1、頻率派概率和貝葉斯概率
概率論使能夠我們能夠提出不確定性的聲明以及在不確定性存在的情況下進行推理。概率論最初的發展是為了分析事件發生的頻率。有一類事件是可以重復的(比如投擲一枚硬幣,觀察硬幣落到正面還是反面),當我們說一個結果發生的概率為p,則如果我們進行無數次的反復實驗,有p的比例會導致這樣的結果。而另一類事件是不能重復的,比如醫生根據病人的症狀判斷病人有40%的概率患有流感,在這個例子中,概率用來表示一種信任度,1表示非常肯定病人患有流感,0表示非常肯定病人沒有流感。前面的一種概率,直接與時間發生的頻率相聯系,稱之為頻率派概率(frequentist probability);而后者則涉及到確定性水平,叫做貝葉斯概率(Bayesian probability)。
2、隨機變量
一個事件的所有可能結果組成這個事件的樣本空間,其中的每一種結果叫做樣本點。如果對於每一個樣本點,都有一個唯一的實數與之對應,則就產生了一個樣本點到唯一實數之間的函數,我們稱該函數為隨機變量。通俗地講,隨機變量就是將隨機事件的結果量化。比如同時投擲兩枚骰子,觀察兩枚骰子的點數,則樣本空間共有36個樣本點組成\(\{(i,j)|i=1,2...,6; j=1,2,...,6\}\),這里可以構造多個隨機變量,比如隨機變量x用來計算兩個骰子點數之和,則x={2,3,...,12},這里就將每一個實驗結果和一個實數映射了起來;再比如投擲一枚硬幣,可能出現正面和反面,我們將正面映射到1,反面映射到0,則x(正面)=1,x(反面)=0,所以有\(P({\rm x}=1)=0.5,P({\rm x} = 0)=0.5\)。所以,隨機變量實質上是函數。隨機變量中的每一個取值及取值的概率被稱為概率分布。
隨機變量可以是離散的,也可以是連續的。如果一個隨機變量的全部可能取值,只有有限多個或可列無窮多個,則稱它是離散型隨機變量,比如上面的計算兩個骰子點數之和。相反,如果隨機變量的取值為連續的(如全部實數,一段區間),則稱它為連續型隨機變量。
離散型隨機變量對應的常見分布有:
- 兩點分布
- 二項分布
- 幾何分布
- 超幾何分布
- 均勻分布
- 泊松分布
連續型隨機變量對應的常見分布有:
我們通常用無格式字體 (plain typeface) 中的小寫字母來表示隨機變量本身,而用手寫體中的小寫字母來表示隨機變量能夠取到的值。例如,\(x_1\) 和 \(x_2\) 都是隨機變量 x 可能的取值,對於向量值變量,我們會將隨機變量寫成 x,它的一個可能取值為 \(x\)。
3、離散型隨機變量及其分布律
離散型隨機變量的概率分布可以用分布律來描述(或者稱為概率質量函數,probability mass function, PMF )。我們通常用大寫字母\(P\)來表示離散型隨機變量的分布律,如\(P(\)x\()\)表示離散型隨機變量x的分布律。
分布律將隨機變量中的每個取值映射到該取值的概率。x = \(x\)的概率用\(P(\)x\(=x)\)來表示。有時我們會先定義一個隨機變量x,然后使用符號~來說明它遵循的分布:x~\(P(\)x\()\)。
