“
最近一份據說是埃森哲的大數據分析PPT莫名被朋友分享,真實與否暫不考究,但是就PPT內容來說,對於數據分析還是很翔實的,有很多實用的大數據分析方法
”
0、簡述
PPT的內容非常多,具體目錄:
1、概述
2、數據分析框架
3、數據分析方法
- **3.1 數據理解 &數據准備 **
- 3.2 分類與回歸
- 3.3 聚類分析
- 3.4 關聯分析
- 3.5 時序模型
- 3.6 結構優化
4、數據分析支撐工具
先給大家說一下,我這篇文章寫什么:
1、總結 「埃森哲」 大數據分析PPT內容;
2、里面有些內容可能比較久遠,我會補充下我所知道的現在比較常用的方法;
3、原PPT的分享內容文字敘述總結居多,我會根據我們日常的工作,編輯一些相關案例,幫助理解;
4、針對 「埃森哲」 公司分享的這個PPT里面的具體方法,我會給出相應地python實現方式,應用起來更方便。
我不確定我是否有公開該PPT的權限,所以就不把PPT放在文章里,如果大家有需要,直接后台留言/回復「數據分析」,我再告訴大家獲取方法。
1、概述
數據分析到底是一個什么樣的工作,由於她的涵蓋范圍非常廣,平時我們經常遇到不同專業的同學成為一名數據分析師,可能是學計算機的,或者是金融工程,也可能是學數學或者統計,數據分析作為一個多學科交叉工種所包含的學科知識也是五花八門,在我理解,數據分析師入門需要掌握4種能力:業務理解能力、數學/統計知識、數據庫操作能力,編程能力。
業務理解能力對於數據分析師來說是至關重要的,業務經驗可以幫助我們在分析具體問題前明確需求,在分析中可以判斷方法是否合理以及分析后的指導應用。
“隨着計算機科學的發展,數據挖掘,機器學習,深度學習,大數據等概念越來越熱,數據分析的手段和方法也越來越豐富”
這也恰恰意味着數據分析不拘一格,做數據分析的工作同樣可以將機器學習甚至深度學習的相關算法加以應用在工作中。
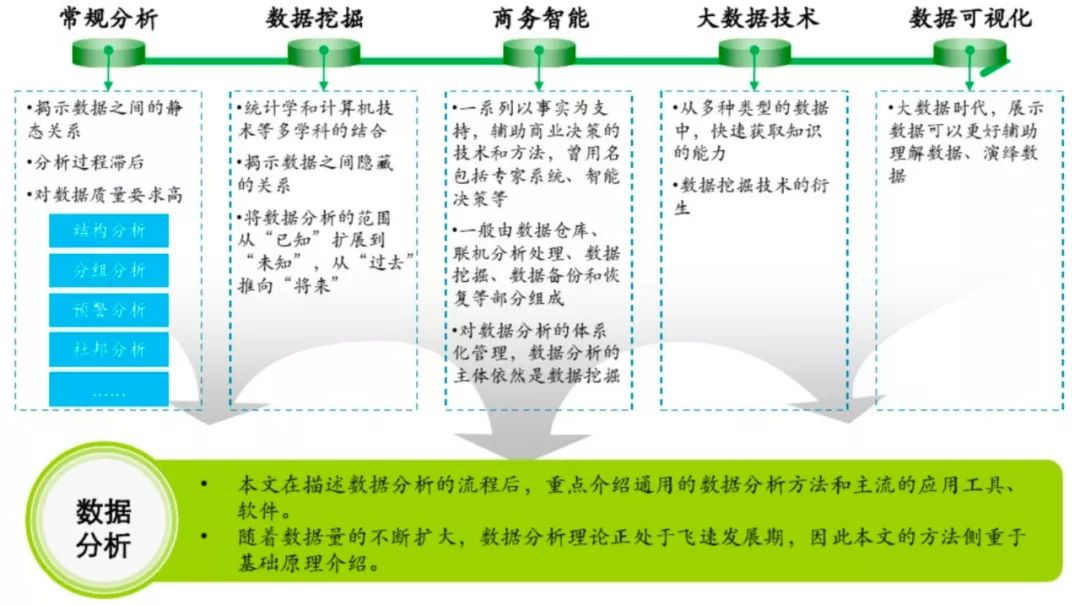
(圖片來自原PPT)
2、數據分析框架
「埃森哲」 的數據分析框架基本完全遵循CRISP-
DM模型,非常經典的數據分析標准流程,采用量應該在50%左右;聽說過這個模型的同學應該相當多吧,尤其是有咨詢公司背景的同學,有了這個框架,那我們如何實現具體流程的呢?
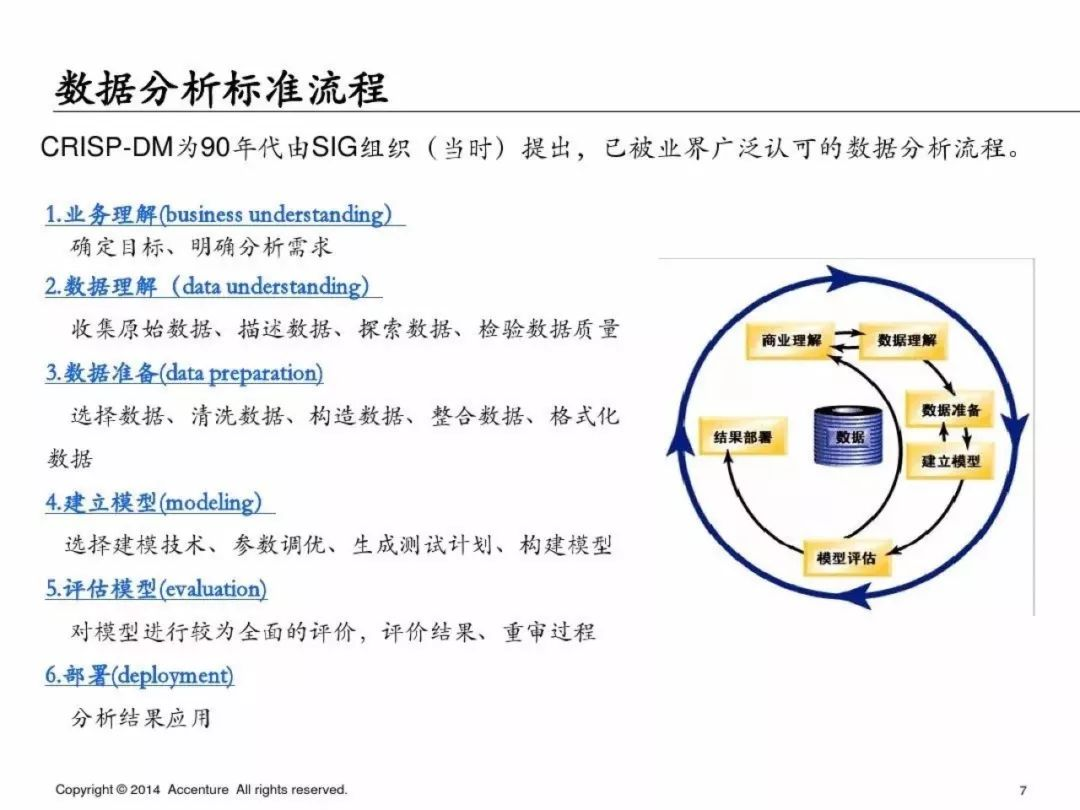
(圖片來自原PPT)
CRISP-DM (cross-industry standard process for data mining),
即為"跨行業數據挖掘標准流程",CRISP-DM 模型是KDD(KDD:Knowledge Discovery in
Database)模型的一種,最近幾年在各種KDD過程模型中占據領先位置,它是由戴姆勒-
克萊斯勒、SPSS和NCR的分析人員共同開發的。CRISP提供了一種開放的、可自由使用的數據挖掘標准過程,使數據挖掘適合於商業或研究單位的問題求解策略。
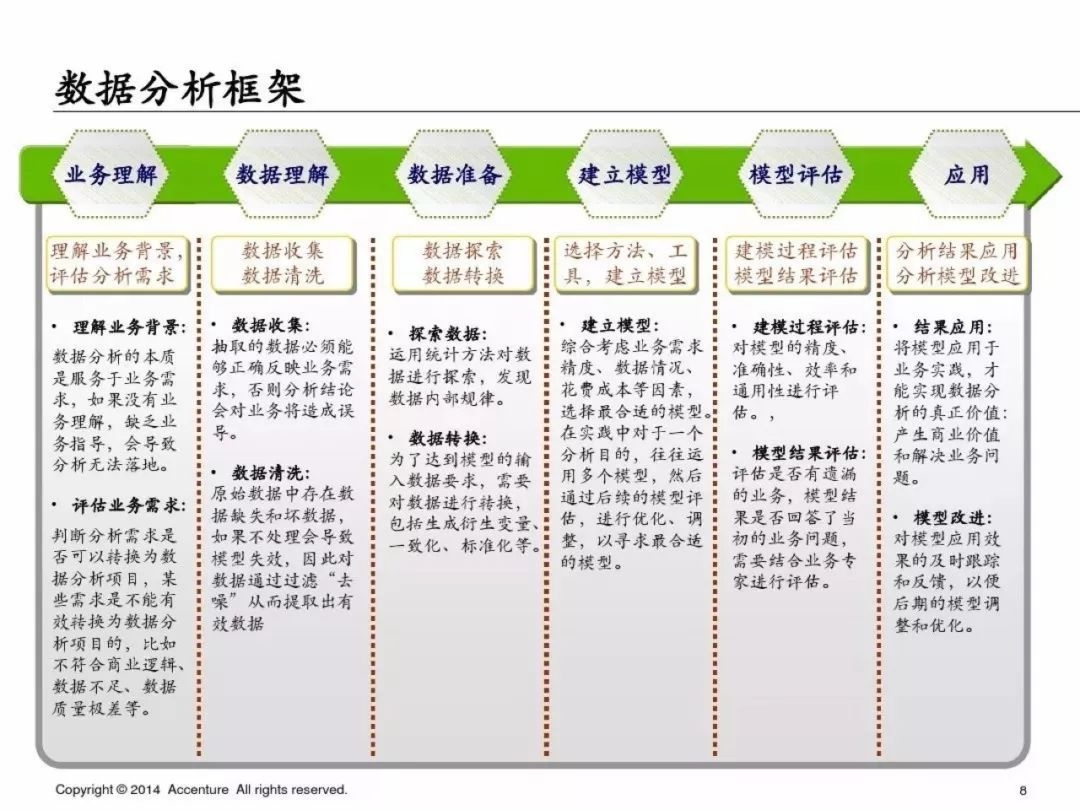
從我自己的理解:如果我們的分析需要建立模型,那么這個流程其實缺少模型監控,在完成建模分析后,我們需要持續觀測模型的穩定性和准確度,在發現問題時可能需要及時的refit我們的模型。
當我們需要建模來解決某個業務問題時,這個就是數據分析的基本框架。但是我覺得這個框架里在建立模型時可以做一些補充:
(這里補充上自己做的關於模型選擇的思維導圖)
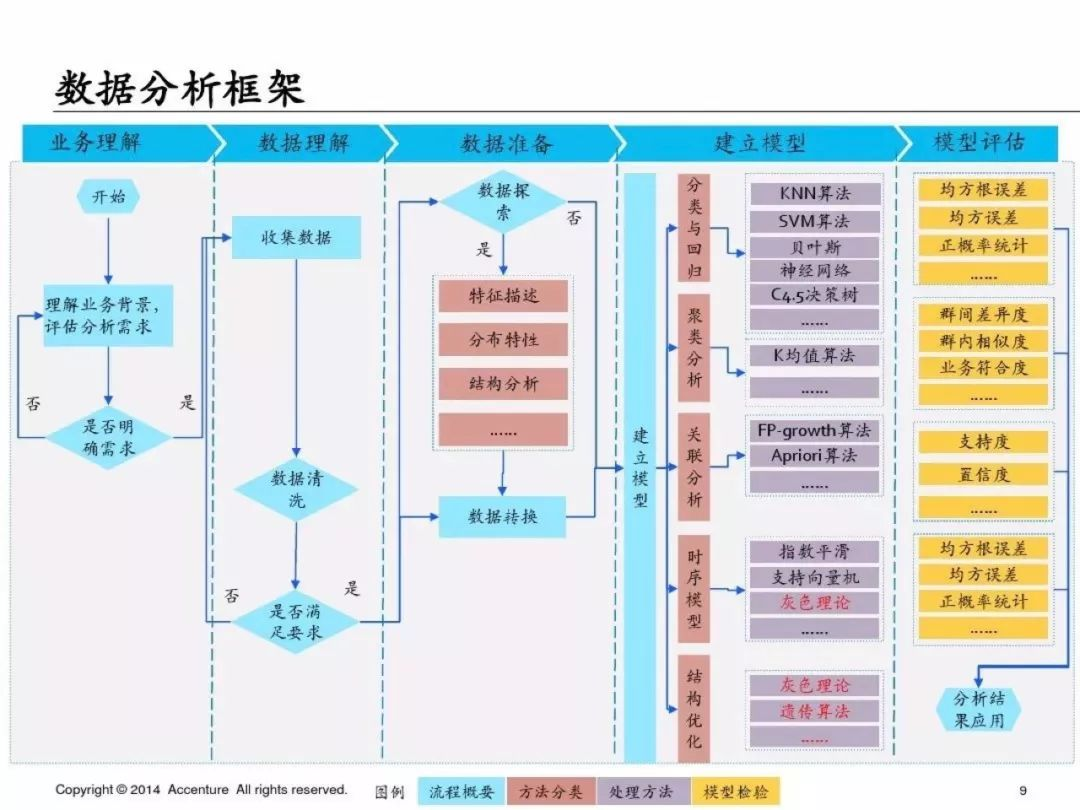
3、數據分析方法
3.1數據清洗&數據探索
在我們拿到數據時首先我們需要對數據進行清洗:
這里一些一定要做的就是:異常值判斷、缺失值處理、重復值處理、數據結構變化;
數據探索:主要是特征描述、數據分布、結構優化、變量相關性。
這里說一下我每次會用到的方法,用一行代碼直接完成數據描述:
import pandas_profiling
data.profile_report(title='Model Dataset')
profile = data.profile_report(title='Model Dataset')
profile.to_file(output_file='model_report.html')
[/code]
常見異常值的判斷方法:
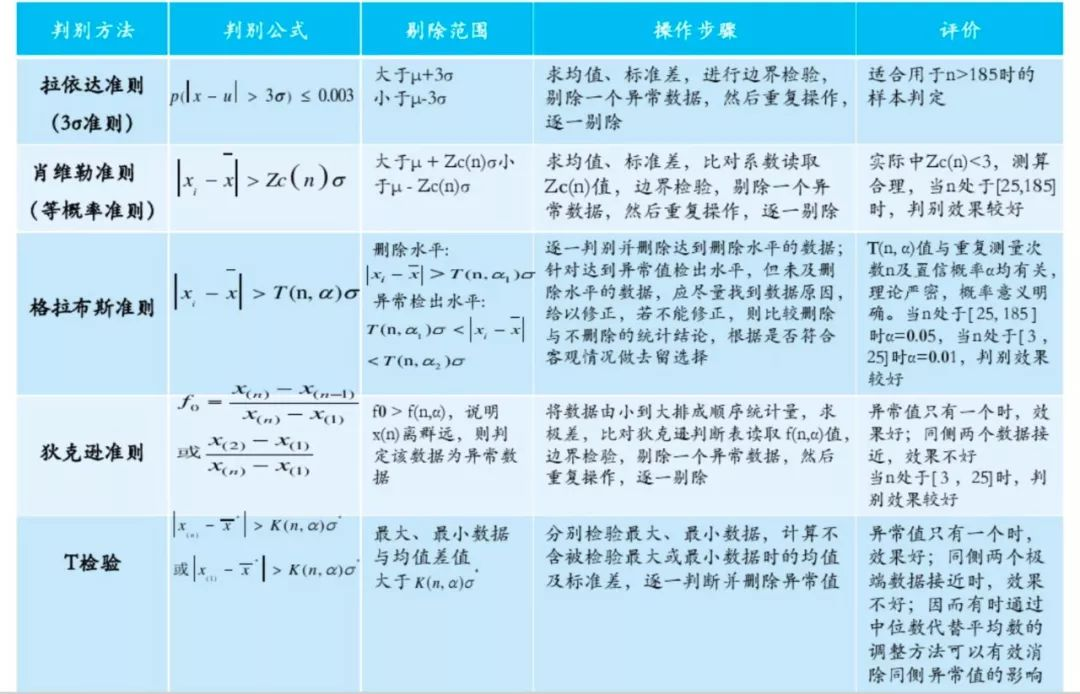
缺失值的處理方法:平均值/固定值/眾數/中位數/上下條數據等填充、K最近距離法、回歸、極大似然估計、多重插值等
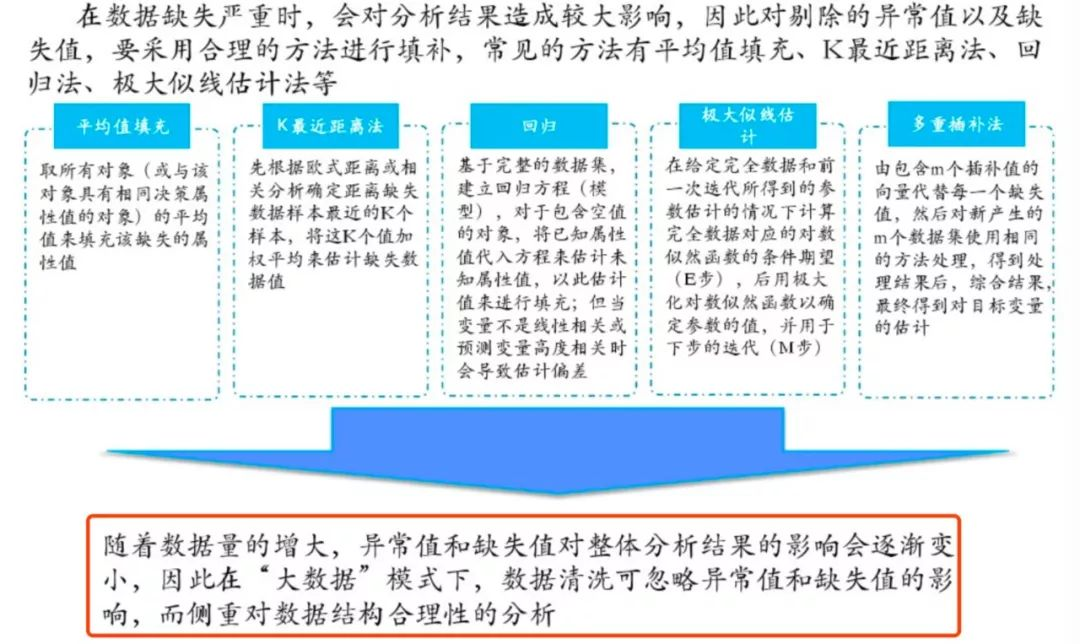
原PPT里的這一句我是完全不贊同的,在某些情況下異常值和缺失值缺失影響會比較小,但是並不可以忽略,尤其是異常值,某些情況下非常影響結果,還是需要引起重視。
對於缺失值的處理,除了直接刪除缺失嚴重的特征外,還可以選擇各種各樣的填充方法。對於每一種填充方式而言,都有其適用的場景,沒有絕對的好壞之分,因此在做數據預處理時,要多嘗試幾種填充方法,選擇表現最佳的即可。
