分布式系統概要
分布式系統是什么
分布式系統的核心是通過網絡來協調,共同完成一致任務的 一些計算機,比如大型網站存儲,MapReduce 算法,點對點文件系統
為什么構建分布式系統
- 獲得更好的並發性,高計算性能
- 多台主機容錯,可以進行故障切換
- 很多主機都是分布在世界各地的,物理環境導致必須構建分布式系統
- 更安全,讓不信任的代碼運行在另一台主機上
分布式系統的挑戰
很多主機並發執行程序,會很復雜
很多意想不到的錯誤,如網絡問題,數據不一致的問題
多台計算機,性能問題
課程會涉及網絡應用的基礎設施
存儲
通信
計算
課程還會提到哪些技術
RPC
多線程
並發控制
分布式的話題
性能,可擴展性
用兩倍的機器獲得兩倍的性能,擴展性並不一定能帶來性能的提升
容錯
如果你的系統是由千萬台主機構建的,那出現主機泵機的可能性很高容錯,可用性
自身可恢復性
以上可以通過非易失性存儲和數據備份來實現
- 數據一致性
因為分布式系統中,數據會存有很多副本,所以會有副本之間數據不一致的問題
MapReduce
參考資料:
論文:https://pdos.csail.mit.edu/6.824/papers/mapreduce.pdf
中文版本:https://zhuanlan.zhihu.com/p/122571315
MapReduce介紹
Google MapReduce 是一種編程模型,所執行的分布式計算會以一組鍵值對作為輸入,輸出另一組鍵值對,用戶則通過編寫 Map 函數和 Reduce 函數來指定所要進行的計算。
map (k1, v1) ->list(k2, v2)
reduce (k2, list(v2)) -> list(v2)
課程中老師對MapReduce的講解:
舉個例子:給定大量的文檔,計算其中每個單詞出現的次數(Word Count)。用戶通常需要提供形如如下偽代碼的代碼來完成計算:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));

函數式編程模型
MapReduce 所采用的編程模型源自於函數式編程里的 Map 函數和 Reduce 函數。后起之秀 Spark 同樣采用了類似的編程模型。
使用函數式編程模型的好處在於這種編程模型本身就對並行執行有良好的支持,這使得底層系統能夠輕易地將大數據量的計算並行化,同時由用戶函數所提供的確定性也使得底層系統能夠將函數重新執行作為提供容錯性的主要手段。
MapReduce 計算執行過程
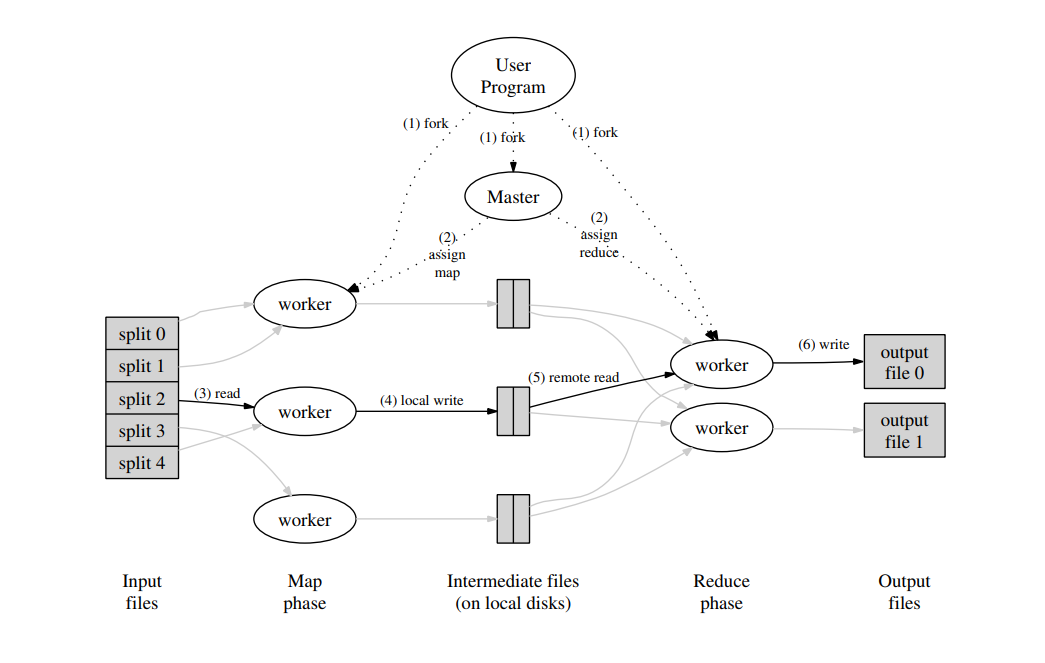
首先,用戶通過 MapReduce 客戶端指定 Map 函數和 Reduce 函數,以及此次 MapReduce 計算的配置,包括中間結果鍵值對的 Partition 數量 R 以及用於切分中間結果的哈希函數 hash。
用戶開始 MapReduce 計算后,整個 MapReduce 計算的流程可總結如下:
- 作為輸入的文件會被分為 M 個 Split,每個 Split 的大小通常在 16~64 MB 之間
- 如此,整個 MapReduce 計算包含 M 個Map 任務和 R 個 Reduce 任務。Master 結點會從空閑的 Worker 結點中進行選取並為其分配 Map 任務和 Reduce 任務
- 收到 Map 任務的 Worker 們(又稱 Mapper)開始讀入自己對應的 Split,將讀入的內容解析為輸入鍵值對並調用由用戶定義的 Map 函數。由 Map 函數產生的中間結果鍵值對會被暫時存放在緩沖內存區中
- 在 Map 階段進行的同時,Mapper 們周期性地將放置在緩沖區中的中間結果存入到自己的本地磁盤中,同時根據用戶指定的 Partition 函數(默認為 hash(key) mod R)將產生的中間結果分為 R 個部分。任務完成時,Mapper 便會將中間結果在其本地磁盤上的存放位置報告給 Master
- Mapper 上報的中間結果存放位置會被 Master 轉發給 Reducer。當 Reducer 接收到這些信息后便會通過 RPC 讀取存儲在 Mapper 本地磁盤上屬於對應 Partition 的中間結果。在讀取完畢后,Reducer 會對讀取到的數據進行排序以令擁有相同鍵的鍵值對能夠連續分布
- 之后,Reducer 會為每個鍵收集與其關聯的值的集合,並以之調用用戶定義的 Reduce 函數。Reduce 函數的結果會被放入到對應的 Reduce Partition 結果文件
實際上,在一個 MapReduce 集群中,Master 會記錄每一個 Map 和 Reduce 任務的當前完成狀態,以及所分配的 Worker。除此之外,Master 還負責將 Mapper 產生的中間結果文件的位置和大小轉發給 Reducer。
值得注意的是,每次 MapReduce 任務執行時,M 和 R 的值都應比集群中的 Worker 數量要高得多,以達成集群內負載均衡的效果。