0,1,2,3},0表示點擊,1表示加入購物車,2表示購買,3表示關注商品
- age_range | 買家年齡分段:1表示年齡<18,2表示年齡在[18,24],3表示年齡在[25,29],4表示年齡在[30,34],5表示年齡在[35,39],6表示年齡在[40,49],7和8表示年齡>=50,0和NULL則表示未知
- gender | 性別:0表示女性,1表示男性,2和NULL表示未知
- province| 收獲地址省份
2.回頭客訓練集train.csv和回頭客測試集test.csv,訓練集和測試集擁有相同的字段,字段定義如下:
- 1.user_id | 買家id
- 2.age_range | 買家年齡分段:1表示年齡<18,2表示年齡在[18,24],3表示年齡在[25,29],4表示年齡在[30,34],5表示年齡在[35,39],6表示年齡在[40,49],7和8表示年齡>=50,0和NULL則表示未知
- 3.gender | 性別:0表示女性,1表示男性,2和NULL表示未知
- 4.merchant_id | 商家id
- 5.label | 是否是回頭客,0值表示不是回頭客,1值表示回頭客,-1值表示該用戶已經超出我們所需要考慮的預測范圍。NULL值只存在測試集,在測試集中表示需要預測的值。
3.創建文件根目錄,並將數據集解壓到該目錄
cd /usr/local
ls
sudo mkdir dbtaobao
//這里會提示你輸入當前用戶(本教程是hadoop用戶名)的密碼
//下面給hadoop用戶賦予針對dbtaobao目錄的各種操作權限
sudo chown -R hadoop:hadoop ./dbtaobao
cd dbtaobao
//下面創建一個dataset目錄,用於保存數據集
mkdir dataset
//下面就可以解壓縮data_format.zip文件
cd ~ //表示進入hadoop用戶的目錄
cd 下載
ls
unzip data_format.zip -d /usr/local/dbtaobao/dataset
cd /usr/local/dbtaobao/dataset
ls
**4.dataset目錄下有三個文件:test.csv、train.csv、user_log.csv
查看user_log.csv前面5條記錄([其他花里胡哨的查看方式] **
(https://blog.csdn.net/chenbengang/article/details/104015652)):
head -5 user_log.csv
2.2數據預處理以及上傳到數據庫
1.刪除文件第一行記錄,即字段名稱
cd /usr/local/dbtaobao/dataset
//下面刪除user_log.csv中的第1行
sed -i '1d' user_log.csv //1d表示刪除第1行,同理,3d表示刪除第3行,nd表示刪除第n行
//下面再用head命令去查看文件的前5行記錄,就看不到字段名稱這一行了
head -5 user_log.csv
2.獲取數據集中雙11的前100000條數據
由於數據太大,這里截取數據集中在雙11的前10000條交易數據作為小數據集small_user_log.csv,建立一個腳本文件完成上面截取任務,請把這個腳本文件放在dataset目錄下和數據集user_log.csv:
cd /usr/local/dbtaobao/dataset
vim predeal.sh
predeal.sh文件內容如下:
#!/bin/bash
#下面設置輸入文件,把用戶執行predeal.sh命令時提供的第一個參數作為輸入文件名稱
infile=$1
#下面設置輸出文件,把用戶執行predeal.sh命令時提供的第二個參數作為輸出文件名稱
outfile=$2
#注意!!最后的$infile > $outfile必須跟在}’這兩個字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11 && $7==11){
id=id+1;
print $1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11
if(id==10000){
exit
}
}
}' $infile > $outfile
使用腳本截取數據:
chmod +x ./predeal.sh
./predeal.sh ./user_log.csv ./small_user_log.csv
3.將數據導入數據庫
確保hadoop啟動,jps查看狀態,以下即可:
3765 NodeManager
3639 ResourceManager
3800 Jps
3261 DataNode
3134 NameNode
3471 SecondaryNameNode
hdfs中創建文件的根目錄:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
本地文件上傳到hdfs:
cd /usr/local/hadoop
./bin/hdfs dfs -put /usr/local/dbtaobao/dataset/small_user_log.csv /dbtaobao/dataset/user_log
啟動mysql( hive將元數據存儲在mysql所以必須啟動 ) 和hive:
service mysql start #可以在Linux的任何目錄下執行該命令
cd /usr/local/hive
./bin/hive # 啟動Hive
創建數據庫和外部表(並且將hdfs文件系統的相應文件上傳到hive數據庫)
hive> create database dbtaobao;
hive> use dbtaobao;
hive> CREATE EXTERNAL TABLE dbtaobao.user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to xmu dblab,Now create dbtaobao.user_log!' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/dbtaobao/dataset/user_log';
