MIT 6.824 Lab 1 - 實現 MapReduce
本文章介紹MIT 6.824 Lab 1的實現,主要任務為采用GoLang實現MapReduce分布式計算框架。
完整的 Lab 說明可參閱鏈接 http://nil.csail.mit.edu/6.824/2021/labs/lab-mr.html。
windows采用Goland+雲服務器
本lab不推薦在window上做實驗,推薦在linux,可以弄虛擬機或者直接搞一個服務器,個人推薦服務器,阿里雲有學生優惠(做點題可以免費用六個月),華為雲或者騰訊雲可以免費用1個月。
IDE編程寫代碼還是很爽的,Goland可以通過部署直接將任意代碼文件傳到服務器指定的路徑下,然后再IDE下方用ssh連接到服務器
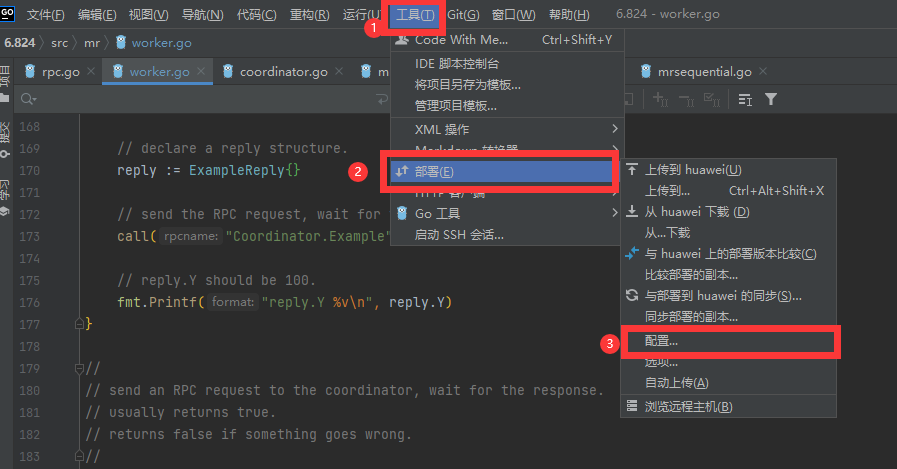
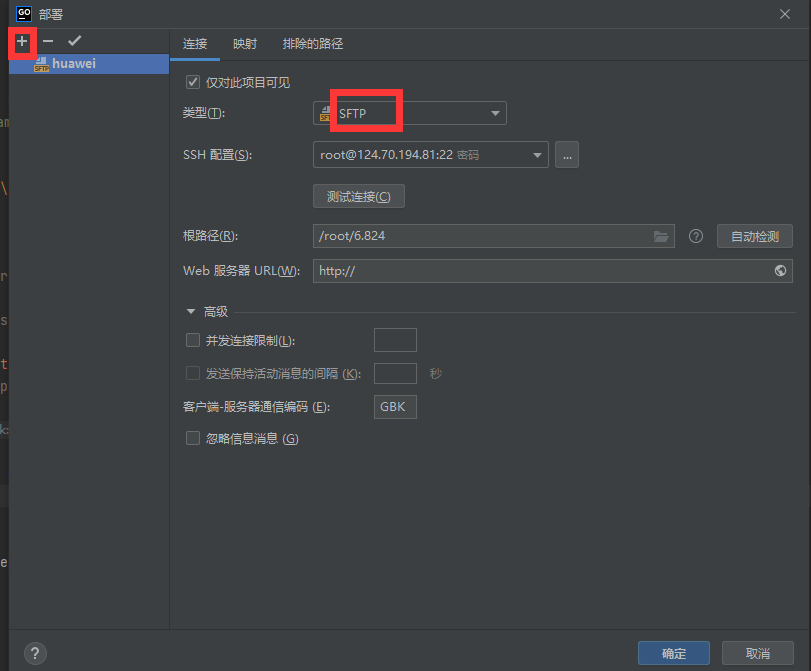
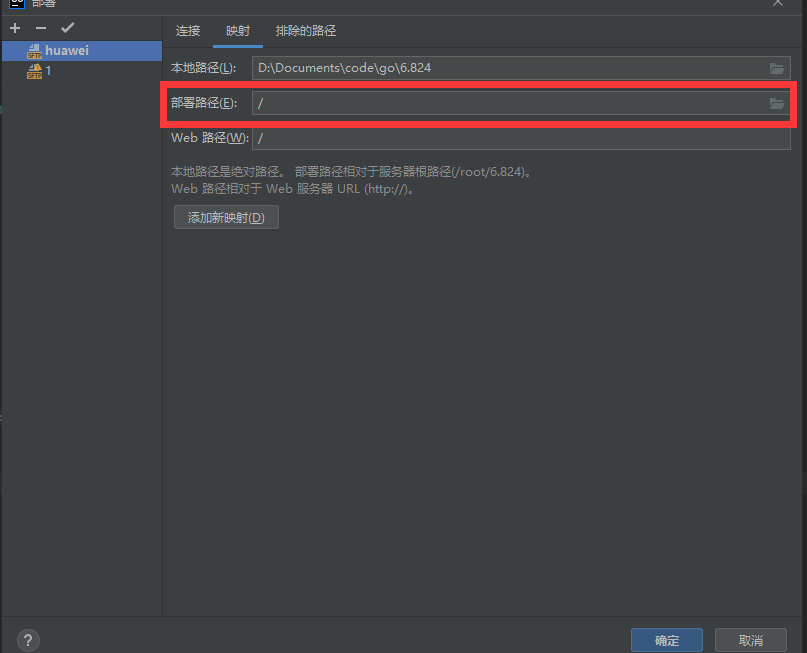
下面是配置Goland的"部署"的具體流程:
安裝go環境
實驗使用Go 1.15進行實驗評分,以 root 或者其他 sudo 用戶身份運行下面的命令,下載並且解壓 Go 二進制文件到/usr/local目錄:
wget -qO- https://golang.org/dl/go1.15.8.linux-amd64.tar.gz | sudo tar -xz -C /usr/local
但在國內連接不上,我是直接在瀏覽器打開網站 https://golang.org/dl/go1.15.8.linux-amd64.tar.gz,把壓縮包下載下來,然后在上傳到服務區上,然后解壓
tar -C /usr/local -zxvf go1.11.5.linux-amd64.tar.gz
國內也可以直接下載該版本的壓縮包
wget -c https://dl.google.com/go/go1.15.8.linux-amd64.tar.gz -O - | sudo tar -xz -C /usr/local
加入環境變量
通過將 Go 目錄添加到$PATH環境變量,系統將會知道在哪里可以找到 Go 可執行文件。
這個可以通過添加下面的行到/etc/profile文件(系統范圍內安裝)或者$HOME/.profile文件(當前用戶安裝):
export PATH=$PATH:/usr/local/go/bin
永久保存:
centos
保存文件,並且重新加載新的PATH 環境變量到當前的 shell 會話:
source /etc/profile
Ubuntun
將命令export PATH=$PATH:/usr/local/go/bin寫入~/.bashrc 中,記得執行 source ~/.bashrc,來將修改應用到當前的bash環境下。
source ~/.bashrc
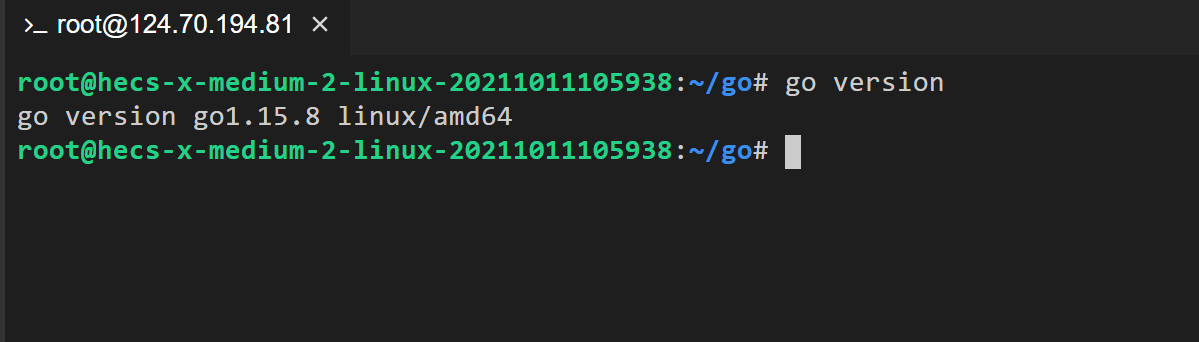
驗證 Go 安裝過程
通過打印 Go 版本號,驗證安裝過程。
go version
go語言入門(中文):https://tour.go-zh.org/welcome/1
