HBase簡介
HBase 是一個分布式的、面向列的開源數據庫。建立在 HDFS 之上。Hbase的名字的來源是 Hadoop database,即 Hadoop 數據庫。HBase 的計算和存儲能力取決於 Hadoop 集群。
它介於 NoSql 和 RDBMS 之間,僅能通過主鍵(row key)和主鍵的 range 來檢索數據,僅支持單行事務(可通過 Hive 支持來實現多表 join 等復雜操作)。
HBase中表的特點:
- 大:一個表可以有上十億行,上百萬列
- 面向列:面向列(族)的存儲和權限控制,列(族)獨立檢索。
- 稀疏:對於為空(null)的列,並不占用存儲空間,因此,表可以設計的非常稀疏。
HBase底層原理
系統架構

根據這幅圖,解釋下HBase中各個組件
Client
- 包含訪問hbase的接口,Client維護着一些cache來加快對hbase的訪問,比如regione的位置信息.
Zookeeper
HBase可以使用內置的Zookeeper,也可以使用外置的,在實際生產環境,為了保持統一性,一般使用外置Zookeeper。
Zookeeper在HBase中的作用:
- 保證任何時候,集群中只有一個master
- 存貯所有Region的尋址入口
- 實時監控Region Server的狀態,將Region server的上線和下線信息實時通知給Master
HMaster
- 為Region server分配region
- 負責region server的負載均衡
- 發現失效的region server並重新分配其上的region
- HDFS上的垃圾文件回收
- 處理schema更新請求
HRegion Server
- HRegion server維護HMaster分配給它的region,處理對這些region的IO請求
- HRegion server負責切分在運行過程中變得過大的region
從圖中可以看到,Client訪問HBase上數據的過程並不需要HMaster參與(尋址訪問Zookeeper和HRegion server,數據讀寫訪問HRegione server)
HMaster僅僅維護者table和HRegion的元數據信息,負載很低。
HBase的表數據模型
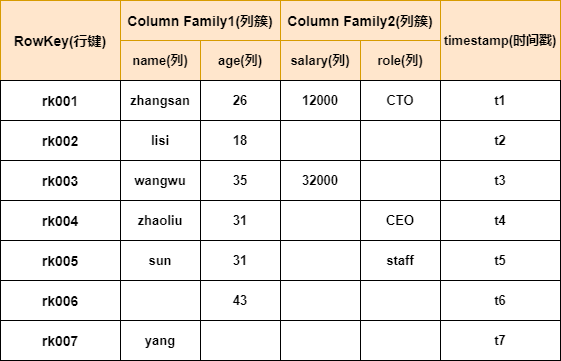
行鍵 Row Key
與nosql數據庫一樣,row key是用來檢索記錄的主鍵。訪問hbase table中的行,只有三種方式:
- 通過單個row key訪問
- 通過row key的range
- 全表掃描
Row Key 行鍵可以是任意字符串(最大長度是 64KB,實際應用中長度一般為 10-100bytes),在hbase內部,row key保存為字節數組。
Hbase會對表中的數據按照rowkey排序(字典順序)
存儲時,數據按照Row key的字典序(byte order)排序存儲。設計key時,要充分排序存儲這個特性,將經常一起讀取的行存儲放到一起。(位置相關性)。
注意:
字典序對int排序的結果是
1,10,100,11,12,13,14,15,16,17,18,19,2,20,21 ... 。要保持整形的自然序,行鍵必須用0作左填充。
行的一次讀寫是原子操作 (不論一次讀寫多少列)。這個設計決策能夠使用戶很容易的理解程序在對同一個行進行並發更新操作時的行為。
列族 Column Family
HBase表中的每個列,都歸屬與某個列族。列族是表的schema的一部分(而列不是),必須在使用表之前定義。
列名都以列族作為前綴。例如 courses:history , courses:math 都屬於 courses 這個列族。
訪問控制、磁盤和內存的使用統計都是在列族層面進行的。
列族越多,在取一行數據時所要參與IO、搜尋的文件就越多,所以,如果沒有必要,不要設置太多的列族。
列 Column
列族下面的具體列,屬於某一個ColumnFamily,類似於在mysql當中創建的具體的列。
時間戳 Timestamp
HBase中通過row和columns確定的為一個存貯單元稱為cell。每個 cell都保存着同一份數據的多個版本。版本通過時間戳來索引。時間戳的類型是 64位整型。時間戳可以由hbase(在數據寫入時自動 )賦值,此時時間戳是精確到毫秒的當前系統時間。時間戳也可以由客戶顯式賦值。如果應用程序要避免數據版本沖突,就必須自己生成具有唯一性的時間戳。每個 cell中,不同版本的數據按照時間倒序排序,即最新的數據排在最前面。
為了避免數據存在過多版本造成的的管理 (包括存貯和索引)負擔,hbase提供了兩種數據版本回收方式:
- 保存數據的最后n個版本
- 保存最近一段時間內的版本(設置數據的生命周期TTL)。
用戶可以針對每個列族進行設置。
單元 Cell
由{row key, column( =<family> + <label>), version} 唯一確定的單元。
cell中的數據是沒有類型的,全部是字節碼形式存貯。
版本號 VersionNum
數據的版本號,每條數據可以有多個版本號,默認值為系統時間戳,類型為Long。
物理存儲
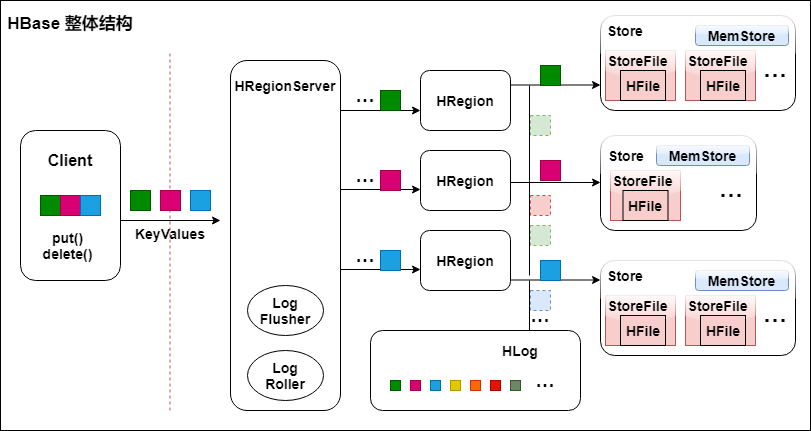
1. 整體結構
-
Table 中的所有行都按照 Row Key 的字典序排列。
-
Table 在行的方向上分割為多個 HRegion。
-
HRegion按大小分割的(默認10G),每個表一開始只有一 個HRegion,隨着數據不斷插入表,HRegion不斷增大,當增大到一個閥值的時候,HRegion就會等分會兩個新的HRegion。當Table 中的行不斷增多,就會有越來越多的 HRegion。
-
HRegion 是 HBase 中分布式存儲和負載均衡的最小單元。最小單元就表示不同的 HRegion 可以分布在不同的 HRegion Server 上。但一個 HRegion 是不會拆分到多個 Server 上的。
-
HRegion 雖然是負載均衡的最小單元,但並不是物理存儲的最小單元。
事實上,HRegion 由一個或者多個 Store 組成,每個 Store 保存一個 Column Family。
每個 Strore 又由一個 MemStore 和0至多個 StoreFile 組成。如上圖。
2. StoreFile 和 HFile 結構
StoreFile以HFile格式保存在HDFS上。
HFile的格式為:
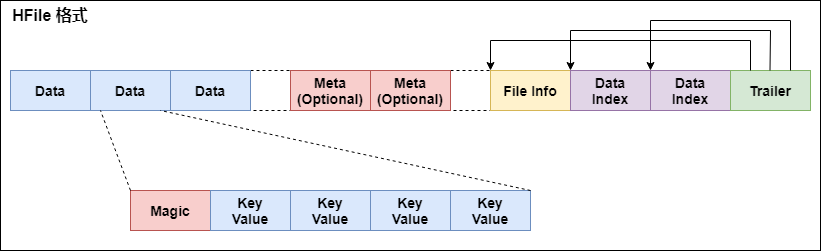
首先HFile文件是不定長的,長度固定的只有其中的兩塊:Trailer和FileInfo。正如圖中所示的,Trailer中有指針指向其他數 據塊的起始點。
File Info中記錄了文件的一些Meta信息,例如:AVG_KEY_LEN, AVG_VALUE_LEN, LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY等。
Data Index和Meta Index塊記錄了每個Data塊和Meta塊的起始點。
Data Block是HBase I/O的基本單元,為了提高效率,HRegionServer中有基於LRU的Block Cache機制。每個Data塊的大小可以在創建一個Table的時候通過參數指定,大號的Block有利於順序Scan,小號Block利於隨機查詢。 每個Data塊除了開頭的Magic以外就是一個個KeyValue對拼接而成, Magic內容就是一些隨機數字,目的是防止數據損壞。
HFile里面的每個KeyValue對就是一個簡單的byte數組。但是這個byte數組里面包含了很多項,並且有固定的結構。我們來看看里面的具體結構:

開始是兩個固定長度的數值,分別表示Key的長度和Value的長度。緊接着是Key,開始是固定長度的數值,表示RowKey的長度,緊接着是 RowKey,然后是固定長度的數值,表示Family的長度,然后是Family,接着是Qualifier,然后是兩個固定長度的數值,表示Time Stamp和Key Type(Put/Delete)。Value部分沒有這么復雜的結構,就是純粹的二進制數據了。
HFile分為六個部分:
-
Data Block 段–保存表中的數據,這部分可以被壓縮.
-
Meta Block 段 (可選的)–保存用戶自定義的kv對,可以被壓縮。
-
File Info 段–Hfile的元信息,不被壓縮,用戶也可以在這一部分添加自己的元信息。
-
Data Block Index 段–Data Block的索引。每條索引的key是被索引的block的第一條記錄的key。
-
Meta Block Index段 (可選的)–Meta Block的索引。
-
Trailer–這一段是定長的。保存了每一段的偏移量,讀取一個HFile時,會首先讀取Trailer,Trailer保存了每個段的起始位置(段的Magic Number用來做安全check),然后,DataBlock Index會被讀取到內存中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從內存中找到key所在的block,通過一次磁盤io將整個 block讀取到內存中,再找到需要的key。DataBlock Index采用LRU機制淘汰。
HFile的Data Block,Meta Block通常采用壓縮方式存儲,壓縮之后可以大大減少網絡IO和磁盤IO,隨之而來的開銷當然是需要花費cpu進行壓縮和解壓縮。
目前HFile的壓縮支持兩種方式:Gzip,Lzo。
3. Memstore與StoreFile
一個 HRegion 由多個 Store 組成,每個 Store 包含一個列族的所有數據
Store 包括位於內存的 Memstore 和位於硬盤的 StoreFile。
寫操作先寫入 Memstore,當 Memstore 中的數據量達到某個閾值,HRegionServer 啟動 FlashCache 進程寫入 StoreFile,每次寫入形成單獨一個 StoreFile
當 StoreFile 大小超過一定閾值后,會把當前的 HRegion 分割成兩個,並由 HMaster 分配給相應的 HRegion 服務器,實現負載均衡
客戶端檢索數據時,先在memstore找,找不到再找storefile。
4. HLog(WAL log)
WAL 意為Write ahead log,類似 mysql 中的 binlog,用來 做災難恢復時用,Hlog記錄數據的所有變更,一旦數據修改,就可以從log中進行恢復。
每個Region Server維護一個Hlog,而不是每個Region一個。這樣不同region(來自不同table)的日志會混在一起,這樣做的目的是不斷追加單個文件相對於同時寫多個文件而言,可以減少磁盤尋址次數,因此可以提高對table的寫性能。帶來的麻煩是,如果一台region server下線,為了恢復其上的region,需要將region server上的log進行拆分,然后分發到其它region server上進行恢復。
HLog文件就是一個普通的Hadoop Sequence File:
- HLog Sequence File 的Key是HLogKey對象,HLogKey中記錄了寫入數據的歸屬信息,除了table和region名字外,同時還包括 sequence number和timestamp,timestamp是”寫入時間”,sequence number的起始值為0,或者是最近一次存入文件系統中sequence number。
- HLog Sequece File的Value是HBase的KeyValue對象,即對應HFile中的KeyValue,可參見上文描述。
讀寫過程
1. 讀請求過程:
HRegionServer保存着meta表以及表數據,要訪問表數據,首先Client先去訪問zookeeper,從zookeeper里面獲取meta表所在的位置信息,即找到這個meta表在哪個HRegionServer上保存着。
接着Client通過剛才獲取到的HRegionServer的IP來訪問Meta表所在的HRegionServer,從而讀取到Meta,進而獲取到Meta表中存放的元數據。
Client通過元數據中存儲的信息,訪問對應的HRegionServer,然后掃描所在HRegionServer的Memstore和Storefile來查詢數據。
最后HRegionServer把查詢到的數據響應給Client。
查看meta表信息
hbase(main):011:0> scan 'hbase:meta'
2. 寫請求過程:
Client也是先訪問zookeeper,找到Meta表,並獲取Meta表元數據。
確定當前將要寫入的數據所對應的HRegion和HRegionServer服務器。
Client向該HRegionServer服務器發起寫入數據請求,然后HRegionServer收到請求並響應。
Client先把數據寫入到HLog,以防止數據丟失。
然后將數據寫入到Memstore。
如果HLog和Memstore均寫入成功,則這條數據寫入成功
如果Memstore達到閾值,會把Memstore中的數據flush到Storefile中。
當Storefile越來越多,會觸發Compact合並操作,把過多的Storefile合並成一個大的Storefile。
當Storefile越來越大,Region也會越來越大,達到閾值后,會觸發Split操作,將Region一分為二。
細節描述:
HBase使用MemStore和StoreFile存儲對表的更新。
數據在更新時首先寫入Log(WAL log)和內存(MemStore)中,MemStore中的數據是排序的,當MemStore累計到一定閾值時,就會創建一個新的MemStore,並且將老的MemStore添加到flush隊列,由單獨的線程flush到磁盤上,成為一個StoreFile。於此同時,系統會在zookeeper中記錄一個redo point,表示這個時刻之前的變更已經持久化了。
當系統出現意外時,可能導致內存(MemStore)中的數據丟失,此時使用Log(WAL log)來恢復checkpoint之后的數據。
StoreFile是只讀的,一旦創建后就不可以再修改。因此HBase的更新其實是不斷追加的操作。當一個Store中的StoreFile達到一定的閾值后,就會進行一次合並(minor_compact, major_compact),將對同一個key的修改合並到一起,形成一個大的StoreFile,當StoreFile的大小達到一定閾值后,又會對 StoreFile進行split,等分為兩個StoreFile。
由於對表的更新是不斷追加的,compact時,需要訪問Store中全部的 StoreFile和MemStore,將他們按row key進行合並,由於StoreFile和MemStore都是經過排序的,並且StoreFile帶有內存中索引,合並的過程還是比較快。
HRegion管理
HRegion分配
任何時刻,一個HRegion只能分配給一個HRegion Server。HMaster記錄了當前有哪些可用的HRegion Server。以及當前哪些HRegion分配給了哪些HRegion Server,哪些HRegion還沒有分配。當需要分配的新的HRegion,並且有一個HRegion Server上有可用空間時,HMaster就給這個HRegion Server發送一個裝載請求,把HRegion分配給這個HRegion Server。HRegion Server得到請求后,就開始對此HRegion提供服務。
HRegion Server上線
HMaster使用zookeeper來跟蹤HRegion Server狀態。當某個HRegion Server啟動時,會首先在zookeeper上的server目錄下建立代表自己的znode。由於HMaster訂閱了server目錄上的變更消息,當server目錄下的文件出現新增或刪除操作時,HMaster可以得到來自zookeeper的實時通知。因此一旦HRegion Server上線,HMaster能馬上得到消息。
HRegion Server下線
當HRegion Server下線時,它和zookeeper的會話斷開,zookeeper而自動釋放代表這台server的文件上的獨占鎖。HMaster就可以確定:
- HRegion Server和zookeeper之間的網絡斷開了。
- HRegion Server掛了。
無論哪種情況,HRegion Server都無法繼續為它的HRegion提供服務了,此時HMaster會刪除server目錄下代表這台HRegion Server的znode數據,並將這台HRegion Server的HRegion分配給其它還活着的節點。
HMaster工作機制
master上線
master啟動進行以下步驟:
- 從zookeeper上獲取唯一一個代表active master的鎖,用來阻止其它HMaster成為master。
- 掃描zookeeper上的server父節點,獲得當前可用的HRegion Server列表。
- 和每個HRegion Server通信,獲得當前已分配的HRegion和HRegion Server的對應關系。
- 掃描.META.region的集合,計算得到當前還未分配的HRegion,將他們放入待分配HRegion列表。
master下線
由於HMaster只維護表和region的元數據,而不參與表數據IO的過程,HMaster下線僅導致所有元數據的修改被凍結(無法創建刪除表,無法修改表的schema,無法進行HRegion的負載均衡,無法處理HRegion 上下線,無法進行HRegion的合並,唯一例外的是HRegion的split可以正常進行,因為只有HRegion Server參與),表的數據讀寫還可以正常進行。因此HMaster下線短時間內對整個HBase集群沒有影響。
從上線過程可以看到,HMaster保存的信息全是可以冗余信息(都可以從系統其它地方收集到或者計算出來)
因此,一般HBase集群中總是有一個HMaster在提供服務,還有一個以上的‘HMaster’在等待時機搶占它的位置。
HBase三個重要機制
1. flush機制
1.(hbase.regionserver.global.memstore.size)默認;堆大小的40%
regionServer的全局memstore的大小,超過該大小會觸發flush到磁盤的操作,默認是堆大小的40%,而且regionserver級別的flush會阻塞客戶端讀寫
2.(hbase.hregion.memstore.flush.size)默認:128M
單個region里memstore的緩存大小,超過那么整個HRegion就會flush,
3.(hbase.regionserver.optionalcacheflushinterval)默認:1h
內存中的文件在自動刷新之前能夠存活的最長時間
4.(hbase.regionserver.global.memstore.size.lower.limit)默認:堆大小 * 0.4 * 0.95
有時候集群的“寫負載”非常高,寫入量一直超過flush的量,這時,我們就希望memstore不要超過一定的安全設置。在這種情況下,寫操作就要被阻塞一直到memstore恢復到一個“可管理”的大小, 這個大小就是默認值是堆大小 * 0.4 * 0.95,也就是當regionserver級別的flush操作發送后,會阻塞客戶端寫,一直阻塞到整個regionserver級別的memstore的大小為 堆大小 * 0.4 *0.95為止
5.(hbase.hregion.preclose.flush.size)默認為:5M
當一個 region 中的 memstore 的大小大於這個值的時候,我們又觸發了region的 close時,會先運行“pre-flush”操作,清理這個需要關閉的memstore,然后 將這個 region 下線。當一個 region 下線了,我們無法再進行任何寫操作。 如果一個 memstore 很大的時候,flush 操作會消耗很多時間。"pre-flush" 操作意味着在 region 下線之前,會先把 memstore 清空。這樣在最終執行 close 操作的時候,flush 操作會很快。
6.(hbase.hstore.compactionThreshold)默認:超過3個
一個store里面允許存的hfile的個數,超過這個個數會被寫到新的一個hfile里面 也即是每個region的每個列族對應的memstore在flush為hfile的時候,默認情況下當超過3個hfile的時候就會對這些文件進行合並重寫為一個新文件,設置個數越大可以減少觸發合並的時間,但是每次合並的時間就會越長
2. compact機制
把小的storeFile文件合並成大的HFile文件。
清理過期的數據,包括刪除的數據
將數據的版本號保存為1個。
split機制
當HRegion達到閾值,會把過大的HRegion一分為二。
默認一個HFile達到10Gb的時候就會進行切分。