hive中查詢數據:
hive> select * from user_log limit 10;
3.基於Hive的數據分析
3.1啟動MySQL、Hadoop和Hive,查看數據庫dbtaobao格式
hive> use dbtaobao; -- 使用dbtaobao數據庫
hive> show tables; -- 顯示數據庫中所有表。
hive> show create table user_log; -- 查看user_log表的各種屬性;
3.2簡單結構查詢:
hive> desc user_log;
hive> select brand_id from user_log limit 10; -- 查看日志前10個交易日志的商品品牌
hive> select month,day,cat_id from user_log limit 20;
hive> select ul.at, ul.ci from (select action as at, cat_id as ci from user_log) as ul limit 20;
3.3查詢條數統計分析
用聚合函數count()計算出表內有多少條行數據。加上distinct,查出uid不重復的數據有多少條
hive> select count(*) from user_log; -- 用聚合函數count()計算出表內有多少條行數據
hive> select count(distinct user_id) from user_log; -- 在函數內部加上distinct,查出user_id不重復的數據有多少條
查詢不重復的數據有多少條(為了排除客戶刷單情況) (嵌套語句最好取別名,就是上面的a,否則很容易報cannot recognize錯誤)
hive> select count(*) from (select user_id,item_id,cat_id,merchant_id,brand_id,month,day,action from user_log group by user_id,item_id,cat_id,merchant_id,brand_id,month,day,action having count(*)=1)a;
3.4關鍵字條件查詢分析
查詢雙11那天有多少人購買了商品
hive> select count(distinct user_id) from user_log where action='2';
取給定時間和給定品牌,求當天購買的此品牌商品的數量
hive> select count(*) from user_log where action='2' and brand_id=2661;
3.5.根據用戶行為分析
查詢一件商品在某天的購買比例或瀏覽比例
hive> select count(distinct user_id) from user_log where action='2'; -- 查詢有多少用戶在雙11購買了商品
hive> select count(distinct user_id) from user_log; -- 查詢有多少用戶在雙11點擊了該店
查詢雙11那天,男女買家購買商品的比例
hive> select count(*) from user_log where gender=0; --查詢雙11那天女性購買商品的數量
hive> select count(*) from user_log where gender=1; --查詢雙11那天男性購買商品的數量
給定購買商品的數量范圍,查詢某一天在該網站的購買該數量商品的用戶id
hive> select user_id from user_log where action='2' group by user_id having count(action='2')>5; -- 查詢某一天在該網站購買商品超過5次的用戶id
3.6.用戶實時查詢分析
不同的品牌的瀏覽次數
hive> create table scan(brand_id INT,scan INT) COMMENT 'This is the search of bigdatataobao' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; -- 創建新的數據表進行存儲
hive> insert overwrite table scan select brand_id,count(action) from user_log where action='2' group by brand_id; --導入數據
hive> select * from scan; -- 顯示結果
4.使用Sqoop將數據從Hive導入MySQL( [ sqoop安裝教程
](http://dblab.xmu.edu.cn/blog/install-sqoop1/) )
4.1.hive預操作 (確保啟動mysql、hadoop和hive)
- 創建臨時表inner_user_log和inner_user_info。執行完以后,Hive會自動在HDFS文件系統中創建對應的數據文件“/user/hive/warehouse/dbtaobao.db/inner_user_log”。
hive> create table dbtaobao.inner_user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_id INT,month STRING,day STRING,action INT,age_range INT,gender INT,province STRING) COMMENT 'Welcome to XMU dblab! Now create inner table inner_user_log ' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
- 將user_log表中的數據插入到inner_user_log,
