Flex 和 Bison的使用
写在前面
本文主要整理了《flex与bison中文版》中关于flex和bison的一些内容,主要用于梳理关于flex和bison以及编译原理中涉及到的一些知识。
1 简介
flex和bison是生成程序的一种工具,常被用作便一起的生成,后来发现其特点在很多其他领域也有广泛的应用。
1.1 词法分析和语法分析
在编译器的领域中,一般会把整个工作分为两个部分,一个是词法分析(lexical analysis),一个是语法分析(syntax analysis)。简单来说就是词法分析将一个需要分析的输入差分成一个个的记号(称为token);而语法分析确定这些token是如何彼此关联的。
alapha = beta + gamma;
词法分析将上述输入划分为几个记号:alapha、=、beta、+、gamma还有;。接着语法分析确定了beta + gamma是一个表达式,而这个表达式被赋值给了alpha。
1.2 正则表达式和语法分析
词法分析可以被概括为寻找一种模式。一种简洁明了的模式表达方式就是正则表达式(regular expression)。flex就是这样由一系列带有指令的正则表达式组成的,这些指令确定了正则表达式匹配后的动作。flex内部通过DFA有限自动机实现将所有的正则表达式翻译成一种高效的内部格式。
%{
int chars = 0;
int words = 0;
int lines = 0;
%}
%%
[a-zA-Z]+ { words++; chars = chars + strlen(yytext); }
\n { chars++; line++; }
. { chars++ }
%%
int main(int argc, char **argv)
{
yylex();
printf("%d\t%d\t%d\n",words,chars,lines);
}
-
声明部分:
%{和%}之间的声明部分会被flex直接复制到生成的C文件的开头部分。 -
模式部分:每个模式在一行的开头处,随后的
{ }中声明了模式匹配所需要执行的C代码。NOTICE:flex中模式必须在行首出现,否则会被flex认为是代码而直接复制到生成的C程序中
在任何一个flex中,yytext表示本次匹配的输入文本。这里使用strlen函数统计字符的个数
-
程序部分:最后就是Flex的主程序部分,负责调用flex提供的词法分析器
yylex(),并输出结果。
1.2.1 Flex和Bison协同工作
一般来说,比较简单的flex程序可以独立于bison自己运行但是在实际的生产环境中,一般需要flex和bison协同配合完成某个工作。flex会获得一个记号流,这样可以方便语法分析器的处理。每当程序需要一个记号的时候,调用fflex()读取一小部分输入然后返回相应的记号。当程序需要下一个记号的时候,yylex()会被再次调用。也就是说,每次返回的时候,会记住当前处理的位置,并从这个位置开始响应下一次处理。
这种工作原理看似难以理解,实际上非常简单:
如果动作有返回,词法分析会在下一次yylex()调用时候继续;
如果动作没有返回,词法分析会继续执行。
1.2.2 记号编号和记号值
词法分析器完成一个记号流的返回时候,实际上有两个组成部分,记号编号(token number)和记号值(token‘s value)。当bison创建语法分析器的时候,会自动的从258开始指派每个记号的编号,并创建一个包含这些编号定义的.h文件。
%{
enum yytokentype {
NUMBER = 258,
ADD = 259,
SUB = 260,
MUL = 261,
DIV = 262,
ABS = 263,
EOL = 264
};
int yylval;
%}
%%
"+" { return ADD; }
"-" { return SUB; }
"*" { return MUL; }
"/" { return DIV; }
"|" { return ABS; }
[0-9]+ { return ADD; }
\n { return ADD; }
[ \t] { }
. { printf("Mystery charater %c\n", *yyytext); }
%%
int main(int argc, char **argv)
{
int tok;
while(tok = yylex){
printf("%d", tok);
if(tok == NUMBER) printf(" = %d",yylval);
else printf("\n");
}
}
上述代码在C语言中定义了一个enum记号编号,接着将yylval定义为整数。这里甚至可以将yylval定义为复合型结构,完全看自己的选择需求。通常来说,记号值被定义为联合类型以便于不同类型的记号可以拥有不同类型的记号值。如此一来就有了一个非常简答的词法分析器。
1.3 文法与语法分析
语法分析器的任务是找到输入记号之间的关系。例如一种较为常见的语法分析关系就是语法分析树。```1 * 2 + 3 * 4 + 5 ``。
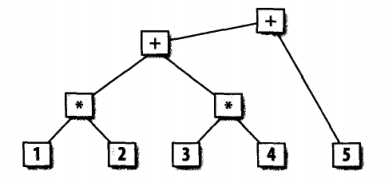
需要注意的是,图中所显示的内容表名*比+有更高的优先级。所以前两个表达式是1 * 2和3 * 4。接着这两个表达式被结合到了一块,最后在加上5。bison在分析其输入时会构造一个语法分析书。在有些应用里,它在整棵树作为一个数据结构创建在内存中以便于后续利用。而有些应用中,语法分析树只是隐含的包含在语法分析器进行一系列操作。
1.3.1 BNF文法
上下文无关文法(Context-Free Grammer)CFG是计算机中比较常见的语言描述,上下文无关文法的标准格式就是Backus-Naur范式(BackusNaur Form,BNF)。
<exp> ::= <factor>
| <exp> + <factor>
<factor> ::= NUMBER
| <factor> * NUMBER
::=被读作是或者编程,|表示或者,创建同类的另一种方式。规则左边的名称是语法符号。大致来说,所有的记号都被认为是语法符号,但是有些语法符号不是记号。BNF具有递归性质,规则会间接的指向自身。这些简单的规则被递归的使用最终形成了复杂的极端的语法。
1.3.2 Bison规则描述语言
bison基本上就是BNF,但是做了一点点简化。
/* simplest version of calculator */
%{
#include <stdio.h>
int yyerror(const char *, ...);
extern int yylex();
extern int yyparse();
%}
/* declare tokens */
%token NUMBER
%token ADD SUB MUL DIV ABS
%token EOL
%%
calclist: /* nothing 从输入开头进行匹配 */
| calclist exp EOL { printf("= %d\n> ", $2); }
;
exp: factor default $$ = $1
| exp ADD exp { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
;
factor: term default $$ = $1
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER default $$ = $1
| ABS term { $$ = $2 >= 0? $2 : - $2; }
;
%%
int main()
{
printf("> ");
yyparse();
return 0;
}
int yyerror(const char *s, ...)
{
int ret;
va_list va;
va_start(va, s);
ret = vfprintf(stderr, s, va);
va_end(va);
return ret;
}
-
声明部分:和flex非常相似,包含了会直接拷贝到目标分析程序的C代码。同样也通过
%{ %}声明。随后是%token记号声明,以便于告诉bison在语法分析程序中极好的名称。NOTICE:记号通常都是大写字母
-
规则部分:通过简单的BNF规则,bison使用单一冒号:而不是::=,并使用分号;作为规则的结束。bison会帮助分析语法,同时动作代码需要维护每个语法符号的关联语义值。biso还可以执行一些额外的动作(创建一些数据结构以便能够后续使用)。
每个bison规则都有一个语义值,当词法分析器返回记号的时候,记号值总会存储在yyval里面,其他语法符号的语义值则在语法分析器的规则里进行设置。
1.3.3 联合编译Flex和Bison程序
前文已经声明过一份flex程序。如果想要和bison联合计算,务必修改一下flex程序。具体就是包含了bison为我们创建的头文件而不是在第一个部分里面的显式的记号值,那个头文件包含了一些极好的编号定义和yylval的定义。
%{
#include <fb1-5.tab.h> //添加了.y文件编译后生成的.h文件
enum yytokentype {
NUMBER = 258,
ADD = 259,
SUB = 260,
MUL = 261,
DIV = 262,
ABS = 263,
EOL = 264
};
int yylval;
%}
%%
"+" { return ADD; }
"-" { return SUB; }
"*" { return MUL; }
"/" { return DIV; }
"|" { return ABS; }
[0-9]+ { return NUMBER; }
\n { return EOL; }
[ \t] { }
. { printf("Mystery charater %c\n", *yyytext); }
%%
/* 由于需要和bison联合,这部分代码也不再需要了。除非是要单独调试.l文件
int main(int argc, char **argv)
{
int tok;
while(tok = yylex){
printf("%d", tok);
if(tok == NUMBER) printf(" = %d",yylval);
else printf("\n");
}
}
*/
fb1-5: fb1-5.l fb1-5.y
bison -d fb1-5.y
flex fb1-5.l
cc -o $@ fb1-5.tab.c lex.yy.c -lfl
1.4 二义性文法
前文的bison文件中的规则部分声明很复杂,是否可以写成如下形式?
