面試吹牛之前先打個草稿!
各位面試官好!
我叫 xxx,畢業於 xxx,之前在 xxx 公司待了 1 年多,期間⼀直從事的是 IT 行業,剛開始的時候做的是 Java 開發后來轉崗到大數據方向做大數據開發; 剛轉行到大數據開發的時候開始比較困難的,大數據並不像 Java 那樣⼀套框架基本可以搞定所有的問題,而是不同的業務對於同⼀個問題有多種解決方案。
我叫 xxx,畢業至今就職於 xx 公司,職位是數倉開發。
參加工作以來,我先后參與籌備大數據服務器購買以及從 0 到 1 的搭建,離線數倉項目組,實時數倉項目組。這三個項目都得到了老板們的一致好評,大大增加了業務方需要客戶數據的效率,能更快的做出實時決策。
我對大數據各框架有濃厚的興趣,工作之余經常鑽研技術,例如 flink 的水位線,雙流 join 等,對業務需求分析的比較透徹。
工作三年,我已經連續兩年被評為優秀員工,我覺得這足以說明我技術扎實,對待工作嚴謹,好學,當然也離不開原公司幫助過我的師傅們。
我叫 xxx,畢業於 xxx,自己大學期間學了 C++就喜歡上了編程,然后大學期間利用業余時間學習了 JAVA。大四的時候又接觸到了大數據,又對大數據產生興趣,學校也開了大數據相關的專業,於是就在晚上找各種相關資料,在 B 站上搜一些比較好的大數據視頻,把相關視頻學習鑽研了一遍。20 年畢業的時候,也從事的大數據行業的工作,參與了大數據架構的搭建,以及數倉的建模等相關的工作。又利用業余時間,進行補充知識,不斷的提高自己。至於以后,還是會不斷的學習來提高自己對大數據的開發能力,提高自己的業務水准。
我叫 xxx,畢業於 xxx。之前 2 年多的時間里一直從事大數據開發工作。
剛開始是在平台崗,主要負責數據平台的搭建以及維持整個框架的正常運行,從購買服務器,包括框架版本選型,以及服務器台數定制,這些都是從 0 到 1 搭建的;在平台崗工作了差不多半年時間,由於這段期間表現比較突出,公司想成立數倉組,就讓我負責籌建搭建數倉的工作,我從數倉建模開始逐漸搭建元數據管理,數據質量監控,權限管理,指標分析,之后就一直數倉崗的工作;直到一年前,公司老大決定要做實時這塊,要統計一個大屏的可視化展示,可能覺得我的攻堅能力比較強,第一時間又想到了我,我就把這個活接過來了,我開始組建實時團隊,也比較好的完成了任務。
我離職前主要是做平台的搭建以及各種指標的分析: 實現和離線的都做;
我最近做的⼀個項目是商城平台,我們這個項目主要包含三個方⾯ :
-
數據倉庫的搭建; -
實時計算系統; -
離線計算系統;
剛開始主要是負責做平台相關的工作,后來做了⼀段時間的實時指標,離職前主要負責離線 指標這塊的內容以及⼀些維護優化的⼯作;
公司大數據部門這邊剛開始有 5 個人,隨后因為業務的增加又招了⼀些人離職前有 8 個人;
一、簡要介紹項目
接下來我先介紹⼀下這個項目:
項目是⼀個高度定制化的商城平台,最近主要做的是數倉和離線指標計算這⼀塊;
數倉初期
數倉搭建初期,由於公司數據量少,經驗不足,數倉沒有層級概念,過來的數據直接進行解析,每次計算一個指標的時候,都需要進行 ETL 操作,每次都需要進行 join,造成了大量的重復操作,效率十分低下,浪費大量人力。
數倉后期
數倉在搭建一段時間后,重復的計算操作困惱了我很久,后來我參考了阿里的離線數倉架構,我們對數倉進行了重新的架構搭建,對數倉進行了分層規划。
主要分為:
-
ods 層 : 數據緩沖層; -
dwd 層 : 基礎數據層; -
dws 層 : 數據匯總層; -
app 層 : 應用層;
分四層的原因主要是為了隔離數據然后還能復用上⼀層計算出來的數據,另一方面也是為了數據的備份;
二、介紹熟悉的框架
數據采集我們主要是采集業務系統的數據及日志數據兩部分,業務系統數據存儲在 Mysql 中,使用 Sqoop 將數據導入大數據平台。
Sqoop:
Sqoop 是在 Hadoop 生態體系和 RDBMS 體系之間傳送數據的一種工具。它的工作機制是將導入或導出命令翻譯成 mapreduce 程序來實現。在翻譯出的 mapreduce 中主要是對 inputformat 和 outputformat 進行定制。
我們在使用 Sqoop 導入導出時出現了 Null 的存儲一致性問題,Hive 中的 Null 在底層是以“\N”來存儲,而 MySQL 中的 Null 在底層就是 Null。為了保證數據兩端的一致性,在導出數據時采用--input-null-string 和--input-null-non-string 兩個參數。導入數據時采用--null-string 和--null-non-string。
Flume:
對於日志采集我們當時選用的是 Flume,采集日志框架也有很多,之所以選擇 Flume 主要是因為它采集數據的效果比較好,其次是對於 HDFS 和 Kafka ⽀持的也比較好;
Flume 主要包含三大組件:
Source、Channel、Sink
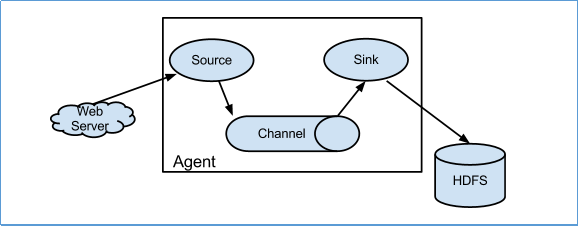
-
Flume 在 1.7 以后提供了⼀個 TailDirSource 用來⽀持多目錄和斷點續傳功能;
-
斷點續傳主要保證在服務器掛掉的情況下,再次啟動服務數據不會丟失的問題;其原理就是在底層維護了⼀個 offset 偏移量(也就是每次讀取文件的偏移量)Flume 會通過這個偏移量來找到上次文件讀取的位置從⽽實現了斷點續傳的功能;
-
在 1.6 以前這個實現斷點續傳是需要手工維護這個偏移量的會比較麻煩;
-
-
Channel 的種類比較多主要有:
-
MemoryChannel : 數據放在內存中,會在 Flume 宕機的時候丟失數據,可以用在對數據安全性要求沒有那么高的場景中比如日志數據;
-
FileChannel : 不會丟失數據,因為數據是放在磁盤上邊的⽽且⽀持多目錄配置可以提高寫入的性能,同時因為有落盤的操作所以效率比較低,適合用在對數據安全性要求比較高的場景比如⾦融類的數據;
-
KafkaChannel : 主要是為了對接 Kafka,使用這個可以節省 Sink 組件也可以提升效率的,我們項目中使用的就是這個 Channel,因為下⼀層是使用 Kafka 來傳遞消息的;
-
-
在 Flume 這⼀層我們還做了⼀個攔截器,主要是對收集到的日志做了⼀層過濾,因為有的日志沒有 id 或一些關鍵字段,這些數據對我們數據分析來說是沒有任何用的,所以在攔截器里邊對這些數據進行了簡單清洗;
-
還做了⼀個分類型的攔截器,在這個攔截器里邊我們對數據進行類型的區分,主要是做了⼀個打標簽的功能對不同的日志數據打上不同的標簽,然后通過后續的選擇器 Multiplexing 將不同標簽的數據放到不同的 topic 里邊,⽅便下游對數據進行處理;
Kafka:
下游數據傳輸使用的是 Kafka 作為消息隊列來傳輸消息,使用 Kafka 的主要原因是因為 Kafka 的高吞吐量以及可以對數據進行分類也就是不同的 topic,⽅便下⼀層的使用,整體的架構是采用 Lamda 架構設計的,實時和離線都會從 Kafka 中獲取數據來進行處理,⽽且還有其他的業務線也是從 Kafka 中獲取數據的,這樣做以后可以有效的提高數據的復用減少數據的冗余,離線這塊我們是在 Kafka 之后⼜做了⼀層 Flume 來作為消費者處理 Kafka 中的數據的, 將消費到的數據直接放入 HDFS 中,實時這塊使用的是 SparkStreaming 來消費 Kafka 中的數據;
為什么選擇 Kafka 作為消息隊列來處理數據
當時在做技術選型的時候我們也是做了大量的調研,因為消息隊列的產品有很多比如 : ReactMQ Kafka 等;
我們當時調研考慮的主要指標就是吞吐量這⼀塊,因為大數據流式處理對數據的吞吐量要求是⾮常高的,在這⼀塊 ReactMQ 是比較厲害的,吞吐量可以達到 1 萬多每秒;通過后來的調研以后發現 Kafka 的吞吐量比 ReactMQ 更高,如果使用恰當的話吞吐量甚⾄可以達到 10 萬+每秒;
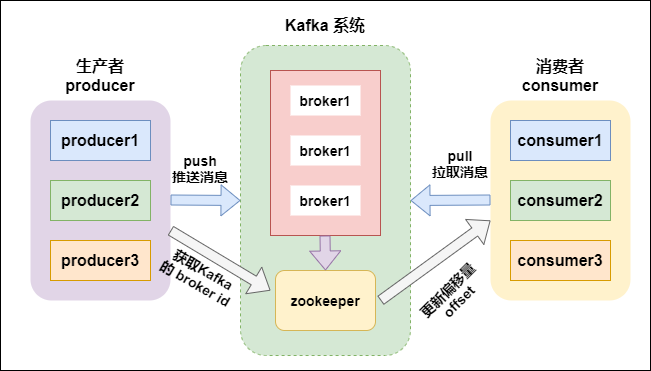
kafka 支持消息持久化,消費端是主動拉取數據,消費狀態和訂閱關系由客戶端負責維護,消息消費完后,不會立即刪除,會保留歷史消息。因此支持多訂閱時,消息只會存儲一份就可以。
-
broker:kafka 集群中包含一個或者多個服務實例(節點),這種服務實例被稱為 broker(一個 broker 就是一個節點/一個服務器); -
topic:每條發布到 kafka 集群的消息都屬於某個類別,這個類別就叫做 topic; -
partition:partition 是一個物理上的概念,每個 topic 包含一個或者多個 partition; -
producer:消息的生產者,負責發布消息到 kafka 的 broker 中; -
consumer:消息的消費者,向 kafka 的 broker 中讀取消息的客戶端; -
consumer group:消費者組,每一個 consumer 屬於一個特定的 consumer group(可以為每個 consumer 指定 groupName);
Kafka 為什么可以這么快?
-
首先從生產者說起,生產者發送數據是按照批進行發送的並不是⼀條⼀條發送的,從這里就已經可以保證 Kafka ⼀個比較高的吞吐量了;
-
生產者來⼀條消息以后會進入⼀個攔截器,在攔截器里邊可以對數據進行⼀個整體的 修改操作⼀般這里是不做特殊的處理的,數據從攔截器出來以后就會進入到序列化器, 在序列化器里邊將數據轉換成⼀個⼆進制流的形式放入 Broker 里邊;
-
經過序列化器以后數據就會⾛到分區器,Kafka 使用的分區器是⼀個叫做 Hash 的分區器,Hasf 分區器我們可以對其進行重寫;
-
生產者將消息發送到 Broker 的過程可能會出現消息的重復或者丟失的情況,這個主要是靠 ACK 的配置來決定的,ack 的響應有三個狀態值 0,1,-1
-
0:生產者只負責發送數據,不關心數據是否丟失,丟失的數據,需要再次發送 -
1:partition 的 leader 收到數據,不管 follow 是否同步完數據,響應的狀態碼為 1 -
-1:所有的從節點都收到數據,響應的狀態碼為-1
-
-
這里還有⼀個很重要的概念就是 ISR 副本同步隊列,在這個隊列里邊包含了 Leader 和 Follower,主要解決的問題就是 Leader 掛了以后誰來做 Leader 的問題:
-
選舉機制就是通過這個 ISR 來進行的,默認是有⼀個排序排序的⼀般都是選取第⼀ 個,因為每⼀批的數據只有最快的那個才能達到第⼀個接收消息,其中 ISR 隊列以及 Leader 的選舉是由 Controller 來控制的,Zookeeper 來進行存儲,關於 Controller 在 Kafka 中也是⾮常重要的 Controller 也有⼀個專門的選舉機制,它是相當於是用 Zookeeper 來做了⼀個分布式鎖,具體原理就是利用 Zookeeper 生成的臨時節點生成⼀個分布式鎖,誰先搶占到誰就是 Leader;
-
三、介紹項目采用的架構
上面也說到,我們整體的架構是采用 Lamda 架構設計的。
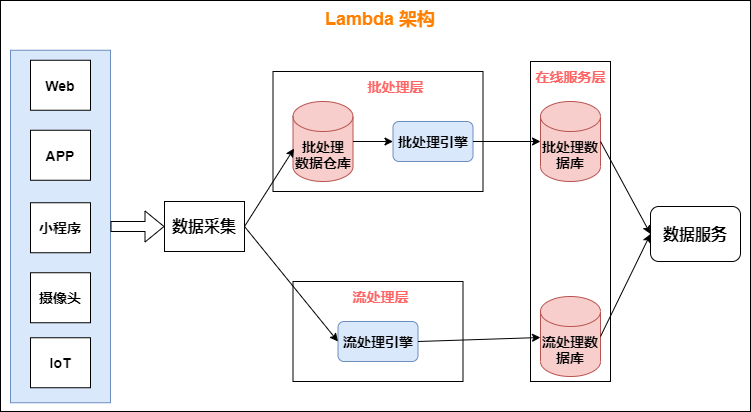
數據從底層的數據源開始,經過 Kafka、Flume 等數據組件進行收集,然后分成兩條線進行計算:
-
一條線是進入流式計算平台(例如 Storm、Flink 或者 SparkStreaming),去計算實時的一些指標;
-
另一條線進入批量數據處理離線計算平台(例如 Mapreduce、Hive,Spark SQL),去計算 T+1 的相關業務指標,這些指標需要隔日才能看見。
在 Lambda 架構中,每層都有自己所肩負的任務。
1. 批處理層存儲管理主數據集(不可變的數據集)和預先批處理計算好的視圖:
批處理層使用可處理大量數據的分布式處理系統預先計算結果。它通過處理所有的已有歷史數據來實現數據的准確性。這意味着它是基於完整的數據集來重新計算的,能夠修復任何錯誤,然后更新現有的數據視圖。輸出通常存儲在只讀數據庫中,更新則完全取代現有的預先計算好的視圖。
2. 流處理層會實時處理新來的大數據:
流處理層通過提供最新數據的實時視圖來最小化延遲。流處理層所生成的數據視圖可能不如批處理層最終生成的視圖那樣准確或完整,但它們幾乎在收到數據后立即可用。而當同樣的數據在批處理層處理完成后,在速度層的數據就可以被替代掉了。
四、詳細介紹數倉搭建
1. 數據各層作用
-
ODS(原始數據層):日志數據和業務進入數倉后,首先放入該層,建立分區表,防止后續的全表掃描,使用 ORC 列式存儲,同時對數據進行壓縮,壓縮格式采用 LZO,以減少存儲空間。
-
日志:商品列表、商品點擊、商品詳情;廣告;故障;后台活躍、通知;啟動表;點贊、評論、收藏等。 -
業務數據:訂單表、用戶表、支付流水表、訂單詳情表、商品表、三級、二級、一級,物流信息(根據產品的來源,有兩種,香港特快直送,閃電保稅倉。一個從香港發貨,一個從內地的保稅倉發貨)等。
-
-
DWD(明細數據層):對 ODS 層數據清洗(去除空值,臟數據,超過極限范圍的數據)。
-
用戶行為數據:自定義 UDF(extends UDF 實現 evaluate 方法),解析公共字段;自定義 UDTF(extends Genertic UDTF->實現三個方法 init(指定返回值的名稱和類型)、process(處理字段一進多出)、close 方法),自定義方法的好處在於更加靈活以及方便調試 bug。在自定義函數解析字段時,我們一般建立中間表,存放解析后的表,最后通過 get_json_object 獲的我們所需要的字段,建立最終所需表。 -
業務數據:維度退化+數據清洗(where group by) -
脫敏:利用 spark 對手機號、身份證號、銀行賬號等敏感信息進行脫敏處理。 -
ETL:通過 HQL、Kettle 對數據進行清洗。清洗標准是核心字段滿足業務邏輯要求,去除重復、空值、超過時限等數據。一般清洗率為萬分之一,如果大於這個數,需要和前端、javaEE 人員進行溝通。 -
維度退化:商品表+三級分類、二級分類、一級分類=>商品表,省份+地區表=>省份表,其中我們用到的維度建模理論是星型模型,事實表周圍 1 級維度。 -
LZO 壓縮:減少存儲空間 -
列式存儲:ORC,增加壓縮比 -
分區表:防止后續的全表掃描
-
重點重點:DWD 層我們使用的是標准的數倉建模理論
數倉建模怎么建?
我們按照數倉工具箱中的維度建模四步走來建的:
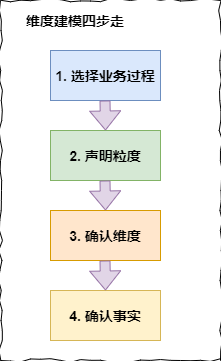
-
選擇業務過程:由於我們公司當時數據量較小,我把 javeEE 涉及的業務表全部導入了,這些表包括實體表,維度表,事務型快照事實表,周期性快照事實表、累積型事實表。過來之后,將這些表作為矩陣的一個列。
-
聲明粒度:粒度一般有:一行信息代表一次、按天、按周、按月等,參考了很多架構之后,我們考慮到后期想要分析更多的指標,只能選擇最小的粒度,一行信息代表一次消費。
-
確認維度:采用標准數倉建模的思維,爭取事實表周圍都是 1 級維度。我們關系的就是什么時間、什么地點、什么人、具體什么活動、優惠券等主題的維度,同時將跟用戶、商品相關的表進行維度退化,盡量把他們降成一級維度。
-
確認事實:這里我們確定的不是事實表,而是事實表的度量值,我們用到的度量值有訂單的個數、訂單的金額、下單次數等可以累加的字段。
-
DWS、DWT(每天的用戶行為寬表):每天的用戶行為寬表、商品寬表,相當於一個周期型快照事實表。每天記錄用戶做了那些事情,商品被下單了多少。
-
DWS 寬表的字段我們是站在維度的角度來取的,比如站在用戶的維度去看待周圍的對應事實表,取事實表對應的度量值,取出訂單的次數、訂單的金額、支付的次數、支付的金額、加入購物車的次數、加入購物車的金額、評論的次數、點贊的次數、收藏的次數等等,將他們組合成為 DWS 層每天發生的事情。
-
后期我們為了統計的指標,加了一個 DWT 層,DWT 層還是站在維度的角度去看待對應事實表,但是它和 DWS 有略微的區別,現在關注的是這個用戶什么時間開始創建的,最后一次登錄是什么時候,累計登錄多少次,最近 30 天登錄多少次等信息。
-
-
DWS、DWT 統稱為服務層:都是為后面的 ADS 層提供服務的,如果統計的是累積性指標,從 DWT 層拿取數據;如果統計的當天的指標,直接從 DWS 層取對應的數據。 DWS 層最大的行為寬表是用戶行為寬表,其字段有互動日期、用戶 id、用戶昵稱、注冊日期、注冊來源、細分渠道、注冊省份、評論次數、打賞次數、添加收藏、取消收藏、關注商品、取消關注的商品、關注人、取消關注的人、點不值次數、點值次數、點贊次數、分享次數、爆料數、加購物車數、取消購物車次數等待。DWT 也是用戶行為寬表,其字段有互動日期、用戶 id、用戶昵稱、注冊日期、注冊來源、細分渠道、注冊省份、最后一次登錄日期、累計登錄日期、最近 30 天登錄日期等等。
-
ADS 層:分析了 100 多個指標:包括 日活、月活、周活、留存、留存率、新增(日、周、年)、轉化率、流失、回流、七天內連續 3 天登錄(點贊、收藏、評價、購買、加購、下單、活動)、連續 3 周(月)登錄、GMV、復購率、復購率排行、點贊、評論、收藏、領優惠價人數、使用優惠價、沉默、值不值得買、退款人數、退款率 topN 熱門商品、留轉 G 復活等。
五、數倉業務詳解
我們數據倉庫是基於維度建模,主要使用星型模型。
-
維度表:一般是對事實的描述信息。每一張維表對應現實世界中的一個對象或者概念。例如:用戶、商品、日期、地區等。
維表的特征:
-
維表的范圍很寬(具有多個屬性、列比較多) -
跟事實表相比,行數相對較小:通常< 10 萬條 -
內容相對固定:編碼表
-
事實表:分為 事務型事實表(每個事務或事件為單位,一旦產生就固定)和 周期型事實表(不會保留所有數據,只保留固定時間間隔的數據,比如每天、每月銷售額)以及 累積性事實表(累積型快照事實表用於跟蹤業務事實的變化,比如訂單的狀態變化情況)。如果需要后面狀態還會改變的就是周期型事實表,一旦確定了,就是事務性事實表。
事實表中的每行數據代表一個業務事件(下單、支付、退款、評價等)。“事實”這個術語表示的是業務事件的度量值(可統計次數、個數、金額等),例如,訂單事件中的下單金額。
每一個事實表的行包括:具有可加性的數值型的度量值、與維表相連接的外鍵、通常具有兩個和兩個以上的外鍵、外鍵之間表示維表之間多對多的關系。
事實表的特征:
-
非常的大 -
內容相對的窄:列數較少 -
經常發生變化,每天會新增加很多。
對於不同的表我們使用不同的同步策略:
同步策略包括全量表,增量表,新增及變化,拉鏈表
日志表:(商品點擊,商品詳情,商品詳情頁表,廣告表,錯誤日志表,消息通知表等)
-
商品點擊:用戶的基本信息字段,動作,商品 id,種類等。 -
商品詳情頁:入口,上一頁面來源,商品 id,加載時間,種類。 -
廣告表:入口,內容,行為,展示風格等。 -
錯誤日志:錯誤詳情 -
消息通知表:通知類型,展示時間,通知內容等
這些記錄性質的,都使用每日增量。
業務表:(購物車,評分,評論,訂單表,訂單詳情表,退貨表,用戶表,商家表,商品分類表(一級,二級,三級),支付流水,物流信息等)
-
購物車詳情:用戶 id ,商品 id,商品價格,商家 id ,商品型號,商品分類等 同步策略:這屬於周期型事實表,因為它可能會隨時改變,所以得用每日新增及變化。
-
評分表:評分時間,評分用戶,評分商品 ,分數等。
同步策略:這是事務性事實表,一般可以用每日增量就可以了,因為評論只能增加,不能修改。
-
評論表:評論時間,評論用戶,評論商品,評論內容。
同步策略:這個跟評分差不多,用每日新增。
-
訂單表:訂單狀態,訂單編號,訂單金額,支付方式,支付流水,創建時間等
同步策略:因為訂單的狀態會隨時發生改變,比如下單,支付,商家發貨,用戶收到貨,確認收貨,等這一系列的狀態會比較長,然后訂單也比較多。所以,要做歷史快照信息的話,最好使用拉鏈表。
-
訂單詳情表:訂單編號,訂單號,用戶 id,商品名稱,商品價格,商品數量,創建時間等。
-
用戶表:用戶 id,性別,等級,vip,注冊時間等等。
同步策略:因為表不是很大,每次做全量表。
-
商家表:商家 id,商家地址,商家規模等級,商家注冊時間,商家分類信息。
同步策略:每次做每日全量。
總結:
-
實體表,不大,就可以做每日全量。 -
對於 維度表,比如說商品分類,這種不是很大,也可以做每日全量,有一些不太會發生改變的維度,就可以固定保存一份值,比如說:地區,種族等。 -
像 事務型事實表,比如說交易流水,操作日志,出庫信息,這種每日比較大,且需要歷史數據的,就根據時間做每日新增,可以利用分區表,每日做分區存儲。 -
像 周期型事實表的同步策略,比如訂單表,有周期性變化,需要反應不同時間點的狀態的,就需要做拉鏈表。記錄每條信息的生命周期,一旦一條記錄的生命周期結束,就開始下一條新的記錄。並把當前的日期放生效開始日期。
六、離線指標
-
日活/周活/月活統計:(每日的根據 key 聚合,求 key 的總數) -
用戶新增:每日新增(每日活躍設備 left join 每日新增表,如果 join 后,每日新增表的設備 id 為空,就是新增) -
用戶留存率:(一周留存)10 日新增設備明細 join 11 日活躍設備明細表,就是 10 日留存的。注意每日留存,一周留存 -
沉默用戶占比:只在當天啟動過,且啟動時間在一周前 -
本周回流用戶數 -
用戶在線時長統計 -
區域用戶訂單數(根據區域分區,然后求訂單數) -
區域訂單總額(根據區域分區,求訂單總額。) -
區域用戶訂單訪問轉化率(以區域分組成單數/訪問數) -
區域客單價(訂單總額度/下訂單總人數) -
總退貨率(退貨商品數/購買商品總數) -
各區域退貨率(根據區域分組) -
GMV(成交總額) -
物流平均時長(用戶收貨時間-物流發貨時間)求平均 -
每周銷量前十品類 -
每周各品類熱門商品銷量前三 -
各區域熱門商品銷量前五(有利於后期鋪貨) -
各區域漏斗分析 -
商品評價人數占比(該商品的總評價人數/該商品的總購買人數) -
各品牌商家總銷售額。 -
各品類中銷量前三的品牌 -
購物車各品類占比(說明大家想買的東西,便於后期鋪貨。) -
每周廣告點擊率。看到這個廣告的人數/點擊這個廣告商品的人數) -
vip 用戶每日,周訂單總額 -
每日限時特賣產品占比(限時特賣產品總額/每日交易總額) -
香港特快直送渠道總交易額占比(香港特快直送渠道總額/每日商品交易總額) -
香港特快直送渠道總交易單占比 -
國內保稅倉渠道總交易額占比(國內保稅倉總額/每日商品交易總額) -
國內保稅倉渠道總交易單占比 -
各區域頁面平均加載時長(考察各地區網絡問題。后台訪問是否穩定) -
頁面單跳轉化率統計 -
獲取點擊下單和支付排名前 10 的品類 -
各類產品季度復購率
七、實時指標
-
每日日活實時統計 -
每日訂單量實時統計 -
一小時內日活實時統計 -
一小時內訂單數實時統計 -
一小時內交易額實時統計 -
一小時內廣告點擊實時統計 -
一小時內區域訂單數統計 -
一小時內區域訂單額統計 -
一小時內各品類銷售 top3 商品統計 -
用戶購買明細靈活分析(根據區域,性別,品類等)
八、寫出分析最難的兩個指標
面試官說現場手寫你分析過最難的兩個指標:
最好不要選擇最難的,除非你能完全寫出來,並且還得讓面試官理解你做的指標的含義,下面選擇容易理解但不算簡單的指標:
1. 活躍用戶指標
我們經常會算活躍用戶,活躍用戶是指至少連續 5 天登錄賬戶的用戶,返回的結果表按照 id 排序。
+----+-----------+
| 7 | Jonathan |
+----+-----------+
思路:
-
去重:由於每個人可能一天可能不止登陸一次,需要去重 -
排序:對每個 ID 的登錄日期排序 -
差值:計算登錄日期與排序之間的差值,找到連續登陸的記錄 -
連續登錄天數計算:select id, count(*) group by id, 差值(偽代碼) -
取出登錄 5 天以上的記錄 -
通過表合並,取出 id 對應用戶名
參考代碼:
SELECT DISTINCT b.id, name
FROM
(SELECT id, login_date,
DATE_SUB(login_date, ROW_NUMBER() OVER(PARTITION BY id ORDER BY login_date)) AS diff
FROM(SELECT DISTINCT id, login_date FROM Logins) a) b
INNER JOIN Accounts ac
ON b.id = ac.id
GROUP BY b.id, diff
HAVING COUNT(b.id) >= 5
注意點:
-
DATE_SUB 的應用:DATE_SUB (DATE, X),注意,X 為正數表示當前日期的前 X 天; -
如何找連續日期:通過排序與登錄日期之間的差值,因為排序連續,因此若登錄日期連續,則差值一致; -
GROUP BY 和 HAVING 的應用:通過 id 和差值的 GROUP BY,用 COUNT 找到連續天數大於 5 天的 id,注意 COUNT 不是一定要出現在 SELECT 后,可以直接用在 HAVING 中
2. 用戶留存率
首先用戶留存率一般是面向新增用戶的概念,是指某一天注冊后的幾天還是否活躍,是以每天為單位進行計算的。
一般收到的需求都是一個時間段內的新增用戶的幾天留存
select '日期', '注冊用戶數', '次日留存率', '2日留存率', '3日留存率', dim_date
,total_cnt
,concat_ws('% | ', cast(round(dif_1cnt*100/total_cnt, 2) as string), cast(dif_1cnt as string))
,concat_ws('% | ', cast(round(dif_2cnt*100/total_cnt, 2) as string), cast(dif_2cnt as string))
,concat_ws('% | ', cast(round(dif_3cnt*100/total_cnt, 2) as string), cast(dif_3cnt as string))
,concat_ws('% | ', cast(round(dif_4cnt*100/total_cnt, 2) as string), cast(dif_4cnt as string))
from
(
select p1.state dim_date
,p1.device_os
,count(distinct p1.user_id) total_cnt
,count(distinct if(datediff(p3.state,p1.state) = 1, p1.user_id, null)) dif_1cnt
,count(distinct if(datediff(p3.state,p1.state) = 2, p1.user_id, null)) dif_2cnt
,count(distinct if(datediff(p3.state,p1.state) = 3, p1.user_id, null)) dif_3cnt
,count(distinct if(datediff(p3.state,p1.state) = 4, p1.user_id, null)) dif_4cnt
from
(
select
from_unixtime(unix_timestamp(cast(partition_date as string), 'yyyyMMdd'), 'yyyy-MM-dd') state,
user_id
from user_active_day
where partition_date between date1 and date2
and user_is_new = 1
group by 1,2
)p1 --日新增用戶名單(register_date,user_id)
left outer join
(
select
from_unixtime(unix_timestamp(cast(partition_date as string), 'yyyyMMdd'), 'yyyy-MM-dd') state,
user_id
from active_users
where partition_date between date1 and date2
group by 1,2
)p3 --期間活躍用戶(active_date,user_id)
on (p3.user_id = p1.user_id)
group by 1,2
) p4;
九、面試官問
自己說完項目之后面試官就開始發問了,注意接招:
1. 如何保證你寫的 sql 正確性?
我一般是造一些特定的測試數據進行測試。
另外離線數據和實時數據分析的結果比較。
2. 測試數據哪來的?
一部分自己寫 Java 程序自己造,一部分從生產環境上取一部分。
3. 測試環境什么樣?
測試環境的配置是生產的一半
4. 測試之后如何上線?
上線的時候,將腳本打包,提交 git。先發郵件抄送經理和總監,運維。通過之后跟運維一 起上線。
5. 你做的項目工作流程是什么?
-
先與產品討論,看報表的各個數據從哪些埋點中取 -
將業務邏輯過程設計好,與產品確定后開始開發 -
開發出報表 SQL 腳本,並且跑幾天的歷史數據,觀察結果 -
將報表放入調度任務中,第二天給產品看結果。 -
周期性將表結果導出或是導入后台數據庫,生成可視化報表
6. Hadoop 宕機?
-
如果 MR 造成系統宕機。此時要控制 Yarn 同時運行的任務數,和每個任務申請的最大內存。
調整參數:
yarn.scheduler.maximum-allocation-mb(單個任務可申請的最多物理內存量,默認是 8192MB) -
如果寫入文件過量造成 NameNode 宕機。那么調高 Kafka 的存儲大小,控制從 Kafka 到 HDFS 的寫入速度。高峰期的時候用 Kafka 進行緩存,高峰期過去數據同步會自動跟上。
7. 說下 Spark 數據傾斜及解決?
數據傾斜以為着某一個或者某幾個 partition 的數據特別大,導致這幾個 partition 上的計算需要耗費相當長的時間。
在 spark 中同一個應用程序划分成多個 stage,這些 stage 之間是串行執行的,而 一個 stage 里面的多個 task 是可以並行執行,task 數目由 partition 數目決定,如 果一個 partition 的數目特別大,那么導致這個 task 執行時間很長,導致接下來 的 stage 無法執行,從而導致整個 job 執行變慢。
避免數據傾斜,一般是要選用合適的 key,或者自己定義相關的 partitioner,通 過加鹽或者哈希值來拆分這些 key,從而將這些數據分散到不同的 partition 去執行。
如下算子會導致 shuffle 操作,是導致數據傾斜可能發生的關鍵點所在:
groupByKey;reduceByKey;aggregaByKey;join;cogroup
8. 為什么 Kafka 不支持讀寫分離?
在 Kafka 中,生產者寫入消息、消費者讀取消息的操作都是與 leader 副本進行交互的,從 而實現的是一種主寫主讀的生產消費模型。 Kafka 並不支持主寫從讀,因為主寫從讀有 2 個很明顯的缺點:
-
數據一致性問題:數據從主節點轉到從節點必然會有一個延時的時間窗口,這個時間 窗口會導致主從節點之間的數據不一致。某一時刻,在主節點和從節點中 A 數據的值都為 X, 之后將主節點中 A 的值修改為 Y,那么在這個變更通知到從節點之前,應用讀取從節點中的 A 數據的值並不為最新的 Y,由此便產生了數據不一致的問題。
-
延時問題:類似 Redis 這種組件,數據從寫入主節點到同步至從節點中的過程需要經歷 網絡 → 主節點內存 → 網絡 → 從節點內存 這幾個階段,整個過程會耗費一定的時間。而在 Kafka 中,主從同步會比 Redis 更加耗時,它需要經歷 網絡 → 主節點內存 → 主節點磁盤 → 網絡 → 從節 點內存 → 從節點磁盤 這幾個階段。對延時敏感的應用而言,主寫從讀的功能並不太適用。
而 kafka 的主寫主讀的優點就很多了:
-
可以簡化代碼的實現邏輯,減少出錯的可能; -
將負載粒度細化均攤,與主寫從讀相比,不僅負載效能更好,而且對用戶可控; -
沒有延時的影響; -
在副本穩定的情況下,不會出現數據不一致的情況。
十、最后的面試小技巧
最后給大家說一點面試小技巧:
一般來說,面試你的人都不是一個很好對付的人。別看他彬彬有禮,看上去笑眯眯的,很和氣的樣子。但沒准兒一肚子壞水。
有些人待人特別客氣,說話還稍稍有點結巴的,更容易讓人上當。
所以,牢記一點,面試的時候保持高度警覺,對方不經意問出來的問題,很可能是他最想知道的。
-
首先說話語速不要太快,有些人介紹自己時滔滔不絕,說話特快。其實這里面有個信息傳遞的問題,跟別人談事情,語速太快,往往容易說錯,對方接受起來也有問題。所以中等語速就可以了。
-
問到期望薪金的時候,最好的回答是不回答,留到下一次面試再談。或者可以反問,公司對於這個崗位定的薪金標准是多少。
-
不要緊張,表現得自然些,要有禮貌,別忘記和主考人招呼,說句"早上好"等。
-
舉止要大方,不可閃縮,要保持自信。待主考人邀請你才可禮貌地坐下,不要太隨便或左顧右盼;切忌裝出懶洋洋和滿不在乎的樣子。
-
微笑可以減輕你內心的不安,更可以令面試的氣氛變得融洽愉快。
-
讓主考人知道你珍惜這次面試的機會。當主考人說話時,要眼望對方,並留心傾聽。
-
讓主考人先打開話匣子。答問題要直接了當,無須太繁復,也不要單說"是"或"不是";否則,主考人會覺得你欠缺誠意。深入的談話內容有助主考人對你作出確切的評估。
-
假如有不太明白主考人的問題,應該禮貌地請他重復。不懂得回答的問題,不妨坦白承認。含糊其辭或亂吹牛會導致面試的失敗。
-
不要打斷主考人的說話,被要求就相同的問題重復作答也不能表示不耐煩,更切忌與主考人爭辯。
-
主考人可能問你一些與面試或者申請的職位完全無關的問題,例如時人時事,目的在進一步了解你的思想及見識。
-
緊記在適當時機帶出自已的優點和特長。但切勿顯得過份自信或浮誇。
-
准備一些與該機構和申請的工作有關的問題在面試結束之前提出。這樣能表現伙的積極,亦可給主考人留下良好印象。
-
最后,問清楚多久才知道面試結果。不要忘記向主考人道謝及說聲"再見"才離去。