感謝您的關注 + 點贊 + 再看,對博主的肯定,會督促博主持續的輸出更多的優質實戰內容!!!

1.序篇-本文結構
-
背景篇-為啥需要 redis 維表
-
目標篇-做 redis 維表的預期效果是什么
-
難點剖析篇-此框架建設的難點、目前有哪些實現
-
維表實現篇-維表實現的過程
-
總結與展望篇
本文主要介紹了 flink sql redis 維表的實現過程。
如果想在本地測試下:

大數據羊說
用數據提升美好事物發生的概率~
29篇原創內容
公眾號
-
在公眾號后台回復flink sql 知其所以然(二)| sql 自定義 redis 數據維表獲取源碼(源碼基於 1.13.1 實現)
-
在你的本地安裝並打開 redis-server,然后使用 redis-cli 執行命令
set a "{\"score\":3,\"name\":\"namehhh\",\"name1\":\"namehhh112\"}" -
執行源碼包中的
flink.examples.sql._03.source_sink.RedisLookupTest測試類,就可以在 console 中看到結果。
如果想直接在集群環境使用:
-
命令行執行
mvn package -DskipTests=true打包 -
將生成的包
flink-examples-0.0.1-SNAPSHOT.jar引入 flink lib 中即可,無需其它設置。
2.背景篇-為啥需要 redis 維表
2.1.啥是維表?事實表?
Dimension Table 概念多出現於數據倉庫里面,維表與事實表相互對應。
給兩個場景來看看:
比如需要統計分性別的 DAU:
-
客戶端上報的日志中(事實表)只有設備 id,只用這個事實表是沒法統計出分性別的 DAU 的。
-
這時候就需要一張帶有設備 id、性別映射的表(這就是維表)來提供性別數據。
-
然后使用事實表去 join 這張維表去獲取到每一個設備 id 對應的性別,然后就可以統計出分性別的 DAU。相當於一個擴充維度的操作。
https://blog.csdn.net/weixin_47482194/article/details/105855116?spm=1001.2014.3001.5501
比如目前想要統計整體銷售額:
-
目前已有 “銷售統計表”,是一個事實表,其中沒有具體銷售品項的金額。
-
“商品價格表” 可以用於提供具體銷售品項的金額,這就是銷售統計的一個維度表。
事實數據和維度數據的識別必須依據具體的主題問題而定。“事實表” 用來存儲事實的度量及指向各個維的外鍵值。維表用來保存該維的元數據。
參考:https://blog.csdn.net/lindan1984/article/details/96566626
2.2.為啥需要 redis 維表?
目前在實時計算的場景中,熟悉 datastream 的同學大多數都使用過 mysql\Hbase\redis 作為維表引擎存儲一些維度數據,然后在 datastream api 中調用 mysql\Hbase\redis 客戶端去獲取到維度數據進行維度擴充。
而 redis 作為 flink 實時場景中最常用的高速維表引擎,官方是沒有提供 flink sql api 的 redis 維表 connector 的。如下圖,基於 1.13 版本。
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/table/overview/

1
阿里雲 flink 是提供了這個能力的。但是這個需要使用阿里雲的產品才能使用。有錢人可以直接上。
https://www.alibabacloud.com/help/zh/faq-detail/122722.htm?spm=a2c63.q38357.a3.7.a1227a53TBMuSY

2
因此本文在介紹怎樣自定義一個 sql 數據維表的同時,實現一個 sql redis 來給大家使用。
3.目標篇-做 redis 維表預期效果是什么
redis 作為維表在 datastream 中的最常用的數據結構就是 kv、hmap 兩種。本文實現主要實現 kv 結構,map 結構大家可以拿到源碼之后進行自定義實現。也就多加幾行代碼就完事了。
預期效果就如阿里雲的 flink redis:
下面是我在本地跑的結果,先看看 redis 中存儲的數據,只有這一條數據,是 json 字符串:

9
下面是預期 flink sql:
CREATE TABLE dimTable (
name STRING,
name1 STRING,
score BIGINT -- redis 中存儲數據的 schema
) WITH (
'connector' = 'redis', -- 指定 connector 是 redis 類型的
'hostname' = '127.0.0.1', -- redis server ip
'port' = '6379', -- redis server 端口
'format' = 'json' -- 指定 format 解析格式
'lookup.cache.max-rows' = '500', -- guava local cache 最大條目
'lookup.cache.ttl' = '3600', -- guava local cache ttl
'lookup.max-retries' = '1' -- redis 命令執行失敗后重復次數
)
SELECT o.f0, o.f1, c.name, c.name1, c.score
FROM leftTable AS o
-- 維表 join
LEFT JOIN dimTable FOR SYSTEM_TIME AS OF o.proctime AS c
ON o.f0 = c.name
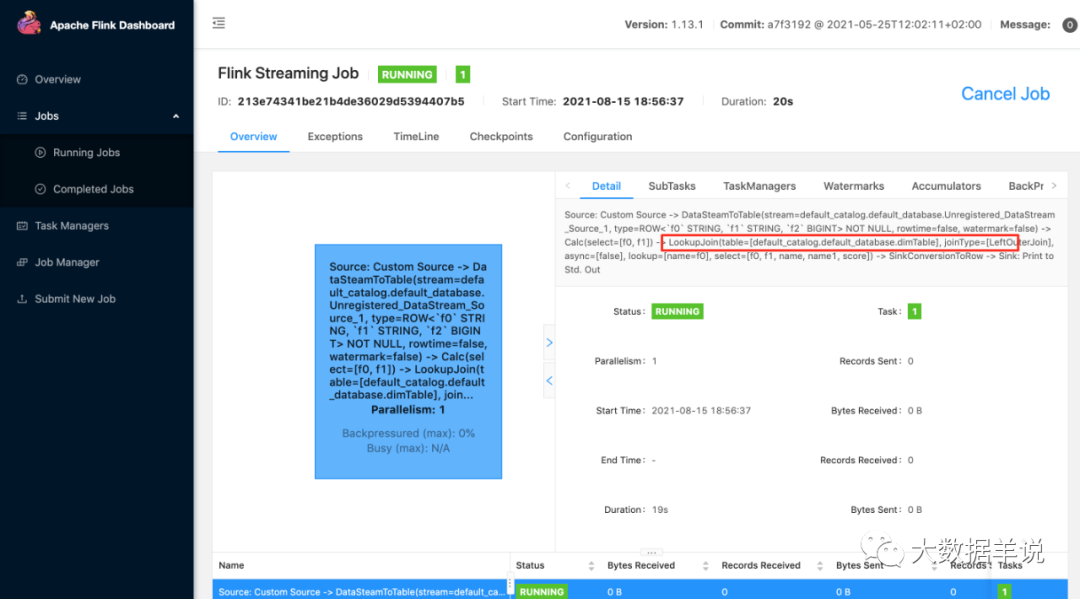
10
結果如下,后面三列就對應到 `c.name, c.name1, c.score`:
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
+I[a, b, namehhh, namehhh112, 3]
4.難點剖析篇-目前有哪些實現
===============
目前可以從網上搜到的實現、以及可以參考的實現有以下兩個:
1. https://github.com/jeff-zou/flink-connector-redis。但是其沒有實現 flink sql redis 維表,只實現了 sink 表,並且使用起來有比較多的限制,包括需要在建表時就指定 key-column,value-column 等,其實博主覺得沒必要指定這些字段,這些都可以動態調整。其實現是對 apache-bahir-flink https://github.com/apache/bahir-flink 的二次開發,但與 bahir 原生實現有割裂感,因為這個項目幾乎重新實現了一遍,接口也和 bahir 不同。
2. 阿里雲實現 https://www.alibabacloud.com/help/zh/faq-detail/122722.htm?spm=a2c63.q38357.a3.7.a1227a53TBMuSY。可以參考的只有用法和配置等。但是有些配置項也屬於阿里自定義的。
因此博主在實現時,就定了一個基調。
1. 復用 connector:復用 bahir 提供的 redis connnector
2. 復用 format:復用 flink 目前的 format 機制,目前這個上述兩個實現都沒有做到
3. 簡潔性:實現 kv 結構。hget 封裝一部分
4. 維表 local cache:為避免高頻率訪問 redis,維表加了 local cache 作為緩存
5.維表實現篇-維表實現的過程
===============
在實現 redis 維表之前,不得不談談 flink 維表加載和使用機制。
5.1.flink 維表原理
--------------
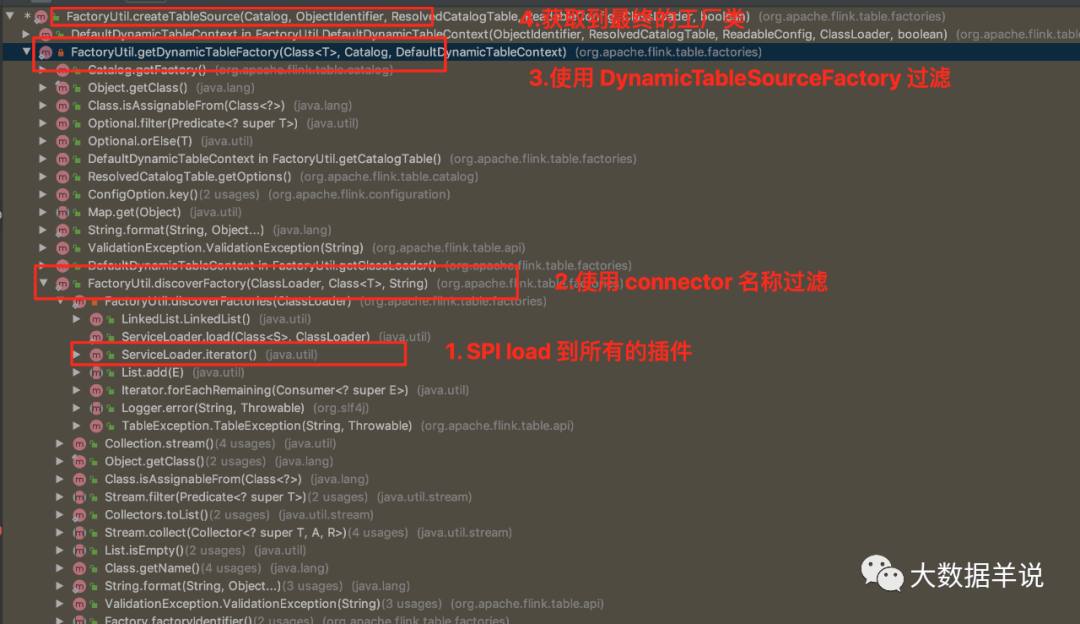
其實上節已經詳細描述了 flink sql 對於 source\\sink 的加載機制,維表屬於 source 的中的 lookup 表,在具體 flink 程序運行的過程之中可以簡單的理解為一個 map,在 map 中調用 redis-client 接口訪問 redis 進行擴充維度的過程。
1. 通過 SPI 機制加載所有的 source\\sink\\format 工廠 `Factory`
2. 過濾出 DynamicTableSourceFactory + connector 標識的 source 工廠類
3. 通過 source 工廠類創建出對應的 source
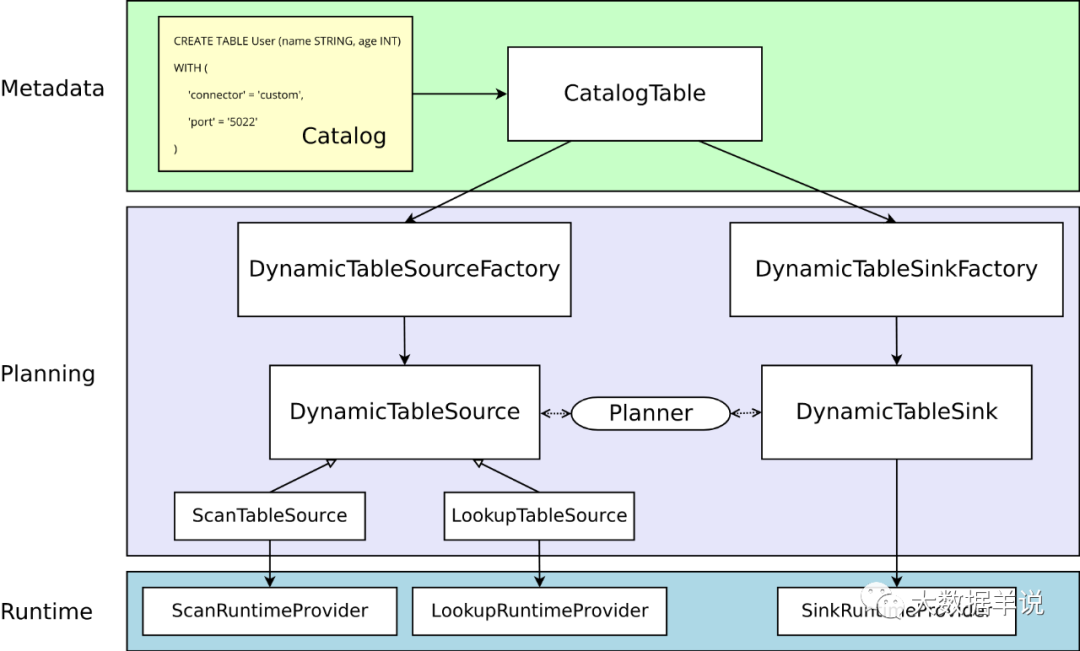
7
5
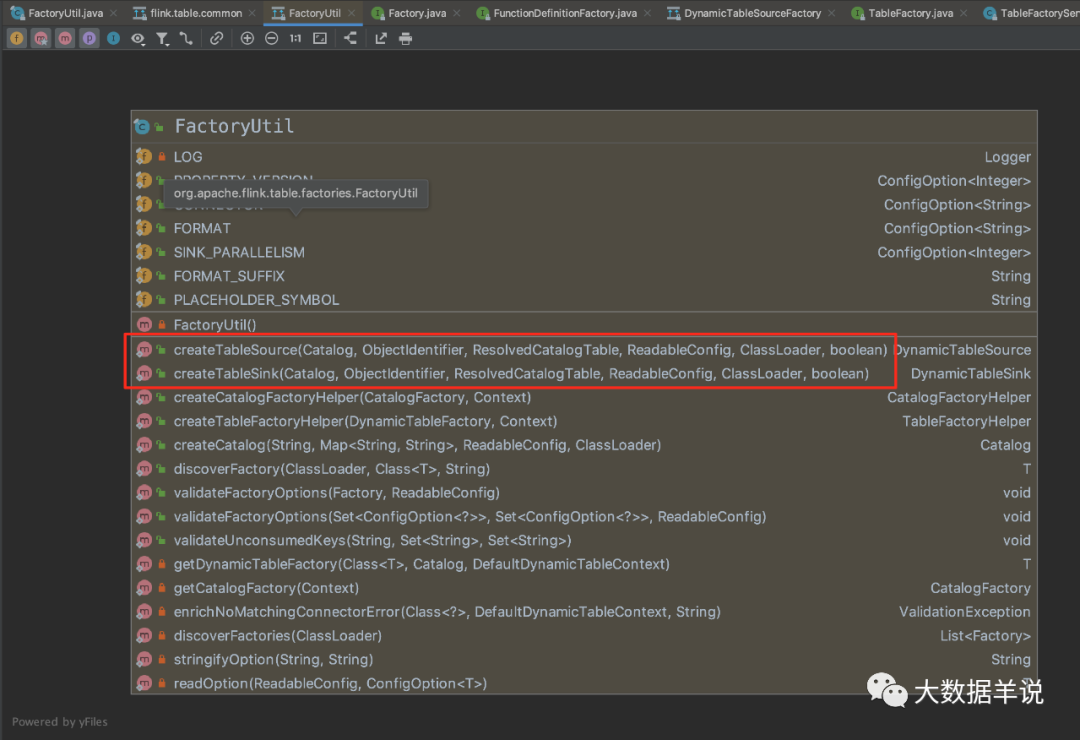
如圖 source 和 sink 是通過 `FactoryUtil.createTableSource` 和 `FactoryUtil.createTableSink` 創建的
4
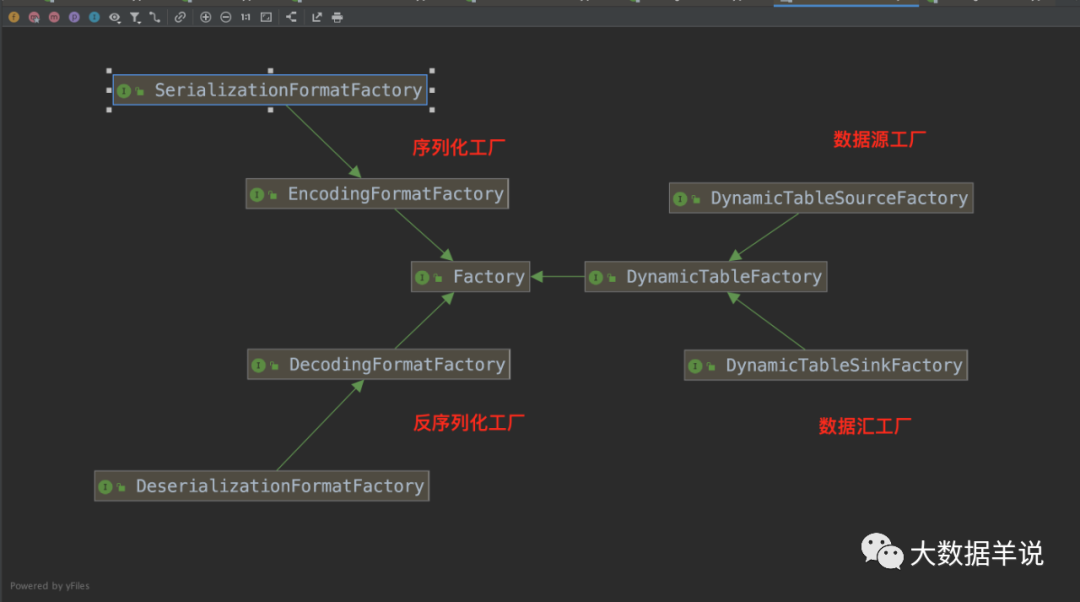
所有通過 SPI 的 source\\sink\\formt 插件都繼承自 `Factory`。
整體創建 source 方法的調用鏈如下圖。
6
5.2.flink 維表實現方案
----------------
先看下博主的最終實現。
總重要的三個實現類:
1. `RedisDynamicTableFactory`
2. `RedisDynamicTableSource`
3. `RedisRowDataLookupFunction`
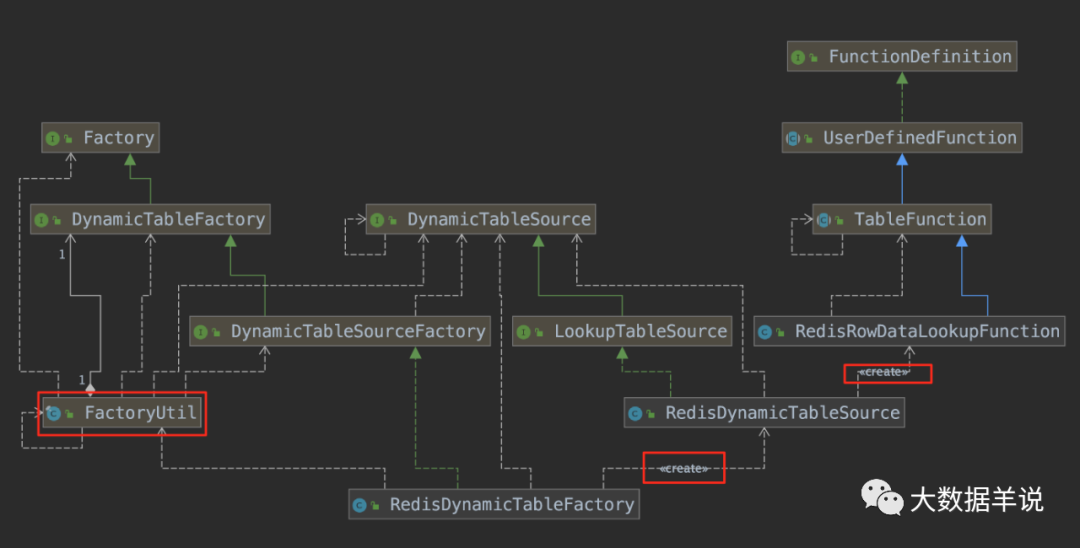
8
具體流程:
1. 定義 SPI 的工廠類 `RedisDynamicTableFactory implements DynamicTableSourceFactory`,並且在 resource\\META-INF 下創建 SPI 的插件文件
2. 實現 factoryIdentifier 標識 `redis`
3. 實現 `RedisDynamicTableFactory#createDynamicTableSource` 來創建對應的 source `RedisDynamicTableSource`
4. 定義 `RedisDynamicTableSource implements LookupTableSource`
5. 實現 `RedisDynamicTableFactory#getLookupRuntimeProvider` 方法,創建具體的維表 UDF `TableFunction<T>`,定義為 `RedisRowDataLookupFunction`
6. 實現 `RedisRowDataLookupFunction` 的 eval 方法,這個方法就是用於訪問 redis 擴充維度的。
介紹完流程,進入具體實現方案細節:
`RedisDynamicTableFactory` 主要創建 source 的邏輯:
public class RedisDynamicTableFactory implements DynamicTableSourceFactory {
...
@Override
public String factoryIdentifier() {
// 標識 redis
return "redis";
}
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// either implement your custom validation logic here ...
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// discover a suitable decoding format
// format 實現
final DecodingFormat<DeserializationSchema
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
// validate all options
// 所有 option 配置的校驗,比如 cache 類參數
helper.validate();
// get the validated options
final ReadableConfig options = helper.getOptions();
final RedisLookupOptions redisLookupOptions = RedisOptions.getRedisLookupOptions(options);
TableSchema schema = context.getCatalogTable().getSchema();
// 創建 RedisDynamicTableSource
return new RedisDynamicTableSource(
schema.toPhysicalRowDataType()
, decodingFormat
, redisLookupOptions);
}
}
resources\\META-INF 文件:
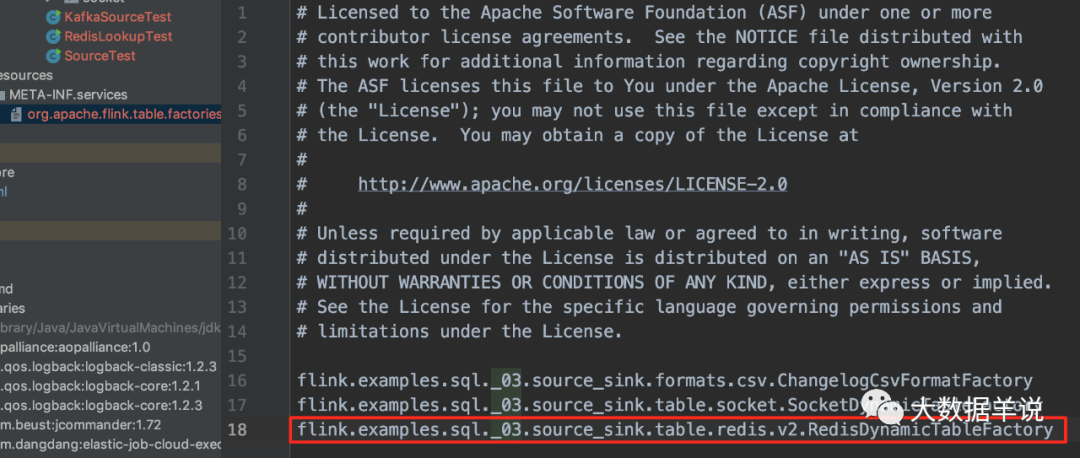
13
`RedisDynamicTableSource` 主要創建 table udf 的邏輯:
public class RedisDynamicTableSource implements LookupTableSource {
...
@Override
public LookupRuntimeProvider getLookupRuntimeProvider(LookupContext context) {
// 初始化 redis 客戶端配置
FlinkJedisConfigBase flinkJedisConfigBase = new FlinkJedisPoolConfig.Builder()
.setHost(this.redisLookupOptions.getHostname())
.setPort(this.redisLookupOptions.getPort())
.build();
// redis key,value 序列化器
LookupRedisMapper lookupRedisMapper = new LookupRedisMapper(
this.createDeserialization(context, this.decodingFormat, createValueFormatProjection(this.physicalDataType)));
// 創建 table udf
return TableFunctionProvider.of(new RedisRowDataLookupFunction(
flinkJedisConfigBase
, lookupRedisMapper
, this.redisLookupOptions));
}
}
`RedisRowDataLookupFunction` table udf 執行維表關聯的主要流程:
public class RedisRowDataLookupFunction extends TableFunction
...
/**
* 具體 redis 執行方法
*/
public void eval(Object... objects) throws IOException {
for (int retry = 0; retry <= maxRetryTimes; retry++) {
try {
// fetch result
this.evaler.accept(objects);
break;
} catch (Exception e) {
LOG.error(String.format("HBase lookup error, retry times = %d", retry), e);
if (retry >= maxRetryTimes) {
throw new RuntimeException("Execution of Redis lookup failed.", e);
}
try {
Thread.sleep(1000 * retry);
} catch (InterruptedException e1) {
throw new RuntimeException(e1);
}
}
}
}
@Override
public void open(FunctionContext context) {
LOG.info("start open ...");
// redis 命令執行器,初始化 redis 鏈接
try {
this.redisCommandsContainer =
RedisCommandsContainerBuilder
.build(this.flinkJedisConfigBase);
this.redisCommandsContainer.open();
} catch (Exception e) {
LOG.error("Redis has not been properly initialized: ", e);
throw new RuntimeException(e);
}
// 初始化 local cache
this.cache = cacheMaxSize <= 0 || cacheExpireMs <= 0 ? null : CacheBuilder.newBuilder()
.recordStats()
.expireAfterWrite(cacheExpireMs, TimeUnit.MILLISECONDS)
.maximumSize(cacheMaxSize)
.build();
if (cache != null) {
context.getMetricGroup()
.gauge("lookupCacheHitRate", (Gauge
this.evaler = in -> {
RowData cacheRowData = cache.getIfPresent(in);
if (cacheRowData != null) {
collect(cacheRowData);
} else {
// fetch result
byte[] key = lookupRedisMapper.serialize(in);
byte[] value = null;
switch (redisCommand) {
case GET:
value = this.redisCommandsContainer.get(key);
break;
case HGET:
value = this.redisCommandsContainer.hget(key, this.additionalKey.getBytes());
break;
default:
throw new IllegalArgumentException("Cannot process such data type: " + redisCommand);
}
RowData rowData = this.lookupRedisMapper.deserialize(value);
collect(rowData);
cache.put(key, rowData);
}
};
}
...
}
}
### 5.2.1.復用 bahir connector
如圖是 bahir redis connector 的實現。
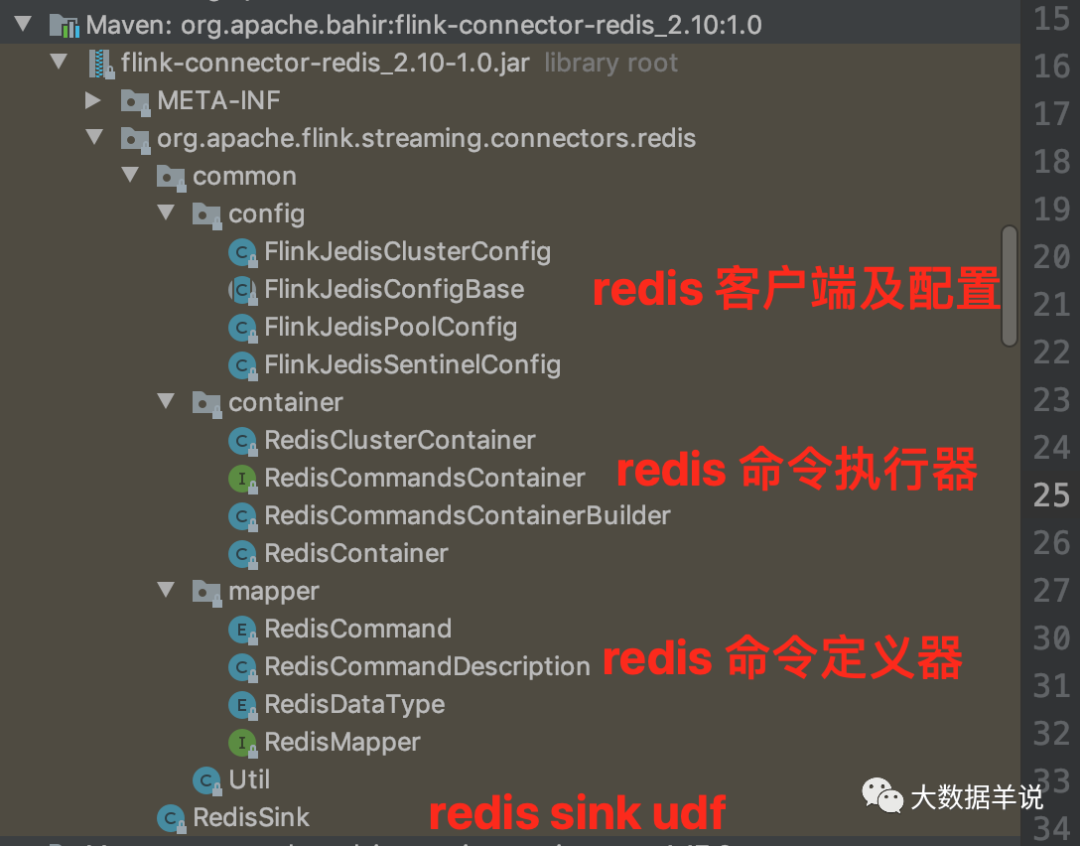
11
博主在實現過程中將能復用的都盡力復用。如圖是最終實現目錄。

12
可以看到目錄結構是與 bahir redis connector 一致的。
其中 `redis 客戶端及其配置` 是直接復用了 bahir redis 的。由於 bahir redis 基本都是 sink 實現,某些實現沒法繼承復用,所以這里我單獨開辟了目錄,`redis 命令執行器` 和 `redis 命令定義器`,但是也基本和 bahir 一致。如果你想要在生產環境中進行使用,可以直接將兩部分代碼合並,成本很低。
### 5.2.2.復用 format
博主直接復用了 flink 本身自帶的 format 機制來作為維表反序列化機制。參考 HBase connector 實現將 cache 命中率添加到 metric 中。
public class RedisDynamicTableFactory implements DynamicTableSourceFactory {
...
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
...
// discover a suitable decoding format
// 復用 format 實現
final DecodingFormat<DeserializationSchema
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
...
}
}
format 同樣也是 SPI 機制加載。
源碼公眾號后台回復**flink sql 知其所以然(二)| sql 自定義 redis 數據維表**獲取。
5.2.3.維表 local cache
--------------------
local cache 在初始化時可以指定 cache 大小,緩存時長等。
this.evaler = in -> {
RowData cacheRowData = cache.getIfPresent(in);
if (cacheRowData != null) {
collect(cacheRowData);
} else {
// fetch result
byte[] key = lookupRedisMapper.serialize(in);
byte[] value = null;
switch (redisCommand) {
case GET:
value = this.redisCommandsContainer.get(key);
break;
case HGET:
value = this.redisCommandsContainer.hget(key, this.additionalKey.getBytes());
break;
default:
throw new IllegalArgumentException("Cannot process such data type: " + redisCommand);
}
RowData rowData = this.lookupRedisMapper.deserialize(value);
collect(rowData);
cache.put(key, rowData);
}
};
6.總結與展望篇
========
6.1.總結
------
本文主要是針對 flink sql redis 維表進行了擴展以及實現,並且復用 bahir redis connector 的配置,具有良好的擴展性。如果你正好需要這么一個 connector,直接公眾號后台回復**flink sql 知其所以然(二)| sql 自定義 redis 數據維表**獲取源碼吧。
6.2.展望
------
當然上述只是 redis 維表一個基礎的實現,用於生產環境還有很多方面可以去擴展的。
1. jedis cluster 的擴展:目前 bahir datastream 中已經實現了,可以直接參考,擴展起來非常簡單
2. aync lookup 維表的擴展:目前 hbase lookup 表已經實現了,可以直接參考實現
3. 異常 AOP,alert 等

**大數據羊說**
用數據提升美好事物發生的概率~
29篇原創內容
公眾號
往期推薦
[
flink sql 知其所以然(一)| source\\sink 原理
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488486&idx=1&sn=b9bdb56e44631145c8cc6354a093e7c0&chksm=c1549f1ef623160834e3c5661c155ec421699fc18c57f2c63ba14d33bab1d37c5930fdce016b&scene=21#wechat_redirect)
[
揭秘字節跳動埋點數據實時動態處理引擎(附源碼)
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247488435&idx=1&sn=5d89a0d24603c08af4be342462409230&chksm=c1549f4bf623165d977426d13a0bdbe821ec8738744d2274613a7ad92dec0256d090aea4b815&scene=21#wechat_redirect)
[
字節火山大數據引擎牛逼!!!
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247487920&idx=1&sn=efdf259512e2a49606d240b50171ac09&chksm=c1549d48f623145ef91f5a25c8fdbd16b8f1086fadf738b3edeeaba85cc191d0f09ab2318604&scene=21#wechat_redirect)
[
實戰 | flink sql 與微博熱搜的碰撞!!!
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247487817&idx=1&sn=4c0192b0f495f39eaf9ea5a6f837844c&chksm=c1549db1f62314a771c6d1e6a17689b5b0826173fff372d5466f26e7e24f3a764e00ef0e622f&scene=21#wechat_redirect)
[
實時數倉不保障時效還玩個毛?
](http://mp.weixin.qq.com/s?__biz=MzkxNjA1MzM5OQ==&mid=2247487642&idx=1&sn=48547ee68b197f5d38a14e9af5c01798&chksm=c1549c62f6231574c940d0858feb9ff4eba884d7c4696a8a7ec77ae023b6e09cc8232680b788&scene=21#wechat_redirect)
**更多 Flink 實時大數據分析相關技術博文,視頻。后台回復 “flink” 獲取。**
點個贊+在看,感謝您的肯定 👇