原文鏈接:本着什么原則,才能寫出優秀的代碼?
作為一名程序員,最不愛干的事情,除了開會之外,可能就是看別人的代碼。
有的時候,新接手一個項目,打開代碼一看,要不是身體好的話,可能直接氣到暈厥。
風格各異,沒有注釋,甚至連最基本的格式縮進都做不到。這些代碼存在的意義,可能就是為了證明一句話:又不是不能跑。
在這個時候,大部分程序員的想法是:這爛代碼真是不想改,還不如直接重寫。
但有的時候,我們看一些著名的開源項目時,又會感嘆,代碼寫的真好,優雅。為什么好呢?又有點說不出來,總之就是好。
那么,這篇文章就試圖分析一下好代碼都有哪些特點,以及本着什么原則,才能寫出優秀的代碼。
初級階段
先說說比較基本的原則,只要是程序員,不管是高級還是初級,都會考慮到的。
這只是列舉了一部分,還有很多,我挑選四項簡單舉例說明一下。
- 格式統一
- 命名規范
- 注釋清晰
- 避免重復代碼
以下用 Python 代碼分別舉例說明:
格式統一
格式統一包括很多方面,比如 import 語句,需要按照如下順序編寫:
- Python 標准庫模塊
- Python 第三方模塊
- 應用程序自定義模塊
然后每部分間用空行分隔。
import os
import sys
import msgpack
import zmq
import foo
再比如,要添加適當的空格,像下面這段代碼;
i=i+1
submitted +=1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)
代碼都緊湊在一起了,很影響閱讀。
i = i + 1
submitted += 1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)
添加空格之后,立刻感覺清晰了很多。
還有就是像 Python 的縮進,其他語言的大括號位置,是放在行尾,還是另起新行,都需要保證統一的風格。
有了統一的風格,會讓代碼看起來更加整潔。
命名規范
好的命名是不需要注釋的,只要看一眼命名,就能知道變量或者函數的作用。
比如下面這段代碼:
a = 'zhangsan'
b = 0
a 可能還能猜到,但當代碼量大的時候,如果滿屏都是 a,b,c,d,那還不得原地爆炸。
把變量名稍微改一下,就會使語義更加清晰:
username = 'zhangsan'
count = 0
還有就是命名要風格統一。如果用駝峰就都用駝峰,用下划線就都用下划線,不要有的用駝峰,有點用下划線,看起來非常分裂。
注釋清晰
看別人代碼的時候,最大的願望就是注釋清晰,但在自己寫代碼時,卻從來不寫。
但注釋也不是越多越好,我總結了以下幾點:
- 注釋不限於中文或英文,但最好不要中英文混用
- 注釋要言簡意賅,一兩句話把功能說清楚
- 能寫文檔注釋應該盡量寫文檔注釋
- 比較重要的代碼段,可以用雙等號分隔開,突出其重要性
舉個例子:
# =====================================
# 非常重要的函數,一定謹慎使用 !!!
# =====================================
def func(arg1, arg2):
"""在這里寫函數的一句話總結(如: 計算平均值).
這里是具體描述.
參數
----------
arg1 : int
arg1的具體描述
arg2 : int
arg2的具體描述
返回值
-------
int
返回值的具體描述
參看
--------
otherfunc : 其它關聯函數等...