前面已經在Hive中的dbtaobao數據庫中創建了一個外部表user_log,把dbtaobao.user_log數據插入到dbtaobao.inner_user_log表中,並查詢是否上傳成功:
hive> INSERT OVERWRITE TABLE dbtaobao.inner_user_log select * from dbtaobao.user_log;
hive> select * from inner_user_log limit 10;
4.2使用Sqoop將數據從Hive導入MySQL
- 1.登錄mysql,創建數據庫, 修改數據庫編碼格式 ,創建表格:
mysql –u root –p
mysql> show databases; #顯示所有數據庫
mysql> create database dbtaobao; #創建dbtaobao數據庫
mysql> use dbtaobao; #使用數據庫
mysql> show variables like "char%";
mysql> CREATE TABLE `dbtaobao`.`user_log` (`user_id` varchar(20),`item_id` varchar(20),`cat_id` varchar(20),`merchant_id` varchar(20),`brand_id` varchar(20), `month` varchar(6),`day` varchar(6),`action` varchar(6),`age_range` varchar(6),`gender` varchar(6),`province` varchar(10)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
提示:語句中的引號是反引號`,不是單引號’。需要注意的是,sqoop抓數據的時候會把類型轉為string類型,所以mysql設計字段的時候,設置為varchar。
- 2.導入數據:
cd /usr/local/sqoop
bin/sqoop export --connect jdbc:mysql://localhost:3306/dbtaobao --username root --password root --table user_log --export-dir '/user/hive/warehouse/dbtaobao.db/inner_user_log' --fields-terminated-by ',';
字段解釋:
./bin/sqoop export ##表示數據從 hive 復制到 mysql 中
–connect jdbc:mysql://localhost:3306/dbtaobao
–username root #mysql登陸用戶名
–password root #登錄密碼
–table user_log #mysql 中的表,即將被導入的表名稱
–export-dir ‘/user/hive/warehouse/dbtaobao.db/user_log ‘ #hive 中被導出的文件,hdfs中存的
–fields-terminated-by ‘,’ #Hive 中被導出的文件字段的分隔符
- 3.查看mysql中的數據:
mysql -u root -p
mysql> use dbtaobao;
mysql> select * from user_log limit 10;
5.Spark預測回頭客行為
5.1預處理test.csv和train.csv數據集
- 1.字段描述和定義
1.user_id | 買家id
2.age_range |
買家年齡分段:1表示年齡<18,2表示年齡在[18,24],3表示年齡在[25,29],4表示年齡在[30,34],5表示年齡在[35,39],6表示年齡在[40,49],7和8表示年齡>=50,0和NULL則表示未知
3.gender | 性別:0表示女性,1表示男性,2和NULL表示未知
4.merchant_id | 商家id
5.label |
是否是回頭客,0值表示不是回頭客,1值表示回頭客,-1值表示該用戶已經超出我們所需要考慮的預測范圍。NULL值只存在測試集,在測試集中表示需要預測的值。
- 2.需要預先處理test.csv數據集,把這test.csv數據集里label字段表示-1值剔除掉,保留需要預測的數據.並假設需要預測的數據中label字段均為1:
cd /usr/local/dbtaobao/dataset
vim predeal_test.sh
predeal_test.sh腳本文件:
#!/bin/bash
#下面設置輸入文件,把用戶執行predeal_test.sh命令時提供的第一個參數作為輸入文件名稱
infile=$1
#下面設置輸出文件,把用戶執行predeal_test.sh命令時提供的第二個參數作為輸出文件名稱
outfile=$2
#注意!!最后的$infile > $outfile必須跟在}’這兩個字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && !$5){
id=id+1;
print $1","$2","$3","$4","1
if(id==10000){
exit
}
}
}' $infile > $outfile
chmod +x ./predeal_test.sh
./predeal_test.sh ./test.csv ./test_after.csv
- 3.train.csv的第一行都是字段名稱,不需要第一行字段名稱,這里在對train.csv做數據預處理時,刪除第一行
sed -i '1d' train.csv
然后剔除掉train.csv中字段值部分字段值為空的數據
cd /usr/local/dbtaobao/dataset
vim predeal_train.sh
#!/bin/bash
#下面設置輸入文件,把用戶執行predeal_train.sh命令時提供的第一個參數作為輸入文件名稱
infile=$1
#下面設置輸出文件,把用戶執行predeal_train.sh命令時提供的第二個參數作為輸出文件名稱