非分布式實現
首先,我們通過 Git 獲取 Lab 的初始代碼:
git clone git://g.csail.mit.edu/6.824-golabs-2021 6.824
cd 6.824
初始代碼中默認已經提供了 簡單的單進程串行 的 MapReduce 參考實現,在 main/mrsequential.go 中。我們可以通過以下命令來試玩一下:
cd src/main go build -buildmode=plugin ../mrapps/wc.go rm mr-out* go run mrsequential.go wc.so pg*.txt more mr-out-0
輸出文件在src/main/mr-out-0,文件中每一行標明了單詞和出現次數。
go build -buildmode=plugin ../mrapps/wc.go該命令的作用是構建 MR APP 的動態鏈接庫,使用了 Golang 的 Plugin 來構建 MR APP,使得 MR 框架的代碼可以和 MR APP 的代碼分開編譯,而后 MR 框架再通過動態鏈接的方式載入指定的 MR APP 運行。
具體說:wc.go 實現了Map函數和Reduce函數,但Map和Reduce相當於基礎性代碼,我們可能會隨時改變它,采用上述的動態鏈接,我們只需要改變wc.go, 然后編譯成wc.so,
go run mrsequential.go wc.so pg*.txt這樣就可以載入我們整體性架構了,其他架構代碼不需要重新部署和運行。mrsequential.go中載入動態庫(如,wc.so)代碼為:
mapf, reducef := loadPlugin(os.Args[1])
在mrapps目錄下提供其他的MR APP實現,幾個文件都實現為map, reduce的函數,這兩個函數在mrsequential.go中加載並調用。給mrsequential綁定不同的*.so文件,也就會加載不同的map, reduce函數。如此實現某種程度上的動態綁定。
mrsequential.go實現的非分布式的,具體實現很簡單:文章提取單詞,調用wc.so的Map函數返回一個數組,數組元素為<word1, 1>對,然后排序,然后同樣的單詞會挨在一起,這樣就能某個單詞收集到一個數組傳到list即可,然后將list傳到Reduce函數,最后返回的結果寫入文件即可。
分布式實現(單機多進程並行)
一定要看一下lab:http://nil.csail.mit.edu/6.824/2021/labs/lab-mr.html。
實驗要點:
-
協調器和工作器的啟動程序在
main/mrcoordinator.go和main/mrworker.go 中;不要更改這些文件。我們需要具體實現代碼放在mr/coordinator.go、mr/worker.go和mr/rpc.go 中。可以采用下面命令初步調試我們的代碼:
# 啟動協調器,輸入數據 go run mrcoordinator.go pg-*.txt # 啟動工作器,加載動態鏈接庫 go run mrworker.go wc.so -
實驗架構:1個協調器和多個工作器,采用rpc通信:項目初始的時候舉了一個例子,可以參考一下。
