深度學習-語義分割總結
翻譯自qure.ai
-
什么是語義分割
對圖片的每個像素都做分類。
-
有哪幾種方法
傳統機器學習方法:如像素級的決策樹分類,參考TextonForest 以及 Random Forest based classifiers 。再有就是深度學習方法。更確切地說,是卷積神經網絡。
深度學習最初流行的分割方法是,打補丁式的分類方法 ( patch classification ) 。逐像素地抽取周圍像素對中心像素進行分類。由於當時的卷積網絡末端都使用全連接層 ( full connected layers ) ,所以只能使用這種逐像素的分割方法。
2014年,來自伯克利的 Fully Convolutional Networks(FCN) 卷積網絡,去掉了末端的全連接層。隨后的語義分割模型基本上都采用了這種結構。除了全連接層,語義分割另一個重要的問題是池化層。池化層能進一步提取抽象特征增加感受域,但是丟棄了像素的位置信息。但是語義分割需要類別標簽和原圖像對齊,因此需要從新引入像素的位置信息。有兩種不同的架構可以解決此像素定位問題。
第一種是編碼-譯碼架構。編碼過程通過池化層逐漸減少位置信息、抽取抽象特征;譯碼過程逐漸恢復位置信息。一般譯碼與編碼間有直接的連接。該類架構中U-net 是最流行的。
第二種架構是膨脹卷積 ( dilated convolutions ) ,拋棄了池化層。使用的卷積核如下圖。

條件隨機場的后處理 經常用來提高分割的精確度。后處理利用圖像的光感強度(可理解為亮度),將周圍強度相近的像素分為同一類。能提高 1-2 個百分點。
-
文章匯總
按時間順序總結八篇paper,看語義分割的結構是如何演變的。分別有FCN 、SegNet 、Dilated Convolutions 、DeepLab (v1 & v2) 、RefineNet 、PSPNet 、Large Kernel Matters 、DeepLab v3 。
FCN 2014年
主要的貢獻:
說明:
比較重要的發現是,分類網絡中的全連接層可以看作對輸入的全域卷積操作,這種轉換能使計算更為高效,並且能重新利用 ImageNet 的預訓練網絡。經過多層卷積及池化操作后,需要進行上采樣,FCN 使用反卷積(可學習)取代簡單的線性插值算法進行上采樣。

SegNet 2015年
編碼-譯碼架構
主要貢獻:
- 將池化層結果應用到譯碼過程。引入了更多的編碼信息。使用的是pooling indices而不是直接復制特征,只是將編碼過程中 pool 的位置記下來,在 uppooling 是使用該信息進行 pooling 。


U-Net 2015
U-Net 有更規整的網絡結構,通過將編碼器的每層結果拼接到譯碼器中得到更好的結果。

Dilated Convolutions 2015年
通過膨脹卷積操作聚合多尺度的信息
主要貢獻:
- 使用膨脹卷積
-
提出 ’context module‘ ,用來聚合多尺度的信息
說明:
池化在分類網絡中能夠擴大感知域,同樣降低了分辨率。所以作者提出了膨脹卷積層。
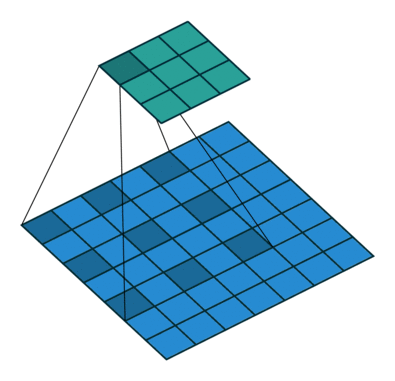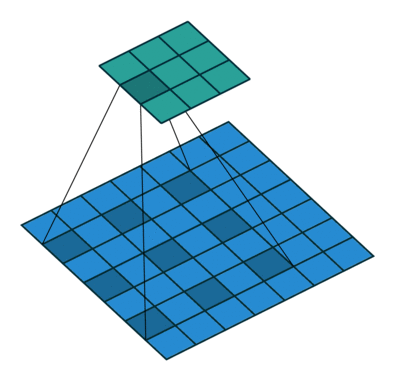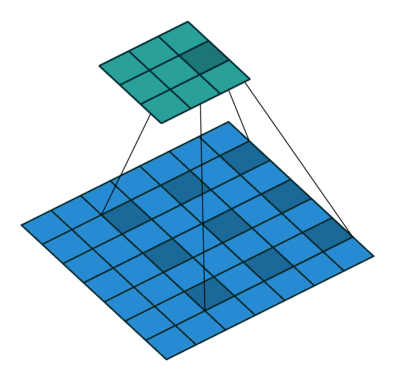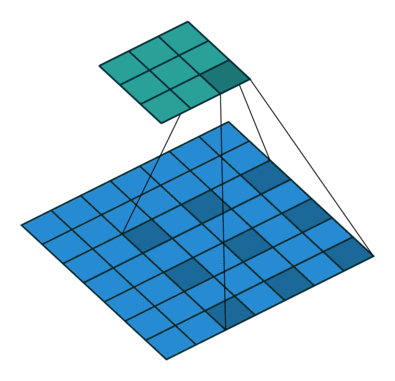

(a) 原始的 3×33×3卷積,1-dilated,感受野為 3×33×3;
(b) 在(a)的基礎上進行 3×33×3卷積,2-dilated,感受野為 7×77×7;
(c) 在(b)的基礎上進行 3×33×3卷積,4-dilated,感受野為 15×1515×15;
由於padding和卷積的stride=1,卷積前后feature map大小可以保持不變,但每個元素的感受野指數增大。Link
膨脹卷積在 DeepLab 中也被稱為暗黑卷積 (atrous convolution) 。此卷積能夠極大的擴大感知域同時不減小空間維度。本模型移去了VGG網的最后兩層池化層,並且其后續的卷積層都采用膨脹卷積。
作者還訓練了一個模塊,輸入卷積結果,級聯了不同膨脹系數的膨脹卷積層的,輸出和輸入有一樣的尺寸,因此此模塊能夠提取不同規模特征中的信息,得到更精確的分割結果。
最后預測結果圖是原圖的八分之一大小,文章使用插值得到最后的分割結果。
DeepLab (v1 & v2) 2014 & 2016
主要貢獻:
- 使用膨脹卷積
- 提出了暗黑空間金字塔池化 (ASPP),融合了不同尺度的信息。
-
使用全連接的條件隨機場
說明:
基本網絡和 dilated convolutions 一致。最后的結構化預測 (精細分割) 采用全連接的 CDF。提出了ASPP,但結果不如 FC-CDF 。


RefineNet 2016年
主要貢獻:
- 精心設計的譯碼模塊
-
所有模塊遵循殘余連接設計
說明:
膨脹卷積有幾個缺點,如計算量大、需要大量內存。這篇文章采用編碼-譯碼架構。編碼部分是 ResNet-101 模塊。譯碼采用 RefineNet 模塊,該模塊融合了編碼模塊的高分辨率特征和前一個 RefineNet 模塊的抽象特征。
每個 RefineNet 模塊接收多個不同分辨率特征,並融合。看圖。


PSPNet 2016年
Pyramid Scene Parsing Network 金字塔場景解析網絡
主要貢獻:
-
提出了金字塔池化模塊來聚合圖片信息
-
使用附加的損失函數
說明:
金字塔池化模塊通過應用大核心池化層來提高感知域。使用膨脹卷積來修改 ResNet 網,並增加了金字塔池化模塊。金字塔池化模塊對 ResNet 輸出的特征進行不同規模的池化操作,並作上采樣后,拼接起來,最后得到結果。
本文提出的網絡結構簡單來說就是將DeepLab(不完全一樣)aspp之前的feature map pooling了四種尺度之后 將5種feature map concat到一起經過卷積最后進行prediction的過程。
附加的損失函數:看不懂

Large Kernel Matters 2017
主要貢獻:
-
提出了使用大卷積核的編碼-譯碼架構
說明:
理論上更深的 ResNet 能有很大的感知域,但研究表明實際上提取的信息來自很小的范圍,因此使用大核來擴大感知域。但是核越大,計算量越大,因此將 k x k 的卷積近似轉換為 1 x k + k x 1 和 k x 1 + 1 x k 卷積的和。本文稱為 GCN。
本文的架構是:使用 ResNet 作為編譯器,而 GCN 和反卷積作為譯碼器。還使用了名為 Boundary Refinement 的殘余模塊。

DeepLab v3 2017
主要貢獻:
-
改進 ASPP
-
串行部署 ASPP 的模塊
說明:
和 DeepLab v2 一樣,將膨脹卷積應用於 ResNet 中。改進的 ASPP 指的是將不同膨脹率的膨脹卷積結果拼接起來。並使用了 BN 。
於 Dilated convolutions (2015) 不一樣的是,v3 直接對中間的特征圖進行膨脹卷積,而不是在最后做。

采集多尺度信息的方法 
對比
| 模型 | 分數 (VOC2012) |
|---|---|
| FCN | 67.2 |
| SegNet | 59.9 |
| Dilated Convolutions | 75.3 |
| DeepLab (v1 & v2) | 79.7 |
| RefineNet | 84.2 |
| PSPNet | 85.4 |
| Large Kernel Matters | 83.6 |
| DeepLab v3 | 85.7 |