outfile=$2
#注意!!最后的$infile > $outfile必須跟在}’這兩個字符的后面
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && ($5!=-1)){
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000){
exit
}
}
}' $infile > $outfile
截取得到訓練數據:
chmod +x ./predeal_train.sh
./predeal_train.sh ./train.csv ./train_after.csv
5.2預測回頭客
- 1.啟動hadoop,創建文件目錄
bin/hadoop fs -mkdir -p /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/train_after.csv /dbtaobao/dataset
bin/hadoop fs -put /usr/local/dbtaobao/dataset/test_after.csv /dbtaobao/dataset
- 2.啟動mysql創建rebuy表
use dbtaobao;
create table rebuy (score varchar(40),label varchar(40));
- 3.使用spark連接mysql數據庫,Spark支持通過JDBC方式連接到其他數據庫獲取數據生成DataFrame。 下載MySQL的JDBC驅動 (mysql-connector-java-5.1.40.zip)。unzip命令解壓后將jar包拷貝到集群每個節點spark下的jars目錄下,啟動spark-submit
cd ~/下載/
unzip mysql-connector-java-5.1.40.zip -d /usr/local/spark/jars
cd /usr/local/spark
./bin/spark-shell --jars /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar --driver-class-path /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar
5.3支持向量機SVM分類器預測回頭客
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.{Vectors,Vector}
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
// val conf = new SparkConf().setAppName("taobao").setMaster("local[2]")
// val sc = new SparkContext(conf)
// 加載數據
val train_data = sc.textFile("/opt/dbtaobao/dataset/train_after.csv")
val test_data = sc.textFile("/opt/dbtaobao/dataset/test_after.csv")
// 構建訓練數據和測試數據
val train= train_data.map{line =>
val parts = line.split(',')
LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts
(2).toDouble,parts(3).toDouble))
}
val test = test_data.map{line =>
val parts = line.split(',')
LabeledPoint(parts(4).toDouble,Vectors.dense(parts(1).toDouble,parts(2).toDouble,parts(3).toDouble))
}
// 構建模型
val numIterations = 1000
val model = SVMWithSGD.train(train, numIterations)
// 查看測試集的預測結果
model.clearThreshold()
val scoreAndLabels = test.map{point =>
val score = model.predict(point.features)
score+" "+point.label
}
scoreAndLabels.foreach(println)
model.setThreshold(0.0)
scoreAndLabels.foreach(println)
model.clearThreshold()
val scoreAndLabels = test.map{point =>
val score = model.predict(point.features)
score+" "+point.label
}
//設置回頭客數據
val rebuyRDD = scoreAndLabels.map(_.split(" "))
//下面要設置模式信息
val schema = StructType(List(StructField("score", StringType, true),StructField("label", StringType, true)))
//下面創建Row對象,每個Row對象都是rowRDD中的一行
val rowRDD = rebuyRDD.map(p => Row(p(0).trim, p(1).trim))
//建立起Row對象和模式之間的對應關系,也就是把數據和模式對應起來
val rebuyDF = spark.createDataFrame(rowRDD, schema)
//下面創建一個prop變量用來保存JDBC連接參數
val prop = new Properties()
prop.put("user", "root") //表示用戶名是root