-
協調器Coordinator負責整體任務產生、分配(RPC)和清點(宕機:work超10秒未完成任務,任務重新分配)
-
工作器Worker負責申請任務(RPC)、完成任務
-
Worker超時未完成的話,Coordinator會把任務分配給其他worker,會產生兩個Worker完成同一個任務,如果work直接將結果寫入文件,會出現沖突。
對於上述第5點,我主要參考https://mr-dai.github.io/mit-6824-lab1/
參考了 Google MapReduce 的做法,Worker 在寫出數據時可以先寫出到臨時文件,最終確認沒有問題后再將其重命名為正式結果文件,區分開了 Write 和 Commit 的過程。Commit 的過程可以是 Coordinator 來執行,也可以是 Worker 來執行:
- Coordinator Commit:Worker 向 Coordinator 匯報 Task 完成,Coordinator 確認該 Task 是否仍屬於該 Worker,是則進行結果文件 Commit,否則直接忽略
- Worker Commit:Worker 向 Coordinator 匯報 Task 完成,Coordinator 確認該 Task 是否仍屬於該 Worker 並響應 Worker,是則 Worker 進行結果文件 Commit,再向 Coordinator 匯報 Commit 完成
這里兩種方案都是可行的,各有利弊。我在我的實現中選擇了 Coordinator Commit,因為它可以少一次 RPC 調用,在編碼實現上會更簡單,但缺點是所有 Task 的最終 Commit 都由 Coordinator 完成,在極端場景下會讓 Coordinator 變成整個 MR 過程的性能瓶頸。
代碼設計與實現
流程如下:
- Coordinator首先輸入數據產生n個Map任務,開啟一個類似服務器的響應函數
ApplyForTask RPC,等待work申請任務。 - Worker采用多進程模擬多台機器,用無限循環實現即可,Worker調用
ApplyForTask RPC申請任務,得到任務后完成任務,完成任務后繼續申請新的任務。 - Coordinator接收到任務申請后,首先判斷該Worker上一個任務有沒有,如果有且任務記錄是該orker(超時的話,應該被取消),記錄完成任務的結果。然后分配新的任務。
- 完成MAP任務后,切換到REDUCE任務階段即可,與上述流程一樣
- Coordinator調用多線程完成任務清點工作,超時的任務重新分配
RPC
這里主要定義一些常用的函數和通信交互的結果,一開始可能想的不是全面,但在書寫的過程中慢慢補充。
const (
MAP = "MAP"
REDUCE = "REDUCE"
DONE = "DONE"
)
// 一定要大寫開頭, 不然RPC通信過程中序列化/反序列化的時候可能找不到
// 任務描述
type Task struct {
Id int
Type string
MapInputFile string
WorkerId int
DeadLine time.Time
}
// 任務申請
type ApplyForTaskArgs struct {
WorkerId int
LastTaskId int
LastTaskType string
}
// 任務申請回復
type ApplyForTaskReply struct {
TaskId int
TaskType string
MapInputFile string
NReduce int
NMap int
}
文件的保存的名字
func tmpMapOutFile(workerId int, mapId int, reduceId int) string {
return fmt.Sprintf("tmp-worker-%d-%d-%d", workerId, mapId, reduceId)
}
func finalMapOutFile(mapId int, reduceId int) string {
return fmt.Sprintf("mr-%d-%d", mapId, reduceId)
}
func tmpReduceOutFile(workerId int, reduceId int) string {
return fmt.Sprintf("tmp-worker-%d-out-%d", workerId, reduceId)
}
func finalReduceOutFile(reduceId int) string {
return fmt.Sprintf("mr-out-%d", reduceId)
}
woker
主要代碼是不斷循環向coordinator請求工作,
MapTask的實現流程:
- 讀取reply的文件內容
- 傳遞動態鏈接的mapf函數,得到中間加過:數字,元素<word,1>
- 將中間結果
Key的Hash值%nReduc進行分配,實際就是相同的單詞給同一個Reduce任務分配,產生結果保存到文件中
ReduceTask的實現流程:
- 讀取該Reduce編號的中間結果文件數據
- 對所有中間結果進行排序,相同的單詞就挨在一起
- 將相同的單詞抽取成一個list,傳到動態鏈接的reducef函數,得到word個數(規范化),保存到Reduce的中間結果文件
// 不斷循環向coordinator請求工作
func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) {
// 單機運行,直接使用 PID 作為 Worker ID,方便 debug
id := os.Getpid()
log.Printf("Worker %d 開始工作:\n", id)
lastTaskId := -1
lastTaskType := ""
for {
args := ApplyForTaskArgs{
WorkerId: id,
LastTaskId: lastTaskId,
LastTaskType: lastTaskType,
}
reply := ApplyForTaskReply{}
call("Coordinator.ApplyForTask", &args, &reply)
switch reply.TaskType {
case "":
log.Printf("接收到所有任務完成信號!")
goto End
case MAP:
doMapTask(id, reply.TaskId, reply.MapInputFile, reply.NReduce, mapf)
case REDUCE:
doReduceTask(id, reply.TaskId, reply.NMap, reducef)
}
lastTaskId = reply.TaskId
lastTaskType = reply.TaskType
log.Printf("完成 %s 任務 %d", reply.TaskType, reply.TaskId)
}
End:
log.Printf("Worker %d 結束工作\n", id)
// Your worker implementation here.
// uncomment to send the Example RPC to the coordinator.
// CallExample()
}
func doMapTask(id int, taskId int, fileName string, nReduce int, mapf func(string, string) []KeyValue) {
// 讀入輸入數據
file, err := os.Open(fileName)
if err != nil {
log.Fatalf("%s 文件打開失敗!", fileName)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("%s 文件內容讀取失敗!", fileName)
}
file.Close()
kva := mapf(fileName, string(content))
hashedKva := make(map[int][]KeyValue)
for _, kv := range kva {
hashed := ihash(kv.Key) % nReduce
hashedKva[hashed] = append(hashedKva[hashed], kv)
}
for i := 0; i < nReduce; i++ {
outFile, _ := os.Create(tmpMapOutFile(id, taskId, i))
for _, kv := range hashedKva[i] {
fmt.Fprintf(outFile, "%v\t%v\n", kv.Key, kv.Value)
}
outFile.Close()
}
}
func doReduceTask(id int, taskId int, nMap int, reducef func(string, []string) string) {
var lines []string
for i := 0; i < nMap; i++ {
file, err := os.Open(finalMapOutFile(i, taskId))
if err != nil {
log.Fatalf("文件 %s 打開失敗!", finalMapOutFile(i, taskId))
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("文件 %s 讀取失敗!", finalMapOutFile(i, taskId))
}
lines = append(lines, strings.Split(string(content), "\n")...)
}
var kva []KeyValue
for _, line := range lines {
if strings.TrimSpace(line) == "" {
continue
}
split := strings.Split(line, "\t")
kva = append(kva, KeyValue{
Key: split[0],
Value: split[1],
})
}
sort.Sort(ByKey(kva))
outFile, _ := os.Create(tmpReduceOutFile(id, taskId))
i := 0
for i < len(kva) {
j := i + 1
for j < len(kva) && kva[j].Key == kva[i].Key {
j++
}
var values []string
for k := i; k < j; k++ {
values = append(values, kva[k].Value)
}
output := reducef(kva[i].Key, values)
fmt.Fprintf(outFile, "%v %v\n", kva[i].Key, output)
i = j
}
outFile.Close()
}
Coordinator
Coordinator的結構
type Coordinator struct {
// Your definitions here.
lock sync.Mutex // 鎖
stage string // 目前任務狀態:MAP REDUCE DONE
nMap int // MAP任務數量
nReduce int // Reduce任務數量
tasks map[string]Task // 任務映射,主要是查看任務狀態
toDoTasks chan Task // 待完成任務,采用通道實現,內置鎖結構
}
Coordinator構造函數,實現功能:初始化和產生MAP任務,開啟另一個線程循環掃描任務狀態
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{
stage: MAP,
nMap: len(files),
nReduce: nReduce,
tasks: make(map[string]Task),
toDoTasks: make(chan Task, int(math.Max(float64(len(files)), float64(nReduce)))),
}
// Your code here.