分布律可以作用於多個隨機變量,這種多個隨機變量的概率分布被稱為聯合概率分布(joint probability distribution),如\(P(\)x=\(x\), y\(=y)\)表示x=\(x\),y=\(y\)同時發生的概率,有時可以簡寫為\(P(x,y)\)。
如果P是一個隨機變量的分布律,則要滿足下面幾個條件:
- \(P\)的定義域是 x 的所有可能取值的集合。
- 對\(∀x∈\rm x,0≤P(x)≤1\)。不可能事件概率為0,必然事件概率為1。
- \(Σ_{x∈\rm x}P(x)=1\),也就是\(P(x)\)的所有取值之和為1,我們稱這條性質為歸一化的(normalized)。
4、連續型隨機變量及其概率密度函數
連續型隨機變量的概率分布可以使用概率密度函數(probability density function, PDF)來描述。如果一個函數\(p\)是概率密度函數,則\(p\)需要滿足以下幾條性質:
- \(p\)的定義域是 x 的所有可能取值的集合。
- 對\(∀x∈\rm x,p(x)≥0\),注意,這里並不要求\(p(x)≤1\),因為\(p(x)\)只是概率密度函數,對\(p(x)\)積分才是概率分布律。
- \(P(a<{\rm x}≤b) = \int^b_a p(x){\rm d}x\),含義是\(x\)落到區間(a,b]的概率((a,b),[a, b], (a,b], [a, b)均滿足這個公式)。
- \(\int p(x){\rm d}x=1\)
下面用一個例子來解釋上面的幾條性質。
考慮在區間[a, b]上的均勻分布,我們用\(u(x;a,b)\)表示該分布的概率密度函數,\(x\)表示以\(x\)為參數,a,b是區間的端點且b>a,也就是\({\rm x}\)~\(u(x;a,b)\),則該均勻分布的概率密度曲線如下:
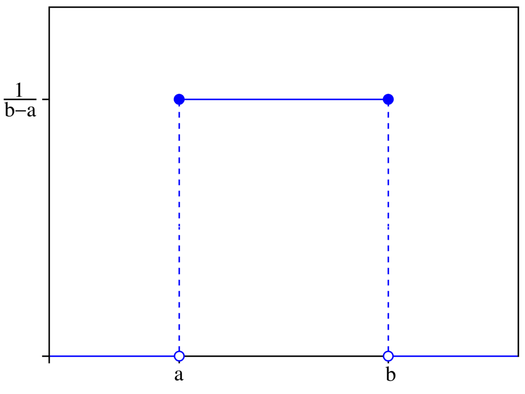
可以看到$u(x;a,b)={\frac{1}{b-a}}$,而且該函數的任一點都是非負的,且在[a, b]上對$u(x;a,b)$積分的結果為1。 ### 5、邊緣概率分布 有時候,我們知道了一組變量的**聯合概率分布**,但我們想了解某一個子集的概率分布,則這種定義在子集上的概率分布被稱為**邊緣概率分布**(marginal probability distribution)。 為什么叫**邊緣**概率分布呢? 舉個例子,假如有兩個隨機變量x, y的二維聯合概率分布如下表:
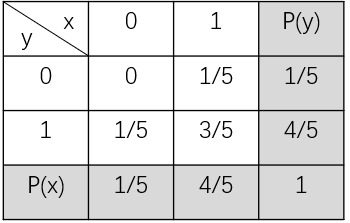
其中$P(x)$和$P(y)$為分別考慮隨機變量x和y時的概率,我們通常將其寫在表格的邊緣處,故稱之為邊緣概率。 從上表可以看出,$P({\rm x}=0)$的概率為x=0時對y的各概率相加,也就是0+1/5=1/5,用公式表示為:
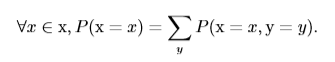
這稱為**求和法則**(sum rule)。 上面的例子中的隨機變量為離散型的,若隨機變量為連續型的,我們需要用積分代替求和:

該公式為x的邊緣概率分布,對x積分可得y的邊緣概率分布。 ### 6、條件概率 在很多情況下,我們感興趣的是一個事件已經發生的情況下,另一個事件發生的概率,這種概率叫做**條件概率**。在事件x已經發生的情況下,事件y發生的概率表示為$P({\rm y}=y|{\rm x}=x)$,可通過下面的公式計算:

其中$P({\rm y}=y,{\rm x}=x)$為$x$和$y$同時發生的概率(也就是聯合概率分布)。條件概率只在$P({\rm x}=x)>0$時有意義。 ### 7、條件概率的鏈式法則 從上節的條件概率公式可以知道兩個事件b,c同時發生的概率:$$P(b, c)=P(b|c)P(c)$$,則三個事件a,b,c同時發生的概率為:$$P(a,b,c)=P(a|b,c)P(b,c)=P(a|b,c)P(b|c)P(c)$$,由數學歸納法可以得到:
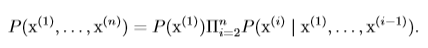
含義是任何多維隨機變量的聯合概率分布,都可以分解成只有一個變量的條件概率相乘的形式。這個規則被稱為**鏈式法則**或**乘法法則**。 ### 8、獨立性和條件獨立性 #### 8.1、獨立性 如果兩個隨機變量(事件)x,y同時發生的概率等於這兩個變量(事件)單獨發生的概率乘積,則稱這兩個隨機變量是獨立的,即:
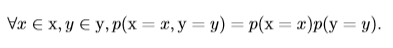
也就是x和y的聯合概率分布等於兩個邊緣概率分布之積。 #### 8.2、條件獨立性 如果在隨機變量(事件)z已經發生的情況下,隨機變量(事件)x和y同時發生的概率等於x和y在z已發生的情況下分別發生的概率乘積,即:
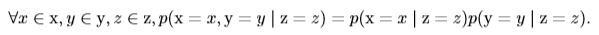
我們稱之為x和y在給定z的情況下是**條件獨立**的。 有一種簡化表示:x⊥y表示x和y相互獨立,x⊥y|z表示x和y在給定z時條件獨立。 ### 9、期望、方差和協方差 #### 9.1、期望 **期望**(expectation)就是隨機變量取值的平均值。設$f(x)$是隨機變量x的函數,則對於離散型隨機變量x,f(x)的期望可以通過求和得到(比如我們知道x的分布,求$f(x)=x^2$的期望):
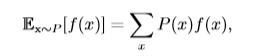
對於連續型隨機變量x,f(x)的期望通過積分得到:
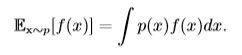
$\mathbb{E}_x[f(x)]$表示f(x)的期望,當期望作用的隨機變量很明顯時,我們可以不寫腳標,簡寫為$\mathbb{E}[f(x)]$。默認地,我們假設$\mathbb{E}[·]$對方括號內的所有隨機變量的值取平均值,當沒有歧義時,我們還可以省略方括號。 **期望是線性的**,如:
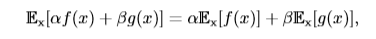
#### 9.2、方差 期望反映了隨機變量分布的平均取值,但在實際問題中,我們不僅關心隨機變量的平均取值,還關心隨機變量的取值與平均取值(期望)的偏離程度,**方差**(variance)就是用來衡量這種偏離程度的,也就是衡量隨機變量x取值的差異性。設f(x)是隨機變量x的函數,則f(x)方差的計算公式如下:
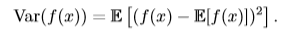
方差越小,則f(x)的值越接近f(x)的期望值。方差的平方根被稱為**標准差**(standard deviation)。 #### 9.3、協方差 **協方差**(covariance)在某種意義上給出了兩個隨機變量之間的相關程度的大小。如隨機變量x和y相互獨立,則x與y的協方差Cov(x, y)=0。設f(x)是x的函數,g(y)是y的函數,則f(x)和g(y)的協方差計算方法為:
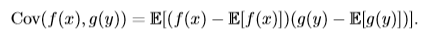
協方差的**絕對值**如果很大則意味着變量值變化很大並且它們同時距離各自的均值很遠。如果協方差是正的,那么兩個變量都傾向於同時取得相對較大的值。如果協方差是負的,那么其中一個變量傾向於取得相對較大的值的同時,另一個變量傾向於取得相對較小的值,反之亦然。其他的衡量指標如**相關系數**(correlation)將每個變量的貢獻歸一化,為了只衡量變量的相關性而不受各個變量尺度大小的影響。 協方差和相關性是有聯系的,但實際上是不同的概念。它們是有聯系的,因為兩個變量如果相互獨立那么它們的協方差為零,如果兩個變量的協方差不為零那么它們一定是相關的。然而,獨立性又是和協方差完全不同的性質。兩個變量如果協方差為零,它們之間一定沒有線性關系。獨立性比零協方差的要求更強,因為獨立性還排除了非線性的關系。兩個變量相互依賴但具有零協方差是可能的。 隨機向量(由多個隨機變量組成的向量)$x∈\mathbb{R}^n$的**協方差矩陣**(covariance matrix)是一個nxn的矩陣,並且滿足:
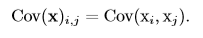
協方差矩陣的對角元是方差:
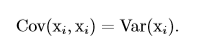
### 10、常見的分布 #### 10.1、伯努利分布(Bernoulli distribution) 一般把只有兩個對立結果的實驗叫做**伯努利實驗**,如投硬幣就是一個伯努利實驗,因為投擲的結果只有正面和反面。把伯努利實驗在相同條件下重復進行n次,且這n次實驗相互獨立,則稱這n次實驗為**n重(次)伯努利實驗**,或稱為**伯努利概型**,對應的概率分布叫做**二項分布**。當n=1時,二項分布變為**伯努利分布**(又稱**兩點分布**,或者**0-1分布**),也就是說伯努利分布是只進行1次伯努利試驗的概率分布。伯努利分布適用於離散型隨機變量。 伯努利分布由單個參數Φ∈[0,1]控制,Φ給出了隨機變量x等於1(如硬幣正面)的概率,則P(x=0)=1-Φ。伯努利分布具有如下性質:
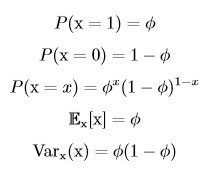
#### 10.2、多項式分布(multinoulli distribution) 在10.1中介紹了**二項分布**,指在每次實驗中,實驗結果只有兩個狀態(投硬幣)。若每次實驗的實驗結果有k個狀態(投骰子),進行n次相互獨立的實驗對應的概率分布叫做**多項式分布**,或者**范疇分布**。多項式分布由向量$p∈[0, 1]^{k-1}$參數化,其中$p_i$表示第i個狀態發生的概率,最后第k個狀態的概率可以通過$1-1^Tp$求出。多項式分布適用於離散型隨機變量。 伯努利分布和多項式分布足夠用來描述在它們領域內的任意分布。它們能夠描述這些分布,不是因為它們特別強大,而是因為它們的領域很簡單;它們可以對那些能夠將所有的狀態進行枚舉的離散型隨機變量進行建模。當處理的是連續型隨機變量時,會有不可數無限多的狀態,所以任何通過少量參數描述的概率分布都必須在分布上加以嚴格的限制。 #### 10.3、正態分布(normal distribution) 實數上最常用的分布就是**正態分布**(normal distribution),也稱為**高斯分布** (Gaussian distribution):
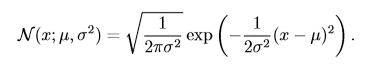
下圖為正態分布的概率密度函數:
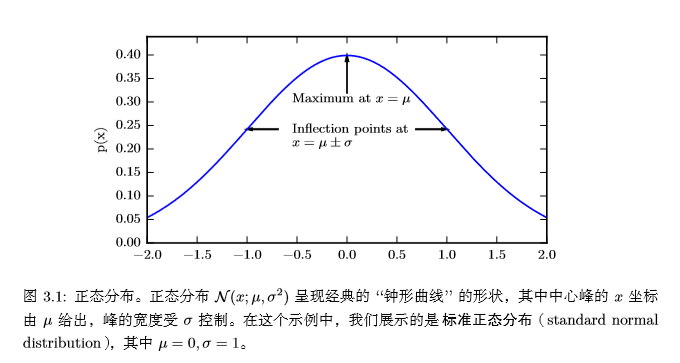
在曲線形狀上,若固定μ,σ越小,曲線越瘦高;σ越大,曲線越矮胖。 正態分布由兩個參數控制:$μ∈\mathbb{R}$和$σ∈(0,+\infty)$。σ表示正態變量取值的集中或分散程度,σ越大,取值也就越分散;而參數μ則反映了正態變量的平均取值和取值的集中位置。實際上,$μ$和$σ^2$分別是正態變量的均值和方差。 當我們要對概率密度函數求值時,我們需要對 σ 平方並且取倒數。當我們需要經常對不同參數下的概率密度函數求值時,一種更高效的參數化分布的方式是使用參數 β ∈ (0,∞),來控制分布的**精度**(precision)(或方差的倒數):
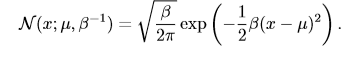
當我們由於缺乏關於某個實數上分布的先驗知識而不知道該選擇怎樣的形式時,正態分布是默認的比較好的選擇。 正態分布也可以擴展到n維空間,這種情況被稱為**多維正態分布**,它的參數是一個正定矩陣**Σ**(特征值均為正數):
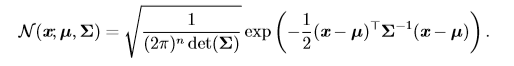
參數 **µ** 仍然表示分布的均值,只不過現在是向量值。參數 **Σ** 給出了分布的協方差矩陣。我們常常把協方差矩陣固定成一個對角陣。一個更簡單的版本是**各向同性** (isotropic)高斯分布,它的協方差矩陣是一個標量乘以單位陣。 #### 10.4、指數分布和Laplace分布 在深度學習中,我們經常會需要一個在 x = 0 點處取得**邊界點**(sharp point) 的分布。我們可以使用**指數分布**來達到這一目的:
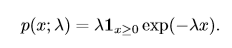
一個聯系緊密的概率分布是**Laplace分布**(Laplace distribution,拉普拉斯分布),它允許我們 在任意一點 µ 處設置概率質量(分布律)的峰值 :
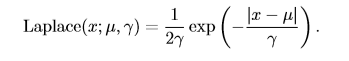
#### 10.5、Dirac分布和經驗分布 #### 10.5.1、Dirac分布 在一些情況下,我們希望概率分布中的所有質量都集中在一個點上。這可以通過**Dirac delta 函數**(Dirac delta function,狄拉克函數)δ(x) 定義概率密度函數來實現: $$p(x)=σ(x)$$ 狄拉克函數可以被描述成在原點處無限高,無限窄的曲線,並且它的積分為1,也就是說該函數在原點處取值為$+\infty$,其他點處為0。通過把 p(x) 定義成 δ 函數左移 −µ 個單位,我們得到了一個在 x = µ 處具有無限窄也無限高的峰值的概率密度函數:$$p(x)=σ(x-μ)$$ #### 10.5.2、經驗分布 Dirac 分布經常作為**經驗分布**(empirical distribution)的一個組成部分出現:
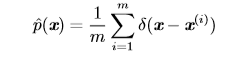
經驗分布將概率密度 1/m 賦給 m 個點 $x^{(1)},...,x^{(m)}$ 中的每一個,這些點是給定的數據集或者采樣的集合。只有在定義連續型隨機變量的經驗分布時,Dirac delta 函數才是必要的。對於離散型隨機變量,情況更加簡單:經驗分布可以被定義成一 個 Multinoulli 分布,對於每一個可能的輸入,其概率可以簡單地設為在訓練集上那個輸入值的**經驗頻率**(empirical frequency)。 當我們在訓練集上訓練模型時,我們可以認為從這個訓練集上得到的經驗分布指明了我們采樣來源的分布。關於經驗分布另外一種重要的觀點是,它是訓練數據的似然最大的那個概率密度函數 。 ### 11、分布的混合 通過組合一些簡單的概率分布來定義新的概率分布也是很常見的。一種通用的組合方法是構造**混合分布**(mixture distribution)。混合分布由一些組件 (component) 分布構成。我們在上一節中已經看過一個混合分布的例子了:實值變量的**經驗分布**對於每一個訓練實例來說,就是以 Dirac 分布為組件的混合分布。 ### 12、常用函數的有用性質 #### 12.1、logistic sigmoid函數 **logistic sigmoid函數**的表示如下:
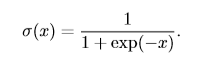
logistic sigmoid 函數通常用來**產生伯努利分布中的參數 ϕ**,因為它的范圍是 (0,1),處在 ϕ 的有效取值范圍內。下面是logistic sigmoid函數的曲線:
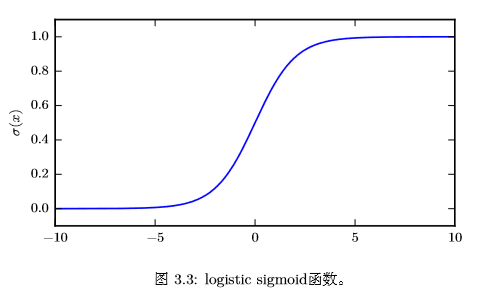
sigmoid函數在變量取絕對值非常大的正值或負值時會出現飽和(saturate)現象,意味着函數會變得很平,並且對輸入的微小改變會變得不敏感。 #### 12.2、softplus函數 **softplus函數**的表示如下:
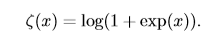
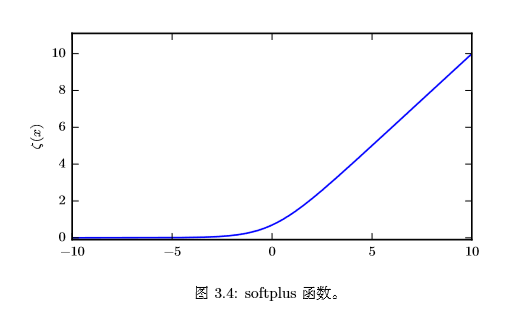
softplus 函數可以用來**產生正態分布的 β 和 σ 參數**,因為它的范圍是 (0,∞)。softplus的函數名來源於它是另一個函數的平滑形式,這個函數是:
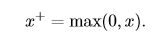
該函數被稱為**正部函數**。 softplus的函數曲線如下圖所示:
#### 12.3、有用的性質 關於logistic sigmoid函數和softplus函數有一些非常有用的性質:
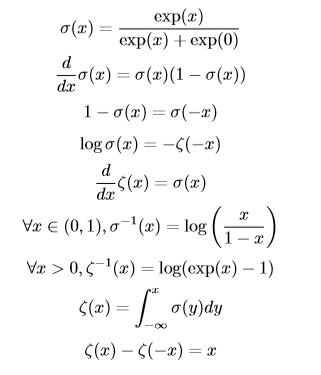
### 13、貝葉斯規則 我們經常會在已知$P(y|x)$的時候來計算$P(x|y)$,這時我們可以使用下面的公式:$$P(x|y)=\frac{P(x,y)}{P(y)}=\frac{P(x)P(y|x)}{P(y)}$$,但$P(y)$有時是不知道的,我們可以使用公式$P(y) = Σ_xP(y|x)P(x)$來計算。 ### 14、結構化概率模型 機器學習的算法經常涉及到在非常多的隨機變量上的概率分布,通常這些隨機變量中的直接相互作用只牽扯到非常少的變量。使用單個函數來描述整個聯合概率分布是非常低效的,這時,我們可以把單個函數分解成因子相乘的形式。比如,有三個隨機變量a,b,c,a影響b的取值,b影響c的取值,但a和c在b給定的情況下是獨立的,則$$p(a,b,c)=p(b)p(a,c|b)=p(b)p(a|b)p(c|b)$$ 這種分解可以極大地減少描述一個分布的參數數量。 我們還可以使用圖論中的圖來表示這種分解,隨機變量代表圖中的結點,邊表示隨機變量間是否有聯系。假設有5個隨機變量a,b,c,d,e,它們對應的圖如下:
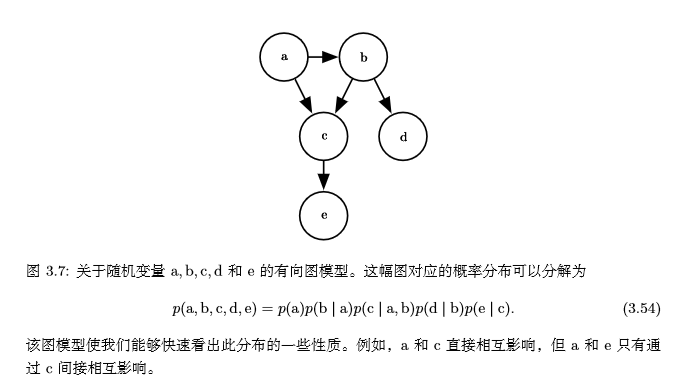
當我們用圖來表示聯合概率分布的分解時,我們把它稱為**結構化概率模型**(structured probabilistic model)或者**圖模型** (graphical model)。 有兩種主要的結構化概率模型:**有向的**和**無向的**。兩種圖模型都使用圖 G,其中 圖的每個節點對應着一個隨機變量,連接兩個隨機變量的邊意味着概率分布可以表示成這兩個隨機變量之間的直接作用。 上面的例子是**有向模型**(directed),它們使用條件概率來表示分解,另一種是**無向模型**。無向模型使用帶有無向邊的圖,它們將分解表示為函數,通常這些函數並不是任何類型的概率分布。在圖G中,如果一個子圖中的結點兩兩互連,則稱該子圖為**團**,記為$C^(i)$。無向模型中的每個團$C^(i)$都伴隨着一個因子$Φ^(i)(C^(i))$,這些因子僅僅是函數,不是概率分布,每個因子的輸出都必須是**非負的**,因子的和或者積分不要求為1。一個無向模型的例子:
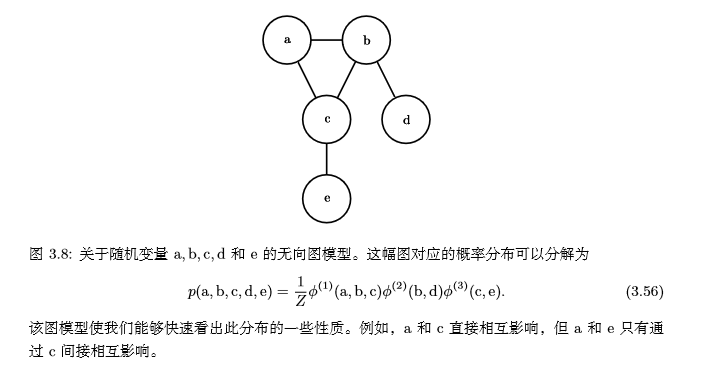
請記住,這些圖模型表示的分解僅僅是描述概率分布的一種語言。它們不是互相排斥的概率分布族。有向或者無向不是概率分布的特性,它是概率分布的一種特殊**描述**(description)所具有的特性,而任何概率分布都可以用這兩種方式進行描述。 ### 15、參考 #### 15.1、《深度學習》中文版