prop.put("password", "hadoop") //表示密碼是hadoop
prop.put("driver","com.mysql.jdbc.Driver") //表示驅動程序是com.mysql.jdbc.Driver
//下面就可以連接數據庫,采用append模式,表示追加記錄到數據庫dbtaobao的rebuy表中
rebuyDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/dbtaobao", "dbtaobao.rebuy", prop)
6.ECharts進行數據可視化分析
**6.1.使用myeclipse+tomcat構建j2ee項目,連接mysql數據庫。也可遠程連接集群上的mysql數據庫。連接並操作mysql數據庫的后端代碼,前端采用js(
可視化項目源代碼下載 ): **
package dbtaobao;
import java.sql.*;
import java.util.ArrayList;
public class connDb {
private static Connection con = null;
private static Statement stmt = null;
private static ResultSet rs = null;
//連接數據庫方法
public static void startConn(){
try{
Class.forName("com.mysql.jdbc.Driver");
//連接數據庫中間件
try{
con = DriverManager.getConnection("jdbc:MySQL://localhost:3306/dbtaobao","root","root");
}catch(SQLException e){
e.printStackTrace();
}
}catch(ClassNotFoundException e){
e.printStackTrace();
}
}
//關閉連接數據庫方法
public static void endConn() throws SQLException{
if(con != null){
con.close();
con = null;
}
if(rs != null){
rs.close();
rs = null;
}
if(stmt != null){
stmt.close();
stmt = null;
}
}
//數據庫雙11 所有買家消費行為比例
public static ArrayList index() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select action,count(*) num from user_log group by action desc");
while(rs.next()){
String[] temp={rs.getString("action"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//男女買家交易對比
public static ArrayList index_1() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,count(*) num from user_log group by gender desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//男女買家各個年齡段交易對比
public static ArrayList index_2() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select gender,age_range,count(*) num from user_log group by gender,age_range desc");
while(rs.next()){
String[] temp={rs.getString("gender"),rs.getString("age_range"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//獲取銷量前五的商品類別
public static ArrayList index_3() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select cat_id,count(*) num from user_log group by cat_id order by count(*) desc limit 5");
while(rs.next()){
String[] temp={rs.getString("cat_id"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
//各個省份的總成交量對比
public static ArrayList index_4() throws SQLException{
ArrayList<String[]> list = new ArrayList();
startConn();
stmt = con.createStatement();
rs = stmt.executeQuery("select province,count(*) num from user_log group by province order by count(*) desc");
while(rs.next()){
String[] temp={rs.getString("province"),rs.getString("num")};
list.add(temp);
}
endConn();
return list;
}
}
6.2可視化結果




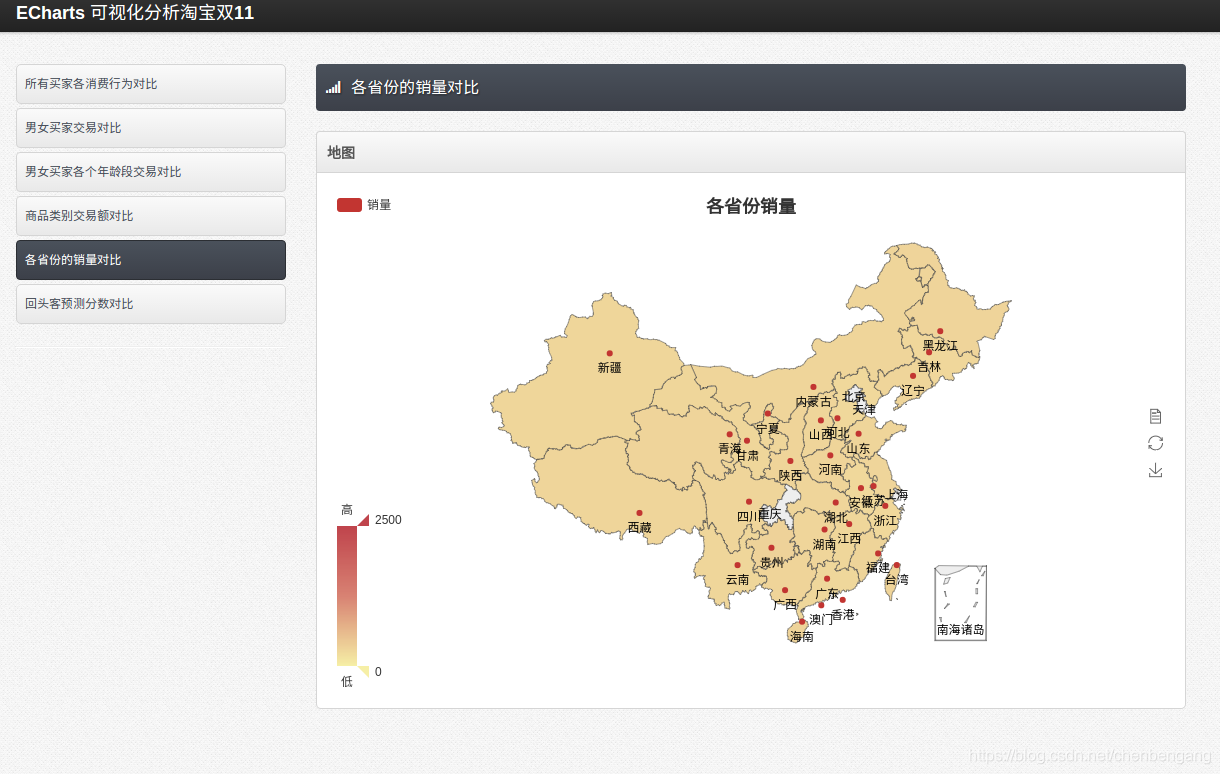
給出的源代碼中未解決最后一個可視化,自行下載china.js,獲取省份位置以及數量進行可視化。