for i, file := range files {
task := Task{
Id: i,
Type: MAP,
WorkerId: -1,
MapInputFile: file,
}
log.Printf("Type: %s", task.Type)
c.tasks[crateTaskId(task.Type, task.Id)] = task
c.toDoTasks <- task
}
log.Printf("Coordinator start\n")
c.server()
// 多線程啟動回收機制,回收超時任務
go func() {
for {
time.Sleep(500 * time.Millisecond)
c.lock.Lock()
for _, task := range c.tasks {
if task.WorkerId != -1 && time.Now().After(task.DeadLine) {
log.Printf("%d 運行任務 %s %d 出現故障,重新收回!", task.WorkerId, task.Type, task.Id)
task.WorkerId = -1
c.toDoTasks <- task
}
}
c.lock.Unlock()
}
}()
return &c
}
任務完成、可用 Task 獲取與分配
func (c *Coordinator) ApplyForTask(args *ApplyForTaskArgs, reply *ApplyForTaskReply) error {
// 記錄woker的上一個任務完成
if args.LastTaskId != -1 {
c.lock.Lock()
taskId := crateTaskId(args.LastTaskType, args.LastTaskId)
// 這里才產生最后的輸出結果,是因為怕超時worker和合法worker都寫入,造成沖突
if task, ok := c.tasks[taskId]; ok && task.WorkerId == args.WorkerId { // 加后一個條件原因是莫個work出現故障,要被回收
log.Printf("%d 完成 %s-%d 任務", args.WorkerId, args.LastTaskType, args.LastTaskId)
if args.LastTaskType == MAP {
for i := 0; i < c.nReduce; i++ {
err := os.Rename(
tmpMapOutFile(args.WorkerId, args.LastTaskId, i),
finalMapOutFile(args.LastTaskId, i))
if err != nil {
log.Fatalf(
"Failed to mark map output file `%s` as final: %e",
tmpMapOutFile(args.WorkerId, args.LastTaskId, i), err)
}
}
} else if args.LastTaskType == REDUCE {
err := os.Rename(
tmpReduceOutFile(args.WorkerId, args.LastTaskId),
finalReduceOutFile(args.LastTaskId))
if err != nil {
log.Fatalf(
"Failed to mark reduce output file `%s` as final: %e",
tmpReduceOutFile(args.WorkerId, args.LastTaskId), err)
}
}
delete(c.tasks, taskId)
if len(c.tasks) == 0 {
c.cutover()
}
}
c.lock.Unlock()
}
// 獲取一個可用的Task並返回
task, ok := <-c.toDoTasks
// 通道關閉,代表整個MR作業已經完成,通知Work退出
if !ok {
return nil
}
c.lock.Lock()
defer c.lock.Unlock()
log.Printf("Assign %s task %d to worker %dls"+
"\n", task.Type, task.Id, args.WorkerId)
// 更新task
task.WorkerId = args.WorkerId
task.DeadLine = time.Now().Add(10 * time.Second)
c.tasks[crateTaskId(task.Type, task.Id)] = task
// 給work返回數據
reply.TaskId = task.Id
reply.TaskType = task.Type
reply.MapInputFile = task.MapInputFile
reply.NMap = c.nMap
reply.NReduce = c.nReduce
return nil
}
運行階段的切換
func (c *Coordinator) cutover() {
if c.stage == MAP {
log.Printf("所有的MAP任務已經完成!開始REDUCE任務!")
c.stage = REDUCE
for i := 0; i < c.nReduce; i++ {
task := Task{Id: i, Type: REDUCE, WorkerId: -1}
c.tasks[crateTaskId(task.Type, i)] = task
c.toDoTasks <- task
}
} else if c.stage == REDUCE {
log.Printf("所有的REDUCE任務已經完成!")
close(c.toDoTasks)
c.stage = DONE
}
}
完成任務體現
func (c *Coordinator) Done() bool {
// Your code here.
c.lock.Lock()
ret := c.stage == DONE
defer c.lock.Unlock()
return ret
}