本文目錄
一、Apache Spark
二、Spark SQL發展歷程
三、Spark SQL底層執行原理
四、Catalyst 的兩大優化
一、Apache Spark
Apache Spark是用於大規模數據處理的統一分析引擎,基於內存計算,提高了在大數據環境下數據處理的實時性,同時保證了高容錯性和高可伸縮性,允許用戶將Spark部署在大量硬件之上,形成集群。
Spark源碼從1.x的40w行發展到現在的超過100w行,有1400多位大牛貢獻了代碼。整個Spark框架源碼是一個巨大的工程。
二、Spark SQL發展歷程

我們知道Hive實現了SQL on Hadoop,簡化了MapReduce任務,只需寫SQL就能進行大規模數據處理,但是Hive也有致命缺點,因為底層使用MapReduce做計算,查詢延遲較高。
1. Shark的誕生
所以Spark在早期版本(1.0之前)推出了Shark,這是什么東西呢,Shark與Hive實際上還是緊密關聯的,Shark底層很多東西還是依賴於Hive,但是修改了內存管理、物理計划、執行三個模塊,底層使用Spark的基於內存的計算模型,從而讓性能比Hive提升了數倍到上百倍。
產生了問題:
-
因為 Shark 執行計划的生成嚴重依賴 Hive,想要增加新的優化非常困難; -
Hive 是進程級別的並行,Spark 是線程級別的並行,所以 Hive 中很多線程不安全的代碼不適用於 Spark; -
由於以上問題,Shark 維護了 Hive 的一個分支,並且無法合並進主線,難以為繼; -
在 2014 年 7 月 1 日的 Spark Summit 上,Databricks 宣布終止對 Shark 的開發,將重點放到 Spark SQL 上。
2. SparkSQL-DataFrame誕生
解決問題:
-
Spark SQL 執行計划和優化交給優化器 Catalyst;
-
內建了一套簡單的 SQL 解析器,可以不使用 HQL;
-
還引入和 DataFrame 這樣的 DSL API,完全可以不依賴任何 Hive 的組件。
新的問題:
對於初期版本的 SparkSQL,依然有挺多問題,例如只能支持 SQL 的使用,不能很好的兼容命令式,入口不夠統一等。
3. SparkSQL-Dataset誕生
SparkSQL 在 1.6 時代,增加了一個新的 API,叫做 Dataset,Dataset 統一和結合了 SQL 的訪問和命令式 API 的使用,這是一個划時代的進步。
在 Dataset 中可以輕易的做到使用 SQL 查詢並且篩選數據,然后使用命令式 API 進行探索式分析。
三、Spark SQL底層執行原理
Spark SQL 底層架構大致如下:

可以看到,我們寫的SQL語句,經過一個優化器(Catalyst),轉化為RDD,交給集群執行。
SQL到RDD中間經過了一個Catalyst,它就是Spark SQL的核心,是針對Spark SQL語句執行過程中的查詢優化框架,基於Scala函數式編程結構。
我們要了解Spark SQL的執行流程,那么理解Catalyst的工作流程是非常有必要的。
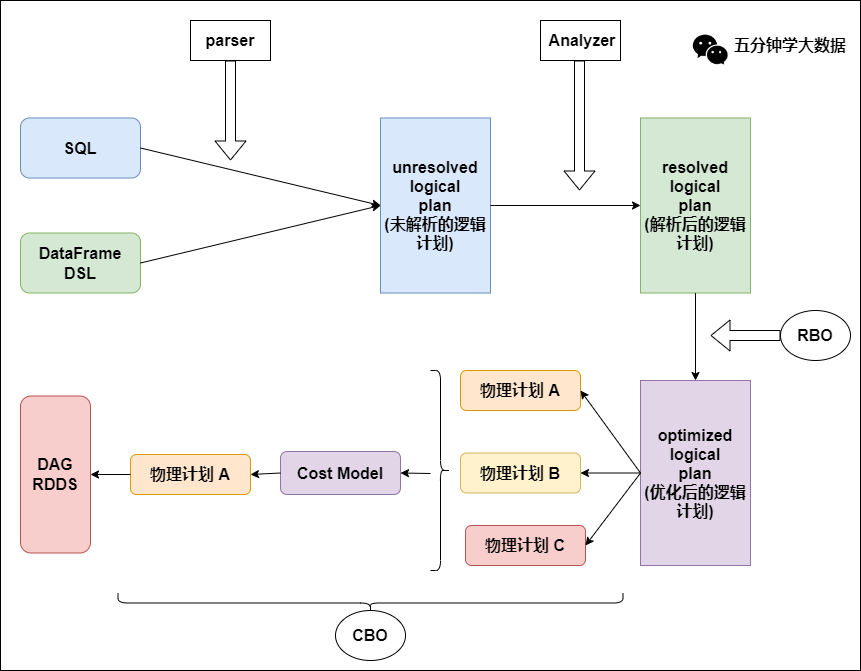
一條SQL語句生成執行引擎可識別的程序,就離不開解析(Parser)、優化(Optimizer)、執行(Execution) 這三大過程。而Catalyst優化器在執行計划生成和優化的工作時候,它離不開自己內部的五大組件,如下所示:
-
Parser模塊:將SparkSql字符串解析為一個抽象語法樹/AST。
-
Analyzer模塊:該模塊會遍歷整個AST,並對AST上的每個節點進行數據類型的綁定以及函數綁定,然后根據元數據信息Catalog對數據表中的字段進行解析。
-
Optimizer模塊:該模塊是Catalyst的核心,主要分為RBO和CBO兩種優化策略,其中RBO是基於規則優化,CBO是基於代價優化。
-
SparkPlanner模塊:優化后的邏輯執行計划OptimizedLogicalPlan依然是邏輯的,並不能被Spark系統理解,此時需要將OptimizedLogicalPlan轉換成physical plan(物理計划) 。
-
CostModel模塊:主要根據過去的性能統計數據,選擇最佳的物理執行計划。這個過程的優化就是CBO(基於代價優化)。
為了更好的對整個過程進行理解,下面通過簡單的實例進行解釋。
步驟1. Parser階段:未解析的邏輯計划
Parser簡單說就是將SQL字符串切分成一個一個的Token,再根據一定語義規則解析成一顆語法樹。Parser模塊目前都是使用第三方類庫ANTLR進行實現的,包括我們熟悉的Hive、Presto、SparkSQL等都是由ANTLR實現的。
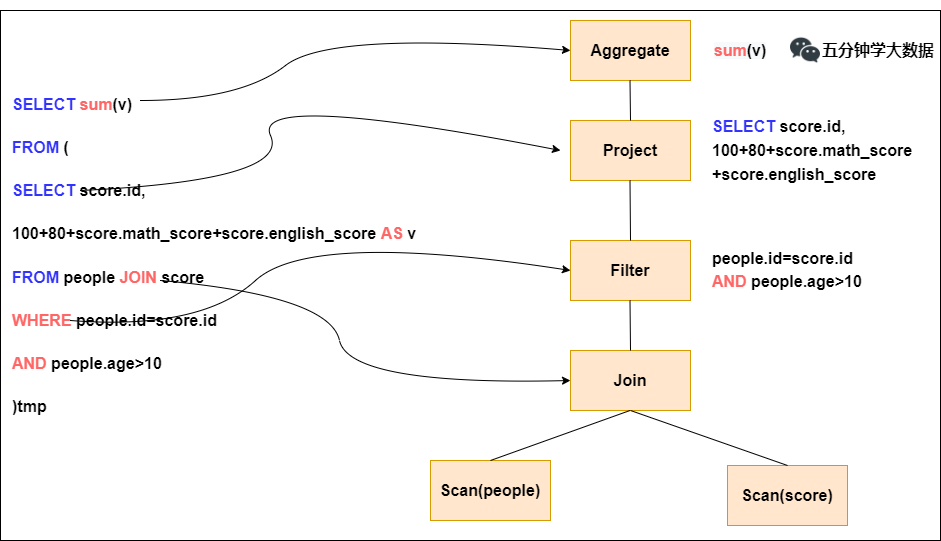
在這個過程中,會判斷SQL語句是否符合規范,比如select from where 等這些關鍵字是否寫對。當然此階段不會對表名,表字段進行檢查。
步驟2. Analyzer階段:解析后的邏輯計划
通過解析后的邏輯計划基本有了骨架,此時需要基本的元數據信息來表達這些詞素,最重要的元數據信息主要包括兩部分:表的Scheme和基本函數信息,表的Scheme主要包括表的基本定義(列名、數據類型)、表的數據格式(Json、Text)、表的物理位置等,基本函數主要指類信息。