示例
--------
示例使用doctest格式, 在`>>>`后的代碼可以被文檔測試工具作為測試用例自動運行
>>> a=[1,2,3]
>>> print [x + 3 for x in a]
[4, 5, 6]
"""
避免重復代碼
隨着項目規模變大,開發人員增多,代碼量肯定也會增加,避免不了的會出現很多重復代碼,這些代碼實現的功能是相同的。
雖然不影響項目運行,但重復代碼的危害是很大的。最直接的影響就是,出現一個問題,要改很多處代碼,一旦漏掉一處,就會引發 BUG。
比如下面這段代碼:
import time
def funA():
start = time.time()
for i in range(1000000):
pass
end = time.time()
print("funA cost time = %f s" % (end-start))
def funB():
start = time.time()
for i in range(2000000):
pass
end = time.time()
print("funB cost time = %f s" % (end-start))
if __name__ == '__main__':
funA()
funB()
funA() 和 funB() 中都有輸出函數運行時間的代碼,那么就適合將這些重復代碼抽象出來。
比如寫一個裝飾器:
def warps():
def warp(func):
def _warp(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
end = time.time()
print("{} cost time = {}".format(getattr(func, '__name__'), (end-start)))
return _warp
return warp
這樣,通過裝飾器方法,實現了同樣的功能。以后如果需要修改的話,直接改裝飾器就好了,一勞永逸。
進階階段
當代碼寫時間長了之后,肯定會對自己有更高的要求,而不只是格式,注釋這些基本規范。
但在這個過程中,也是有一些問題需要注意的,下面就來詳細說說。
炫技
第一個要說的就是「炫技」,當對代碼越來越熟悉之后,總想寫一些高級用法。但現實造成的結果就是,往往會使代碼過度設計。
這不得不說說我的親身經歷了,曾經有一段時間,我特別迷戀各種高級用法。
有一次寫過一段很長的 SQL,而且很復雜,里面甚至還包含了一個遞歸調用。有「炫技」嫌疑的 Python 代碼就更多了,往往就是一行代碼包含了 N 多魔術方法。
然后在寫完之后漏出滿意的笑容,感慨自己技術真牛。
結果就是各種被罵,更重要的是,一個星期之后,自己都看不懂了。

其實,代碼並不是高級方法用的越多就越牛,而是要找到最適合的。
越簡單的代碼,越清晰的邏輯,就越不容易出錯。而且在一個團隊中,你的代碼並不是你一個人維護,降低別人閱讀,理解代碼的成本也是很重要的。
脆弱
第二點需要關注的是代碼的脆弱性,是否細微的改變就可能引起重大的故障。
代碼里是不是充滿了硬編碼?如果是的話,則不是優雅的實現。很可能導致每次性能優化,或者配置變更就需要修改源代碼。甚至還要重新打包,部署上線,非常麻煩。
而把這些硬編碼提取出來,設計成可配置的,當需要變更時,直接改一下配置就可以了。
再來,對參數是不是有校驗?或者容錯處理?假如有一個 API 被第三方調用,如果第三方沒按要求傳參,會不會導致程序崩潰?
舉個例子:
page = data['page']
size = data['size']
這樣的寫法就沒有下面的寫法好:
page = data.get('page', 1)
size = data.get('size', 10)
繼續,項目中依賴的庫是不是及時升級更新了?
積極,及時的升級可以避免跨大版本升級,因為跨大版本升級往往會帶來很多問題。
還有就是在遇到一些安全漏洞時,升級是一個很好的解決辦法。
最后一點,單元測試完善嗎?覆蓋率高嗎?
說實話,程序員喜歡寫代碼,但往往不喜歡寫單元測試,這是很不好的習慣。
有了完善,覆蓋率高的單元測試,才能提高項目整體的健壯性,才能把因為修改代碼帶來的 BUG 的可能性降到最低。
重構
隨着代碼規模越來越大,重構是每一個開發人員都要面對的功課,Martin Fowler 將其定義為:在不改變軟件外部行為的前提下,對其內部結構進行改變,使之更容易理解並便於修改。
重構的收益是明顯的,可以提高代碼質量和性能,並提高未來的開發效率。
但重構的風險也很大,如果沒有理清代碼邏輯,不能做好回歸測試,那么重構勢必會引發很多問題。
這就要求在開發過程中要特別注重代碼質量。除了上文提到的一些規范之外,還要注意是不是濫用了面向對象編程原則,接口之間設計是不是過度耦合等一系列問題。
那么,在開發過程中,有沒有一個指導性原則,可以用來規避這些問題呢?
當然是有的,接着往下看。
高級階段
最近剛讀完一本書,Bob 大叔的《架構整潔之道》,感覺還是不錯的,收獲很多。

全書基本上是在描述軟件設計的一些理論知識。大體分成三個部分:編程范式(結構化編程、面向對象編程和函數式編程),設計原則(主要是 SOLID),以及軟件架構(其中講了很多高屋建翎的內容)。
總體來說,這本書中的內容可以讓你從微觀(代碼層面)和宏觀(架構層面)兩個層面對整個軟件設計有一個全面的了解。
其中 SOLID 就是指面向對象編程和面向對象設計的五個基本原則,在開發過程中適當應用這五個原則,可以使軟件維護和系統擴展都變得更容易。
五個基本原則分別是:
- 單一職責原則(SRP)
- 開放封閉原則(OCP)
- 里氏替換原則(LSP)
- 接口隔離原則(ISP)
- 依賴倒置原則(DIP)
單一職責原則(SRP)
A class should have one, and only one, reason to change. – Robert C Martin
一個軟件系統的最佳結構高度依賴於這個系統的組織的內部結構,因此每個軟件模塊都有且只有一個需要被改變的理由。
這個原則非常容易被誤解,很多程序員會認為是每個模塊只能做一件事,其實不是這樣。
舉個例子:
假如有一個類 T,包含兩個函數,分別是 A() 和 B(),當有需求需要修改 A() 的時候,但卻可能會影響 B() 的功能。
這就不是一個好的設計,說明 A() 和 B() 耦合在一起了。
開放封閉原則(OCP)
Software entities should be open for extension, but closed for modification. – Bertrand Meyer, Object-Oriented Software Construction
如果軟件系統想要更容易被改變,那么其設計就必須允許新增代碼來修改系統行為,而非只能靠修改原來的代碼。
通俗點解釋就是設計的類對擴展是開放的,對修改是封閉的,即可擴展,不可修改。
看下面的代碼示例,可以簡單清晰地解釋這個原則。
void DrawAllShape(ShapePointer list[], int n)
{
int i;
for (i = 0; i < n; i++)
{
struct Shape* s = list[i];
switch (s->itsType)
{
case square:
DrawSquare((struct Square*)s);
break;
case circle:
DrawSquare((struct Circle*)s);
break;
default:
break;
}
}
}
上面這段代碼就沒有遵守 OCP 原則。
假如我們想要增加一個三角形,那么就必須在 switch 下面新增一個 case。這樣就修改了源代碼,違反了 OCP 的封閉原則。
缺點也很明顯,每次新增一種形狀都需要修改源代碼,如果代碼邏輯復雜的話,發生問題的概率是相當高的。
class Shape
{
public:
virtual void Draw() const = 0;
}
class Square: public Shape
{
public:
virtual void Draw() const;
}
class Circle: public Shape
{
public:
virtual void Draw() const;
}
void DrawAllShapes(vector<Shape*>& list)
{
vector<Shape*>::iterator I;
for (i = list.begin(): i != list.end(); i++)
{
(*i)->Draw();
}
}
通過這樣修改,代碼就優雅了很多。這個時候如果需要新增一種類型,只需要增加一個繼承 Shape 的新類就可以了。完全不需要修改源代碼,可以放心擴展。
里氏替換原則(LSP)
Require no more, promise no less.– Jim Weirich
這項原則的意思是如果想用可替換的組件來構建軟件系統,那么這些組件就必須遵守同一個約定,以便讓這些組件可以相互替換。
里氏替換原則可以從兩方面來理解:
第一個是繼承。如果繼承是為了實現代碼重用,也就是為了共享方法,那么共享的父類方法就應該保持不變,不能被子類重新定義。
子類只能通過新添加方法來擴展功能,父類和子類都可以實例化,而子類繼承的方法和父類是一樣的,父類調用方法的地方,子類也可以調用同一個繼承得來的,邏輯和父類一致的方法,這時用子類對象將父類對象替換掉時,當然邏輯一致,相安無事。
第二個是多態,而多態的前提就是子類覆蓋並重新定義父類的方法。
為了符合 LSP,應該將父類定義為抽象類,並定義抽象方法,讓子類重新定義這些方法。當父類是抽象類時,父類就是不能實例化,所以也不存在可實例化的父類對象在程序里,也就不存在子類替換父類實例(根本不存在父類實例了)時邏輯不一致的可能。
舉個例子:
看下面這段代碼:
class A{
public int func1(int a, int b){
return a - b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50=" + a.func1(100, 50));
System.out.println("100-80=" + a.func1(100, 80));
}
}
輸出;
100-50=50
100-80=20
現在,我們新增一個功能:完成兩數相加,然后再與 100 求和,由類 B 來負責。即類 B 需要完成兩個功能:
- 兩數相減
- 兩數相加,然后再加 100
現在代碼變成了這樣:
class B extends A{
public int func1(int a, int b){
return a + b;
}
public int func2(int a, int b){
return func1(a,b) + 100;
}
}
public class Client{
public static void main(String[] args){
B b = new B();
System.out.println("100-50=" + b.func1(100, 50));
System.out.println("100-80=" + b.func1(100, 80));
System.out.println("100+20+100=" + b.func2(100, 20));
}
}
輸出;
100-50=150
100-80=180
100+20+100=220
可以看到,原本正常的減法運算發生了錯誤。原因就是類 B 在給方法起名時重寫了父類的方法,造成所有運行相減功能的代碼全部調用了類 B 重寫后的方法,造成原本運行正常的功能出現了錯誤。
這樣做就違反了 LSP,使程序不夠健壯。更通用的做法是:原來的父類和子類都繼承一個更通俗的基類,原有的繼承關系去掉,采用依賴、聚合,組合等關系代替。
接口隔離原則(ISP)
Clients should not be forced to depend on methods they do not use. –Robert C. Martin
軟件設計師應該在設計中避免不必要的依賴。
ISP 的原則是建立單一接口,不要建立龐大臃腫的接口,盡量細化接口,接口中的方法要盡量少。
也就是說,我們要為各個類建立專用的接口,而不要試圖去建立一個很龐大的接口供所有依賴它的類去調用。
在程序設計中,依賴幾個專用的接口要比依賴一個綜合的接口更靈活。
單一職責與接口隔離的區別:
- 單一職責原則注重的是職責;而接口隔離原則注重對接口依賴的隔離。
- 單一職責原則主要是約束類,其次才是接口和方法,它針對的是程序中的實現和細節; 而接口隔離原則主要約束接口。
舉個例子:
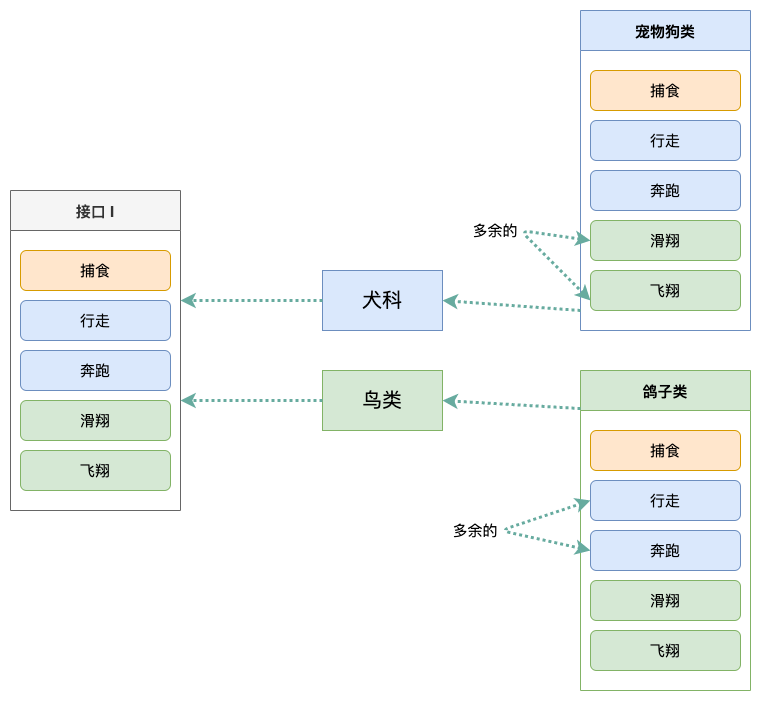
首先解釋一下這個圖的意思:
「犬科」類依賴「接口 I」中的方法:「捕食」,「行走」,「奔跑」; 「鳥類」類依賴「接口 I」中的方法「捕食」,「滑翔」,「飛翔」。
「寵物狗」類與「鴿子」類分別是對「犬科」類與「鳥類」類依賴的實現。
對於具體的類:「寵物狗」與「鴿子」來說,雖然他們都存在用不到的方法,但由於實現了「接口 I」,所以也 必須要實現這些用不到的方法,這顯然是不好的設計。
如果將這個設計修改為符合接口隔離原則的話,就必須對「接口 I」進拆分。
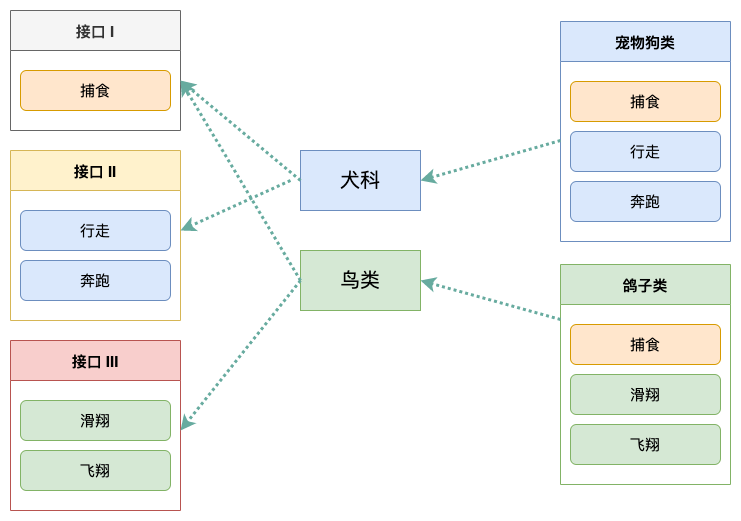
在這里,我們將原有的「接口 I」拆分為三個接口,拆分之后,每個類只需實現自己需要的接口即可。
依賴倒置原則(DIP)
High-level modules should not depend on low-level modules. Both should depend on abstractions. Abstractions should not depend on details. Details should depend on abstractions.– Robert C. Martin
高層策略性的代碼不應該依賴實現底層細節的代碼。
這話聽起來就讓人聽不明白,我來翻譯一下。大概就是說在寫代碼的時候,應該多使用穩定的抽象接口,少依賴多變的具體實現。
舉個例子:
看下面這段代碼:
public class Test {
public void studyJavaCourse() {
System.out.println("張三正在學習 Java 課程");
}
public void studyDesignPatternCourse() {
System.out.println("張三正在學習設計模式課程");
}
}
上層直接調用:
public static void main(String[] args) {
Test test = new Test();
test.studyJavaCourse();
test.studyDesignPatternCourse();
}
這樣寫乍一看並沒有什么問題,功能也實現的好好的,但仔細分析,卻並不簡單。
第一個問題:
如果張三又新學習了一門課程,那么就需要在 Test() 類中增加新的方法。隨着需求增多,Test() 類會變得非常龐大,不好維護。
而且,最理想的情況是,新增代碼並不會影響原有的代碼,這樣才能保證系統的穩定性,降低風險。
第二個問題:
Test() 類中方法實現的功能本質上都是一樣的,但是卻定義了三個不同名字的方法。那么有沒有可能把這三個方法抽象出來,如果可以的話,代碼的可讀性和可維護性都會增加。
第三個問題:
業務層代碼直接調用了底層類的實現細節,造成了嚴重的耦合,要改全改,牽一發而動全身。
基於 DIP 來解決這個問題,勢必就要把底層抽象出來,避免上層直接調用底層。

抽象接口:
public interface ICourse {
void study();
}
然后分別為 JavaCourse 和 DesignPatternCourse 編寫一個類:
public class JavaCourse implements ICourse {
@Override
public void study() {
System.out.println("張三正在學習 Java 課程");
}
}
public class DesignPatternCourse implements ICourse {
@Override
public void study() {
System.out.println("張三正在學習設計模式課程");
}
}
最后修改 Test() 類:
public class Test {
public void study(ICourse course) {
course.study();
}
}
現在,調用方式就變成了這樣:
public static void main(String[] args) {
Test test = new Test();
test.study(new JavaCourse());
test.study(new DesignPatternCourse());
}
通過這樣開發,上面提到的三個問題得到了完美解決。
其實,寫代碼並不難,通過什么設計模式來設計架構才是最難的,也是最重要的。
所以,下次有需求的時候,不要着急寫代碼,先想清楚了再動手也不遲。
這篇文章寫的特別辛苦,主要是后半部分理解起來有些困難。而且有一些原則也確實沒有使用經驗,單靠文字理解還是差點意思,體會不到精髓。
其實,文章中的很多要求我都做不到,總結出來也相當於是對自己的一個激勵。以后對代碼要更加敬畏,而不是為了實現功能草草了事。寫出健壯,優雅的代碼應該是每個程序員的目標,與大家共勉。
如果覺得這篇文章還不錯的,歡迎點贊和轉發,感謝~
推薦閱讀:
參考資料: