最近看了好多潛類別軌跡latent class trajectory models的文章,發現這個方法和我之前常用的橫斷面數據的潛類別和潛剖面分析完全不是一個東西,做縱向軌跡的正宗流派還是這個方法,當然了這個方法和潛增長和增長曲線模型在做法並沒有實際區別,都是用的hlme這個函數。但是文獻中的叫法和花樣就比較多了。
像本文寫的latent class trajectory models,之前寫的潛類別增長模型LCGA和增長曲線模型GMM都是潛類別線性混合模型latent class linear mixed models (LCLMM)的分支。
The major difference between LCGA and GMM is that LCGA does not allow within-class variation whereas GMM does allow within-class variation
像這一類的模型都是用hlme這個函數跑,這篇文章也可以看作是作為之前的潛增長和增長曲線文章的一個實際應用的延續。
應用背景
很多的同學關心某個變量的縱向發展軌跡,並且還感興趣不同軌跡對某個結局的影響如何。如果你的研究也涉及到這樣的問題,你就可以考慮用潛類別軌跡模型了,參考文獻也甩給大家,大家感興趣可以去瞅瞅下面這個文章:
Mirza, S. S., Wolters, F. J., Swanson, S. A., Koudstaal, P. J., Hofman, A., Tiemeier, H., & Ikram, M. A. (2016). 10-year trajectories of depressive symptoms and risk of dementia: a population-based study. The Lancet Psychiatry, 3(7), 628-635.
文章作者通過潛類別軌跡模型將人群抑郁症狀發展軌跡分成了5類,最終發現只有特定類軌跡才和隨后的痴呆有關系,這對痴呆的干預和抑郁痴呆的關系的認識都是有重要意義的。
今天我就仿照這篇文章給大家寫寫如何做潛類別軌跡模型。
潛類別軌跡的報告內容
做之前我們還是看看這篇文獻中是如何介紹這個方法的。
We used latent class trajectory models to identify trajectories of depressive symptoms over time. This is a specialised form of finite mixture modelling, and is designed to identify latent classes of individuals following similar progressions of a determinant over time or with age.
可以看到這個方法在重要作用是識別那些隨着時間或者年齡擁有相似症狀和疾病進程的人群類別。比如做抑郁的潛類別軌跡就是要識別出人群中可能的抑郁進程亞組。文章中也說明了這個模型就是一個特殊的混合模型specialised form of finite mixture modelling。
在擬合症狀隨着時間或者年齡變化的時候,我們允許或者說我們需要去考慮症狀和時間的曲線關系的,就是說不能簡單第認為某個症狀的縱向變化一定是線性的,意思就是我們要考慮時間變量的高次項,一般來講二次就夠了。作者的論文中也是加了時間的二次項的。然后根據BIC確定最優類別數,同時確保后驗概率大於0.7,類別人數大於0.02.
最終作者出圖如下:
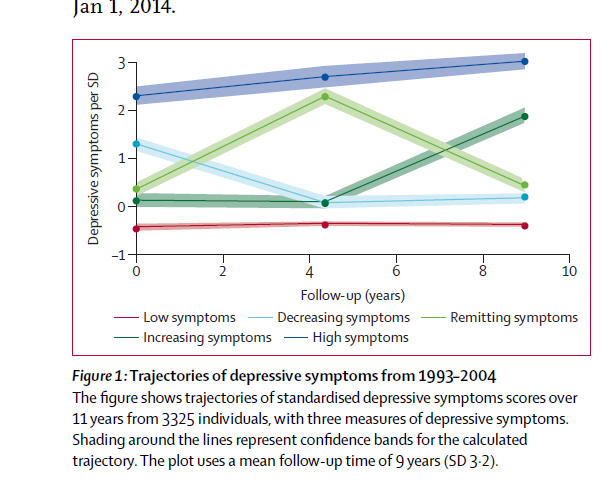
作者根據這個軌跡走勢,還給每個類別進行了命名,打上標簽,包括Low symptoms,Decreasing symptoms,Remitting symptoms,Increasing symptoms, High symptoms,然后將軌跡標簽作為預測變量進行了后續的生存分析。
對於軌跡部分結果的報告,因為這個文章軌跡只是一部分而並非主要目的,所以報告很少,只有每一個軌跡的人群數量和占比。
接下來給大家分享如何做這么一個潛類別軌跡。
潛類別軌跡的做法
潛類別軌跡有專門的R包可以做,感興趣的同學可以去看這篇文章:
Lennon H, Kelly S, Sperrin M, et al Framework to construct and interpret latent class trajectory modelling BMJ Open 2018;8:e020683. doi: 10.1136/bmjopen-2017-020683
上面這篇文章給出了潛類別軌跡模型的做法框架,共8步:

本文的絕大部分步驟也都是參考的上面的文章。
現在我手上的數據長這樣:
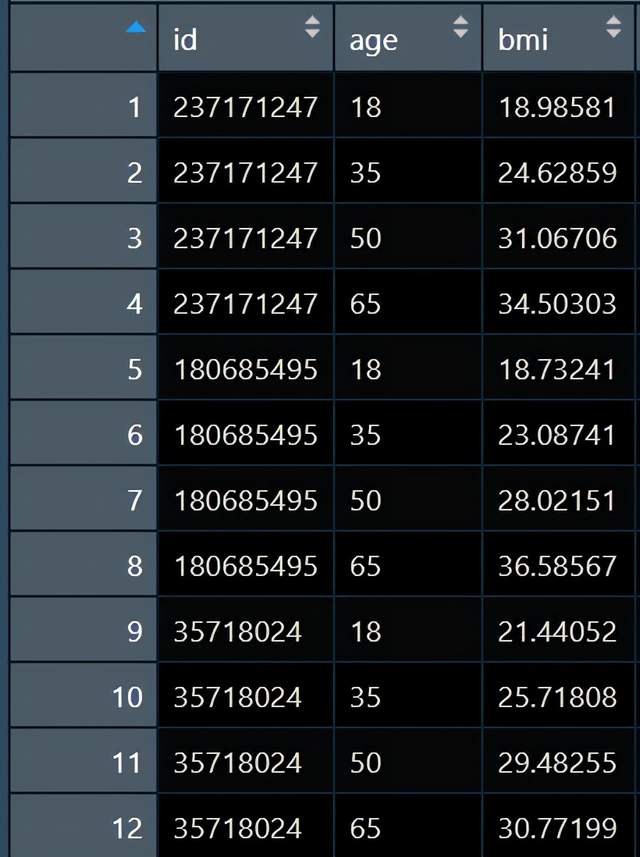
一個縱向的長型數據,包括每個人不同年齡段測得的bmi,我現在就想看看隨着年齡的增長,人群bmi軌跡是不是存在異質性亞組。接下來我就用潛類別軌跡模型回答這個問題,並且出圖,並得到每個軌跡類別的人數和占比。
首先我們寫出軌跡類別數量為1時候的潛類別軌跡的代碼:
m.1 <- hlme(bmi ~ 1+ age + I(age^2), random = ~ 1 + age, ng = 1, data = data.frame(bmi), subject = "id")
關於hlme之前給大家寫過各個參數的意思,上面的代碼就是要擬合bmi隨着年齡變化的軌跡,同時考慮年齡的隨機效應(截距+斜率),並聲明嵌套的高水平subject = "id"。運行上面的代碼我們就擬合了一個軌跡類別為1的模型。
之后我們還需要擬合2到7個類別的模型,這個7是上面文獻推薦的哈,我們可以寫個循環語句,一次搞定(為什么不從模型1循環到7呢?是因為ng參數為1時我們並不需要設定mixture參數,所以2到7寫了循環,1單獨做):
lin <- c(m.1$ng, m.1$BIC) for (i in 2:7) { mi <- hlme(fixed = bmi ~ 1+ age + I(age^2), mixture = ~ 1 + age + I(age^2), random = ~ 1 + age, ng = i, nwg = TRUE, data = data.frame(bmi), subject = "id") lin <- rbind(lin, c(i, mi$BIC)) }
7個模型跑完,我們需要對比每個模型的BIC(這個也是參考的The Lancet Psychiatry那篇文章的做法),所以我們對模型和相應的BIC進行展示:

從上圖就可以看得出我們軌跡數量確定為5個時,模型的BIC最小,由此可以確定軌跡數量為5。
按照論文報告的要求我們需要出圖,根據圖中每條軌跡的走勢確定軌跡類別標簽,還有每個軌跡類別的人群數量和占比,具體方法如下:
首先,進行圖形的繪制,我們解決這類問題(包括機器學習模型)的基本思路依然是通過自我數據得到模型,通過模型擬合新數據出圖,代碼如下:
plotpred <- predict(m5, datnew, var.time ="age", draws = TRUE) plot(plotpred, lty=2,xlab="Age", ylab="BMI", legend.loc = "topleft", cex=0.75)
上面的代碼中m5為我們擬合的5個軌跡類別的模型對象。
運行代碼得到圖如下:
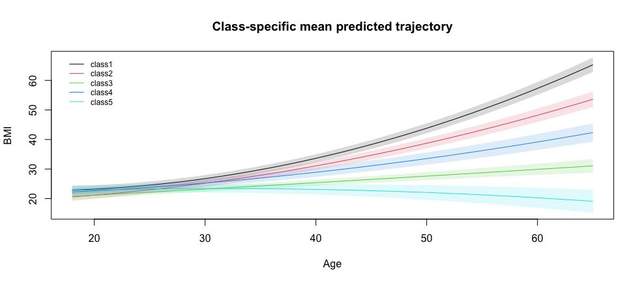
然后我們就可以根據圖的走勢給每個潛類別軌跡打上有臨床意義的標簽了,有了標簽就可以進行后續的建模了。
然后我們還需要報告每個軌跡類別的人數和占比,方法如下:
m5$pprob
運行代碼即可得到,每個個案到底屬於哪個軌跡類別,以及其屬於每個軌跡類別的概率,如下圖:
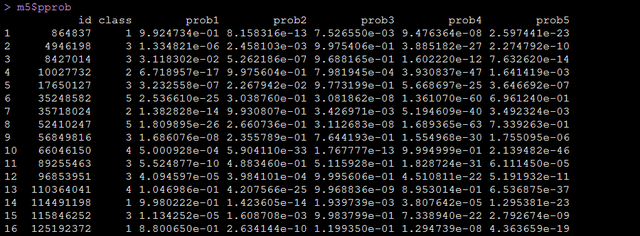
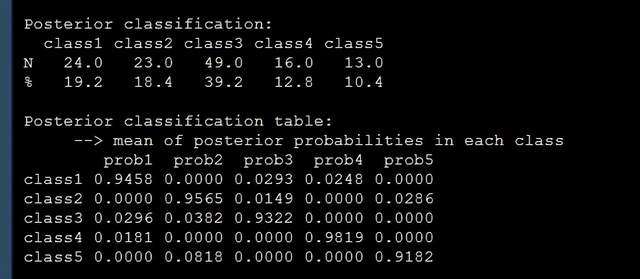
到這兒我們的模型基本跑完了,論文中有提到后驗概率大於0.7,類別人數大於0.02,這個在模型總結中也是可以調出來的:
基本上掌握了上面的方法,柳葉刀精神病學那篇文章的前半部分統計分析就完成了,如果你想將某個症狀或者疾病發展的軌跡作為自變量的相關研究都可以進行了,好了今天要給大家分享的潛類別軌跡模型的做法就是這樣。
后記:寫完這篇文章,我越來越覺得潛類別軌跡模型和增長混合模型就是一個東西,只不過不同的學者用詞不一樣,不知各位看官怎么看,可以私信我交流。
另外,還特別建議大家好好去看lcmm包的說明文檔,相信大家看完之后還會有更大收獲。
小結
今天給大家寫了潛類別軌跡的做法,感謝大家耐心看完,自己的文章都寫的很細,代碼都在原文中,希望大家都可以自己做一做,請轉發本文到朋友圈后私信回復“數據鏈接”獲取所有數據和本人收集的學習資料。如果對您有用請先收藏,再點贊分享。
也歡迎大家的意見和建議,大家想了解什么統計方法都可以在文章下留言,說不定我看見了就會給你寫教程哦,另歡迎私信。
如果你是一個大學本科生或研究生,如果你正在因為你的統計作業、數據分析、模型構建,科研統計設計等發愁,如果你在使用SPSS, R,Python,Mplus, Excel中遇到任何問題,都可以聯系我。因為我可以給您提供最好的,最詳細和耐心的數據分析服務。
如果你對Z檢驗,t檢驗,方差分析,多元方差分析,回歸,卡方檢驗,相關,多水平模型,結構方程模型,中介調節,量表信效度等等統計技巧有任何問題,請私信我,獲取詳細和耐心的指導。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #Reports, #Composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
加油吧,打工人!
往期精彩
R數據分析:什么是人群歸因分數Population Attributable Fraction
R數據分析:隨機截距交叉滯后RI-CLPM與傳統交叉滯后CLPM