Analyzer會再次遍歷整個語法樹,對樹上的每個節點進行數據類型綁定及函數綁定,比如people詞素會根據元數據表信息解析為包含age、id以及name三列的表,people.age會被解析為數據類型的int的變量,sum被解析為特定的聚合函數。
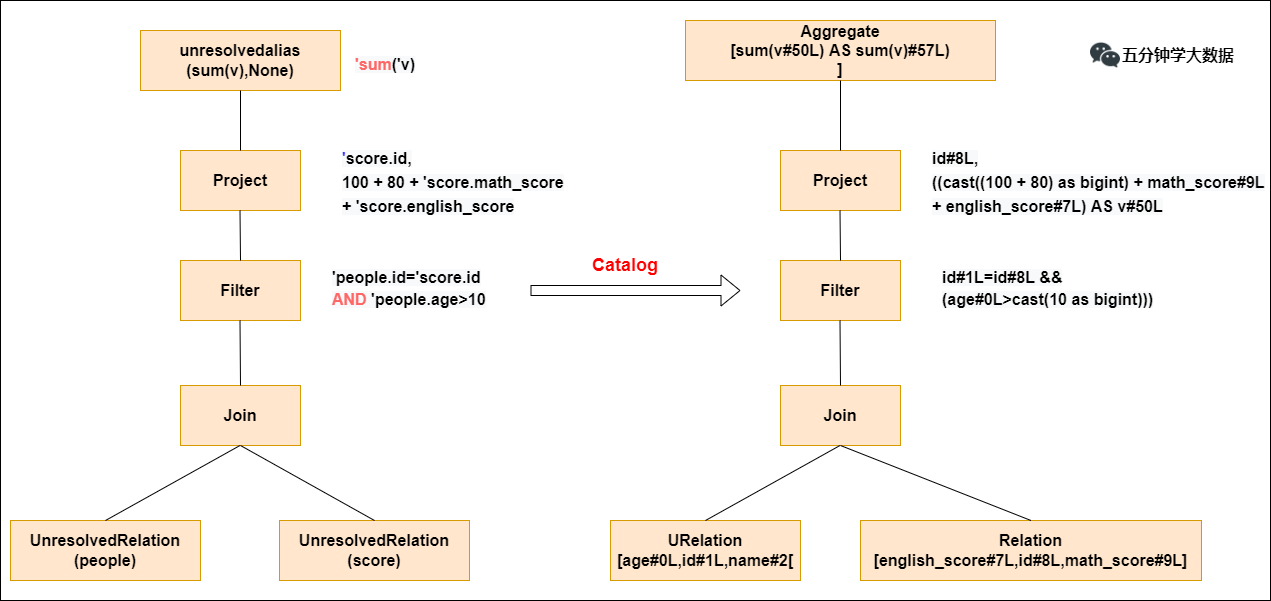
此過程就會判斷SQL語句的表名,字段名是否真的在元數據庫里存在。
步驟3. Optimizer模塊:優化過的邏輯計划
Optimizer優化模塊是整個Catalyst的核心,上面提到優化器分為基於規則的優化(RBO)和基於代價優化(CBO)兩種。基於規則的優化策略實際上就是對語法樹進行一次遍歷,模式匹配能夠滿足特定規則的節點,在進行相應的等價轉換。下面介紹三種常見的規則:謂詞下推(Predicate Pushdown) 、常量累加(Constant Folding) 、列值裁剪(Column Pruning) 。
-
謂詞下推(Predicate Pushdown)

上圖左邊是經過解析后的語法樹,語法樹中兩個表先做join,之后在使用age>10進行filter。join算子是一個非常耗時的算子,耗時多少一般取決於參與join的兩個表的大小,如果能夠減少參與join兩表的大小,就可以大大降低join算子所需的時間。
謂詞下推就是將過濾操作下推到join之前進行,之后再進行join的時候,數據量將會得到顯著的減少,join耗時必然降低。
-
常量累加(Constant Folding)

常量累加就是比如計算x+(100+80)->x+180,雖然是一個很小的改動,但是意義巨大。如果沒有進行優化的話,每一條結果都需要執行一次100+80的操作,然后再與結果相加。優化后就不需要再次執行100+80操作。
-
列值裁剪(Column Pruning)
列值裁剪是當用到一個表時,不需要掃描它的所有列值,而是掃描只需要的id,不需要的裁剪掉。這一優化一方面大幅度減少了網絡、內存數據量消耗,另一方面對於列式存儲數據庫來說大大提高了掃描效率。
步驟4. SparkPlanner模塊:轉化為物理執行計划
根據上面的步驟,邏輯執行計划已經得到了比較完善的優化,然而,邏輯執行計划依然沒辦法真正執行,他們只是邏輯上可行,實際上Spark並不知道如何去執行這個東西。比如join是一個抽象概念,代表兩個表根據相同的id進行合並,然而具體怎么實現合並,邏輯執行計划並沒有說明。
此時就需要將邏輯執行計划轉化為物理執行計划,也就是將邏輯上可行的執行計划變為Spark可以真正執行的計划。比如join算子,Spark根據不同場景為該算子制定了不同的算法策略,有BroadcastHashJoin、ShuffleHashJoin以及SortMergejoin等,物理執行計划實際上就是在這些具體實現中挑選一個耗時最小的算法實現,怎么挑選,下面簡單說下:
