還記得之前介紹過的命名實體識別系列文章嗎,可以從句子中提取出人名、地址、公司等實體字段,當時只是簡單提到了BERT+CRF模型,BERT已經在上一篇文章中介紹過了,本文將對CRF做一個基本的介紹。本文盡可能不涉及復雜晦澀的數學公式,目的只是快速了解CRF的基本概念以及其在命名實體識別等自然語言處理領域的作用。
什么是CRF?
CRF,全稱 Conditional Random Fields,中文名:條件隨機場。是給定一組輸入序列的條件下,另一組輸出序列的條件概率分布模型。
什么時候可以用CRF?
當輸出序列的每一個位置的狀態,需要考慮到相鄰位置的狀態的時候。舉兩個例子:
1、假設有一堆小明日常生活的照片,可能的狀態有吃飯、洗澡、刷牙等,大部分情況,我們是能夠識別出小明的狀態的,但是如果你看到一張小明露出牙齒的照片,在沒有相鄰的小明的狀態為條件的情況下,是很難判斷他是在吃飯還是刷牙的。這時,就可以用crf。
2、假設有一句話,這里假設是英文,我們要判斷每個詞的詞性,那么對於一些詞來說,如果不知道相鄰詞的詞性的情況下,是很難准確判斷每個詞的詞性的。這時,也可以用crf。
什么是隨機場?
我們先來說什么是隨機場。
The collection of random variables is called a stochastic process.A stochastic process that is indexed by a spatial variable is called a random field.
隨機變量的集合稱為隨機過程。由一個空間變量索引的隨機過程,稱為隨機場。
也就是說,一組隨機變量按照某種概率分布隨機賦值到某個空間的一組位置上時,這些賦予了隨機變量的位置就是一個隨機場。比如上面的例子中,小明的一系列照片分別是什么狀態組成了一組位置,我們從一組隨機變量{吃飯、洗澡、刷牙}中取值,隨機變量遵循某種概率分布,隨機賦給一組照片的某一張的輸出位置,並完成這組照片的所有輸出位置的狀態賦值后,這些狀態和所在的位置全體稱為隨機場。
為什么叫條件隨機場?
回答這個問題需要先來看看什么是馬爾可夫隨機場(也叫馬爾可夫網絡),如果一個位置的賦值只和與它相鄰的位置的值有關,與和它不相鄰的位置的值無關,那么這個隨機場就是一個馬爾可夫隨機場。這個假設用在小明和詞性標注的例子中的話就是我們是通過前一張照片或者后一張照片的狀態來判斷當前照片的狀態是刷牙還是吃飯,我們是根據前一個詞的詞性或者后一個詞的詞性來判斷當前詞的詞性是什么。
然而,無論是照片還是詞性的判斷,如果僅僅通過相鄰的照片或詞性來判斷當前照片或詞的狀態還是過於草率了,如果還能加入對照片中的內容或詞的含義的參考,最后的判斷當然會更准確啦。
而條件隨機場(CRF),就是給定了一組觀測狀態(照片可能的狀態/可能出現的詞)下的馬爾可夫隨機場。也就是說CRF考慮到了觀測狀態這個先驗條件,這也是條件隨機場中的條件一詞的含義。
CRF的數學描述
設X與Y是隨機變量,P(Y|X)是給定X時Y的條件概率分布,若隨機變量Y構成的是一個馬爾科夫隨機場,則稱條件概率分布P(Y|X)是條件隨機場。在實際的應用中,比如上面的兩個例子,我們一般都要求X和Y有相同的結構,如下:
X=(X1,X2,...Xn),Y=(Y1,Y2,...Yn)
比如詞性標注,我們要求輸出的詞性序列和輸入的句子中的每個詞是一一對應的。
X和Y有相同的結構的CRF就構成了線性鏈條件隨機場(Linear chain Conditional Random Fields,簡稱 linear-CRF)。
上面的例子中沒有提到命名實體識別,但其實命名實體識別的原理和上面的例子是一樣的,也是用到了linear-CRF,后面會提到。
CRF如何提取特征?
CRF中有兩類特征函數,分別是狀態特征和轉移特征,狀態特征用當前節點(某個輸出位置可能的狀態中的某個狀態稱為一個節點)的狀態分數表示,轉移特征用上一個節點到當前節點的轉移分數表示。其損失函數定義如下:

CRF損失函數的計算,需要用到真實路徑分數(包括狀態分數和轉移分數),其他所有可能的路徑的分數(包括狀態分數和轉移分數)。這里的路徑用詞性來舉例就是一句話對應的詞性序列,真實路徑表示真實的詞性序列,其他可能的路徑表示其他的詞性序列。
這里的分數就是指softmax之前的概率,或稱為未規范化的概率。softmax的作用就是將一組數值轉換成一組0-1之間的數值,這些數值的和為1,這樣就可以表示概率了。
對於詞性標注來說,給定一句話和其對應的詞性序列,那么其似然性的計算公式(CRF的參數化公式)如下,圖片出自條件隨機場CRF:
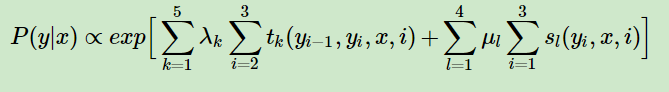
- l表示某個詞上定義的狀態特征的個數,k表示轉移特征的個數,i表示詞在句子中的位置。
- tk和sl分別是轉移特征函數和狀態特征函數。
- λk和μl分別是轉移特征函數和狀態特征函數的權重系數,通過最大似然估計可以得到。
- 上面提到的狀態分數和轉移分數都是非規范化的對數概率,所以概率計算都是加法,這里加上一個exp是為了將對數概率轉為正常概率。實際計算時還會除以一個規范化因子Z(x),其實就是一個softmax過程。
在只有CRF的情況下,上面說的2類特征函數都是人工設定好的。通俗的說就是人工設定了觀測序列的特征。
人為設定狀態特征模板,比如設定“某個詞是名詞”等。
人為設定轉移特征模板,比如設定“某個詞是名詞時,上一個詞是形容詞”等。
給定一句話的時候,就根據上面設定的特征模板來計算這句話的特征分數,計算的時候,如果這句話符合特征模板中的特征規則,則那個特征規則的值就為1,否則就為0。
實體識別的表現取決於2種特征模板設定的好壞。
所以如果我們能使用深度神經網絡的方式,特征就可以由模型自己學習得到,這就是使用BERT+CRF的原因。
命名實體識別中的BERT和CRF是怎么配合的?
由BERT學習序列的狀態特征,從而得到一個狀態分數,該分數直接輸入到CRF層,省去了人工設置狀態特征模板。
這里的狀態特征是說序列某個位置可能對應的狀態(命名實體識別中是指實體標注),
狀態分數是每個可能的狀態的softmax前的概率(又稱非規范化概率,或者直接稱作分數),
實體標注通常用BIO標注,B表示詞的開始,I表示詞的延續,O表示非實體詞,比如下面的句子和其對應的實體標注(假設我們要識別的是人名和地點):
小 明 愛 北 京 的 天 安 門 。
B-Person I-Person O B-Location I-Location O B-Location I-Location I-Location O
也就是說BERT層學到了句子中每個字符最可能對應的實體標注是什么,這個過程是考慮到了每個字符左邊和右邊的上下文信息的,但是輸出的最大分數對應的實體標注依然可能有誤,不會100%正確的,出現B后面直接跟着B,后者標注以I開頭了,都是有可能的,而降低這些明顯不符規則的問題的情況的發生概率,就可以進一步提高BERT模型預測的准確性。此時就有人想到用CRF來解決這個問題。
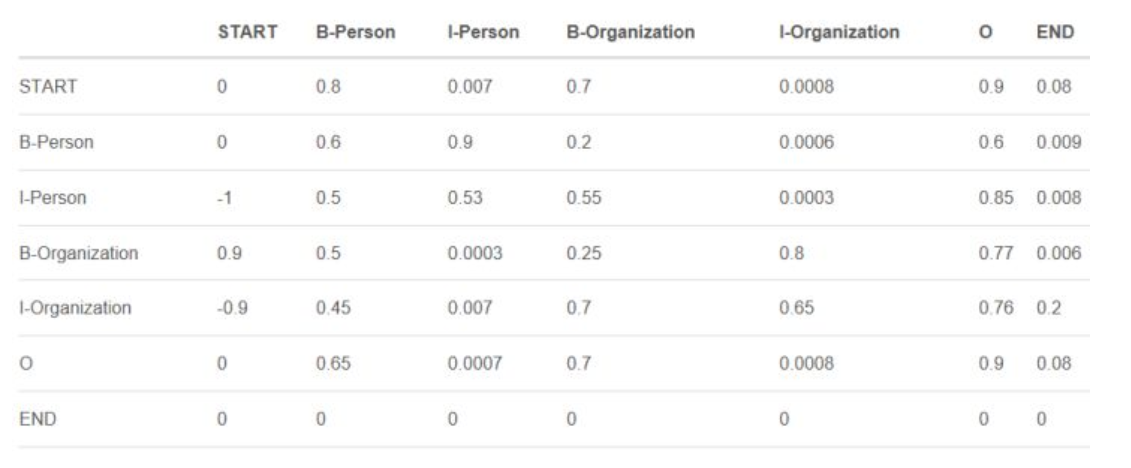
CRF算法中涉及到2種特征函數,一個是狀態特征函數,計算狀態分數,一個是轉移特征函數,計算轉移分數。前者只針對當前位置的字符可以被轉換成哪些實體標注,后者關注的是當前位置和其相鄰位置的字符可以有哪些實體標注的組合。BERT層已經將狀態分數輸出到CRF層了,所以CRF層還需要學習一個轉移分數矩陣,該矩陣表示了所有標注狀態之間的組合,比如我們這里有B-Person I-Person B-Location I-Location O 共5種狀態,有時候還會在句子的開始和結束各加一個START 和 END標注,表示一個句子的開始和結束,那么此時就是7種狀態了,那么2個狀態(包括自己和自己)之間的組合就有7*7=49種,上面說的轉移分數矩陣中的元素就是這49種組合的分數(或稱作非規范化概率),表示了各個組合的可能性。這個矩陣一開始是隨機初始化的,通過訓練后慢慢會知道哪些組合更符合規則,哪些更不符合規則。從而為模型的預測帶來類似如下的約束:
- 句子的開頭應該是“B-”或“O”,而不是“I-”。
- “B-label1 I-label2 I-label3…”,在該模式中,類別1,2,3應該是同一種實體類別。比如,“B-Person I-Person” 是正確的,而“B-Person I-Organization”則是錯誤的。
- “O I-label”是錯誤的,命名實體的開頭應該是“B-”而不是“I-”。
矩陣示意如下:
為什么不能通過人工來判斷標注規則並編寫好修正邏輯呢?
因為人工雖然能判斷出預測的標注前后關系是否符合規則,但是無法知道如何對不符合規則的預測進行調整,比如我們知道句子的開頭應該是“B-”或“O”,而不是“I-”,但是究竟是B-還是O呢?而且對於標注狀態非常多的場景下,人工編寫的工作量和邏輯是非常大且復雜的。
CRF損失函數的計算,需要用到真實路徑分數(包括狀態分數和轉移分數),其他所有可能的路徑的分數(包括狀態分數和轉移分數)。其中真實路徑的狀態分數是根據訓練得到的BERT模型的輸出計算出來的,轉移分數是從CRF層提供的轉移分數矩陣得到的。其他路徑的狀態分數和轉移分數其實也是這樣計算的。
其中真實路徑的計算原理,其實是使用了維特比算法,關於維特比算法,這篇維特比算法在CRF(條件隨機場)中是如何起作用的?中有具體介紹。
總結
命名實體識別中,BERT負責學習輸入句子中每個字和符號到對應的實體標簽的規律,而CRF負責學習相鄰實體標簽之間的轉移規則。
ok,本篇就這么多內容啦~,感謝閱讀O(∩_∩)O。