邏輯上,CUDA中所有thread是並行的,但是,從硬件的角度來說,實際上並不是所有的thread能夠在同一時刻執行,接下來我們將深入學習和了解有關warp的一些本質。
1. Warps & Thread Blocks
warp是SM的基本執行單元。一個warp包含32個並行thread,這32個thread執行於SIMT模式。也就是說所有thread執行同一條指令,並且每個thread會使用各自的data執行該指令。
block可以是1D、2D或者3D的,但是,從硬件角度看,所有的thread都被組織成一維的,每個thread都有個唯一的ID。每個block的warp數量可以由下面的公式計算獲得:
WarpPerBlock = ceil(ThreadPerBlock / warpSize)
一個warp中的線程必然在同一個block中,如果block所含線程數目不是warp大小的整數倍,那么多出的那些thread所在的warp中,會剩余一些inactive的thread,也就是說,即使湊不夠warp整數倍的thread,硬件也會為warp湊足,只不過那些thread是inactive狀態,需要注意的是,即使這部分thread是inactive的,也會消耗SM資源,這點是編程時應避免的。

2. Warp Divergence(warp分歧)
GPU支持傳統的、C-style的顯式控制流結構,例如if…else,for,while等等。但和CPU對比來說,GPU沒有復雜的分支預測。
這樣問題就來了,因為所有同一個warp中的thread必須執行相同的指令,那么如果這些線程在遇到控制流語句時,如果進入不同的分支,那么同一時刻除了正在執行的分支外,其余分支都被阻塞了,十分影響性能。這類問題就是warp divergence。
注意,warp divergence問題只會發生在同一個warp中。 下圖展示了warp divergence問題:

為了獲得最好的性能,就需要避免同一個warp存在不同的執行路徑。避免該問題的方法很多,比如這樣一個情形,假設有兩個分支,分支的決定條件是thread的唯一ID的奇偶性,kernel函數如下:
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if (tid % 2 == 0)
a = 100.0f;
else
b = 200.0f;
c[tid] = a + b;
}
一種方法是,將條件改為以warp大小為步調,然后取奇偶,代碼如下:
__global__ void mathKernel2(void)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a, b;
a = b = 0.0f;
if ((tid / warpSize) % 2 == 0)
a = 100.0f;
else
b = 200.0f;
c[tid] = a + b;
}
通過測試發現兩個kernel函數性能相近,到這里你應該在奇怪為什么二者表現相同呢,實際上是因為當我們的代碼很簡單,可以被預測時,CUDA的編譯器會自動幫助優化我們的代碼。(稍微提一下GPU分支預測,這里一個被稱為預測變量的東西會被設置成1或者0,所有分支都會執行,但是只有預測變量值為1時,該分支才會得到執行。當條件狀態少於某一個閾值時,編譯器會將一個分支指令替換為預測指令。)因此,現在回到自動優化問題,一段較長的代碼就可能會導致warp divergence問題了。
可以使用下面的命令強制編譯器不做優化:
$ nvcc -g -G -arch=sm_20 program.cu -o program
3. Resource Partitioning(資源划分)
一個warp的context包括以下三部分:
1 Program counter
2 Register
3 Shared memory
同一個warp執行context切換是沒有消耗的,因為在整個warp的生命期內,SM處理的每個warp的執行context都是“on-chip”的。
每個SM有一個32位register集合放在register file中,還有固定數量的shared memory,這些資源都被thread瓜分了,由於資源是有限的,所以,如果thread數量比較多,那么每個thread占用資源就比較少,反之如果thread數量較少,每個thread占用資源就較多,這需要根據自己的需求作出一個平衡。
資源限制了駐留在SM中blcok的數量,不同的GPU,register和shared memory的數量也不同,就像Fermi和Kepler架構的差別。如果沒有足夠的資源,kernel的啟動就會失敗。
當一個block獲得到足夠的資源時,就成為active block。block中的warp就稱為active warp。active warp又可以被分為下面三類:
1 Selected warp
2 Stalled warp
3 Eligible warp
SM中warp調度器每個cycle會挑選active warp送去執行,一個被選中的warp稱為Selected warp,沒被選中,但是已經做好准備被執行的稱為Eligible warp,沒准備好要被執行的稱為Stalled warp.
warp適合執行需要滿足下面兩個條件:
1 32個CUDA core有空
2 所有當前指令的參數都准備就緒
例如,Kepler架構GPU任何時刻的active warp數目必須少於或等於64個。selected warp數目必須小於或等於4個(因為scheduler有4個?不確定,至於4個是不是太少則不用擔心,kernel啟動前,會有一個warmup操作,可以使用cudaFree()來實現)。如果一個warp阻塞了,調度器會挑選一個Eligible warp准備去執行。
CUDA編程中應該重視對計算資源的分配:這些資源限制了active warp的數量。因此,我們必須掌握硬件的一些限制,為了最大化GPU利用率,我們必須最大化active warp的數目。
4. Latency Hiding(延遲隱藏)
指令從開始到結束消耗的clock cycle稱為指令的latency。當每個cycle都有eligible warp被調度時,計算資源就會得到充分利用,基於此,我們就可以將每個指令的latency隱藏於issue其它warp的指令的過程中。
和CPU編程相比,latency hiding對GPU非常重要。CPU cores被設計成可以最小化一到兩個thread的latency,但是GPU的thread數目可不是一個兩個那么簡單。
當涉及到指令latency時,指令可以被區分為下面兩種:
1 Arithmetic instruction
2 Memory instruction
顧名思義,Arithmetic instruction latency是一個算術操作的始末間隔。另一個則是指load或store的始末間隔。二者的latency大約為:
1 10-20 cycle for arithmetic operations
2 400-800 cycles for global memory accesses
下圖是一個簡單的執行流程,當warp0阻塞時,執行其他的warp,當warp變為eligible時從新執行。

你可能想要知道怎樣評估active warps 的數量來hide latency。Little’s Law可以提供一個合理的估計:
NumberofRequiredWarps = Latency * Throughput
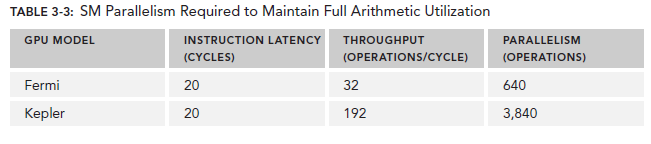
對於Arithmetic operations來說,並行性可以表達為用來hide Arithmetic latency的操作的數目。下表顯示了Fermi和Kepler相關數據,這里是以(a + b * c)作為操作的例子。不同的算數指令,throughput(吞吐)也是不同的。
因為memory throughput總是以GB/Sec為單位,我們需要先作相應的轉化。可以通過下面的指令來查看device的memory frequency:
$ nvidia-smi -a -q -d CLOCK | fgrep -A 3 "Max Clocks" | fgrep "Memory"
以Fermi為例,其memory frequency可能是1.566GHz,Kepler的是1.6GHz。那么轉化過程為:

乘上這個92可以得到上圖中的74,這里的數字是針對整個device的,而不是每個SM。
有了這些數據,我們可以做一些計算了,以Fermi為例,假設每個thread的任務是將一個float(4 bytes)類型的數據從global memory移至SM用來計算,你應該需要大約18500個thread,也就是579個warp來隱藏所有的memory latency。

Fermi有16個SM,所以每個SM需要579/16=36個warp來隱藏memory latency。
Occupancy(占用率)
當一個warp阻塞了,SM會執行另一個eligible warp。理想情況是,每時每刻到保證cores被占用。Occupancy就是每個SM的active warp占最大warp數目的比例:

們可以使用cuda庫函數的方法來獲取warp最大數目:
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device);
然后用maxThreadsPerMultiProcessor來獲取具體數值。
grid和block的配置准則:
- 保證block中thread數目是32的倍數
- 避免block太小:每個blcok最少128或256個thread
- 根據kernel需要的資源調整block
- 保證block的數目遠大於SM的數目
- 多做實驗來挖掘出最好的配置
Occupancy專注於每個SM中可以並行的thread或者warp的數目。不管怎樣,Occupancy不是唯一的性能指標,當Occupancy達到某個值時,再做優化就可能不再有效果了,還有許多其它的指標需要調節
6、Synchronize(同步)
同步是並行編程中的一個普遍問題。在CUDA中,有兩種方式實現同步:
1. System-level:等待所有host和device的工作完成
2. Block-level:等待device中block的所有thread執行到某個點
-
cudaDeviceSynchronize
因為CUDA API和host代碼是異步的,cudaDeviceSynchronize() 可以用來停下CPU等待CUDA中的操作完成:
cudaError_t cudaDeviceSynchronize(void);
-
synchreads
因為block中的thread執行順序不定,CUDA提供了一個函數來同步block中的thread。
__synchreads() 函數可以確保同一線程塊內的所有線程保持同步,但是不能確保不同線程塊直接的線程同步。一個warp內的線程不需要同步;調用一次__synchreads() 至少需要四個時鍾周期,一般需要更多時鍾周期,應盡量避免使用。
-
memory fence
不保證所有線程運行到同一位置,只保證執行memory fence函數的線程生產的數據能夠安全得被其他線程消費;
__threadfence() :一個線程調用該函數后,該線程在該語句前對全局存儲器或者共享存儲器的訪問已經全部完成,執行結果對grid中的所有線程可見;
__threadfence__block() : 一個線程調用該函數后,該線程在該語句前對全局存儲器或共享存儲器的訪問已經全部完成,執行結果對block中所有線程可見;
7. Bank Conflict
對於同一個wrap中的線程(一個wrap內包含了32個線程),訪問共享存儲器時,以half-wrap的形式分兩次訪問。同一half-wrap內的線程同時可以訪問不同的bank,而不同線程對同一個bank 的訪問只能順序進行。
所謂的bank-conflict,就是同一half-wrap內的線程,訪問了同一bank里的共享內存。bank-conflict會讓原本並行的對共享內存的訪存操作變成串行從而極大的降低程序效率。 特殊情況是:half-wrap內所有的線程訪問同一個共享內存中的同一地址,會產生一次廣播,在這種情況下不會發生bank conflict。
下面有一些小技巧可以避免bank conflict 或者提高global存儲器的訪問速度
1. 盡量按行操作,需要按列操作時可以先對矩陣進行轉置
2. 划分子問題時,使每個block處理的問題寬度恰好為16的整數倍,使得訪存可以按照 s_data[tid]=i_data[tid]的形式進行
3. 使用對齊的數據格式,盡量使用nvidia定義的格式如float3,int2等,這些格式本身已經對齊。
4. 當要處理的矩陣寬度不是16的整數倍時,將其補為16的整數倍,或者用malloctopitch而不是malloc。
5. 利用廣播,例如s_odata[tid] = tid%16 < 8 ? s_idata[tid] : s_idata[15];會產生8路的塊訪問沖突而用:s_odata[tid]=s_idata[15];s_odata[tid]= tid%16 < 8 ? s_idata[tid] : s_odata[tid]; 則不會產生塊訪問沖突