exp: exp ADD exp
| exp SUB exp
| exp MUL exp
| exp IDV exp
| ABS exp
| NUMBER
;
/*****************************原来的写法******************************/
calclist: /* nothing 从输入开头进行匹配 */
| calclist exp EOL { printf("= %d\n> ", $2); }
;
exp: factor default $$ = $1
| exp ADD exp { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
;
factor: term default $$ = $1
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER default $$ = $1
| ABS term { $$ = $2 >= 0? $2 : - $2; }
;
原因如下:优先级和二义性。
分开的term,factor,exp的语法可以有效地让bison先处理ABS,再处理MUL/DIV,最后处理ADD/SUB。一旦一种文法有不同优先级,也就是一种操作符比另一种操作符绑定的更紧密时,语法分析器就需要为每种优先级指定一个规则。
bison常用的分析算法可以看做是一个记号用来决定那种规则来匹配输入。有的文法并不具有二义性但是有哪些地方可能需要向前看更多的记号来决定匹配的规则。这就可能导致冲突。
1.5 更多规则的添加
上述的代码可能不是非常完备的。当需要处理圆括号或者注释的话,需要在原有基础上添加一些规则。
bison新加的规则:
%{
#include <stdio.h>
#include <stdlib.h>
#include <stdarg.h>
int yyerror(const char *s,...);
extern int yylex();
extern int yyparse();
%}
/* declare tokens */
%token NUMBER
%token ADD SUB MUL DIV ABS
%token OP CP //定义了左右括号
%token EOL
%%
calclist: /* nothing 从输入开头进行匹配 */
| calclist exp EOL { printf("= %d\n> ", $2); }
| calclist EOL { printf("> "); }
;
exp: factor
| exp ADD exp { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
| exp ABS factor { $$ = $1 | $3; }
;
factor: term
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER
| ABS term { $$ = $2 >= 0? $2 : - $2; }
| OP exp CP { $$ = $2; } //新添加的一个规则,表示括号
;
%%
int main()
{
printf("> ");
yyparse();
return 0;
}
int yyerror(const char *s, ...)
{
int ret;
va_list va;
va_start(va, s);
ret = vfprintf(stderr, s, va);
va_end(va);
return ret;
}
flex新添加的规则
%{
#include "yacc.tab.h" //添加了.y文件编译后生成的.h文件
int yylval;
%}
%%
"+" { return ADD; }
"-" { return SUB; }
"*" { return MUL; }
"/" { return DIV; }
"|" { return ABS; }
[0-9]+ { yylval = atoi(yytext);return NUMBER; }
\n { return EOL; }
[ \t] { }
"(" { return OP; }
")" { return CP; }
"//".* /* 忽略掉注释 */
. { printf("Mystery charater %c\n", *yytext); }
%%
/* 由于需要和bison联合,这部分代码也不再需要了。除非是要单独调试.l文件
int main(int argc, char **argv)
{
int tok;
while(tok = yylex){
printf("%d", tok);
if(tok == NUMBER) printf(" = %d",yylval);
else printf("\n");
}
}
*/
2 Flex的使用——统计单词个数
flex内部使用了强大的正则表达式语言。正则表达式中有特殊意义的字符:
-
[] 字符类,可以匹配方括号中的任意一个字符。如果内部有^符号,则表示“非”。这个字符类别是从ASCII字符编码:[A-z]将匹配所有大小写字母,同时还匹配落在Z和z之间的几个标点符号。
-
[a-z]{-}[jv] 一种不同的字符类别,包含的字符是前一个字符集减去后一个字符集。
-
^ 如果是正则表达式的第一个字符匹配行首。也被方括号中表示补集。
-
$ 如果是正则表达式的最后一个字符就匹配行尾。
-
{} 当花括号中带有一个或者两个数字的时候,表示一个范围:
A{1-3},即匹配1-3个字母A;而0{5}则表示匹配00000。当花括号中带有名字时,则指向以这个名字命名的模式。 -
\ 用来表示元字符自身和一部分常用的C语言转义序列。例如,\n表示换换行符,而*则是字面意义上的星号。
-
* 匹配零个或者多个紧接在前面的表达式。例如,
[ \t]*可以匹配任意个空格和tab,也就是空白字符,能够匹配“ ”,“tab tab”或者一个或多个空字符串。 -
+ 匹配一个或者多个紧接在前面的表达式。例如,[0-9]+可以匹配字符串,像1,11或者123456,但是不是一个空字符串。
-
? 匹配零个或者一个紧接在前面的表达式。例如,-?[0-9]+匹配一个有符号数字,它带有一个可选的前置符号。
-
| 选择操作符,匹配紧接在前面的表达式或者紧跟在后面的表达式。例如:faith|hope|charity中的任何一个。
-
“...” 所有引号的字符将基于字面意义被解释。不属于C转义序列的元字符将失去它的原有特殊意义。
-
() 把一系列的正则表达式组成一个新的正则表达式。例如,(01)匹配字符01,而a(bc|de)匹配abd或者ade。圆括号建立带有*,+,?和|的复杂模式很有用。
-
/ 尾部上下文,匹配斜线前的正则表达式,但是要求其后紧跟着斜线后的表达式。例如,0/1匹配字符串01中的0,但是不会匹配字符串0或者02。斜线后的匹配内容不会被消耗掉,它们会返还给输入以便于继续匹配。每个模式只允许一个尾部上下文操作符。
2.1 正则表达式的例子
不妨假设现在需要匹配一个可选小数点的数字字符串的模式:
[-+]?[0-9]+ : 可选的正负号和数字字符串。
[-+]?[0-9.]+ : 增加了更多的可能性,比如1.2.3.4。
[-+]?[0-9]+\.?[0-9]+ : 有些没有匹配到,比如 .12 和 12.
[-+]?[0-9]*\.?[0-9]+ : 不能匹配 12.
[-+]?[0-9]+\.?[0-9]* : 不能匹配 .12
[-+]?[0-9]*\.?[0-9]* : 可能匹配空字符串和仅有一个小数点的情况。
这说明了字符类的?* +的组合并不能匹配带有一个可选小数点的数值。幸运的是选择操作符|可以帮助实现这一点。
[-+]?([0-9]*\.?[0-9]+|[0-9]+\.)
[-+]?([0-9]*\.?[0-9]+|[0-9]+\.[0-9]*) 这个就过于复杂了,但是也一样有效
如果需要添加一个可选的指数,模式就比较简单:
E(+|-)?[0-9]+
(我们把正负号字符作为选择项而不是字符类的出现,这仅仅是实现方法的不同而已。)
[-+]?([0-9]*\.?[0-9]+|[0-9]+\.)(E(+|-)?[0-9]+)?