-
實際上SparkPlanner對優化后的邏輯計划進行轉換,是生成了多個可以執行的物理計划Physical Plan;
-
接着CBO(基於代價優化)優化策略會根據Cost Model算出每個Physical Plan的代價,並選取代價最小的 Physical Plan作為最終的Physical Plan。
以上2、3、4步驟合起來,就是Catalyst優化器!
步驟5. 執行物理計划
最后依據最優的物理執行計划,生成java字節碼,將SQL轉化為DAG,以RDD形式進行操作。
總結:整體執行流程圖
四、Catalyst 的兩大優化
這里在總結下Catalyst優化器的兩個重要的優化。
1. RBO:基於規則的優化
優化的點比如:謂詞下推、列裁剪、常量累加等。
-
謂詞下推案例:
select
*
from
table1 a
join
table2 b
on a.id=b.id
where a.age>20 and b.cid=1
上面的語句會自動優化為如下所示:
select
*
from
(select * from table1 where age>20) a
join
(select * from table2 where cid=1) b
on a.id=b.id
就是在子查詢階段就提前將數據進行過濾,后期join的shuffle數據量就大大減少。
-
列裁剪案例:
select
a.name, a.age, b.cid
from
(select * from table1 where age>20) a
join
(select * from table2 where cid=1) b
on a.id=b.id
上面的語句會自動優化為如下所示:
select
a.name, a.age, b.cid
from
(select name, age, id from table1 where age>20) a
join
(select id, cid from table2 where cid=1) b
on a.id=b.id
就是提前將需要的列查詢出來,其他不需要的列裁剪掉。
-
常量累加:
select 1+1 as id from table1
上面的語句會自動優化為如下所示:
select 2 as id from table1
就是會提前將1+1計算成2,再賦給id列的每行,不用每次都計算一次1+1。
2. CBO:基於代價的優化
就是在SparkPlanner對優化后的邏輯計划生成了多個可以執行的物理計划Physical Plan之后,多個物理執行計划基於Cost Model選取最優的執行耗時最少的那個物理計划。