Flex 和 Bison的使用
寫在前面
本文主要整理了《flex與bison中文版》中關於flex和bison的一些內容,主要用於梳理關於flex和bison以及編譯原理中涉及到的一些知識。
1 簡介
flex和bison是生成程序的一種工具,常被用作便一起的生成,后來發現其特點在很多其他領域也有廣泛的應用。
1.1 詞法分析和語法分析
在編譯器的領域中,一般會把整個工作分為兩個部分,一個是詞法分析(lexical analysis),一個是語法分析(syntax analysis)。簡單來說就是詞法分析將一個需要分析的輸入差分成一個個的記號(稱為token);而語法分析確定這些token是如何彼此關聯的。
alapha = beta + gamma;
詞法分析將上述輸入划分為幾個記號:alapha、=、beta、+、gamma還有;。接着語法分析確定了beta + gamma是一個表達式,而這個表達式被賦值給了alpha。
1.2 正則表達式和語法分析
詞法分析可以被概括為尋找一種模式。一種簡潔明了的模式表達方式就是正則表達式(regular expression)。flex就是這樣由一系列帶有指令的正則表達式組成的,這些指令確定了正則表達式匹配后的動作。flex內部通過DFA有限自動機實現將所有的正則表達式翻譯成一種高效的內部格式。
%{
int chars = 0;
int words = 0;
int lines = 0;
%}
%%
[a-zA-Z]+ { words++; chars = chars + strlen(yytext); }
\n { chars++; line++; }
. { chars++ }
%%
int main(int argc, char **argv)
{
yylex();
printf("%d\t%d\t%d\n",words,chars,lines);
}
-
聲明部分:
%{和%}之間的聲明部分會被flex直接復制到生成的C文件的開頭部分。 -
模式部分:每個模式在一行的開頭處,隨后的
{ }中聲明了模式匹配所需要執行的C代碼。NOTICE:flex中模式必須在行首出現,否則會被flex認為是代碼而直接復制到生成的C程序中
在任何一個flex中,yytext表示本次匹配的輸入文本。這里使用strlen函數統計字符的個數
-
程序部分:最后就是Flex的主程序部分,負責調用flex提供的詞法分析器
yylex(),並輸出結果。
1.2.1 Flex和Bison協同工作
一般來說,比較簡單的flex程序可以獨立於bison自己運行但是在實際的生產環境中,一般需要flex和bison協同配合完成某個工作。flex會獲得一個記號流,這樣可以方便語法分析器的處理。每當程序需要一個記號的時候,調用fflex()讀取一小部分輸入然后返回相應的記號。當程序需要下一個記號的時候,yylex()會被再次調用。也就是說,每次返回的時候,會記住當前處理的位置,並從這個位置開始響應下一次處理。
這種工作原理看似難以理解,實際上非常簡單:
如果動作有返回,詞法分析會在下一次yylex()調用時候繼續;
如果動作沒有返回,詞法分析會繼續執行。
1.2.2 記號編號和記號值
詞法分析器完成一個記號流的返回時候,實際上有兩個組成部分,記號編號(token number)和記號值(token‘s value)。當bison創建語法分析器的時候,會自動的從258開始指派每個記號的編號,並創建一個包含這些編號定義的.h文件。
%{
enum yytokentype {
NUMBER = 258,
ADD = 259,
SUB = 260,
MUL = 261,
DIV = 262,
ABS = 263,
EOL = 264
};
int yylval;
%}
%%
"+" { return ADD; }
"-" { return SUB; }
"*" { return MUL; }
"/" { return DIV; }
"|" { return ABS; }
[0-9]+ { return ADD; }
\n { return ADD; }
[ \t] { }
. { printf("Mystery charater %c\n", *yyytext); }
%%
int main(int argc, char **argv)
{
int tok;
while(tok = yylex){
printf("%d", tok);
if(tok == NUMBER) printf(" = %d",yylval);
else printf("\n");
}
}
上述代碼在C語言中定義了一個enum記號編號,接着將yylval定義為整數。這里甚至可以將yylval定義為復合型結構,完全看自己的選擇需求。通常來說,記號值被定義為聯合類型以便於不同類型的記號可以擁有不同類型的記號值。如此一來就有了一個非常簡答的詞法分析器。
1.3 文法與語法分析
語法分析器的任務是找到輸入記號之間的關系。例如一種較為常見的語法分析關系就是語法分析樹。```1 * 2 + 3 * 4 + 5 ``。
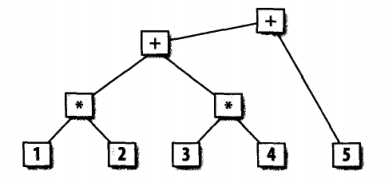
需要注意的是,圖中所顯示的內容表名*比+有更高的優先級。所以前兩個表達式是1 * 2和3 * 4。接着這兩個表達式被結合到了一塊,最后在加上5。bison在分析其輸入時會構造一個語法分析書。在有些應用里,它在整棵樹作為一個數據結構創建在內存中以便於后續利用。而有些應用中,語法分析樹只是隱含的包含在語法分析器進行一系列操作。
1.3.1 BNF文法
上下文無關文法(Context-Free Grammer)CFG是計算機中比較常見的語言描述,上下文無關文法的標准格式就是Backus-Naur范式(BackusNaur Form,BNF)。
<exp> ::= <factor>
| <exp> + <factor>
<factor> ::= NUMBER
| <factor> * NUMBER
::=被讀作是或者編程,|表示或者,創建同類的另一種方式。規則左邊的名稱是語法符號。大致來說,所有的記號都被認為是語法符號,但是有些語法符號不是記號。BNF具有遞歸性質,規則會間接的指向自身。這些簡單的規則被遞歸的使用最終形成了復雜的極端的語法。
1.3.2 Bison規則描述語言
bison基本上就是BNF,但是做了一點點簡化。
/* simplest version of calculator */
%{
#include <stdio.h>
int yyerror(const char *, ...);
extern int yylex();
extern int yyparse();
%}
/* declare tokens */
%token NUMBER
%token ADD SUB MUL DIV ABS
%token EOL
%%
calclist: /* nothing 從輸入開頭進行匹配 */
| calclist exp EOL { printf("= %d\n> ", $2); }
;
exp: factor default $$ = $1
| exp ADD exp { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
;
factor: term default $$ = $1
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER default $$ = $1
| ABS term { $$ = $2 >= 0? $2 : - $2; }
;
%%
int main()
{
printf("> ");
yyparse();
return 0;
}
int yyerror(const char *s, ...)
{
int ret;
va_list va;
va_start(va, s);
ret = vfprintf(stderr, s, va);
va_end(va);
return ret;
}
-
聲明部分:和flex非常相似,包含了會直接拷貝到目標分析程序的C代碼。同樣也通過
%{ %}聲明。隨后是%token記號聲明,以便於告訴bison在語法分析程序中極好的名稱。NOTICE:記號通常都是大寫字母
-
規則部分:通過簡單的BNF規則,bison使用單一冒號:而不是::=,並使用分號;作為規則的結束。bison會幫助分析語法,同時動作代碼需要維護每個語法符號的關聯語義值。biso還可以執行一些額外的動作(創建一些數據結構以便能夠后續使用)。
每個bison規則都有一個語義值,當詞法分析器返回記號的時候,記號值總會存儲在yyval里面,其他語法符號的語義值則在語法分析器的規則里進行設置。
1.3.3 聯合編譯Flex和Bison程序
前文已經聲明過一份flex程序。如果想要和bison聯合計算,務必修改一下flex程序。具體就是包含了bison為我們創建的頭文件而不是在第一個部分里面的顯式的記號值,那個頭文件包含了一些極好的編號定義和yylval的定義。
%{
#include <fb1-5.tab.h> //添加了.y文件編譯后生成的.h文件
enum yytokentype {
NUMBER = 258,
ADD = 259,
SUB = 260,
MUL = 261,
DIV = 262,
ABS = 263,
EOL = 264
};
int yylval;
%}
%%
"+" { return ADD; }
"-" { return SUB; }
"*" { return MUL; }
"/" { return DIV; }
"|" { return ABS; }
[0-9]+ { return NUMBER; }
\n { return EOL; }
[ \t] { }
. { printf("Mystery charater %c\n", *yyytext); }
%%
/* 由於需要和bison聯合,這部分代碼也不再需要了。除非是要單獨調試.l文件
int main(int argc, char **argv)
{
int tok;
while(tok = yylex){
printf("%d", tok);
if(tok == NUMBER) printf(" = %d",yylval);
else printf("\n");
}
}
*/
fb1-5: fb1-5.l fb1-5.y
bison -d fb1-5.y
flex fb1-5.l
cc -o $@ fb1-5.tab.c lex.yy.c -lfl
1.4 二義性文法
前文的bison文件中的規則部分聲明很復雜,是否可以寫成如下形式?
exp: exp ADD exp
| exp SUB exp
| exp MUL exp
| exp IDV exp
| ABS exp
| NUMBER
;
/*****************************原來的寫法******************************/
calclist: /* nothing 從輸入開頭進行匹配 */
| calclist exp EOL { printf("= %d\n> ", $2); }
;
exp: factor default $$ = $1
| exp ADD exp { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
;
factor: term default $$ = $1
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER default $$ = $1
| ABS term { $$ = $2 >= 0? $2 : - $2; }
;
原因如下:優先級和二義性。
分開的term,factor,exp的語法可以有效地讓bison先處理ABS,再處理MUL/DIV,最后處理ADD/SUB。一旦一種文法有不同優先級,也就是一種操作符比另一種操作符綁定的更緊密時,語法分析器就需要為每種優先級指定一個規則。
bison常用的分析算法可以看做是一個記號用來決定那種規則來匹配輸入。有的文法並不具有二義性但是有哪些地方可能需要向前看更多的記號來決定匹配的規則。這就可能導致沖突。
1.5 更多規則的添加
上述的代碼可能不是非常完備的。當需要處理圓括號或者注釋的話,需要在原有基礎上添加一些規則。
bison新加的規則:
%{
#include <stdio.h>
#include <stdlib.h>
#include <stdarg.h>
int yyerror(const char *s,...);
extern int yylex();
extern int yyparse();
%}
/* declare tokens */
%token NUMBER
%token ADD SUB MUL DIV ABS
%token OP CP //定義了左右括號
%token EOL
%%
calclist: /* nothing 從輸入開頭進行匹配 */
| calclist exp EOL { printf("= %d\n> ", $2); }
| calclist EOL { printf("> "); }
;
exp: factor
| exp ADD exp { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
| exp ABS factor { $$ = $1 | $3; }
;
factor: term
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER
| ABS term { $$ = $2 >= 0? $2 : - $2; }
| OP exp CP { $$ = $2; } //新添加的一個規則,表示括號
;
%%
int main()
{
printf("> ");
yyparse();
return 0;
}
int yyerror(const char *s, ...)
{
int ret;
va_list va;
va_start(va, s);
ret = vfprintf(stderr, s, va);
va_end(va);
return ret;
}
flex新添加的規則
%{
#include "yacc.tab.h" //添加了.y文件編譯后生成的.h文件
int yylval;
%}
%%
"+" { return ADD; }
"-" { return SUB; }
"*" { return MUL; }
"/" { return DIV; }
"|" { return ABS; }
[0-9]+ { yylval = atoi(yytext);return NUMBER; }
\n { return EOL; }
[ \t] { }
"(" { return OP; }
")" { return CP; }
"//".* /* 忽略掉注釋 */
. { printf("Mystery charater %c\n", *yytext); }
%%
/* 由於需要和bison聯合,這部分代碼也不再需要了。除非是要單獨調試.l文件
int main(int argc, char **argv)
{
int tok;
while(tok = yylex){
printf("%d", tok);
if(tok == NUMBER) printf(" = %d",yylval);
else printf("\n");
}
}
*/
2 Flex的使用——統計單詞個數
flex內部使用了強大的正則表達式語言。正則表達式中有特殊意義的字符:
-
[] 字符類,可以匹配方括號中的任意一個字符。如果內部有^符號,則表示“非”。這個字符類別是從ASCII字符編碼:[A-z]將匹配所有大小寫字母,同時還匹配落在Z和z之間的幾個標點符號。
-
[a-z]{-}[jv] 一種不同的字符類別,包含的字符是前一個字符集減去后一個字符集。
-
^ 如果是正則表達式的第一個字符匹配行首。也被方括號中表示補集。
-
$ 如果是正則表達式的最后一個字符就匹配行尾。
-
{} 當花括號中帶有一個或者兩個數字的時候,表示一個范圍:
A{1-3},即匹配1-3個字母A;而0{5}則表示匹配00000。當花括號中帶有名字時,則指向以這個名字命名的模式。 -
\ 用來表示元字符自身和一部分常用的C語言轉義序列。例如,\n表示換換行符,而*則是字面意義上的星號。
-
* 匹配零個或者多個緊接在前面的表達式。例如,
[ \t]*可以匹配任意個空格和tab,也就是空白字符,能夠匹配“ ”,“tab tab”或者一個或多個空字符串。 -
+ 匹配一個或者多個緊接在前面的表達式。例如,[0-9]+可以匹配字符串,像1,11或者123456,但是不是一個空字符串。
-
? 匹配零個或者一個緊接在前面的表達式。例如,-?[0-9]+匹配一個有符號數字,它帶有一個可選的前置符號。
-
| 選擇操作符,匹配緊接在前面的表達式或者緊跟在后面的表達式。例如:faith|hope|charity中的任何一個。
-
“...” 所有引號的字符將基於字面意義被解釋。不屬於C轉義序列的元字符將失去它的原有特殊意義。
-
() 把一系列的正則表達式組成一個新的正則表達式。例如,(01)匹配字符01,而a(bc|de)匹配abd或者ade。圓括號建立帶有*,+,?和|的復雜模式很有用。
-
/ 尾部上下文,匹配斜線前的正則表達式,但是要求其后緊跟着斜線后的表達式。例如,0/1匹配字符串01中的0,但是不會匹配字符串0或者02。斜線后的匹配內容不會被消耗掉,它們會返還給輸入以便於繼續匹配。每個模式只允許一個尾部上下文操作符。
2.1 正則表達式的例子
不妨假設現在需要匹配一個可選小數點的數字字符串的模式:
[-+]?[0-9]+ : 可選的正負號和數字字符串。
[-+]?[0-9.]+ : 增加了更多的可能性,比如1.2.3.4。
[-+]?[0-9]+\.?[0-9]+ : 有些沒有匹配到,比如 .12 和 12.
[-+]?[0-9]*\.?[0-9]+ : 不能匹配 12.
[-+]?[0-9]+\.?[0-9]* : 不能匹配 .12
[-+]?[0-9]*\.?[0-9]* : 可能匹配空字符串和僅有一個小數點的情況。
這說明了字符類的?* +的組合並不能匹配帶有一個可選小數點的數值。幸運的是選擇操作符|可以幫助實現這一點。
[-+]?([0-9]*\.?[0-9]+|[0-9]+\.)
[-+]?([0-9]*\.?[0-9]+|[0-9]+\.[0-9]*) 這個就過於復雜了,但是也一樣有效
如果需要添加一個可選的指數,模式就比較簡單:
E(+|-)?[0-9]+
(我們把正負號字符作為選擇項而不是字符類的出現,這僅僅是實現方法的不同而已。)
[-+]?([0-9]*\.?[0-9]+|[0-9]+\.)(E(+|-)?[0-9]+)?
2.2 Flex處理二義性的模式
大多數flex程序都有二義性,相同的輸入可能會被不同的模式匹配。flex通過兩個簡單的規則來解決。
- 詞法分析匹配輸入時匹配盡可能多的字符串。
- 如果兩個模式都可以匹配的話,匹配在程序中更早的出現的模式。
例如:
"+" { return ADD; }
"=" { return ASSIGN; }
"+=" { return ASSIGNADD; }
"if" { return KEYWORDIF; }
"else" { return KEYWORDELSE }
[a-zA-Z_][a-zA-Z0-9_]* { return IDENTIFIER; }
對於前三個模式來說,字符串+=被匹配為一個記號,因為+=比+更長。對於后三個模式來說,只要匹配關鍵字的模式先於匹配標識符的模式,詞法分析器就可以正確的匹配關鍵字。
2.3 Flex詞法分析器中的文件I/O操作
2.3.1 單文件操作
主函數中,用戶在命令行中給出了文件名,主函數會打開這個文件並賦值給yyin,否則,yyin會保持未賦值的狀態,這種情況下yylex會吧stdin賦值給它。
%option noyywrap
%{
int chars = 0;
int words = 0;
int lines = 0;
%}
%%
[a-zA-Z]+ { words++; chars += strlen(yytext); }
\n { chars++;lines++; }
. { chars++; }
%%
int main(int argc, char ** argv)
{
if(argc > 1){
if(!(yyin = fopen(argv[1], "r"))) {
perror(arrgv[1]);
return 1;
}
}
yylex();
printf("%d %d %d",lines, words, chars);
}
2.3.2 多文件操作
%option noyywrap
%{
int chars = 0;
int words = 0;
int lines = 0;
int totchars = 0;
int totwords = 0;
int totlines = 0;
%}
%%
[a-zA-Z]+ { words++; chars += strlen(yytext); }
\n { chars++;lines++; }
. { chars++; }
%%
int main(int argc, char ** argv)
{
int i;
if(argc < 2){
yylex();
printf("%d %d %d",lines, words, chars);
return 0;
}
for(i = 1;i < argc;i++){
FILE *f = fopen(argv[i], "r");
if(!f){
perror(argv[i]);
return 1;
}
yyrestart(f);
yylex();
fclose(f);
printf("%d %d %d %s",lines, words, chars,argv[i]);
totchars += chars; chars = 0;
totwords += words; words = 0;
totlines += lines; lines = 0;
}
if(argc > 1){
printf("%d %d %d",totolines, totwords, totchars);
return 0;
}
}
2.4 Flex詞法分析器的I/O結構
2.4.1 Flex詞法分析器的輸入
大多數情況下,flex詞法分析器從文件或者標准輸入讀取輸入。從文件讀取或者從終端讀取存在着一個微小但是重要的差異——預讀機制。
flex詞法分析器使用稱為YY_BUFFER_STATE的數據結構處理輸入,該結構定義一個單一的輸入源。包含一個字符串緩沖區和一些變量和標記。有時候會包含一個所讀取文件的FILE*,但是我們可以通過創建一個與文件無關的YY_BUFFER_STATE分析已經在內存中的字符串。
一般來說,輸入管理的三個層次是:
- 設置yyin來讀取所需文件。
- 創建並使用YY_BUFFER_STATE輸入緩存區
- 重新定義YY_INPUT
2.4.2 Flex詞法分析器的輸出
所有沒有被匹配的輸入都被拷貝到yyout。
#define ECHO fwrite( yytext, yyleng, 1, yyout )
對於一些僅處理一部分輸入其余部分保持不變的flex程序來說,flex 的模式標准是好的。flex允許設置%option nodefault,使他不要添加默認的規則。這樣當輸入無法被給定的規則完全匹配時候,詞法分析器可以報告錯誤。
2.5 起始狀態和嵌套輸入文件
/* Companion source code for "flex & bison", published by O'Reilly
* Media, ISBN 978-0-596-15597-1
* Copyright (c) 2009, Taughannock Networks. All rights reserved.
* See the README file for license conditions and contact info.
* $Header: /home/johnl/flnb/code/RCS/fb2-3.l,v 2.3 2010/01/04 02:43:58 johnl Exp $
*/
%option noyywrap warn nodefault
%x IFILE
struct bufstack {
struct bufstack *prev; /* previous entry */
YY_BUFFER_STATE bs; /* saved buffer */
int lineno; /* saved line number */
char *filename; /* name of this file */
FILE *f; /* current file */
} *curbs = 0;
char *curfilename; /* name of current input file */
int newfile(char *fn);
int popfile(void);
%%
^"#"[ \t]*include[ \t]*[\"<] { BEGIN IFILE; }
<IFILE>[^ \t\n\">]+ {
{ int c;
while((c = input()) && c != '\n') ;
}
yylineno++;
if(!newfile(yytext))
yyterminate(); /* no such file */
BEGIN INITIAL;
}
<IFILE>.|\n {
fprintf(stderr, "%4d bad include line\n", yylineno);
yyterminate();
}
^. { fprintf(yyout, "%4d %s", yylineno, yytext); }
^\n { fprintf(yyout, "%4d %s", yylineno++, yytext); }
\n { ECHO; yylineno++; }
. { ECHO; }
<<EOF>> { if(!popfile()) yyterminate(); }
%%
main(int argc, char **argv)
{
if(argc < 2) {
fprintf(stderr, "need filename\n");
return 1;
}
if(newfile(argv[1]))
yylex();
}
int
newfile(char *fn)
{
FILE *f = fopen(fn, "r");
struct bufstack *bs = malloc(sizeof(struct bufstack));
/* die if no file or no room */
if(!f) { perror(fn); return 0; }
if(!bs) { perror("malloc"); exit(1); }
/* remember state */
if(curbs)curbs->lineno = yylineno;
bs->prev = curbs;
/* set up current entry */
bs->bs = yy_create_buffer(f, YY_BUF_SIZE);
bs->f = f;
bs->filename = fn;
yy_switch_to_buffer(bs->bs);
curbs = bs;
yylineno = 1;
curfilename = fn;
return 1;
}
int
popfile(void)
{
struct bufstack *bs = curbs;
struct bufstack *prevbs;
if(!bs) return 0;
/* get rid of current entry */
fclose(bs->f);
yy_delete_buffer(bs->bs);
/* switch back to previous */
prevbs = bs->prev;
free(bs);
if(!prevbs) return 0;
yy_switch_to_buffer(prevbs->bs);
curbs = prevbs;
yylineno = curbs->lineno;
curfilename = curbs->filename;
return 1;
}
2.5.1 起始狀態
起始狀態允許我們在特定特定時刻哪些模式可以被匹配。文件頂部的%x IFILE定義為起始狀態,它將在我們尋找#include語句中的文件名的時候被使用。在任何時候,這個詞法分析器都處於一個起始狀態中,並且只匹配這個狀態所激活的那些模式。
%option noyywrap warn nodefault
%x IFILE
struct bufstack {
struct bufstack *prev; /* previous entry */
YY_BUFFER_STATE bs; /* saved buffer */
int lineno; /* saved line number */
char *filename; /* name of this file */
FILE *f; /* current file */
} *curbs = 0;
char *curfilename; /* name of current input file */
int newfile(char *fn);
int popfile(void);
%%
第一個模式匹配#include語句,知道遇見文件名之前的雙引號為止。如果第一個模式得到了匹配,詞法分析器會切換到IFILE狀態,讀取接下來的文件名。IFILE的第二個模式匹配一個文件名,直到遇到結束引號、空白字符或者行結束符。
由於獨占的起始狀態IFILE定義了一個小型的詞法分析器,因此這個詞法分析器必須能處理任何可能的輸入。第二個IFILE模式是用來匹配不規范的#include行的輸入,只需要打印錯誤信息並調用宏yyterminate()來立即從詞法分析器返回。
接下來是<<EOF>>,它所匹配的是輸入文件的結束。我們調用后面定義的popfile()來返回前一個輸入文件。如果返回為0,意味着這是最后一個文件;否則將從上次的位置繼續分析。
%%
^"#"[ \t]*include[ \t]*[\"<] { BEGIN IFILE; }
<IFILE>[^ \t\n\">]+ {
{
int c;
while((c = input()) && c != '\n') ;
}
yylineno++;
if(!newfile(yytext))
yyterminate(); /* no such file */
BEGIN INITIAL;
}
<IFILE>.|\n {
fprintf(stderr, "%4d bad include line\n", yylineno);
yyterminate();
}
^. { fprintf(yyout, "%4d %s", yylineno, yytext); }
^\n { fprintf(yyout, "%4d %s", yylineno++, yytext); }
\n { ECHO; yylineno++; }
. { ECHO; }
<<EOF>> { if(!popfile()) yyterminate(); }
%%
2.5.2 嵌套輸入文件
newfile(fn)在文件名為fn的文件的同時保存前面所有輸入文件的信息。bufstack結構維護一個逆向鏈表,每一個節點保存了yylineno和文件名的信息。這個例程打開文件,創建並切換到flex的緩沖區,並且保存前一個打開的文件、文件名和緩沖區。
int
newfile(char *fn)
{
FILE *f = fopen(fn, "r");
struct bufstack *bs = malloc(sizeof(struct bufstack));
/* die if no file or no room */
if(!f) { perror(fn); return 0; }
if(!bs) { perror("malloc"); exit(1); }
/* remember state */
if(curbs)curbs->lineno = yylineno;
bs->prev = curbs;
/* set up current entry */
bs->bs = yy_create_buffer(f, YY_BUF_SIZE);
bs->f = f;
bs->filename = fn;
yy_switch_to_buffer(bs->bs);
curbs = bs;
yylineno = 1;
curfilename = fn;
return 1;
}
popfile和newfile剛好相反。它關閉打開的文件,刪除當前的flex緩沖區,然后從前一個堆棧項恢復緩沖區、文件名和行號。恢復前一個緩沖區的時候它沒有調用yyrestart(),如果調用了yyrestart(),將會丟失已經讀入緩沖區的輸入。
int
popfile(void)
{
struct bufstack *bs = curbs;
struct bufstack *prevbs;
if(!bs) return 0;
/* get rid of current entry */
fclose(bs->f);
yy_delete_buffer(bs->bs);
/* switch back to previous */
prevbs = bs->prev;
free(bs);
if(!prevbs) return 0;
yy_switch_to_buffer(prevbs->bs);
curbs = prevbs;
yylineno = curbs->lineno;
curfilename = curbs->filename;
return 1;
}
2.6 符號表和重要語匯索引生成器
基本上每個flex和bison都會使用符號表(symbol table)來記錄輸入中使用的名稱。我們用一個非常簡單的程序作為例子,會生成重要與會索引,也就是輸入中出現的各個單詞所在行號的列表,然后將其修改為一個能夠讀取C語言的交叉引用程序。
2.6.1 管理符號表
重要語匯索引的符號表只需要簡答的記錄每個單詞以及其它們所在文件的行號。
%option noyywrap nodefault yylineno case-insensitive
/* the symbol table */
%{
struct symbol { /* a word */
struct ref *reflist;
char *name;
};
struct ref {
struct ref *next;
char *filename;
int flags;
int lineno;
};
/* simple symtab of fixed size */
#define NHASH 9997
struct symbol symtab[NHASH];
struct symbol *lookup(char*);
void addref(int, char*, char*, int);
char *curfilename; /* name of current input file */
%}
%%
%option行有兩個以前沒有見過的選項,都非常有用。選項%yylineno告訴flex定義一個名為yylineno的整形變量用來保存行號。(yylineno一般必須初始化為1),對於包含文件的情況,還需要額外的保存和恢復的動作。即使有這樣一些規則,仍然比手動維護行號簡單。
case-insensitice,他要求flex是一個大小寫無關的詞法分析器。
此處的符號表也就是一個symbol結構的數組,每個結構包含一個指向名稱的指針以及引用列表。
/* skip common words */
a |
an |
and |
are |
as |
at |
be |
but |
for |
in |
is |
it |
of |
on |
or |
that |
the |
this |
to /* ignore */
[a-z]+(\'(s|t))? { addref(yylineno, curfilename, yytext, 0); }
.|\n /* ignore everything else */
%%
重要語匯索引通常不索引常見的短詞,因此第一個模式將忽視它們( /* ignore */ )。包函數線的語義動作告知它與下一條規則的語義動作一致。最后一個忽略單詞的語義動作並不做任何事情,這樣就忽略了這個單詞。
[a-z]+(\'(s|t))?是詞法分析器的主體,大致匹配一個英文單詞。后面接着's或者't。**每一個匹配的單詞都會和當前文件名以及行號一起傳遞給稍后會講到的addref()。
.|\n模式匹配所有前面沒有匹配到的字符。
當兩個模式都可以匹配的時候,flex將匹配更早出現的。所以要把忽略規則前置,全匹配后置。
main(argc, argv)
int argc;
char **argv;
{
int i;
if(argc < 2) { /* just read stdin */
curfilename = "(stdin)";
yylineno = 1;
yylex();
} else
for(i = 1; i < argc; i++) {
FILE *f = fopen(argv[i], "r");
if(!f) {
perror(argv[1]);
return (1);
}
curfilename = argv[i]; /* for addref */
yyrestart(f);
yylineno = 1;
yylex();
fclose(f);
}
printf("old = %d, new = %d, total = %d, probes = %d, avg = %1.2f\n",
nold, nnew, nold+nnew, nprobe, (float)nprobe / (nold+nnew));
printrefs();
}
主函數和讀取多個文件的字數的程序非常相似。依次打開每個文件,使用yyrestart安排讀取文件,然后調用yylex。額外的工作是把curfilename設置為文件名,便於構造引用列表,並且為每個文件設置yylineno為1(否則行號將會從一個文件到另一個文件進行累加)最后,printrefs會把符號表按順序排列並打印出可引用的信息。
2.6.2 使用符號表
詞法分析器的代碼包含了一個簡單的符號表例程,一個添加單詞到符號表的歷程以及一個在所有輸入被運行后打印出重要語匯索引的例程。
lookup獲取一個字符串並返回用於這個字符串名稱的符號表目的位置,如果名字不存在的話就創建它。名字查找技術稱為線性探測的哈希算法。使用哈希函數吧字符串轉化為符號表中的條目號,然后檢查這個條目,如果該條目會被一個不同符號占用時就順序檢查下一個條目直到有可用的為止。
哈希函數對於每個字符,首先用9乘以一個哈希值,然后再xor這個字符,所有的操作都基於無符號數以避免溢出的情況。查找例程通過把哈希值對符號表的大小取模來得到符號表的索引。
/* hash a symbol */
static unsigned
symhash(char *sym)
{
unsigned int hash = 0;
unsigned c;
while(c = *sym++) hash = hash*9 ^ c;
return hash;
}
int nnew, nold;
int nprobe;
struct symbol *
lookup(char* sym)
{
struct symbol *sp = &symtab[symhash(sym)%NHASH];
int scount = NHASH; /* how many have we looked at */
while(--scount >= 0) {
nprobe++;
if(sp->name && !strcmp(sp->name, sym)) { nold++; return sp; }
if(!sp->name) { /* new entry */
nnew++;
sp->name = strdup(sym);
sp->reflist = 0;
return sp;
}
if(++sp >= symtab+NHASH) sp = symtab; /* try the next entry */
}
fputs("symbol table overflow\n", stderr);
abort(); /* tried them all, table is full */
}
每當lookup創在一個新的條目,他就會調用strup來產生字符串的拷貝並放到符號表條目中。flex和bison程序會經常存在難以跟蹤的字符串存儲管理問題。主要是因為yytext中的字符串會在下個詞法記號被分析師被替換掉。
void
addref(int lineno, char *filename, char *word, int flags)
{
struct ref *r;
struct symbol *sp = lookup(word);
/* don't do dups */
if(sp->reflist &&
sp->reflist->lineno == lineno && sp->reflist->filename == filename) return;
r = malloc(sizeof(struct ref));
if(!r) {fputs("out of space\n", stderr); abort(); }
r->next = sp->reflist;
r->filename = filename;
r->lineno = lineno;
r->flags = flags;
sp->reflist = r;
}
接下來是addref,詞法分析器用它來調用來添加對特定單詞的引用,這個例程基於引用結構的鏈表來實現。為了讓報告可以變得更短一些,如果符號已經有一個對同行好和文件名的應用,則它不會添加為這個引用。這里不會創建文件名的拷貝,因為知道這個字符串在調用放並不會改變。也不會拷貝單詞,因為lookup會幫我們處理它。每一個引用都有一個flag值,他將會在下個例子中被使用。
/* aux function for sorting */
static int
symcompare(const void *xa, const void *xb)
{
const struct symbol *a = xa;
const struct symbol *b = xb;
if(!a->name) {
if(!b->name) return 0; /* both empty */
return 1; /* put empties at the end */
}
if(!b->name) return -1;
return strcmp(a->name, b->name);
}
void
printrefs()
{
struct symbol *sp;
qsort(symtab, NHASH, sizeof(struct symbol), symcompare); /* sort the symbol table */
for(sp = symtab; sp->name && sp < symtab+NHASH; sp++) {
char *prevfn = NULL; /* last printed filename, to skip dups */
/* reverse the list of references */
struct ref *rp = sp->reflist;
struct ref *rpp = 0; /* previous ref */
struct ref *rpn; /* next ref */
do {
rpn = rp->next;
rp->next = rpp;
rpp = rp;
rp = rpn;
} while(rp);
/* now print the word and its references */
printf("%10s", sp->name);
for(rp = rpp; rp; rp = rp->next) {
if(rp->filename == prevfn) {
printf(" %d", rp->lineno);
} else {
printf(" %s:%d", rp->filename, rp->lineno);
prevfn = rp->filename;
}
}
printf("\n");
}
}
最后一部分對符號表進行排序和打印。使用qsort函數對符號表按照字母表順序進行排序。由於符號表不一定被用完,所以排序函數把沒有使用的條目放到使用的條目后面,這樣排序后的使用條目在符號表的前端。
接着printrefs自上而下打印符號表中對每個單詞的引用。引用被存儲在一個鏈表中,由於每個引用被壓入鏈表前端,事實上是倒序的。所以要翻轉整個鏈表來使他變成順序排列,然后進行打印。為了讓重要語匯索引可讀性更好一點,僅在文件名有變化時才打印文件名。同時只是比較文件名的置身,因為照理來說用於相同條目蔣志祥同一個文件名拷貝。
2.7 C語言的交叉引用
/* fb2-5 C cross-ref */
%option noyywrap nodefault yylineno
%x COMMENT
%x IFILE
/* some complex named patterns */
/* Universal Character Name */
UCN (\\u[0-9a-fA-F]{4}|\\U[0-9a-fA-F]{8})
/* float exponent */
EXP ([Ee][-+]?[0-9]+)
/* integer length */
ILEN ([Uu](L|l|LL|ll)?|(L|l|LL|ll)[Uu]?)
/* the symbol table */
第一個模式匹配通用字符名稱,一種在字符串和標識符中放置非ASCII碼字符的方法:通用字符名由跟在\u后的4個16進制或者跟在\u 后面的8個十六進制數表示。
第二個模式是浮點類型的指數部分。
第三個模式表示無符號的整形數字。
%{
struct symbol { /* 變量名稱 */
struct ref *reflist;
char *name;
};
struct ref {
struct ref *next;
char *filename;
int flags; /* 01 - definition */
int lineno;
};
/* 簡單的固定大小的符號表 */
#define NHASH 9997
struct symbol symtab[NHASH];
struct symbol *lookup(char*);
void addref(int, char*, char*, int);
char *curfilename; /* 當前輸入文件的名稱 */
int defining; /* 名稱是否是定義 */
/* 文件堆棧 */
struct bufstack {
struct bufstack *prev; /* 前一個條目 */
YY_BUFFER_STATE bs; /* 保存的緩沖區 */
int lineno; /* 保存文件的行號 */
char *filename; /* 文件名 */
FILE *f; /* 當前文件 */
} *curbs;
int newfile(char *fn);
int popfile(void);
%}
接下來規則部分
%%
/* comments */
"/*" { BEGIN(COMMENT) ; }
<COMMENT>"*/" { BEGIN(INITIAL); }
<COMMENT>([^*]|\en)+|.
/* C++ comment, a common extension */
"//".*\n
獨占的起始狀態使詞法分析器更容易被匹配注釋。
第一個規則在看到/*時激活comment狀態,而第二個規則在遇到*/時會切換回正常的INITIAL狀態。
第三個規則匹配兩者之間的一切字符。
之所以采取([^*]|\n)+,是因為這種方式一次就匹配一長串文本。這是因為這個方式排除了*,因此第二個規則才能夠匹配*/。
C語言注釋的模式
雖然單一的flex模式可以匹配C語言注釋,但是這也做並不是一個好主意。可以參考如下模式:
/\*([^*]|\*+[^/*])*\*+/他匹配開始一個注釋的兩個字符,
/\*;接着是一連串的不帶星號的字符或者尾部不帶星號和斜線的一連串星號,([^*]|\*+[^/*])*;最后是一個或者多個星號外加一個結束的斜線,\*+/。有兩個原因讓我們更傾向於使用多個模式和其實狀態。一個原因是注釋可能更長,在注釋占據了若干代碼時候會有問題,因為flex的記號有一定的輸入緩沖的長度限制,通常是16K(這種錯誤不太會被測試到)。另外一個原因是多個模式更容易發現和診斷沒有結束的注釋。雖然通過修改前面的模式可以匹配到,但是這更容易發成超過16K長度限制的情況。
/* declaration keywords */
_Bool |
_Complex |
_Imaginary |
auto |
char |
const |
double |
enum |
extern |
float |
inline |
int |
long |
register |
restrict |
short |
signed |
static |
struct |
typedef |
union |
unsigned |
void |
volatile { defining = 1; }
/* keywords */
break
case
continue
default
do
else
for
goto
if
return
sizeof
switch
while
下面是匹配所有C語言關鍵字的模式。對於引入聲明或者定義的關鍵字我們將設置defining標志,對其他關鍵字不需要做任何事情。
/* 常量 */
/* 整數 */
0[0-7]*{ILEN}?
[1-9][0-9]*{ILEN}?
0[Xx][0-9a-fA-F]+{ILEN}?
/* 十進制 浮點數 */
([0-9]*\.[0-9]+|[0-9]+\.){EXP}?[flFL]?
[0-9]+{EXP}[flFL]?
/* 十六進制 浮點數 */
0[Xx]([0-9a-fA-F]*\.[0-9a-fA-F]+|[0-9a-fA-F]+\.?)[Pp][-+]?[0-9]+[flFL]?
數字的模式非常復雜,我們的命名模式ILEN和EXP可以使處理變得更為簡單。
接下來是字符常量,和字符串常量。字符常量由單引號開始,其后面可以使一個或者多個非單引號和反斜線的普通字符,或者是通過反斜線轉義的字符比如\n,或者是以轉義符開始的最多三個八進制數字,或者是以轉義符開始的一定數量的十六進制數字,或者是通過通用字符名稱,最后都以單引號結尾。字符串字面量基本類似,除了它通過雙引號引起,並且帶有一個可選的前綴L來表明一個寬字符串,並且它也可以為空。
/* 字符常量 */
\'([^'\\]|\\['"?\\abfnrtv]|\\[0-7]{1,3}|\\[Xx][0-9a-fA-F]+|{UCN})+\'
/* 字符串字面量 */
L?\"([^\"\\]|\\['"?\\abfnrtv]|\\[0-7]{1,3}|\\[Xx][0-9a-fA-F]+|{UCN})+\"
C語言將操作符和標點都稱為標點符號。這里我們額外定義了表明變量名或者函數定義結束的三種模式,其余的無需特別處理。
標識符由字母、下划線與通用字符名開頭,后面是可選的更多字母、下划線、通用字符名以及數字、當我們遇到一個標識符時,就在符號表中添加一個對其的引用。
/* 標點符號 */
"{"|"<%"|";" { defining = 0; }
"["|"]"|"("|")"|"{"|"}"|"."|"->"
"++"|"--"|"&"|"*"|"+"|"-"|"~"|"!"
"/"|"%"|"<<"|">>"|"<"|">"|"<="|">="|"=="|"!="|"^"|"|"|"&&"|"||"
"?"|":"|";"|"..."
"="|"*="|"/="|"%="|"+="|"-="|"<<="|">>="|"&="|"^=""|="
","|"#"|"##"
"<:"|":>"|"%>"|"%:"|"%:%:"
/* 標識符 */
([_a-zA-Z]|{UCN})([_a-zA-Z0-9]|{UCN})* {
addref(yylineno, curfilename, yytext, defining); }
/* 空白字符 */
[ \t\n]+
/* 續行符 */
\\$
/* some preprocessor stuff */
"#"" "*if.*\n
"#"" "*else.*\n
"#"" "*endif.*\n
"#"" "*define.*\n
"#"" "*line.*\n
/* recognize an include */
^"#"[ \t]*include[ \t]*[\"<] { BEGIN IFILE; }
<IFILE>[^>\"]+ {
{ int c;
while((c = input()) && c != '\n') ;
}
newfile(strdup(yytext));
BEGIN INITIAL;
}
<IFILE>.|\n { fprintf(stderr, "%s:%d bad include line\n",
curfilename, yylineno);
BEGIN INITIAL;
}
<<EOF>> { if(!popfile()) yyterminate(); }
最后一個模式就是匹配之前所有沒有處理到的字符。由於這個模式覆蓋了有效C程序中可能出現的每個記號,所以事實上不應該被匹配到。
/* invalid character */
. { printf("%s:%d: Mystery character '%s'\n",
curfilename, yylineno, yytext);
}
%%
接下來是代碼部分
/* hash a symbol */
static unsigned
symhash(char *sym)
{
unsigned int hash = 0;
unsigned c;
while(c = *sym++) hash = hash*9 ^ c;
return hash;
}
struct symbol *
lookup(char* sym)
{
struct symbol *sp = &symtab[symhash(sym)%NHASH];
int scount = NHASH; /* how many have we looked at */
while(--scount >= 0) {
if(sp->name && !strcmp(sp->name, sym)) { return sp; }
if(!sp->name) { /* new entry */
sp->name = strdup(sym);
sp->reflist = 0;
return sp;
}
if(++sp >= symtab+NHASH) sp = symtab; /* try the next entry */
}
fputs("symbol table overflow\n", stderr);
abort(); /* tried them all, table is full */
}
void
addref(int lineno, char *filename, char *word, int flags)
{
struct ref *r;
struct symbol *sp = lookup(word);
/* don't do dups */
if(sp->reflist &&
sp->reflist->lineno == lineno && sp->reflist->filename == filename) return;
r = malloc(sizeof(struct ref));
if(!r) {fputs("out of space\n", stderr); abort(); }
r->next = sp->reflist;
r->filename = filename;
r->lineno = lineno;
r->flags = flags;
sp->reflist = r;
}
/* print the references
* sort the table alphabetically
* then flip each entry's reflist to get it into forward order
* and print it out
*/
/* aux function for sorting */
static int
symcompare(const void *xa, const void *xb)
{
const struct symbol *a = xa;
const struct symbol *b = xb;
if(!a->name) {
if(!b->name) return 0; /* both empty */
return 1; /* put empties at the end */
}
if(!b->name) return -1;
return strcmp(a->name, b->name);
}
void
printrefs()
{
struct symbol *sp;
qsort(symtab, NHASH, sizeof(struct symbol), symcompare); /* sort the symbol table */
for(sp = symtab; sp->name && sp < symtab+NHASH; sp++) {
char *prevfn = NULL; /* last printed filename, to skip dups */
/* reverse the list of references */
struct ref *rp = sp->reflist;
struct ref *rpp = 0; /* previous ref */
struct ref *rpn; /* next ref */
do {
rpn = rp->next;
rp->next = rpp;
rpp = rp;
rp = rpn;
} while(rp);
/* now print the word and its references */
printf("%10s", sp->name);
for(rp = rpp; rp; rp = rp->next) {
if(rp->filename == prevfn) {
printf(" %d", rp->lineno);
} else {
printf(" %s:%d", rp->filename, rp->lineno);
prevfn = rp->filename;
}
if(rp->flags & 01) printf("*");
}
printf("\n");
}
}
接下來主程序調用newfile,如果成果的話,為每個文件執行yylex。
int
main(argc, argv)
int argc;
char **argv;
{
int i;
if(argc < 2) {
fprintf(stderr, "need filename\n");
return 1;
}
for(i = 1; i < argc; i++) {
if(newfile(argv[i])) yylex();
}
printrefs();
return 0;
}
newfile無法打開一個文件時候,只是打印一個錯誤消息;能夠在打開文件時返回1,反正則返回0;而規則處理部分包含文件的代碼將繼續處理下一行。
/* nested input files */
int
newfile(char *fn)
{
FILE *f = fopen(fn, "r");
struct bufstack *bs;
/* check if no file */
if(!f) {
perror(fn);
return 0;
}
bs = malloc(sizeof(struct bufstack));
if(!bs) { perror("malloc"); exit(1); }
/* remember state */
if(curbs) curbs->lineno = yylineno;
bs->prev = curbs;
bs->f = f;
bs->filename = fn;
/* set up current entry */
bs->bs = yy_create_buffer(f, YY_BUF_SIZE);
yy_switch_to_buffer(bs->bs);
curbs = bs;
yylineno = 1;
curfilename = fn;
return 1;
}
int
popfile(void)
{
struct bufstack *bs = curbs;
struct bufstack *prevbs;
if(!bs) return 0;
/* get rid of current entry
fclose(bs->f);
yy_delete_buffer(bs->bs);
/* switch back to previous */
prevbs = bs->prev;
free(bs);
if(!prevbs) return 0;
yy_switch_to_buffer(prevbs->bs);
curbs = prevbs;
yylineno = curbs->lineno;
curfilename = curbs->filename;
return 1;
}