2.2 Flex处理二义性的模式
大多数flex程序都有二义性,相同的输入可能会被不同的模式匹配。flex通过两个简单的规则来解决。
- 词法分析匹配输入时匹配尽可能多的字符串。
- 如果两个模式都可以匹配的话,匹配在程序中更早的出现的模式。
例如:
"+" { return ADD; }
"=" { return ASSIGN; }
"+=" { return ASSIGNADD; }
"if" { return KEYWORDIF; }
"else" { return KEYWORDELSE }
[a-zA-Z_][a-zA-Z0-9_]* { return IDENTIFIER; }
对于前三个模式来说,字符串+=被匹配为一个记号,因为+=比+更长。对于后三个模式来说,只要匹配关键字的模式先于匹配标识符的模式,词法分析器就可以正确的匹配关键字。
2.3 Flex词法分析器中的文件I/O操作
2.3.1 单文件操作
主函数中,用户在命令行中给出了文件名,主函数会打开这个文件并赋值给yyin,否则,yyin会保持未赋值的状态,这种情况下yylex会吧stdin赋值给它。
%option noyywrap
%{
int chars = 0;
int words = 0;
int lines = 0;
%}
%%
[a-zA-Z]+ { words++; chars += strlen(yytext); }
\n { chars++;lines++; }
. { chars++; }
%%
int main(int argc, char ** argv)
{
if(argc > 1){
if(!(yyin = fopen(argv[1], "r"))) {
perror(arrgv[1]);
return 1;
}
}
yylex();
printf("%d %d %d",lines, words, chars);
}
2.3.2 多文件操作
%option noyywrap
%{
int chars = 0;
int words = 0;
int lines = 0;
int totchars = 0;
int totwords = 0;
int totlines = 0;
%}
%%
[a-zA-Z]+ { words++; chars += strlen(yytext); }
\n { chars++;lines++; }
. { chars++; }
%%
int main(int argc, char ** argv)
{
int i;
if(argc < 2){
yylex();
printf("%d %d %d",lines, words, chars);
return 0;
}
for(i = 1;i < argc;i++){
FILE *f = fopen(argv[i], "r");
if(!f){
perror(argv[i]);
return 1;
}
yyrestart(f);
yylex();
fclose(f);
printf("%d %d %d %s",lines, words, chars,argv[i]);
totchars += chars; chars = 0;
totwords += words; words = 0;
totlines += lines; lines = 0;
}
if(argc > 1){
printf("%d %d %d",totolines, totwords, totchars);
return 0;
}
}
2.4 Flex词法分析器的I/O结构
2.4.1 Flex词法分析器的输入
大多数情况下,flex词法分析器从文件或者标准输入读取输入。从文件读取或者从终端读取存在着一个微小但是重要的差异——预读机制。
flex词法分析器使用称为YY_BUFFER_STATE的数据结构处理输入,该结构定义一个单一的输入源。包含一个字符串缓冲区和一些变量和标记。有时候会包含一个所读取文件的FILE*,但是我们可以通过创建一个与文件无关的YY_BUFFER_STATE分析已经在内存中的字符串。
一般来说,输入管理的三个层次是:
- 设置yyin来读取所需文件。
- 创建并使用YY_BUFFER_STATE输入缓存区
- 重新定义YY_INPUT
2.4.2 Flex词法分析器的输出
所有没有被匹配的输入都被拷贝到yyout。
#define ECHO fwrite( yytext, yyleng, 1, yyout )
对于一些仅处理一部分输入其余部分保持不变的flex程序来说,flex 的模式标准是好的。flex允许设置%option nodefault,使他不要添加默认的规则。这样当输入无法被给定的规则完全匹配时候,词法分析器可以报告错误。
2.5 起始状态和嵌套输入文件
/* Companion source code for "flex & bison", published by O'Reilly
* Media, ISBN 978-0-596-15597-1
* Copyright (c) 2009, Taughannock Networks. All rights reserved.
* See the README file for license conditions and contact info.
