1. Flink 的容錯機制(checkpoint)
Checkpoint機制是Flink可靠性的基石,可以保證Flink集群在某個算子因為某些原因(如 異常退出)出現故障時,能夠將整個應用流圖的狀態恢復到故障之前的某一狀態,保證應用流圖狀態的一致性。Flink的Checkpoint機制原理來自“Chandy-Lamport algorithm”算法。
每個需要Checkpoint的應用在啟動時,Flink的JobManager為其創建一個 CheckpointCoordinator(檢查點協調器),CheckpointCoordinator全權負責本應用的快照制作。
CheckpointCoordinator(檢查點協調器),CheckpointCoordinator全權負責本應用的快照制作。 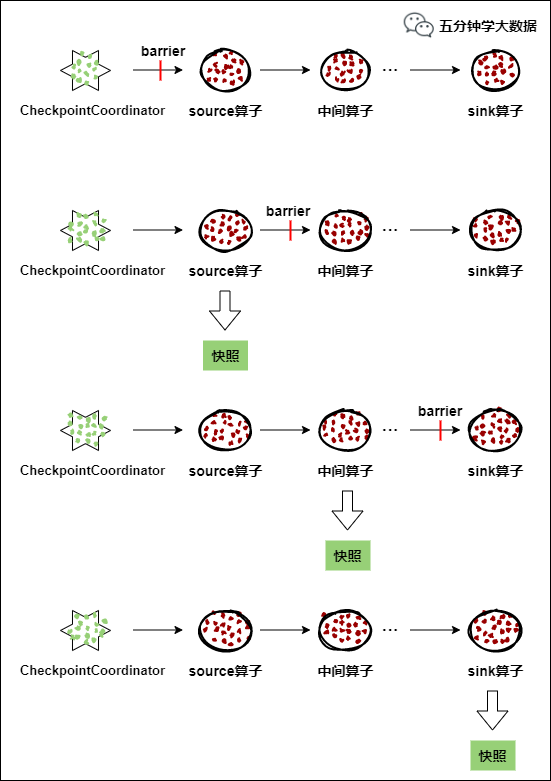
-
CheckpointCoordinator(檢查點協調器) 周期性的向該流應用的所有source算子發送 barrier(屏障)。
-
當某個source算子收到一個barrier時,便暫停數據處理過程,然后將自己的當前狀態制作成快照,並保存到指定的持久化存儲中,最后向CheckpointCoordinator報告自己快照制作情況,同時向自身所有下游算子廣播該barrier,恢復數據處理
-
下游算子收到barrier之后,會暫停自己的數據處理過程,然后將自身的相關狀態制作成快照,並保存到指定的持久化存儲中,最后向CheckpointCoordinator報告自身快照情況,同時向自身所有下游算子廣播該barrier,恢復數據處理。
-
每個算子按照步驟3不斷制作快照並向下游廣播,直到最后barrier傳遞到sink算子,快照制作完成。
-
當CheckpointCoordinator收到所有算子的報告之后,認為該周期的快照制作成功; 否則,如果在規定的時間內沒有收到所有算子的報告,則認為本周期快照制作失敗。
文章推薦:
2. Flink Checkpoint與 Spark 的相比,Flink 有什么區別或優勢嗎
Spark Streaming 的 Checkpoint 僅僅是針對 Driver 的故障恢復做了數據和元數據的 Checkpoint。而 Flink 的 Checkpoint 機制要復雜了很多,它采用的是輕量級的分布式快照,實現了每個算子的快照,及流動中的數據的快照。
3. Flink 中的 Time 有哪幾種
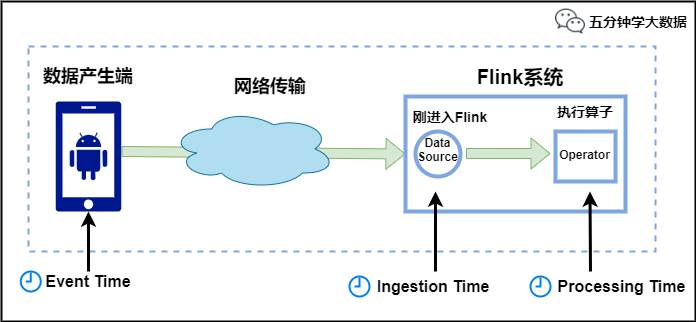
Flink中的時間有三種類型,如下圖所示:
-
Event Time:是事件創建的時間。它通常由事件中的時間戳描述,例如采集的日志數據中,每一條日志都會記錄自己的生成時間,Flink通過時間戳分配器訪問事件時間戳。
-
Ingestion Time:是數據進入Flink的時間。
-
Processing Time:是每一個執行基於時間操作的算子的本地系統時間,與機器相關,默認的時間屬性就是Processing Time。
例如,一條日志進入Flink的時間為2021-01-22 10:00:00.123,到達Window的系統時間為2021-01-22 10:00:01.234,日志的內容如下:
2021-01-06 18:37:15.624 INFO Fail over to rm2
對於業務來說,要統計1min內的故障日志個數,哪個時間是最有意義的?—— eventTime,因為我們要根據日志的生成時間進行統計。
4. 對於遲到數據是怎么處理的
Flink中 WaterMark 和 Window 機制解決了流式數據的亂序問題,對於因為延遲而順序有誤的數據,可以根據eventTime進行業務處理,對於延遲的數據Flink也有自己的解決辦法,主要的辦法是給定一個允許延遲的時間,在該時間范圍內仍可以接受處理延遲數據:
-
設置允許延遲的時間是通過allowedLateness(lateness: Time)設置
-
保存延遲數據則是通過sideOutputLateData(outputTag: OutputTag[T])保存
-
獲取延遲數據是通過DataStream.getSideOutput(tag: OutputTag[X])獲取
文章推薦:
Flink 中極其重要的 Time 與 Window 詳細解析
5. Flink 的運行必須依賴 Hadoop 組件嗎
Flink可以完全獨立於Hadoop,在不依賴Hadoop組件下運行。但是做為大數據的基礎設施,Hadoop體系是任何大數據框架都繞不過去的。Flink可以集成眾多Hadooop 組件,例如Yarn、Hbase、HDFS等等。例如,Flink可以和Yarn集成做資源調度,也可以讀寫HDFS,或者利用HDFS做檢查點。
6. Flink集群有哪些角色?各自有什么作用
有以下三個角色:
JobManager處理器:
也稱之為Master,用於協調分布式執行,它們用來調度task,協調檢查點,協調失敗時恢復等。Flink運行時至少存在一個master處理器,如果配置高可用模式則會存在多個master處理器,它們其中有一個是leader,而其他的都是standby。
TaskManager處理器:
也稱之為Worker,用於執行一個dataflow的task(或者特殊的subtask)、數據緩沖和data stream的交換,Flink運行時至少會存在一個worker處理器。
Clint客戶端:
Client是Flink程序提交的客戶端,當用戶提交一個Flink程序時,會首先創建一個Client,該Client首先會對用戶提交的Flink程序進行預處理,並提交到Flink集群中處理,所以Client需要從用戶提交的Flink程序配置中獲取JobManager的地址,並建立到JobManager的連接,將Flink Job提交給JobManager
7. Flink 資源管理中 Task Slot 的概念
在Flink中每個TaskManager是一個JVM的進程, 可以在不同的線程中執行一個或多個子任務。 為了控制一個worker能接收多少個task。worker通過task slot(任務槽)來進行控制(一個worker至少有一個task slot)。
8. Flink的重啟策略了解嗎
Flink支持不同的重啟策略,這些重啟策略控制着job失敗后如何重啟:
- 固定延遲重啟策略
固定延遲重啟策略會嘗試一個給定的次數來重啟Job,如果超過了最大的重啟次數,Job最終將失敗。在連續的兩次重啟嘗試之間,重啟策略會等待一個固定的時間。
- 失敗率重啟策略
失敗率重啟策略在Job失敗后會重啟,但是超過失敗率后,Job會最終被認定失敗。在兩個連續的重啟嘗試之間,重啟策略會等待一個固定的時間。
- 無重啟策略
Job直接失敗,不會嘗試進行重啟。
9. Flink 是如何保證 Exactly-once 語義的
Flink通過實現兩階段提交和狀態保存來實現端到端的一致性語義。分為以下幾個步驟:
開始事務(beginTransaction)創建一個臨時文件夾,來寫把數據寫入到這個文件夾里面
預提交(preCommit)將內存中緩存的數據寫入文件並關閉
正式提交(commit)將之前寫完的臨時文件放入目標目錄下。這代表着最終的數據會有一些延遲
丟棄(abort)丟棄臨時文件
若失敗發生在預提交成功后,正式提交前。可以根據狀態來提交預提交的數據,也可刪除預提交的數據。
文章推薦:
八張圖搞懂 Flink 端到端精准一次處理語義 Exactly-once
10. 如果下級存儲不支持事務,Flink 怎么保證 exactly-once
端到端的 exactly-once 對 sink 要求比較高,具體實現主要有冪等寫入和事務性寫入兩種方式。
冪等寫入的場景依賴於業務邏輯,更常見的是用事務性寫入。而事務性寫入又有預寫日志(WAL)和兩階段提交(2PC)兩種方式。
如果外部系統不支持事務,那么可以用預寫日志的方式,把結果數據先當成狀態保存,然后在收到 checkpoint 完成的通知時,一次性寫入 sink 系統。
11. Flink是如何處理反壓的
Flink 內部是基於 producer-consumer 模型來進行消息傳遞的,Flink的反壓設計也是基於這個模型。Flink 使用了高效有界的分布式阻塞隊列,就像 Java 通用的阻塞隊列(BlockingQueue)一樣。下游消費者消費變慢,上游就會受到阻塞。
12. Flink中的狀態存儲
Flink在做計算的過程中經常需要存儲中間狀態,來避免數據丟失和狀態恢復。選擇的狀態存儲策略不同,會影響狀態持久化如何和 checkpoint 交互。Flink提供了三種狀態存儲方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
13. Flink是如何支持流批一體的
這道題問的比較開闊,如果知道Flink底層原理,可以詳細說說,如果不是很了解,就直接簡單一句話:Flink的開發者認為批處理是流處理的一種特殊情況。批處理是有限的流處理。Flink 使用一個引擎支持了 DataSet API 和 DataStream API。
14. Flink的內存管理是如何做的
Flink 並不是將大量對象存在堆上,而是將對象都序列化到一個預分配的內存塊上。此外,Flink大量的使用了堆外內存。如果需要處理的數據超出了內存限制,則會將部分數據存儲到硬盤上。Flink 為了直接操作二進制數據實現了自己的序列化框架。
15. Flink CEP 編程中當狀態沒有到達的時候會將數據保存在哪里
在流式處理中,CEP 當然是要支持 EventTime 的,那么相對應的也要支持數據的遲到現象,也就是watermark的處理邏輯。CEP對未匹配成功的事件序列的處理,和遲到數據是類似的。在 Flink CEP的處理邏輯中,狀態沒有滿足的和遲到的數據,都會存儲在一個Map數據結構中,也就是說,如果我們限定判斷事件序列的時長為5分鍾,那么內存中就會存儲5分鍾的數據,這在我看來,也是對內存的極大損傷之一。
文章推薦: