最近在做人群計數的實驗,發現一篇總結很詳細的綜述文章《CNN-based Density Estimation and Crowd Counting: A Survey》,論文地址是 https://arxiv.org/pdf/2003.12783.pdf
本文內容參考自該綜述,總結了其中提到的部分網絡和其他人群計數的相關研究,包括損失函數設計評價指標等。
另一個學習人群計數很好的資源項目是c3f,地址是https://github.com/gjy3035/C-3-Framework,另一個很好的學習資源是同作者的awesome總結 https://github.com/gjy3035/Awesome-Crowd-Counting
c3F實現了一些較知名的人群計數算法,從數據集的處理到模型搭建到指標評價,代碼寫的很友好詳細。Awesome-crowd也在持續更新人群計數的最新進展。
相關工作
早期基於檢測的工作:
通過聚類檢測進行人群計數 《Counting people by clustering person detector outputs》
通過背景分割與頭-肩檢測進行計數《Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection》
密集場景的行人檢測 《Pedestrian detection in crowded scenes》
行人檢測 《Monocular pedestrian detection: Survey and experiments》
大多通過滑窗的方式進行頭部或者肩部的檢測。其余通用目標檢測結構,在稀疏場景效果好,但密集人群,遮擋和背景混亂時效果很差。
升級: 基於回歸的檢測,直接學習圖像到目標數量的映射。如Privacy preserving
crowd monitoring: Counting people without people models or tracking, 《Multi-source multi-
scale counting in extremely dense crowd images》,《Bayesian poisson regression for crowd counting》。他們提取全局特征,如紋理、漸變、邊緣或者局部特征SIFT LBP HOG GLCM。然后利用線性回歸或者高斯回歸進行學習特征到數量的映射。
采用密度估計的方法:回歸的方法解決了遮擋問題,但是忽略了空間信息,《Learning to count objects in image》學習局部特征到密度圖的線性映射,首次提出基於密度估計的方法。解決線性映射的困難,《Deep people counting in extremely dense crowds》提出非線性映射。這些方法都是手工特征。所以后面cnn的發展,自動提取特征。
cnn的方法: 早期的模型使用簡單的cnn預測密度圖,如《Deep people counting in extremely dense crowds》、《Fast crowd density estimation with convolutional neural networks》、《Cross-scene crowd counting via deep convolutional neural networks》,相比傳統手工特征提升巨大。最近主流是基於全連接網絡。
具有代表性的網絡
分為三類: 傳統cnn結構、 多列、單列
傳統cnn結構
即卷積+池化+全連接三大塊組合而成,而無其他信息。
《Fast crowd density estimation with convolutional neural networks》2015是第一篇引入CNN的人群計數論文,使用兩個級聯conv-net完成,
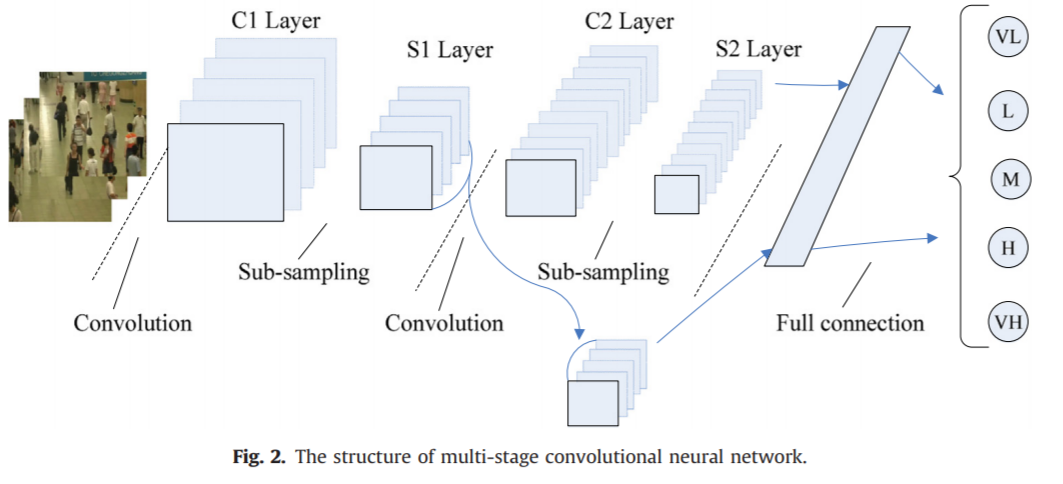
《Deep people counting in extremely dense crowds》2015基於AlexNet實現一個深層的人群計數網絡,使用的技巧包括將原圖裁剪、翻轉生成大量小的patches,而不是直接喂入原圖像。
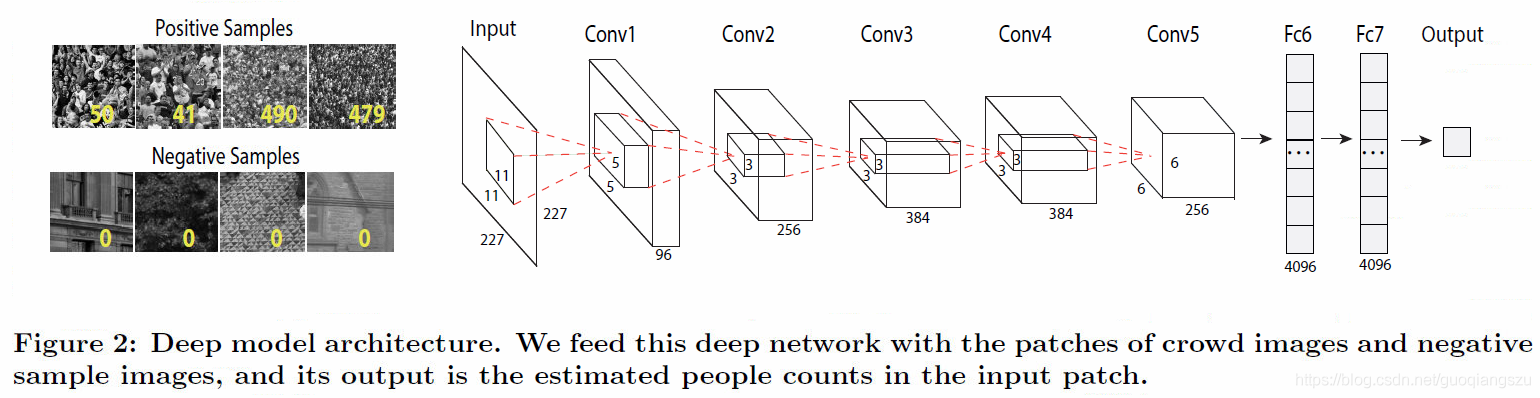
《Learning to count with cnn boosting》2016,利用組合學習的boosting算法,使用了分層增強和選擇性采樣來提高計數准確性並減少訓練時間。
上面這些都是基本的cnn結構,即卷積池化疊加的結構,全連接輸出,效果不是很好,后來發展出多列的結構。
多列結構
多列結構是使用不同列捕獲不同尺度的信息,從而提高精度。
《Single-image crowd counting via multi-column convolutional neural network》cvpr2016,
是第一篇使用多列結構的人群計數網絡,它受MDNN的啟發,有三個結構和深度都相同的分支,只是卷積的大小不同,最后組合,生成密度圖,而不是輸出統計的數字。三個分支捕獲不同尺度信息,但是三個分支太相似,而且很淺,整個結果看來只是幾個弱回歸變量的組合,效果不是很好。
另外,第一篇使用密度圖輸出的計數論文是2010年的《Learning To Count Objects in Images》。

《Towards perspective-free object counting with deep learning》
該論文兩個要點:提出了一個 novel convolutional neural network:Counting CNN (CCNN),將圖像塊回歸到密度圖,; 提出Hydra CNN,學習多尺度非線性回歸的計數模型。


Hydra網絡的輸入是patches的金字塔,金字塔的每一層都重設到固定大小然后輸入。
《Crowdnet: A deep convolutional network for dense crowd counting》2016,
Crowdnet的輸入分別進入兩個網絡,一個deep netweork是類似vgg的結構,去掉了全連接,是一個全卷積的結構,該部分卷積核小,捕獲高級語義信息,另一部分shallow network,卷積核大,檢測距離相機視角遠的人頭,最后concat兩個部分的輸出,使用1x1卷積輸出,雙線性插值恢復到原圖像尺寸,即為圖像的特征圖。

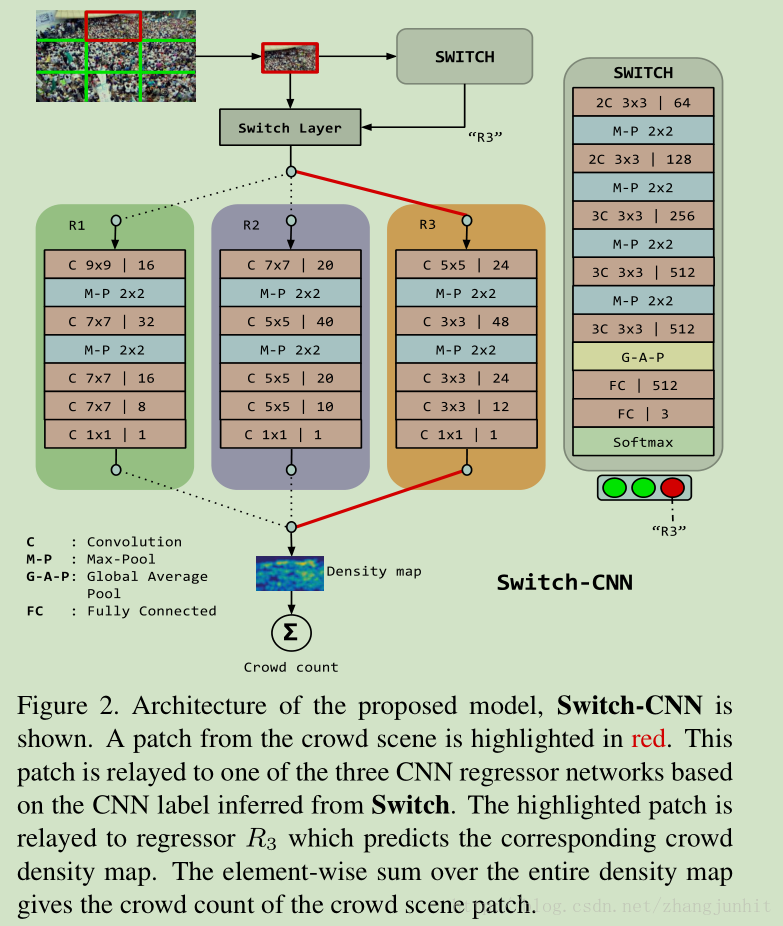
《Switching convolutional neural network for crowd counting》2017.
Switch-CNN。該論文在圖像塊上訓練多個獨立的cnn,先把圖像分為3x3份,對每份使用一個cnn網絡輸出,即圖中的switch,看它適合選擇后面那個網絡進行密度估計,一共有三種選擇。三種選擇的網絡結構設計參考的是MCNN,而switch部分則是基於vgg16。
《Generating high-quality crowd density maps using contextual pyramid cnns》2017
CP-CNN,該論文的改進點是結合整體和局部信息,從而提高檢測精度。該論文認為:
1)這些方法都沒有顯示的嵌入 context 信息,而 context 信息對提升性能很有幫助 2)當前基於回歸的密度圖估計方法更側重降低人群總數估計誤差,而不是側重人群密度圖的質量 3)當前的 CNN 網絡基本都是使用 像素級歐式損失函數來訓練網絡,這導致密度圖比較模糊。https://blog.csdn.net/zhangjunhit/article/details/78029133
網絡結構如下,GCE和LCE是分類網絡,分別獲取全局和局部context信息,文章將圖像的密度分為5個級別,很低、低、中等、高和很高。而DME是類似MCNN的三列結構,將圖像映射到高維的特征圖,最后使用F-CNN整合三個部分學習到特征。更多信息可以參考原文和這篇博客https://blog.csdn.net/zhangjunhit/article/details/78029133

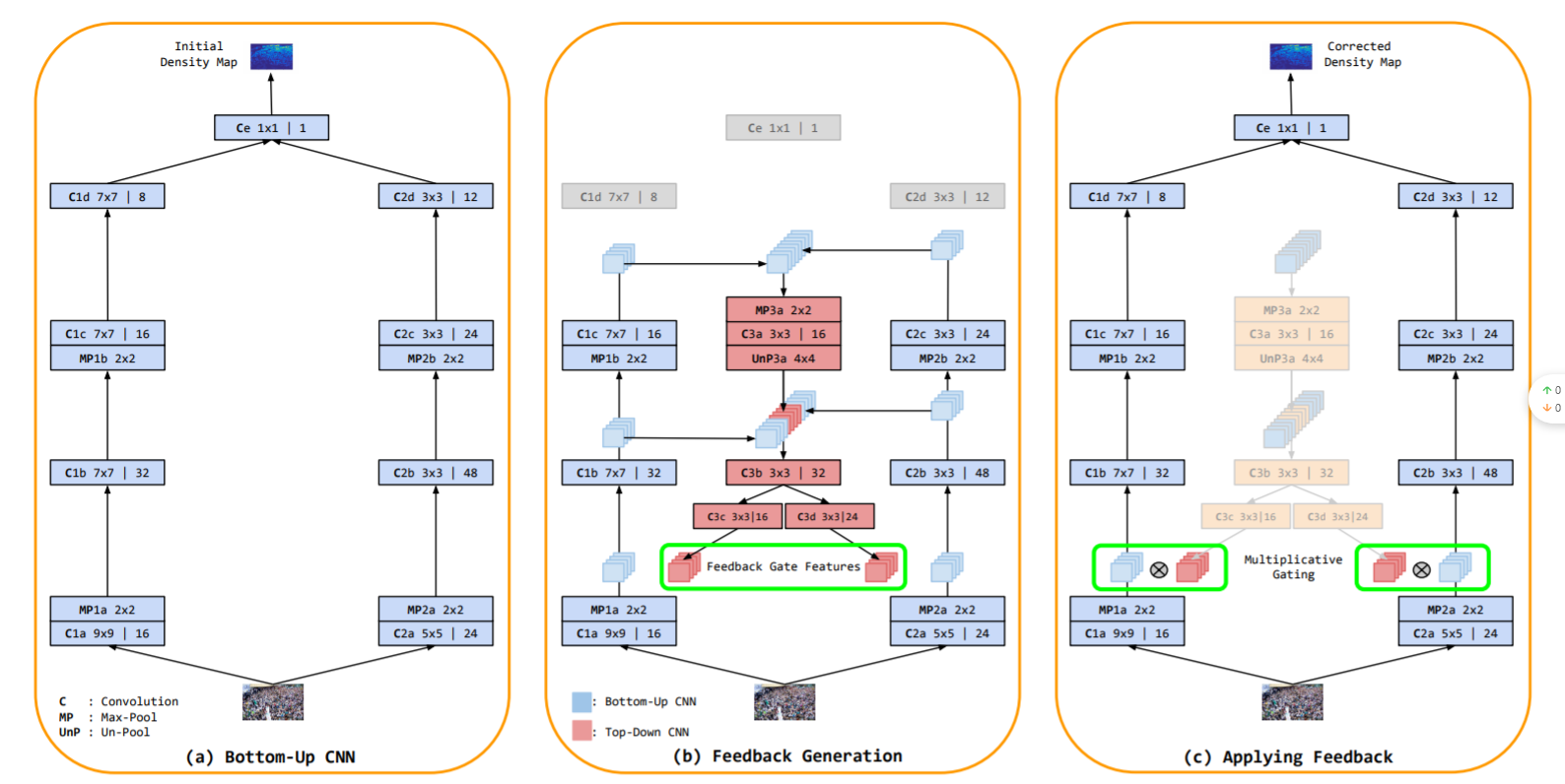
《Top-down feedback for crowd counting convolutional neural network》 2018
TDF-CNN,將自上而下的信息傳遞給自下而上的網絡以修改密度估計。
《Crowd counting using deep recurrent spatial-aware network》
DRSAN,利用空間變壓器網絡(STN)處理尺度變化和旋轉變化的問題

《Crowd counting using scale-aware attention networks》2019
SAAN。類似於CP-CNN的思想,利用視覺注意機制自動為全局圖像級別和局部圖像補丁級別選擇特定的比例
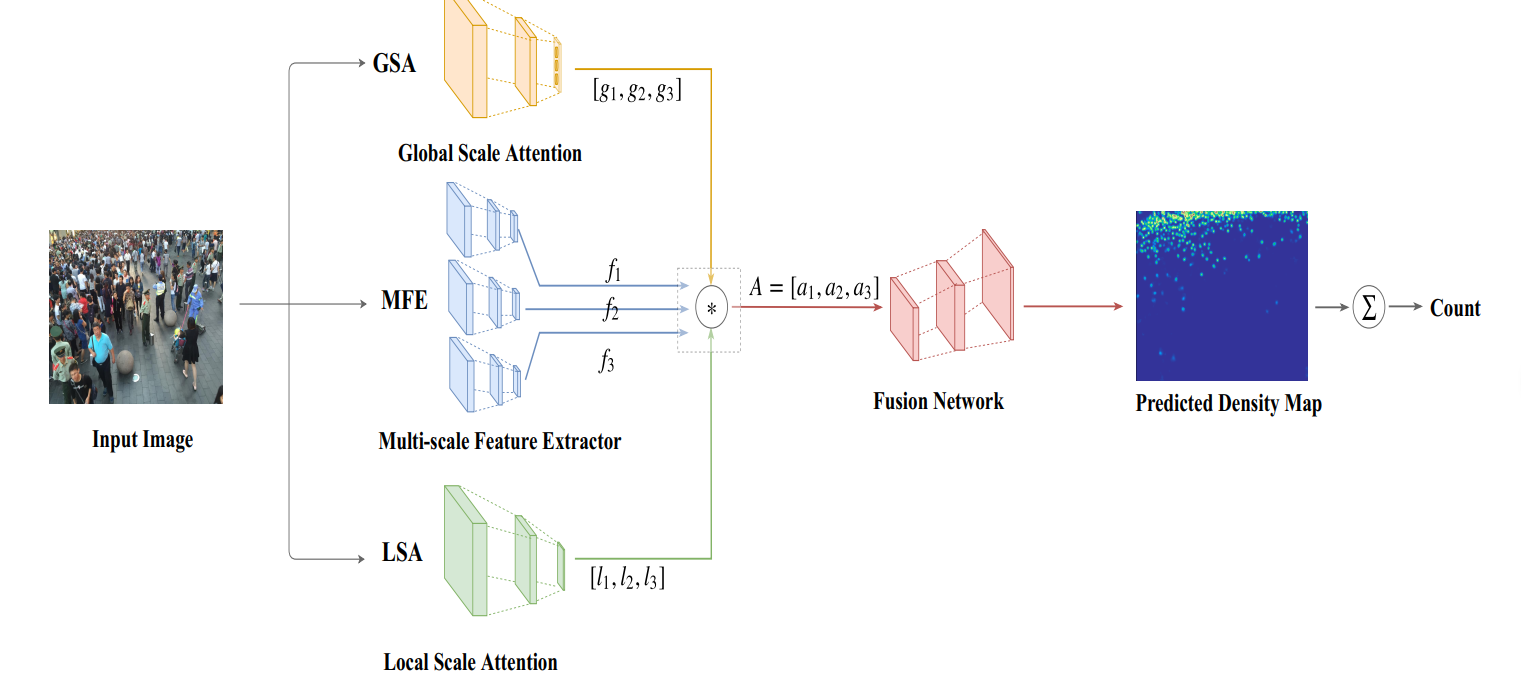
整體結構如上,GSA是全局尺度注意力網絡,MFE是一個多尺度的特征提取結構,LSA是局部尺度注意網絡。
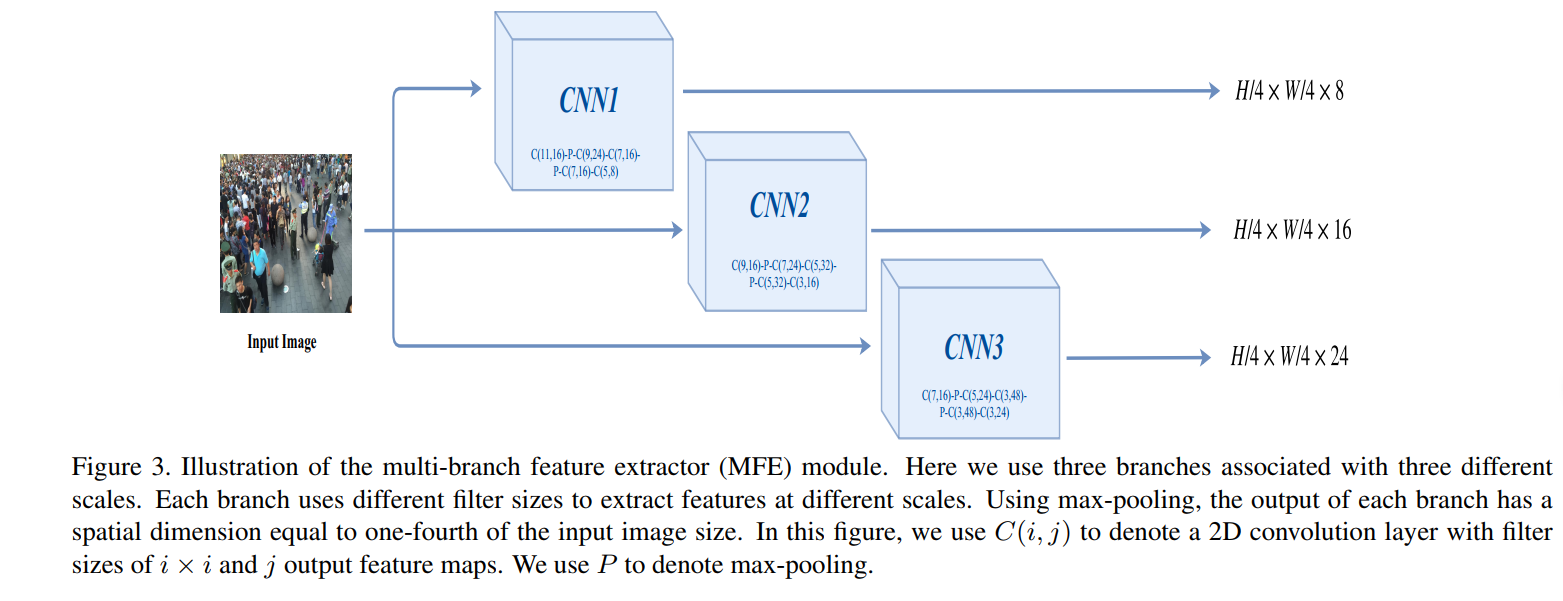
MFE采用多個分支獲取多尺度的特征。
該論文將注意力集中在尺度上,其中GSA是用於捕獲全局的上下文信息,類似之前的CP-CNN,但是只將密度分為了三個級別:低密度、中密度和高密度。結構如下,網絡輸出三個得分,分別代表了三個預定義的密度級別。
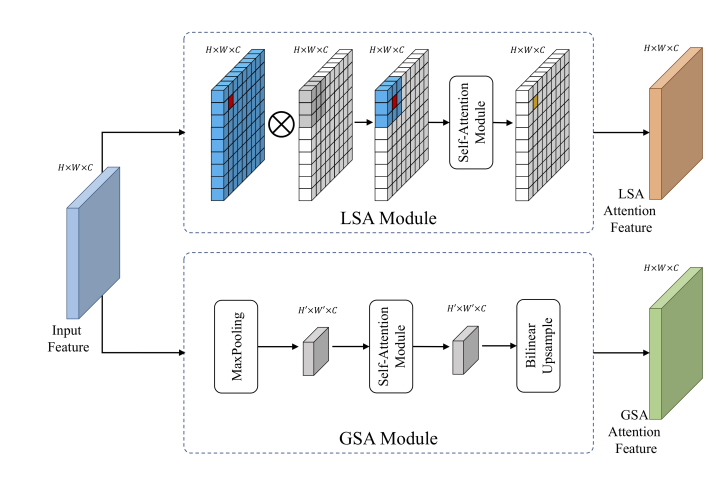
一張圖的不同區域密度級別不一樣,因此增加了LSA捕獲局部密度信息。
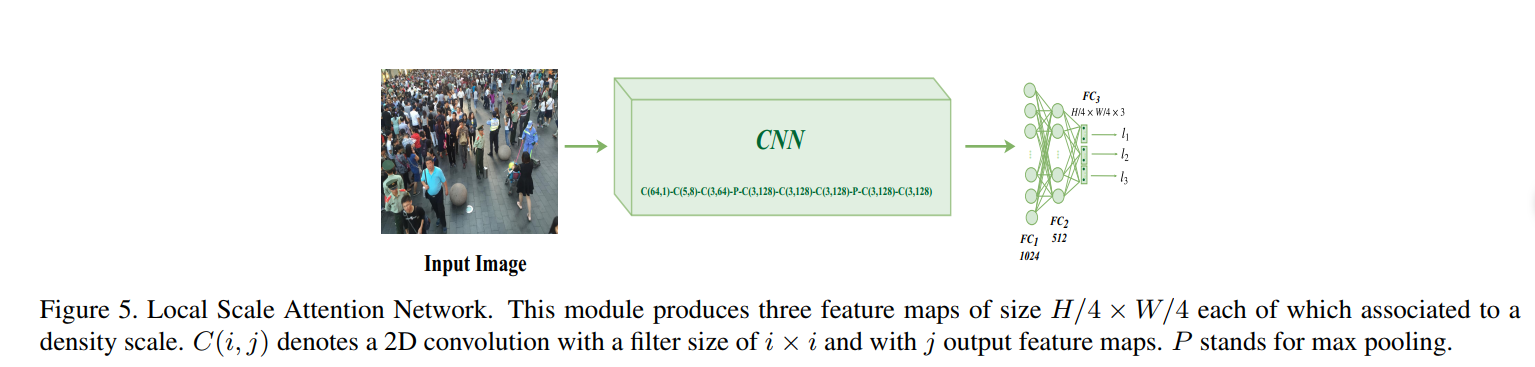
LSA的輸出也是三個數,但是它在最后用的sigmoid激活,而GSA是softmax輸出三個值。
最后那個GSA、LSA和MFE的輸出融合,可以看到MFE的三個分支輸出都是一樣的尺寸,但是通道數不一樣,設定低密度,中密度和高密度的通道數分別設置為24、16和8(卷積核越大,感受野范圍越廣,因此密度越大,即圖上的第一個分支是高密度)。
融合的方式是加權,加權后的特征圖再送入Fusion Network,該部分是卷積與反卷積組成,反卷積的目的是上采樣,恢復特征圖的大小為原始圖像大小,最后經過一個1x1的卷積得到預測的圖像密度圖。
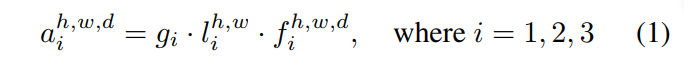
另外在損失函數上,除了密度圖與gt之間的距離,還考慮了全局和局部的尺度注意力。而這個尺度注意力的計算如下:
對於數據集的gt,找到人數的范圍,即人數最多的那張圖的值和最少的值,將這個范圍分為三段,實際上就是對應着之前提到的三個密度級別,然后對於某一張具體圖片的全局尺度注意力得分進行計算。某張具體圖片的gt的人數,落在划分的哪一段,如{1,2,3},那么該圖像的全局尺度值即為該值,然后該圖像在GSA的輸出是三個尺度的預測得分g,將這三個數g與gt進行比較,使用多類交叉熵損失函數CE計算。如該圖像在GSA的輸出是g = [0.2,0.5,0.3],而該圖的標簽是高密度,即gt=[0,0,1]。那么計算CE(g,gt)的結果即為這個GSA的損失值。
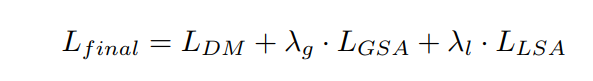
相應的,局部的尺度注意力損失值計算類似,計算gt的局部尺度注意力范圍是指 每個像素的64x64鄰域的密度范圍,即計算每個像素的鄰域密度值,然后統計整個圖的像素鄰域密度值范圍。將這個范圍分為三段。 然后具體某個像素的的局部尺度值,與LSA的輸出進行交叉熵計算。
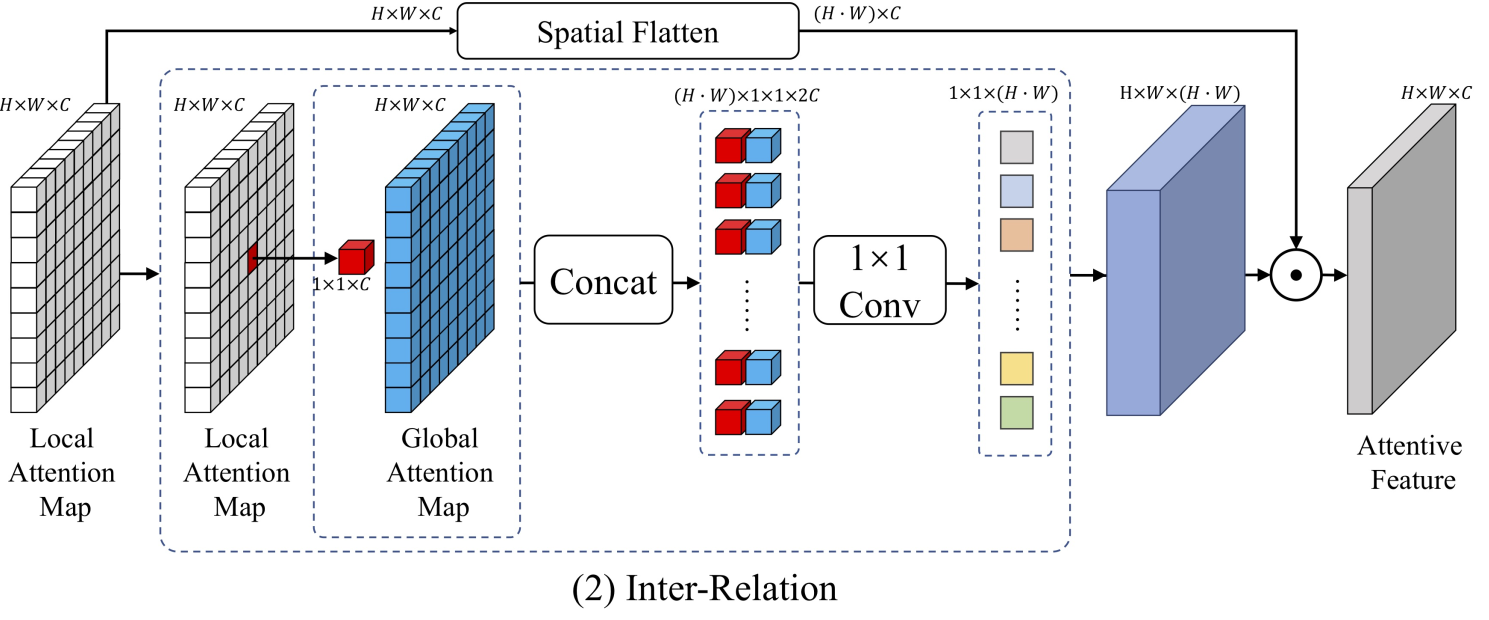
《Relational attention network for crowd counting》2019
RA-Net,該網絡也是使用了局部注意力和全局注意力。用LSA和GSA生成兩個特征圖,(這里的SA是self-attention,SAAN中的SA是指Scale attention)。
得到兩種特征圖后,進行特征的融合,論文中提出三種融合方式,
一種是 Intra-Relation,它又分為sum和concat的方式,故實際上Intra-Relation是兩種不同的方式,融合方式也很簡單,如下圖。一個采用concat后卷積輸出,另外一種直接相加輸出。
另一種融合方式是Inter-Relation,
《Improving the learning of multi-column convolutional neural network for crowd counting》
McML,該論文是對多列卷積網絡計數的思考,提出一種可以用於任何多列CNN的結構組件,如下圖,其中的statistical network整合了兩列的信息,最后輸出參數Iw應用於各自列的特征圖輸出。
McML已將統計網絡集成到多列結構中,以自動估計列之間的相互信息。統計網絡的本質是分類器網絡。具體來說,輸入是來自不同列的要素,而輸出是列之間的相互信息。我們使用互信息來大致指示不同列中要素之間的比例相關性。通過最大程度地減少列之間的相互信息,McML可以指導每一列專注於不同的圖像比例信息。(原文對McML的描述)
《Dadnet: Dilated-attention-deformable convnet for crowd counting》2019
DadNet,擴張-注意-可變形( Dilated-Attention-Deformable)卷積網絡
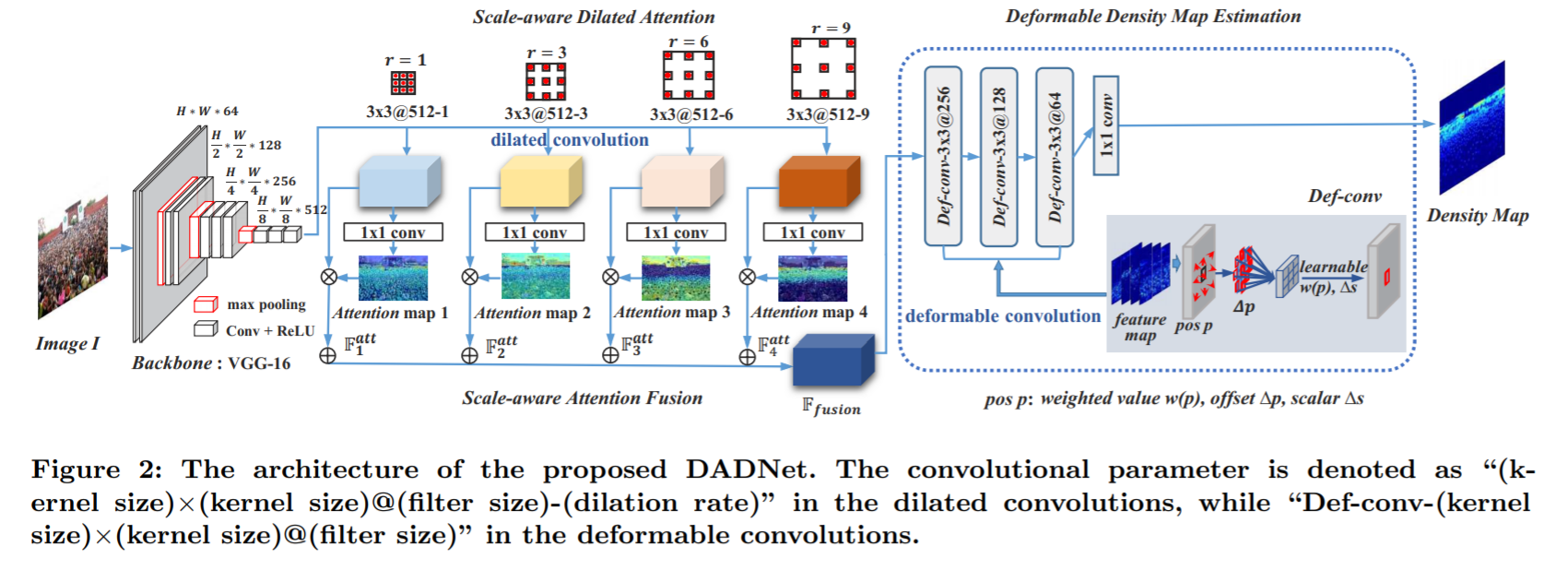
文章側重於特征融合,對於多尺度問題采用空洞卷積,從而獲得不同大小的感受野。總體結構如上。
骨干網絡VGG輸出原圖1/8的尺寸,然后將其通過四個不同擴張尺寸的空洞卷積和1x1普通卷積,得到四個對應不同感受野尺度的特征圖,這四個特征圖再依次乘上其對應的原空洞卷積輸出,最后疊加為融合后的特征,將其輸入最后的可變形模塊,最后的可變形模塊是連續三個可變形卷積,其輸出經過1x1卷積后即為最終的估計密度圖。
單列的cnn模型
多列cnn的效果很好,但仍有缺點,在《Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes》(CVPR 2018)論文中有討論。該論文提出CSRnet,使用單列的空洞卷積,上面的DadNet的空洞思想也啟發自該網絡,
CSRnet中提出的多列卷積缺點:1)訓練困難,時間長。2)各列的結果相似,效果大同小異,冗余大。3)分類器的精度難以把控,高精度的分類器又會導致模型結構過於復雜。4)參數浪費,大量參數被用於密度等級分類器,使得密度生成部分反而精度不足。
單列網絡體系結構通常部署單個和更深的CNN,而不是多列網絡體系結構的膨脹結構,並且前提是不增加網絡的復雜性。
W-VLAD : 《Crowd counting via weighted vlad on dense attribute feature maps》
該論文提出一種LAF結構,對比SPP,可以來表示空間信息。
學習范式
人群計數分為多任務和單任務。大多是單任務范式,即生成密度圖,然后求和得到人數或者直接回歸出人數。
多任務:通過結合密度估計和其他任務(例如分類,檢測,分割等)而表現出更好的性能。基於多任務的方法通常設計有多個子網此外,與純單列架構相比,可能存在對應於不同任務的其他分支。綜上所述,多任務體系結構可以看作是多列和單列之間的交叉融合,但二者都不相同
推理方式
基於patches和基於整幅圖像的。前者通常將圖像分成小塊送入訓練,各小塊得出其密度估計圖后進行整合,后者送入整幅圖像訓練。
基於patches的方法特點是忽略全局信息,且滑窗導致計算成本大。后者缺點是忽略局部信息。
監督方式
全監督和半/無/自監督。
評估指標
分為三類:圖像級的計數值評估,像素級的密度圖質量評估,點級的定位精度評估。
圖像級指標
-
MAE和RMSE
\[\begin{array}{c} M A E=\frac{1}{N} \sum_{i=1}^{N}\left|C_{I_{i}}^{p r e d}-C_{I_{i}}^{g t}\right| \\ R M S E=\sqrt{\frac{1}{N} \sum_{i=1}^{N}\left|C_{I_{i}}^{p r e d}-C_{I_{i}}^{g t}\right|^{2}} \end{array} \]即直接比較gt的人數與預測密度圖的人數。MAE可以評估准確性,RMSE可以
-
GAME 因為MAE沒有考慮位置信息,故提出Grid Average Mean Absolute Error 。
\[\operatorname{GAME}(L)=\frac{1}{N} \sum_{n=1}^{N}\left(\sum_{l=1}^{4^{L}}\left|C_{I_{i}}^{p r e d}-C_{I_{i}}^{g t}\right|\right) \]其中\(4^L\)表示將圖像划分為一些不重疊的區域,\(L\)越大,對GAME指標的限制越大
質量評估PSNR等,略
其他
模型設計
數據集坐標到密度圖的生成
高斯核,自適應,結合K近鄰等。
密度圖的三種方式生成:
- 使用高斯核 適用於場景沒有嚴重透視失真的場景
- 透視密度圖 適用於固定場景,利用行人高度線性回歸生成的透視圖,對不同的頭部生成不同大小的高斯核。出自論文 跨場景人群計數Cross-scene Crowd Counting via Deep Convolutional Neural Networks
- k-nn密度圖 mcnn論文提出。
損失函數
最常用歐幾里得距離損失,此外smoothL1損失,tukey損失具有更強的魯棒性,對抗性損失可以用來提升密度圖質量,輕量級的局部SSIM損失結合歐式距離損失,來增強密度圖和標簽的結構相似性。TEDnet提出的損失:空間抽象損失SAL,Spatial Abstraction Loss將密度圖做金字塔池化,計算不同空間層上的MSE,考慮到了像素空間的關聯性,而不是獨立像素。類似於DSnet的密度圖池化后計算損失。另一個是空間相關性損失SAL,Spatial Correlation Loss,通過互相關系數計算比較估計圖和gt的相似性,計算如下,其中pq是圖像的橫縱坐標。Z和Y表示各自在各個像素點處的值。
經過簡單的實驗,DSNet論文中提到的一致性損失確實很有效,即將密度圖和真實圖進行自適應平均池化,目的是匯聚局部信息,因為原來的L2損失是只比較了單個像素點,現在將一個區域匯聚后再進行比較,考慮到了鄰域像素,因此更有效,類似於金字塔池化的SAL損失。一致性損失的torch實現如下。
def cal_lc_loss(output, target, sizes=(1,2,4)):
criterion_L1 = nn.L1Loss()
Lc_loss = None
for s in sizes:
pool = nn.AdaptiveAvgPool2d(s) # 輸出s*s
est = pool(output)
gt = pool(target)
if Lc_loss:
Lc_loss += criterion_L1(est, gt)
else:
Lc_loss = criterion_L1(est, gt)
return Lc_loss