在Baidu上以FM和DNN為關鍵詞搜索的結果中,我找遍了都沒看明白FM和DNN怎么能聯系在一起,上周在導師討論會的壓力下,終於自己想明白了,這里記錄一下。
在上一篇blog中,已經介紹了FM模型,對FM模型進行求解后,對於每一個特征\(x_i\)都能夠得到對應的隱向量\(v_i\),那么這個\(v_i\)到底是什么呢?
想一想Google提出的word2vec,word2vec是word embedding方法的一種,word embedding的意思就是,給出一個文檔,文檔就是一個單詞序列,比如 “A B A C B F G”, 希望對文檔中每個不同的單詞都得到一個對應的向量(往往是低維向量)表示。比如,對於這樣的“A B A C B F G”的一個序列,也許我們最后能得到:A對應的向量為[0.1 0.6 -0.5],B對應的向量為[-0.2 0.9 0.7] 。
倫敦大學張偉楠博士在攜程深度學習Meetup[2]上分享了Talk《Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction in Display Ads》。主要講了他基於DNN來解決CTR prediction的想法,其中有關於DNN輸入層的設計圖如下:
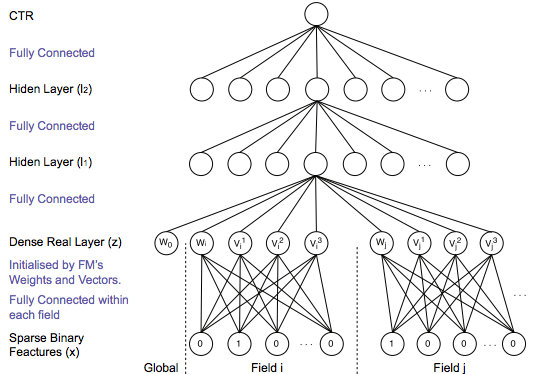
其實,在學習FM模型的時候,我們得到的就是各個離散特征的embedding表示,即FM求解得到的$v_i$就是對應特征的embedding,因此就可以將稀疏的離散特征轉化為連續的多維向量,就得到了DNN的輸入層。