大數據之kafka
第一章 kafka概述
1.1 定義
- kafka是一個分布式的基於發布/訂閱模式的消息隊列,主要應用於大數據實時處理領域
1.2 消息隊列
1.2.1 傳統消息隊列的應用場景
-
同步處理:
生產者生產數據,直接傳給消費者
-
異步處理:
生產者生產數據,把數據放在消息隊列中,供消費者自行拉取
- 使用消息隊列的好處
- 解耦
- 允許你獨立的擴展或修改兩邊的處理過程,只要確保它們遵守同樣的接口約束
- 可恢復性
- 系統的一部分組件失效時,不會影響整個系統,消息隊列降低了進程間的耦合度,所以即使一個處理消息的進程掛掉,加入隊列中的消息仍然可以在系統恢復后被處理
- 緩沖
- 有助於控制和優化數據流經過系統的速度,解決生產消息和消費者消息的處理速度不一致的情況
- 靈活性&峰值處理能力
- 在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見,如果為以能處理這類峰值訪問為標准來投入資源隨時待命無疑是巨大的浪費,使用消息隊列能夠使關鍵組件頂住突發的訪問壓力,而不會因為突發的超負荷請求而完全崩潰
- 異步通信
- 很多時候,用戶不想也不需要立刻處理消息,消息隊列提供了很多異步處理機制,允許用戶把一個消息放入隊列中,但並不立即處理它。想向隊列中放入多少消息就放多少,然后再需要的時候再去處理它們
- 解耦
1.2.2 消息隊列的兩種模式
- 點對點模式(一對一,消費者主動拉取數據,消息收到后消息清除)
- 消息生產者生產消息發送到Queue中,然后消息消費者從Queue中取出並且消費消息。消息被消費以后,Queue中不再有存儲,所以消費者不可能消費到已經被消費的數據。Queue支持存在多個消費者,但是對一個消息而言,只會有一個消費者可以消費
- 發布/訂閱模式(一對多,消費者消費數據之后不會清除消息)
- 消息生產者(發布)將消息發布到topic中,同時有多個消息消費者(訂閱)消費該消息,和點對點方式不同,發布到topic的消息會被所有訂閱者消費
1.3 kafka基礎架構
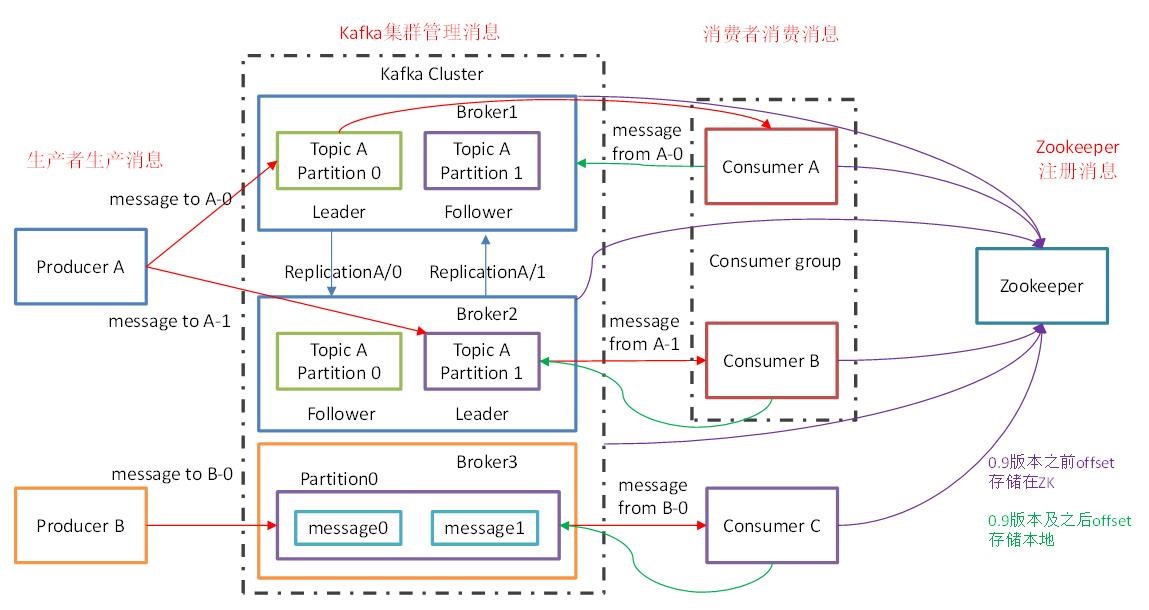
備注:同一個分區的數據只能被同一個消費者組內的某一個消費者消費
1.3.1 Broker
- kafka集群包含一個或多個服務器,服務器節點成為broker
1.3.2 Topic
- 每條發布到kafka集群的消息都有一個類別,這個類別被稱為topic
- 類似於數據庫的表名或者ES中的index
- 物理上不同topic的消息分開存儲
- 邏輯上一個topic的消息雖然保存於一個或多個broker上但用戶只需指定消息的topic即可生產或消費數據而不必關心數據存於何處
####在kafka集群中,除了數據文件是存在本機,其他的都存在zookeeper上
1.3.3 partition
-
topic中的數據分割成一個或多個partition
-
每個topic至少有一個partition,當生產者產生數據的時候,根據分配策略(Hash取模),選擇分區,然后將消息追加到指定的分區的末尾(隊列)
## partition數據路由規則 1.指定了partition,則直接使用 2.未指定partition,但指定key,通過對key的value進行hash選出一個partition 3.partition和key都未指定,使用輪詢選出一個partition -
每個消息都會有一個自增的編號
- 標識順序
- 用於標識消息的偏移量,有專門的索引信息
-
每個partition中的數據使用多個segment文件存儲
-
partition中的數據是有序的,不同partition間的數據丟失了數據的順序
-
如果topic有多個partition,消費數據時就不能保證數據的順序,在需要嚴格保證消息的消費順序的場景下,需要將partition數目設為1
-
broker存儲topic的數據,如果某個topic有N個partition,集群中有N個broker,那么每個broker存儲該topic的一個partition。
-
如果某topic有N個partition,集群中有(N+M)個broker,那么其中有N個broker存儲topic的一個partition,剩下的M個broker不存儲該topic的partition數據。
-
如果某topic有N個partition,集群中broker數目少於N個,那么一個broker存儲topic的一個或多個partition,在實際生產環境中,盡量避免這種情況發生,容易導致kafka集群數據不均衡
1.3.4 Leader
-
每個partition有多個副本,其中有且僅有一個作為leader,leader是當前負責數據讀寫partition
1.producer先從zookeeper的"/borkers/.../state"節點找到該partition的leader 2.producer將消息發送給該leader 3.leader將消息寫入本地log 4.followers從leader pull消息,寫入本地log后leader發送ACK 5.leader收到所有ISR的replica的ACK后,增加HW(high watermark,最后commit的的offset)並向producer發送ACK
1.3.5 Follower
- Follower跟隨leader,所有寫請求都通過leader路由,數據變更會廣播給所有follower,follower與leader保持數據同步
- 如果leader失敗,則從follower中選取一個新的leader
- 當follower掛掉、卡住或同步太慢,leader會把這個follower從“in sync replicas”(ISR)列表中刪除,重新創建一個follower
1.3.6 replication
-
數據會存放到topic分區中,但是有可能分區會損壞;分區=partition
-
我們需要對分區的數據進行備份(備份多少取決於你對數據的重視程度)
-
我們將分區的數據分為leader(1)和Follower(N)
- leader負責寫入和讀取數據
- follower只負責備份
- 保證了數據的一致性
-
備份數設置為N,表示主+備=N(參考HDFS)
##kafka分配replica的算法如下: 1.將所有broker(假設為N)和待分配的partition排序 2.將第i個partition分配到第(i mod n )個broker上 3.將第i個partition的第j個replica分配到第((i+j)mode n)個broker上
第二章 kafka快速入門
2.1 安裝部署
2.1.1 集群規划
| hadoop102 | hadoop103 | hadoop104 |
|---|---|---|
| zookeeper kafka | zookeeper kafka | zookeeper kafka |
2.1.2 jar包下載
https://kafka.apache.org/downloads
2.1.3 集群部署
-
上傳軟件包到hadoop102
[xiaoyao@hadoop102 config]$ cd /opt/src/ [xiaoyao@hadoop102 src]$ ll 總用量 574656 -rw-r--r--. 1 root root 9623007 6月 7 16:31 apache-zookeeper-3.5.9-bin.tar.gz -rw-r--r--. 1 root root 395448622 1月 14 2021 hadoop-3.2.2.tar.gz -rw-r--r--. 1 xiaoyao xiaoyao 144935989 5月 6 23:54 jdk-8u291-linux-x64.tar.gz -rw-r--r--. 1 root root 38424081 6月 17 23:08 kafka_2.10-0.10.2.1.tgz -rw-rw-r--. 1 xiaoyao xiaoyao 5393 6月 30 22:41 sdimage.xml -
解壓軟件包
[xiaoyao@hadoop102 src]$ cd /opt/module/ [xiaoyao@hadoop102 module]$ ll 總用量 4 drwxr-xr-x. 13 xiaoyao xiaoyao 4096 6月 28 00:08 hadoop-3.2.2 drwxr-xr-x. 8 xiaoyao xiaoyao 273 4月 8 03:26 jdk1.8.0_291 drwxr-xr-x. 6 xiaoyao xiaoyao 89 4月 22 2017 kafka drwxrwxr-x. 6 xiaoyao xiaoyao 134 8月 1 17:29 zookeeper -
修改配置文件
##修改kafka配置文件 [xiaoyao@hadoop102 config]$ pwd /opt/module/kafka/config [xiaoyao@hadoop102 config]$ vim server.properties #broker全局唯一編號,不能重復 broker.id=0 #刪除topic功能 delete.topic.enable=true #處理網絡請求的線程數量 num.network.threads=3 #處理磁盤IO的線程數量 num.io.threads=8 #發送套接字緩沖區的大小 socket.send.buffer.bytes=102400 #接收套接字緩沖區的大小 socket.receive.buffer.bytes=102400 #請求套接字緩沖區大小 socket.request.max.bytes=104857600 #kafka數據的存放路徑 log.dirs=/opt/module/kafka/data #topic在當前broker上的分區個數 num.partitions=1 #用來恢復和清理data下數據的線程數量 num.recovery.threads.per.data.dir=1 #segment文件保留的最長時間,超時將被刪除 log.retention.hours=168 #每個文件的最大空間,默認為1G log.segment.bytes=1073741824 #配置連接zookeeper集群地址 zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181 #配置連接zookeeper超時時間 zookeeper.connection.timeout.ms=6000 #創建目錄文件 [xiaoyao@hadoop102 kafka]$ mkdir data logs ##修改zookeeper配置文件 [xiaoyao@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg #通信心跳時間 tickTime=2000 #Leader和follower初始通信時限 initLimit=10 #Leader和Follower同步通信時限 syncLimit=5 #數據文件目錄 dataDir=/opt/module/zookeeper/data #客戶端連接端口 clientPort=2181 #集群信息 server.1=hadoop102:2888:3888 server.2=hadoop103:2888:3888 server.3=hadoop104:2888:3888 #創建目錄文件 [xiaoyao@hadoop102 kafka]$ mkdir /opt/module/zookeeper/data/ [xiaoyao@hadoop102 zookeeper]$ echo "1" >> data/myid -
配置環境變量
[xiaoyao@hadoop102 kafka]$ more /etc/profile | grep "KAFKA_HOME" export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin -
分發安裝包
#把hadoop102上的kafka目錄文件拷貝到另外兩個節點 [xiaoyao@hadoop102 module]$ xsync kafka/ ##把hadoop102上的zookeeper目錄文件拷貝到另外兩個節點 [xiaoyao@hadoop102 module]$ xsync zookeeper/ 備注:由於之前配置了分發腳本 -
修改另外節點配置信息
##在hadoop103和hadoop104上修改broker.id #hadoop103 [xiaoyao@hadoop103 kafka]$ grep "broker.id" config/server.properties broker.id=1 #hadoop104 [xiaoyao@hadoop104 kafka]$ grep "broker.id" config/server.properties broker.id=2 #修改節點上myid [xiaoyao@hadoop103 zookeeper]$ cat data/myid 2 [xiaoyao@hadoop104 zookeeper]$ cat data/myid 3 -
啟動集群
#由於kafka集群依賴於zookeeper工作,須先啟動zk [xiaoyao@hadoop102 bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [xiaoyao@hadoop103 bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [xiaoyao@hadoop104 bin]$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ##啟動kafka,三個節點都要啟動 #以守護進程啟動 [xiaoyao@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
2.2 kafka命令行操作
2.2.1 創建topic
[xiaoyao@hadoop102 bin]$ ./kafka-topics.sh --create --topic first --zookeeper hadoop102:2181 --partitions 2 --replication-factor 2
Created topic "first".
#備注:創建的主題有兩個分區和兩個副本,副本數不能超過節點數
#分區的好處:提高讀寫的並行度,提高主題的負載均衡能力
#副本的好處:數據冗余,容災,備份,保證數據的一致性!
2.2.2 查看topic
##查看topic,由於是集群,在任意一個節點都能查看
[xiaoyao@hadoop102 bin]$ ./kafka-topics.sh --zookeeper hadoop102:2181 --list
first
2.2.3 刪除topic
[xiaoyao@hadoop102 bin]$ ./kafka-topics.sh --zookeeper hadoop102:2181 --delete --topic first
Topic first is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
#如果配置文件中參數沒有設置為true,只是邏輯上標記刪除
2.2.4 查看主題詳細信息
[xiaoyao@hadoop102 bin]$ ./kafka-topics.sh --zookeeper hadoop102:2181 --topic first --describe
Topic:first PartitionCount:3 ReplicationFactor:1 Configs:
Topic: first Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: first Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: first Partition: 2 Leader: 1 Replicas: 1 Isr: 1
2.2.5 生產者生產數據
[xiaoyao@hadoop102 bin]$ ./kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
2.2.6 消費者消費數據
#0.9版本以前使用
[xiaoyao@hadoop103 bin]$ ./kafka-console-consumer.sh --topic first --zookeeper hadoop102:2181
#0.9版本以后使用
[xiaoyao@hadoop104 bin]$ ./kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first
#從頭消費數據
[xiaoyao@hadoop104 bin]$ ./kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first --from-beginning
2.2.7 修改分區數
[xiaoyao@hadoop102 kafka]$ ./bin/kafka-topics.sh --zookeeper hadoop102:2181 --alter --topic first --partitions 4
#只能增加分區,不可減少
第三章 kafka架構深入
3.1 kafka工作流程及文件存儲機制
3.1.1 kafka工作流程

- kafka中消息是以topic進行分類的,生產者生產消息,消費者消費消息,都是面向topic的
- topic是邏輯上的概念,而partition是物理上的概念,每個partition對應一個log文件,該log文件中存儲的就是producer生產的數據,生產者生產的數據會被不斷追加到該log文件末端,且每條數據都有自己的offset,消費者組中的每個消費者,都會實時記錄自己消費到了哪個offset,以便出錯恢復時,從上次的位置繼續消費
3.1.2 kafka文件存儲機制

-
由於生產者生產的消息會不斷追加到 log 文件末尾,為防止 log 文件過大導致數據定位
效率低下,Kafka 采取了分片和索引機制,將每個 partition 分為多個 segment。每個 segment
對應兩個文件——“.index”文件和“.log”文件。這些文件位於一個文件夾下,該文件夾的命名
規則為:topic 名稱+分區序號。例如,first 這個 topic 有三個分區,則其對應的文件夾為 first-
0,first-1,first-2。
00000000000000000000.index 00000000000000000000.log 00000000000000170410.index 00000000000000170410.log 00000000000000239430.index 00000000000000239430.log -
index 和 log 文件以當前 segment 的第一條消息的 offset 命名。下圖為 index 文件和 log
文件的結構示意圖。

-
“.index”文件存儲大量的索引信息,“.log”文件存儲大量的數據,索引文件中的元
數據指向對應數據文件中 message 的物理偏移地址。
3.2 kafka生產者
3.2.1 分區策略
- 分區的原因
- 方便在集群中擴展,每個partition可以通過調整以適應它所在的機器,而一個topic又可以有多個partition組成,因此整個集群就可以適應任意大小的數據了
- 可以提高並發,因為可以以partition為單位讀寫了
- 分區的原則
- 指明partition的情況下,直接將指明的值直接作為partition值
- 沒有指明partition值但有key的情況下,將key的hash值與topic的partition數進行取余得到partition值
- 既沒有partition值又沒有key值的情況下,第一次調用時隨機生成一個整數(后面每次調用在這個整數上自增),將這個值與topic可用的partition總數取余得到partition值,也就是常說的輪詢算法
3.2.2 數據可靠性保證
- 副本數據同步策略
- ISR機制
- ack應答機制
- 故障處理:HW、LEO
- 副本數據同步策略
兩種副本同步策略(kafka選擇第二種)
| 方案 | 優點 | 缺點 |
|---|---|---|
| 半數以上完成同步,就發送ack | 延遲低 | 選舉新的leader時,容忍n台節點的故障,需要2n+1個副本 |
| 全部同步完成,才發送ack | 選舉新的leader時,容忍n台節點的故障,需要n+1個副本 | 延遲高 |
- kakfa選擇第二種同步策略,原因如下:
- 為了容忍n台節點的故障,第一種方案需要2n+1個副本,而第二種方案只需要n+1個副本,而Kafka的每個分區都有大量的數據,第一種方案會造成大量數據的冗余。
- 雖然第二種方案的網絡延遲會比較高,但網絡延遲對Kafka的影響較小。
- ISR
- 為了防止Kafka在選擇第二種數據同步策略時,因為某一個follower故障導致leader一直等下去,Leader維護了一個動態的in-sync replica set (ISR)。
- ISR:同步副本,和leader保持同步的follower集合,當ISR中的 follower完成數據的同步之后,leader就會給生產者發送ack。
- 如果follower長時間未向leader同步數據,則該follower將被踢出ISR,該時間閾值由replica.lag.time.max.ms參數設定(默認:10s)。
- 如果Leader發生故障,就會從ISR中選舉新的leader。
- ack應答機制
-
為保證生產者發送的數據,能可靠的發送到指定的topic,topic的每個partition收到的數據后,都需要向生產者發送ack(確認收到),如果生產者收到ack,就會進行下一輪的發送,否則從新發送數據

kafka為用戶提供了三種可靠性級別(acks參數)
- acks=0
producer不等待broker的ack,broker一接收到還沒有寫入磁盤就已經返回。
當broker故障時,有可能丟失數據。 - acks=1
producer等待broker的ack,partition的leader落盤成功后返回ack。
如果在follower同步成功之前leader故障,那么將會丟失數據。 - acks=-1(all)
producer等待broker的ack,partition的leader和follower(ISR中的所有follower)全部落盤成功后才返回ack。
如果在follower同步完成后,broker發送ack之前leader發生故障,此時kafka從ISR中重新選舉一個leader,生產者沒有收到ack重新發送一份到新leader上,則造成數據重復。
如果ISR中只剩一個leader時,此時leader發生故障,可能會造成數據丟失。
如果一個follower故障,該節點被踢出ISR,只要ISR中所有節點都同步即可返回ack,不影響。
-
故障處理

-
LEO:每個副本的最后一個Offset
-
HW:所有副本中最小的LEO
(1)follower故障
follower發生故障后會被臨時踢出ISR,待該follower恢復后,follower會讀取本地磁盤記錄的上次的HW,並將log文件高於HW的部分截取掉,從HW開始向leader進行同步。等該follower的LEO大於等於該Partition的HW,即follower追上leader之后,就可以重新加入ISR了。
(2)leader故障
leader發生故障之后,會從ISR中選出一個新的leader,之后,為保證多個副本之間的數據一致性,其余的 follower會先將各自的log文件高於HW的部分截掉,然后從新的leader同步數據。
注意:這只能保證副本之間的數據一致性,並不能保證數據不丟失或者不重復。(是否丟數據是acks保證)
3.2.3 Exactly Once語義
-
將服務器的ACK級別設置為-1,可以保證生產者到server之間不會丟失數據,即At Least Once語義,相對的,將服務器ACK級別設置為0,可以保證生產者每條消息只會被發送一次,即At Most Once語義
-
At Least Once可以保證數據不丟失,但是不能保證數據不重復;相對的,At Most Once可以保證數據不重復,但不能保證數據不丟失,但是對於一些非常重要的信息,比如說交易數據,下游數據消費者要求數據既不重復也不丟失,即Exactly Once語義,在0.11版本以前的kafka,對此是無能為力的,只能保證數據不丟失,再在下游消費者對數據做全局去重,對於多個下游應用的情況,每個都需要單獨做全局去重,這就對性能造成極大影響。
-
0.11版本后的kafka,引入了這一重大特性:冪等性,所謂的冪等性就是指生產者無論向server發送多少次重復數據,server只會持久化一條,冪等性結合At Least Once語義,就構成了kafka的Exactly Once語義
-
At Least Once + 冪等性 = EXactly Once
-
要開啟冪等性,只需要將生產者的參數中enable.idompotence設置為true,kafka的冪等性實現其實就是將原來下游需要做的去重放在了數據上游,開啟冪等性的生產者在初始化的時候會被分配一個PID,發往同一partition的消息會附帶Sequence Number。而broker端會對<PID,Partition,SeqNumber>做緩存,當具有相同主鍵的消息提交時,broker只會持久化一條
-
但是PID重啟就會變化,同時不同的partition也具有不同主鍵,所以冪等性無法保證跨分區會話的Exactly Once
-
3.3 kafka消費者
3.3.1 消費方式
- consumer采用pull(拉)模式從broker讀取數據
- push(推)模式很難適應速率不同的消費者,因為消息發送速率是由broker決定的。它的目標是盡可能以最快速度傳遞消息,但是這樣容易造成consumer來不及處理消息,典型的表現就是拒絕服務和網絡堵塞,而pull模式可以根據consumer的消費能力以適當的速率消費消息
- pull模式的不足之處是,如果kafka沒有數據,消費者可能會陷入循環中,一直返回空數據,針對這一點,kafka消費者在消費數據時會傳入一個時長參數timeout,如果當前沒有數據可供消費,consumer會等待一段時間之后再返回,這段時長是timeout
3.3.2 分區分配策略
- kafka有兩種分配策略
- RoundRobin(輪詢),面向對象為組
- Range(范圍),面向對象為主體
3.3.3 offset的維護

-
由於consumer在消費過程中可能會出現斷電宕機等故障,consumer恢復后,需要從故障前的位置繼續消費,所以consumer需要實時記錄自己消費到了哪個offset,以便故障恢復后繼續消費
-
根據消費者組、主題、分區來決定offset
3.3.4 消費者組案例
-
需求:測試同一個消費者組中的消費者,同一時刻只能有一個消費者消費
-
案例實操
-
在Hadoop102、hadoop103上修改group.id為任意組名
[xiaoyao@hadoop102 config]$ vim /opt/module/kafka/config/consumer.properties group.id=xiaoyao -
在hadoop102、hadoop103上分別啟動消費者
[xiaoyao@hadoop102 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first --consumer.config config/consumer.properties [xiaoyao@hadoop103 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first --consumer.config config/consumer.properties -
在hadoop104上啟動生產者
[xiaoyao@hadoop104 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first -
查看hadoop102和hadoop103的接收者
- 同一時刻只有一個消費者能夠接收到數據
-
3.4 kafka高效讀寫數據
-
順序寫磁盤
- kafka的producer生產數據,要寫入到log文件中,寫的過程是一直追加到文件末端,為順序寫,官網有數據表明,同樣的磁盤,順序寫能到600M/s,而隨機寫只有100k/s,這與磁盤的機械結構有關,順序寫之所以快,是因為其省去了大量磁頭尋址的時間
-
零復制技術

3.5 zookeeper在kafka中的作用
- kafka集群中有一個broker會被選舉為controller,負責管理集群broker的上下線,所有topic的分區副本分配和leader選舉等工作
- controller的管理工作都是依賴於zookeeper的
3.6 kafka事務
- kafka從0.11版本開始引入了事務支持,事務可以保證kafka在Exactly Once語義的基礎上,生產和消費可以跨分區會話,要么全部成功,要么全部失敗
3.6.1 producer事務
- 為了實現跨分區跨會話的事務,需要引入一個全局唯一的Transaction ID,並將producer獲得的PID和Transaction ID綁定,這樣當producer重啟后就可以通過正在進行的Transaction ID獲得原來的ID
- 為了管理Transaction,kafka引入了一個新的組件Transaction Coordinator,producer就是通過和Transaction Coordinator交互獲得Transaction ID對應的任務狀態,Transaction Coordinator還負責將事務所有寫入kafka的一個內部topic,這樣即使整個服務重啟,由於事務狀態得到保存,進行中的事務狀態可以得到恢復,從而繼續運行
3.6.2 consumer事務
- 上述事務機制主要是從producer方面考慮,對於consumer而言,事務的保證就會相對較弱,尤其無法保證commit的信息被精確消費,這是由於consumer可以通過offset訪問任意消息,而且不同的segmentFile生命周期不同,同一事務的消息可能會出現重啟后被刪除的情況
第四章 kafka監控
4.1 kafka Eagle
-
修改kafka啟動命令
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-server -Xms1G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70" export JMX_PORT="9999" fi #修改后需要分發到其他節點 -
上傳壓縮包到集群/opt/src目錄,並解壓
[xiaoyao@hadoop102 src]$ ls apache-zookeeper-3.5.9-bin.tar.gz hadoop-3.2.2.tar.gz jdk-8u291-linux-x64.tar.gz kafka_2.10-0.10.2.1.tgz kafka-eagle-bin-2.0.1.tar.gz sdimage.xml [xiaoyao@hadoop102 module]$ ll 總用量 4 drwxr-xr-x. 13 xiaoyao xiaoyao 4096 6月 28 00:08 hadoop-3.2.2 drwxr-xr-x. 8 xiaoyao xiaoyao 273 4月 8 03:26 jdk1.8.0_291 drwxr-xr-x. 8 xiaoyao xiaoyao 113 8月 1 18:05 kafka drwxrwxr-x. 3 xiaoyao xiaoyao 65 8月 16 16:09 kafka-eagle drwxrwxr-x. 8 xiaoyao xiaoyao 158 8月 1 18:29 zookeeper -
配置環境變量
export KE_HOME=/opt/module/kafka-eagle export PATH=$PATH:$KE_HOME/bin -
修改配置文件
kafka.eagle.zk.cluster.alias=cluster1 cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181 cluster1.zk.acl.enable=false cluster1.zk.acl.schema=digest cluster1.zk.acl.username=test cluster1.zk.acl.password=test123 cluster1.kafka.eagle.broker.size=20 kafka.zk.limit.size=25 kafka.eagle.webui.port=8048 cluster1.kafka.eagle.offset.storage=kafka #根據kafka版本配置 kafka.eagle.metrics.charts=true kafka.eagle.metrics.retain=15 kafka.eagle.sql.topic.records.max=5000 kafka.eagle.sql.fix.error=true kafka.eagle.topic.token=keadmin kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://192.168.10.102:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull kafka.eagle.username=root kafka.eagle.password=123456 -
啟動服務
#啟動之前先啟動zk和kafka [xiaoyao@hadoop102 kafka-eagle]$ ke.sh start * Kafka Eagle Service has started success. * Welcome, Now you can visit 'http://192.168.10.102:8048' * Account:admin ,Password:123456
第五章 總結
-
kafka消息數據積壓,kafka消費能力不足怎么處理
- 如果是kafka消費能力不足,則可以考慮增加topic的分區數,並且同時提升消費者組的消費者數量,消費者數=分區數(兩者缺一不可)
- 如果是下游的數據處理不及時:提高每批次拉取的數量,批次拉取數據過少(拉取數據/處理時間<生產速度),使處理的數據小於生產的數據,也會造成數據積壓
-
Leader 總是 -1,怎么破?
-
在生產環境中,你一定碰到過“某個主題分區不能工作了”的情形。使用命令行查看狀態的 話,會發現 Leader 是 -1,於是,你使用各種命令都無濟於事,最后只能用“重啟大 法”。
-
但是,有沒有什么辦法,可以不重啟集群,就能解決此事呢?
-
刪除 ZooKeeper 節點 /controller,觸發 Controller 重選舉。 Controller 重選舉能夠為所有主題分區重刷分區狀態,可以有效解決因不一致導致的 Leader 不可用問題。
-