深度學習在圖像語義分割中的應用
本文主要分為三個部分:
- 圖像的語義分割問題是什么
- 分割方法的概述
- 對語義分割方面有代表性的論文的總結
什么是圖像的語義分割?
在計算機視覺領域,分割、檢測、識別、跟蹤這幾個問題是緊密相連的。不同於傳統的基於灰度、顏色、紋理和形狀等特征的圖像分割問題,圖像語義分割是從像素級理解圖像,需要確定圖像中每個像素的對應的目標類別。如下圖:
除了識別出摩托車和騎摩托車的人,我們還必須划定每個物體的邊界。圖像分類問題輸出幾個代表類別的值,而語義分割需要輸出每個像素對應的類別。
有哪些語義分割的方法?
在深度學習統治計算機視覺領域之前,有Texton Forests和Random Forest based classifiers等方法來進行語義分割。深度學習的方法興起以后,在圖像分類任務上取得巨大成功的卷積神經網絡同樣在圖像語義分割任務中得到了非常大的提升。最初引入深度學習的方法是patch classification方法,它使用像素周圍的區塊來進行分類,由於使用了神經網絡中使用了全連接結構,所以限制了圖像尺寸和只能使用區塊的方法。2014年出現了[Fully Convolutional Networks (FCN),FCN推廣了原有的CNN結構,在不帶有全連接層的情況下能進行密集預測。,因此FCN可以處理任意大小的圖像,並且提高了處理速度。后來的很多語義分割方法都是基於FCN的改進。
然而將卷積神經網絡應用在語義分割中也帶來了一些問題,其中一個主要的問題就是池化層( pooling layers)。池化層增加了視野,但是同時也丟失了精確的位置信息,這與語義分割需要的准確的像素位置信息相矛盾。
針對這個問題,學術界主要有兩種類型的解決方法。
一種是編碼解碼器(encoder-decoder)網絡結構,編碼器使用池化層逐漸減少空間維度,解碼器逐漸恢復目標對象的細節和空間維度。通常從編碼器到解碼器的快捷連接幫助解碼器更好地恢復對象細節,如下圖所示。U-Net是這類方法的代表。

另一種方法是取消了池化層,並使用了空洞卷積。

條件隨機場(Conditional Random Field,CRF)方法通常在后期處理中用於改進分割效果。CRF方法是一種基於底層圖像像素強度進行“平滑”分割的圖模型,在運行時會將像素強度相似的點標記為同一類別。加入條件隨機場方法可以提高1~2%的最終評分值。

接下來是對一些有代表性的論文進行梳理,包括了從FCN開始的語義分割網絡結構的演變過程。這些網絡結構都使用了VOC2012進行評測。
論文梳理
按照論文的發表順序,將會梳理一下論文:
- FCN
- SegNet
- Dilated Convolutions
- DeepLab (v1 & v2)
- RefineNet
- PSPNet
- Large Kernel Matters
- DeepLab v3
對於以上的每篇論文,下面將會分別指出主要貢獻並進行解釋,也貼出了這些結構在VOC2012數據集中的測試分值IOU。
FCN
Fully Convolutional Networks for Semantic Segmentation
Submitted on 14 Nov 2014
主要貢獻:
- 將端到端的卷積網絡推廣到語義分割中
- 將Imagenet分類任務中訓練好的網絡結構,應用與語義分割中
- 使用反卷積層進行上采樣
- 提出了跳層連接來改善上采樣的粗糙程度
詳細解釋:
FCN將傳統CNN中的全連接層轉化成一個個的卷積層。如下圖所示,在傳統的CNN結構中,前5層是卷積層,第6層和第7層分別是一個長度為4096的一維向量,第8層是長度為1000的一維向量,分別對應1000個類別的概率。FCN將這3層表示為卷積層,卷積核的大小(通道數,寬,高)分別為(4096,1,1)、(4096,1,1)、(1000,1,1)。所有的層都是卷積層,故稱為全卷積網絡。

可以發現,經過多次卷積(還有pooling)以后,得到的圖像越來越小,分辨率越來越低(粗略的圖像),那么FCN是如何得到圖像中每一個像素的類別的呢?為了從這個分辨率低的粗略圖像恢復到原圖的分辨率,FCN使用了上采樣。例如經過5次卷積(和pooling)以后,圖像的分辨率依次縮小了2,4,8,16,32倍。對於最后一層的輸出圖像,需要進行32倍的上采樣,以得到原圖一樣的大小。
這個上采樣是通過反卷積(deconvolution)和跳層連接實現的。對第5層的輸出(32倍放大)反卷積到原圖大小,得到的結果還是不夠精確,一些細節無法恢復。於是Jonathan將第4層的輸出和第3層的輸出也依次反卷積,分別需要16倍和8倍上采樣,結果就精細一些了。下圖是這個卷積和反卷積上采樣的過程:

下圖是32倍,16倍和8倍上采樣得到的結果的對比,可以看到它們得到的結果越來越精確:

與傳統用CNN進行圖像分割的方法相比,FCN有兩大明顯的優點:一是可以接受任意大小的輸入圖像,而不用要求所有的訓練圖像和測試圖像具有同樣的尺寸。二是更加高效,因為避免了由於使用像素塊而帶來的重復存儲和計算卷積的問題。
同時FCN的缺點也比較明顯:一是得到的結果還是不夠精細。進行8倍上采樣雖然比32倍的效果好了很多,但是上采樣的結果還是比較模糊和平滑,對圖像中的細節不敏感。二是對各個像素進行分類,沒有充分考慮像素與像素之間的關系,忽略了在通常的基於像素分類的分割方法中使用的空間規整(spatial regularization)步驟,缺乏空間一致性。
補充:
反池化和反卷積:

FCN在VOC2012上的得分:

SegNet
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Submitted on 2 Nov 2015
主要貢獻:
- 將最大池化指數轉移至解碼器中,改善了分割分辨率
詳細解釋:
在FCN網絡中,通過上卷積層和一些跳躍連接產生了粗糙的分割圖,為了提升效果而引入了更多的跳躍連接。
然而,FCN網絡僅僅復制了編碼器特征,而Segnet網絡復制了最大池化指數。這使得在內存使用上,SegNet比FCN更為高效。

SegNet在VOC2012上的得分:

空洞卷積
Multi-Scale Context Aggregation by Dilated Convolutions
Submitted on 23 Nov 2015
主要貢獻:
- 使用了空洞卷積,這是一種可用於密集預測的卷積層
- 提出在多尺度聚集條件下使用空洞卷積的“背景模塊”
詳細解釋:
池化操作增大了感受野,有助於實現分類網絡。但是池化操作在分割過程中也降低了分辨率。
因此,該論文所提出的空洞卷積層工作方式如下圖:
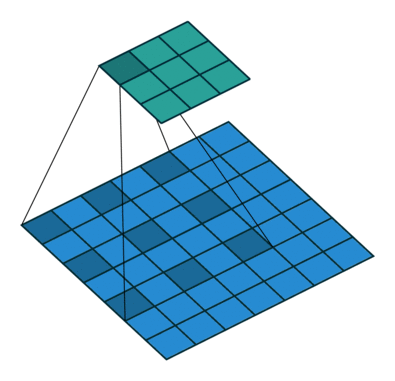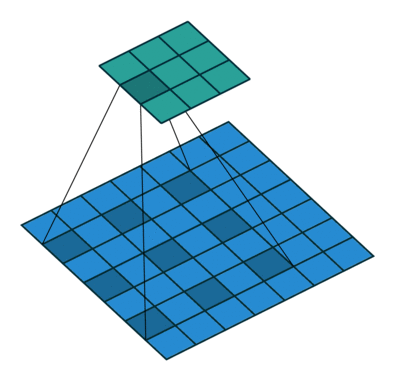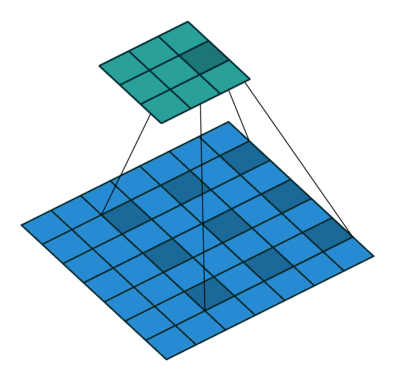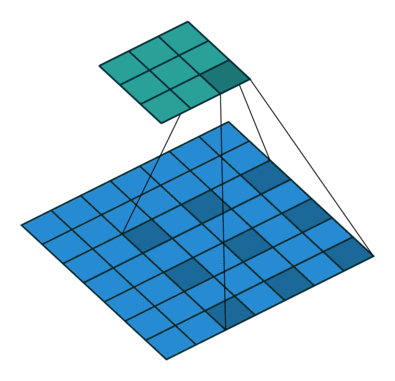
空洞卷積層在不降低空間維度的前提下增大了相應的感受野指數(注:在接下來將提到的DeepLab中,空洞卷積被稱為多孔卷積atrous convolution)。從預訓練好的分類網絡中(這里指的是VGG網絡)移除最后兩個池化層,而用空洞卷積取代了隨后的卷積層。特別的是,池化層3和池化層4之間的卷積操作為空洞卷積層2,池化層4之后的卷積操作為空洞卷積層4。這篇文章所提出的背景模型(frontend module)可在不增加參數數量的情況下獲得密集預測結果。
這篇文章所提到的背景模塊單獨訓練了前端模塊的輸出,作為該模型的輸入。該模塊是由不同擴張程度的空洞卷積層級聯而得到的,從而聚集多尺度背景模塊並改善前端預測效果。
在VOC2012上的得分:

評價:
需要注意的是,該模型預測分割圖的大小是原圖像大小的1/8。這是幾乎所有方法中都存在的問題,將通過內插方法得到最終分割圖。
DeepLab (v1 , v2)
v1 : Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Submitted on 22 Dec 2014
詳細解釋:
DeepLab是Google搞出來的一個model,在VOC上的排名要比CRF as RNN的效果好。Deeplab仍然采用了FCN來得到score map,並且也是在VGG網絡上進行fine-tuning。但是在得到score map的處理方式上,要比原FCN處理的優雅很多。
還記得FCN中是怎么得到一個更加dense的score map的嗎? 是一張500x500的輸入圖像,直接在第一個卷積層上conv1_1加了一個100的padding。最終在fc7層勉強得到一個16x16的score map。雖然處理上稍顯粗糙,但是畢竟人家是第一次將圖像分割在CNN上搞成end-to-end,並且在當時performance是state-of-the-art。
而怎樣才能保證輸出的尺寸不會太小而又不必加100 padding這樣“粗糙的”做法呢?可能有人會說減少池化層不就行了,這樣理論上是可以的,但是這樣直接就改變了原先可用的結構了,而且最重要的一點是就不能用以前的結構參數進行fine-tune了。
所以,Deeplab這里使用了一個非常優雅的做法:將VGG網絡的pool4和pool5層的stride由原來的2改為了1,再加上 1 padding。就是這樣一個改動,使得vgg網絡總的stride由原來的32變成8,進而使得在輸入圖像為514x514時,fc7能得到67x67的score map, 要比FCN確實要dense很多很多。
但是這種改變網絡結果的做法也帶來了一個問題: stride改變以后,如果想繼續利用vgg model進行fine tuning,會導致后面感受野發生變化。這個問題在下圖(a) (b)體現出來了,注意花括號就是感受野的大小:

感受野就是輸出featuremap某個節點的響應對應的輸入圖像的區域。比如我們第一層是一個33的卷積核,那么我們經過這個卷積核得到的featuremap中的每個節點都源自這個33的卷積核與原圖像中33的區域做卷積,那么我們就稱這個featuremap的節點感受野大小為33。
具體計算公式為:
其中:\(r_n\)表示第n層layer的輸入的某個區域,\(s_n\)表示第n層layer的步長,\(k_n\)表示kernel/pooling size
Deeplab提出了一種新的卷積,帶孔的卷積:Atrous Convolution。來解決兩個看似有點矛盾的問題:
既想利用已經訓練好的模型進行fine-tuning,又想改變網絡結構得到更加dense的score map。
如下圖(a) (b)所示,在以往的卷積或者pooling中,一個filter中相鄰的權重作用在feature map上的位置上是連續的。為了保證感受野不發生變化,某一層的stride由2變為1以后,后面的層需要采用hole算法,具體來講就是將連續的連接關系是根據hole size大小變成skip連接的。上圖(C)中使用hole為2的Atrous Convolution則感受野依然為7。(C)中的padding為2,如果再增加padding大小,是不是又變”粗糙”了?當然不會,因為是Atrous Convolution,連接是skip的,所以2個padding不會同時和一個filter相連。

所以,Atrous Convolution能夠保證這樣的池化后的感受野不變,從而可以fine tune,同時也能保證輸出的結果更加精細。即:

DeepLab后面接了一個全連接條件隨機場(Fully-Connected Conditional Random Fields)對分割邊界進行refine。 CRF簡單來說,能做到的就是在決定一個位置的像素值時(在這個paper里是label),會考慮周圍鄰居的像素值(label),這樣能抹除一些噪音。但是通過CNN得到的feature map在一定程度上已經足夠平滑了,所以short range的CRF沒什么意義。於是作者采用了fully connected CRF,這樣考慮的就是全局的信息了。

另外,CRF是后處理,是不參與訓練的,在測試的時候對feature map做完CRF后,再雙線性插值resize到原圖尺寸,因為feature map是8s的,所以直接放大到原圖是可以接受的。
v2 : DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
Submitted on 2 Jun 2016
v1之后,論文作者又推出了DeepLab的v2版本。這里就簡單講講改進的地方。
Multi-scale對performance提升很大,而我們知道,receptive field,視野域(或者感受野),是指feature map上一個點能看到的原圖的區域,那么如果有多個receptive field,是不是相當於一種Multi-scale?出於這個思路,v2版本在v1的基礎上增加了一個多視野域。具體看圖可以很直觀的理解。

rate也就是hole size。這個結構作者稱之為ASPP(atrous spatial pyramid pooling),基於洞的空間金字塔。
此外,DeepLab v2有兩個基礎網絡結構,一個是基於vgg16,另外一個是基於resnet101的
在VOC2012上的得分:

RefineNet
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
Submitted on 20 Nov 2016
主要貢獻:
- 帶有精心設計解碼器模塊的編碼器-解碼器結構
- 所有組件遵循殘差連接的設計方式
詳細解釋:
使用空洞卷積的方法也存在一定的缺點,它的計算成本比較高,同時由於需處理大量高分辨率特征圖譜,會占用大量內存,這個問題阻礙了高分辨率預測的計算研究。DeepLab得到的預測結果只有原始輸入的1/8大小。所以,這篇論文提出了相應的編碼器-解碼器結構,其中編碼器是ResNet-101模塊,解碼器為能融合編碼器高分辨率特征和先前RefineNet模塊低分辨率特征的RefineNet模塊。

每個RefineNet模塊包含一個能通過對較低分辨率特征進行上采樣來融合多分辨率特征的組件,以及一個能基於步幅為1及5×5大小的重復池化層來獲取背景信息的組件。這些組件遵循恆等映射的思想,采用了殘差連接的設計方式。

在VOC2012上的得分:

PSPNet
Pyramid Scene Parsing Network
Submitted on 4 Dec 2016
主要貢獻:
- 提出了金字塔池化模塊來聚合背景信息
- 使用了附加損失(auxiliary loss)
詳細解釋:
全局場景分類很重要,由於它提供了分割類別分布的線索。金字塔池化模塊使用大內核池化層來捕獲這些信息。和上文提到的空洞卷積論文一樣,PSPNet也用空洞卷積來改善Resnet結構,並添加了一個金字塔池化模塊。該模塊將ResNet的特征圖譜連接到並行池化層的上采樣輸出,其中內核分別覆蓋了圖像的整個區域、半各區域和小塊區域。
在ResNet網絡的第四階段(即輸入到金字塔池化模塊后),除了主分支的損失之外又新增了附加損失,這種思想在其他研究中也被稱為中級監督(intermediate supervision)。

在VOC2012上的得分:

大內核
Large Kernel Matters -- Improve Semantic Segmentation by Global Convolutional Network
Submitted on 8 Mar 2017
主要貢獻:
- 提出了一種帶有大維度卷積核的編碼器-解碼器結構。
詳細解釋:
這項研究通過全局卷積網絡來提高語義分割的效果。
語義分割不僅需要圖像分割,而且需要對分割目標進行分類。在分割結構中不能使用全連接層,這項研究發現可以使用大維度內核來替代。
采用大內核結構的另一個原因是,盡管ResNet等多種深層網絡具有很大的感受野,有相關研究發現網絡傾向於在一個小得多的區域來獲取信息,並提出了有效感受野的概念。
大內核結構計算成本高,且具有很多結構參數。因此,k×k卷積可近似成1×k+k×1和k×1+1×k的兩種分布組合。這個模塊稱為全局卷積網絡(Global Convolutional Network, GCN)。
接下來談結構,ResNet(不帶空洞卷積)組成了整個結構的編碼器部分,同時GCN網絡和反卷積層組成了解碼器部分。該結構還使用了一種稱作邊界細化(Boundary Refinement,BR)的簡單殘差模塊。GCN結構:

在VOC2012上的得分:

DeepLab v3
Rethinking Atrous Convolution for Semantic Image Segmentation
Submitted on 17 Jun 2017
主要貢獻:
- 改進了空間維度上的金字塔空洞池化方法(ASPP)
- 該模塊級聯了多個空洞卷積結構
詳細解釋:
與在DeepLab v2網絡、空洞卷積中一樣,這項研究也用空洞卷積/多空卷積來改善ResNet模型。這篇論文還提出了三種改善ASPP的方法,涉及了像素級特征的連接、加入1×1的卷積層和三個不同比率下3×3的空洞卷積,還在每個並行卷積層之后加入了批量歸一化操作。
級聯模塊實際上是一個殘差網絡模塊,但其中的空洞卷積層是以不同比率構建的。這個模塊與空洞卷積論文中提到的背景模塊相似,但直接應用到中間特征圖譜中,而不是置信圖譜。置信圖譜是指其通道數與類別數相同的CNN網絡頂層特征圖譜。
該論文獨立評估了這兩個所提出的模型,嘗試結合將兩者結合起來並沒有提高實際性能。兩者在驗證集上的實際性能相近,帶有ASPP結構的模型表現略好一些,且沒有加入CRF結構。
這兩種模型的性能優於DeepLab v2模型的最優值,文章中還提到性能的提高是由於加入了批量歸一化層和使用了更優的方法來編碼多尺度背景。

在VOC2012上的得分:

References:
blog.qure.ai
QbitAI
從FCN到DeepLab
A Review on Deep Learning Techniques Applied to Semantic Segmentation 翻譯
PASCAL VOC Challenge performance evaluation