上述缺失值處理方法的代碼參考:https://github.com/AHNU/fill_missing_values
舉一個KNN填充缺失值得例子:
填充近鄰的數據,先利用knn計算臨近的k個數據,然后填充他們的均值。(安裝fancyimpute)除了knn填充,fancyimpute還提供了其他填充方法。
```code
from fancyimpute import KNN
train_data = pd.DataFrame(KNN(k=8).fit_transform(train_data), columns=features)
[/code]
**數據探索**
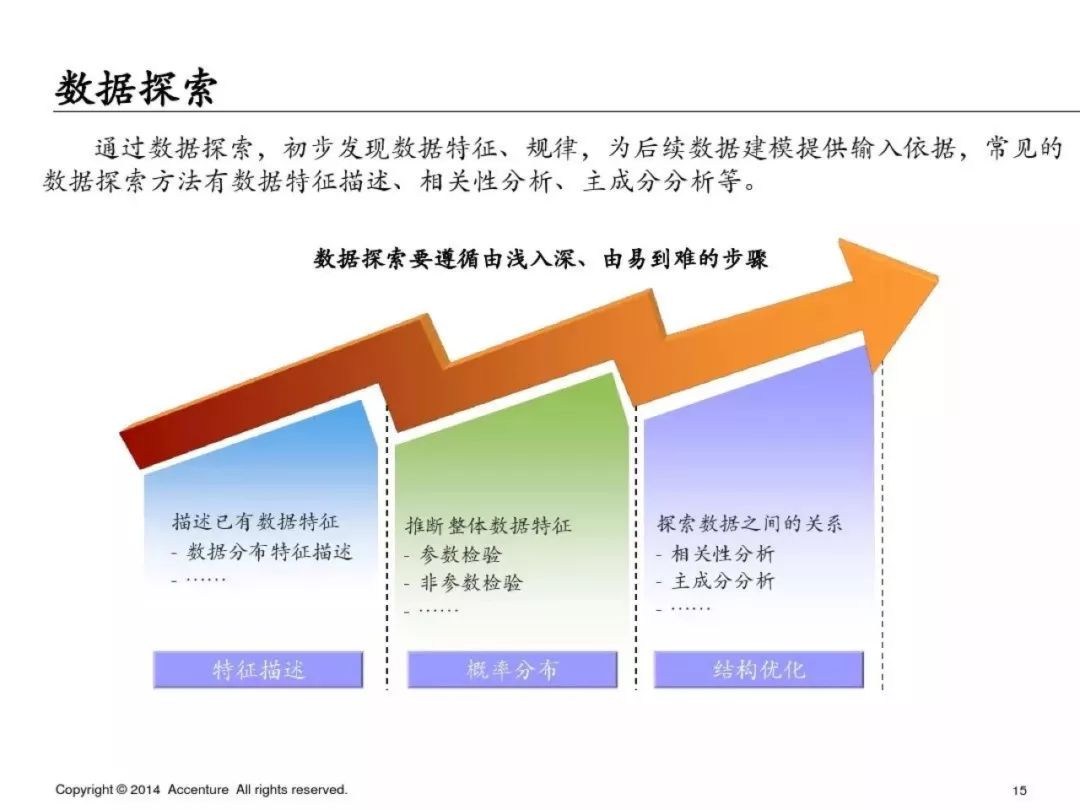
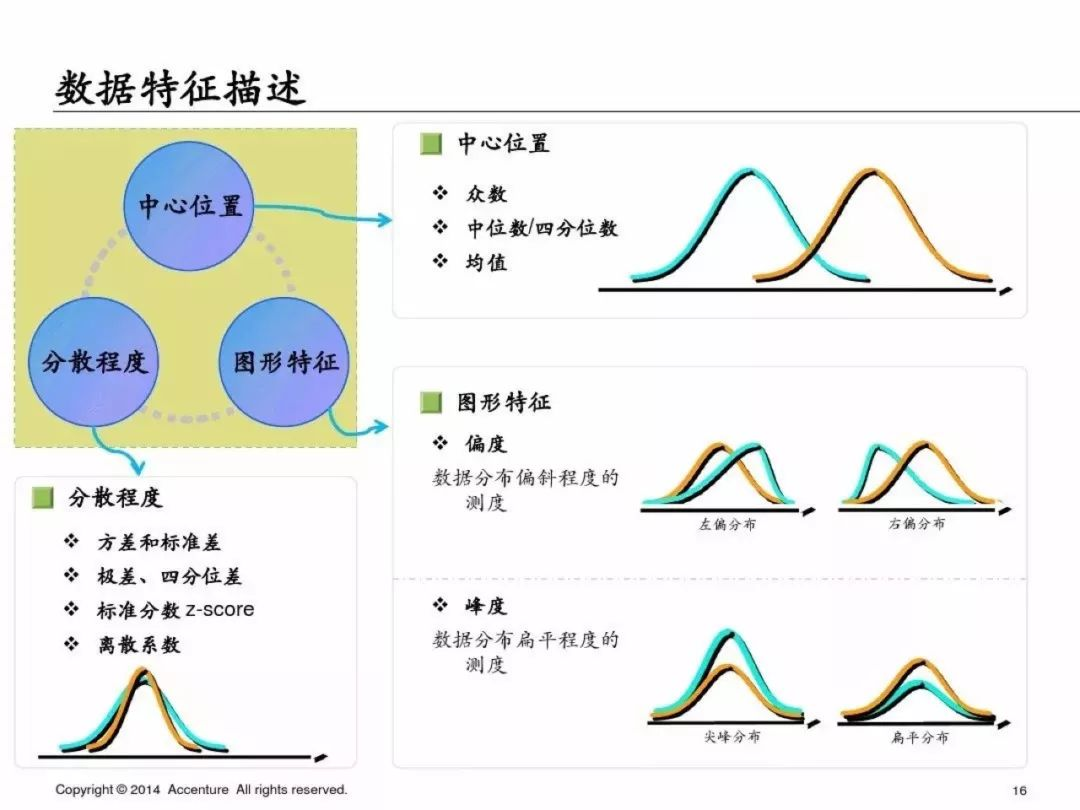
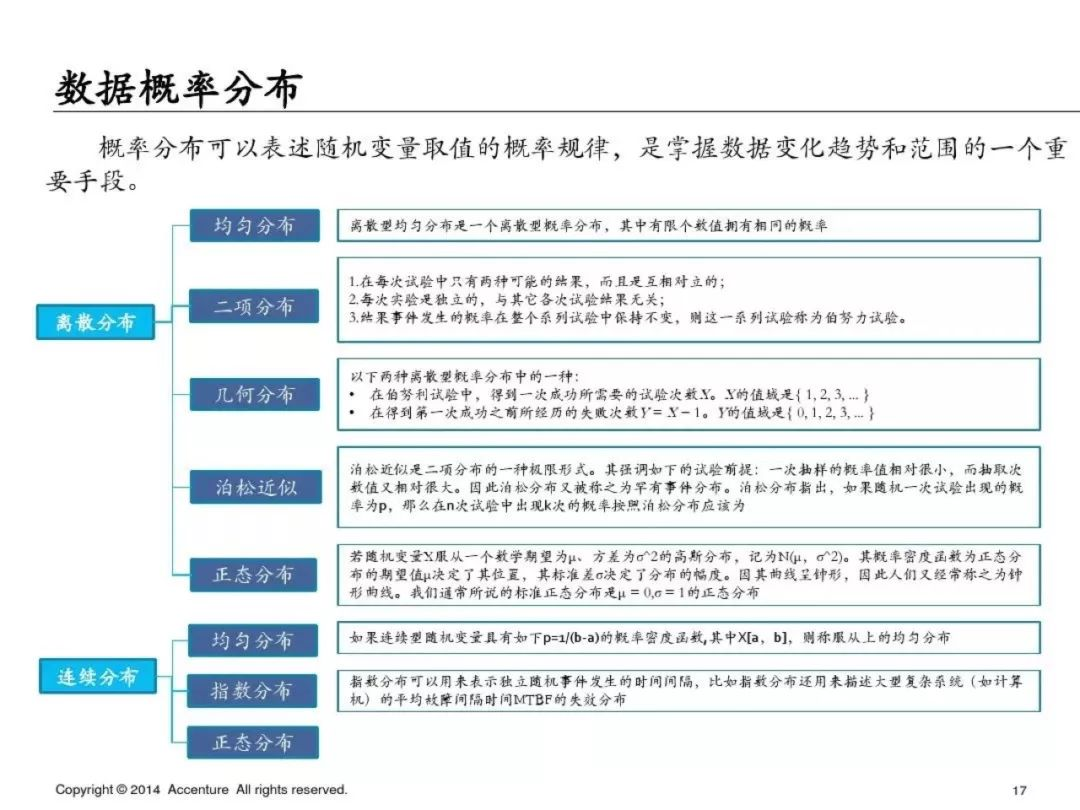
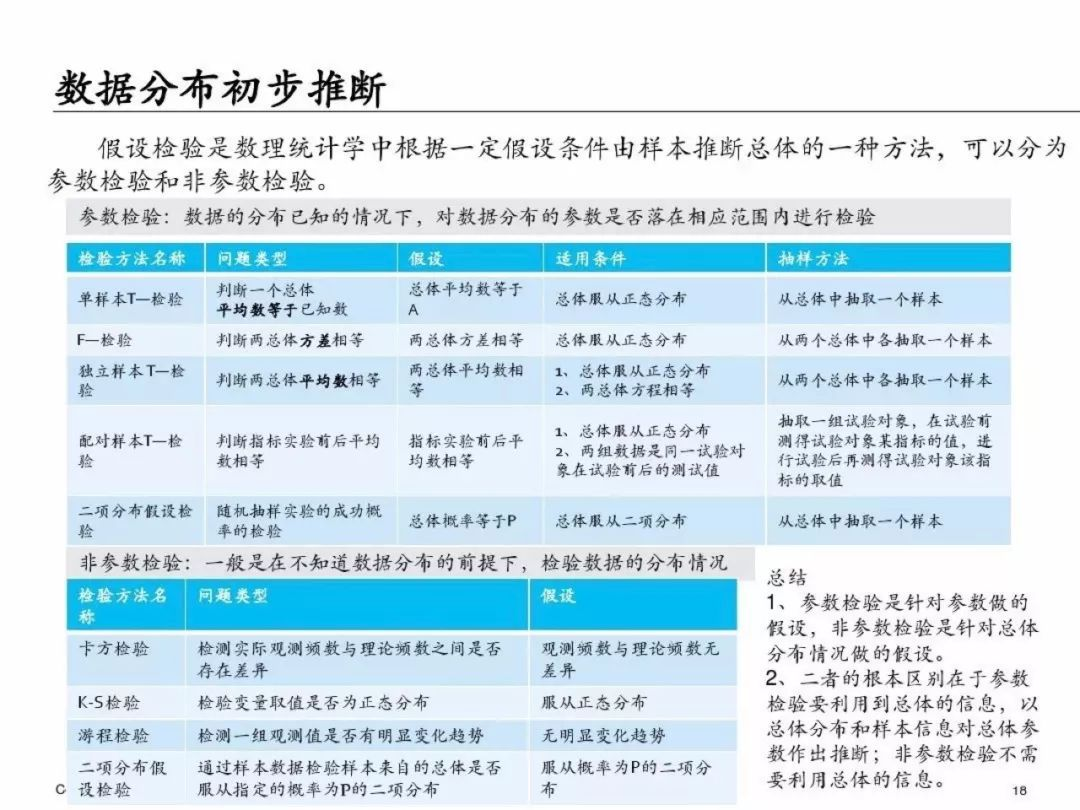
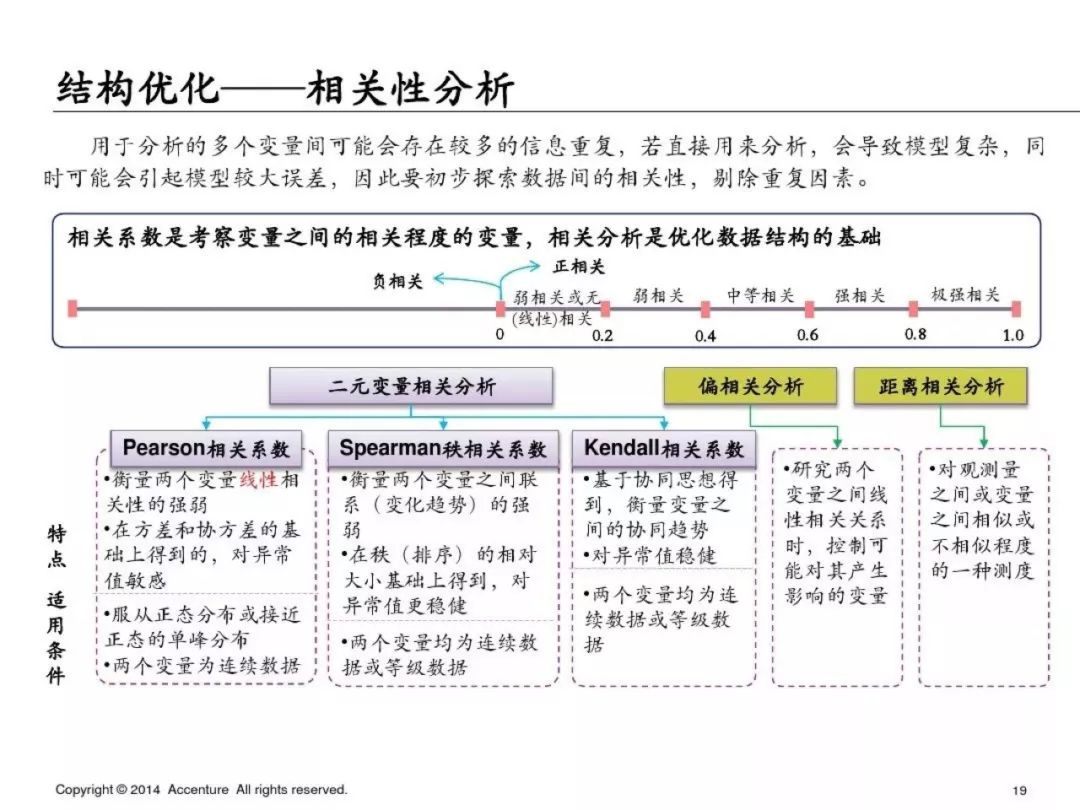

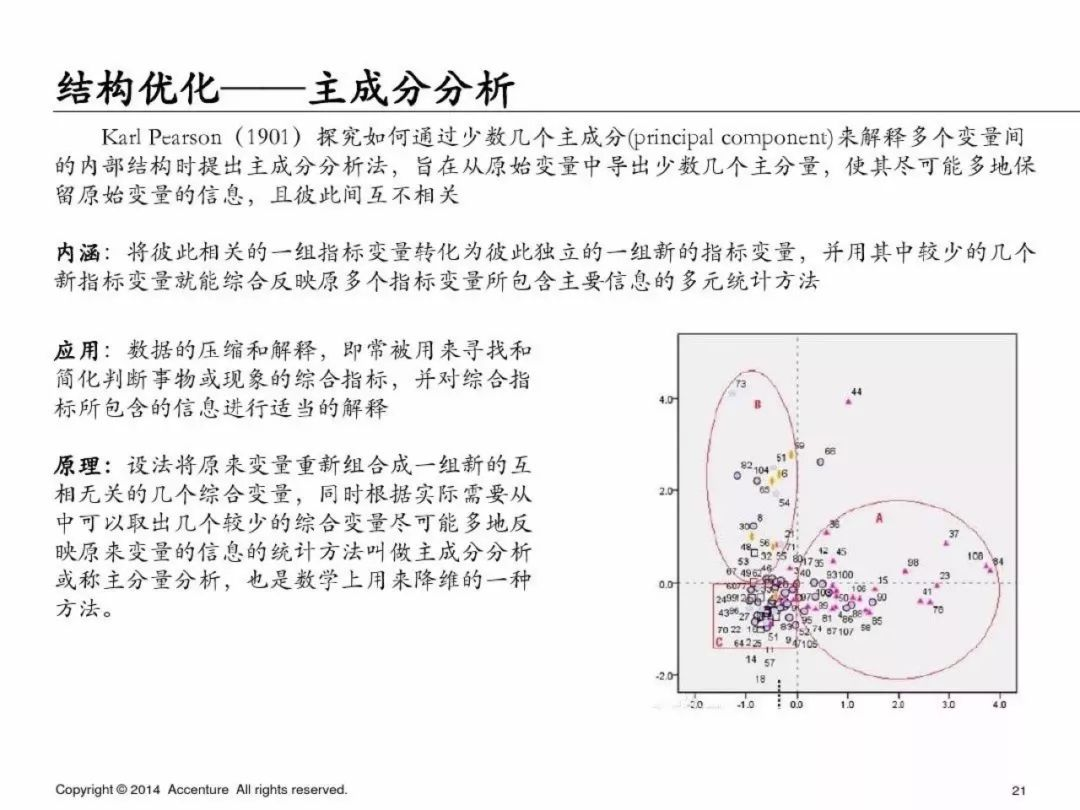
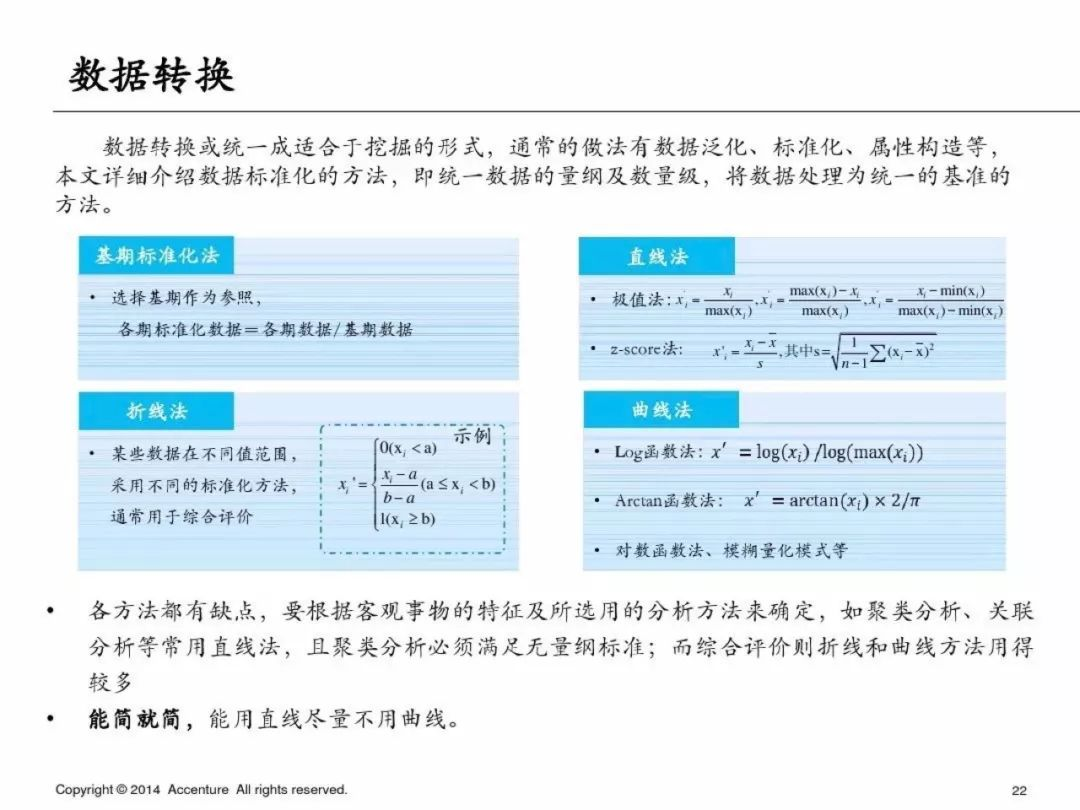
為了避免篇幅過長,第一部分就先寫到這里,下一篇繼續寫PPT中介紹的具體的分析方法和python實現方式,具體如下:
3.2 分類與回歸
3.3 聚類分析
3.4 關聯分析
3.5 時序模型
3.6 結構優化
4 數據分析支撐工具
**作者Info:**
> 【作者】:A字頭
> 【原創公眾號】:數據札記倌(Data_Groom)
> 【簡介】:這是一個堅持原創的技術公眾號,每天堅持推送各種 Python基礎/進階文章,數據分析,爬蟲實戰,機器學習算法,不定期分享各類學習資源。
> 【福利】:送你新人大禮包一份,關注公眾號,后台回復:“CSDN” 即可獲取!