* $Header: /home/johnl/flnb/code/RCS/fb2-3.l,v 2.3 2010/01/04 02:43:58 johnl Exp $
*/
%option noyywrap warn nodefault
%x IFILE
struct bufstack {
struct bufstack *prev; /* previous entry */
YY_BUFFER_STATE bs; /* saved buffer */
int lineno; /* saved line number */
char *filename; /* name of this file */
FILE *f; /* current file */
} *curbs = 0;
char *curfilename; /* name of current input file */
int newfile(char *fn);
int popfile(void);
%%
^"#"[ \t]*include[ \t]*[\"<] { BEGIN IFILE; }
<IFILE>[^ \t\n\">]+ {
{ int c;
while((c = input()) && c != '\n') ;
}
yylineno++;
if(!newfile(yytext))
yyterminate(); /* no such file */
BEGIN INITIAL;
}
<IFILE>.|\n {
fprintf(stderr, "%4d bad include line\n", yylineno);
yyterminate();
}
^. { fprintf(yyout, "%4d %s", yylineno, yytext); }
^\n { fprintf(yyout, "%4d %s", yylineno++, yytext); }
\n { ECHO; yylineno++; }
. { ECHO; }
<<EOF>> { if(!popfile()) yyterminate(); }
%%
main(int argc, char **argv)
{
if(argc < 2) {
fprintf(stderr, "need filename\n");
return 1;
}
if(newfile(argv[1]))
yylex();
}
int
newfile(char *fn)
{
FILE *f = fopen(fn, "r");
struct bufstack *bs = malloc(sizeof(struct bufstack));
/* die if no file or no room */
if(!f) { perror(fn); return 0; }
if(!bs) { perror("malloc"); exit(1); }
/* remember state */
if(curbs)curbs->lineno = yylineno;
bs->prev = curbs;
/* set up current entry */
bs->bs = yy_create_buffer(f, YY_BUF_SIZE);
bs->f = f;
bs->filename = fn;
yy_switch_to_buffer(bs->bs);
curbs = bs;
yylineno = 1;
curfilename = fn;
return 1;
}
int
popfile(void)
{
struct bufstack *bs = curbs;
struct bufstack *prevbs;
if(!bs) return 0;
/* get rid of current entry */
fclose(bs->f);
yy_delete_buffer(bs->bs);
/* switch back to previous */
prevbs = bs->prev;
free(bs);
if(!prevbs) return 0;
yy_switch_to_buffer(prevbs->bs);
curbs = prevbs;
yylineno = curbs->lineno;
curfilename = curbs->filename;
return 1;
}
2.5.1 起始状态
起始状态允许我们在特定特定时刻哪些模式可以被匹配。文件顶部的%x IFILE定义为起始状态,它将在我们寻找#include语句中的文件名的时候被使用。在任何时候,这个词法分析器都处于一个起始状态中,并且只匹配这个状态所激活的那些模式。
%option noyywrap warn nodefault
%x IFILE
struct bufstack {
struct bufstack *prev; /* previous entry */
YY_BUFFER_STATE bs; /* saved buffer */
int lineno; /* saved line number */
char *filename; /* name of this file */
FILE *f; /* current file */
} *curbs = 0;
char *curfilename; /* name of current input file */
int newfile(char *fn);
int popfile(void);
%%
第一个模式匹配#include语句,知道遇见文件名之前的双引号为止。如果第一个模式得到了匹配,词法分析器会切换到IFILE状态,读取接下来的文件名。IFILE的第二个模式匹配一个文件名,直到遇到结束引号、空白字符或者行结束符。
由于独占的起始状态IFILE定义了一个小型的词法分析器,因此这个词法分析器必须能处理任何可能的输入。第二个IFILE模式是用来匹配不规范的#include行的输入,只需要打印错误信息并调用宏yyterminate()来立即从词法分析器返回。
接下来是<<EOF>>,它所匹配的是输入文件的结束。我们调用后面定义的popfile()来返回前一个输入文件。如果返回为0,意味着这是最后一个文件;否则将从上次的位置继续分析。
%%
^"#"[ \t]*include[ \t]*[\"<] { BEGIN IFILE; }
<IFILE>[^ \t\n\">]+ {
{
int c;
while((c = input()) && c != '\n') ;
}
yylineno++;
if(!newfile(yytext))
yyterminate(); /* no such file */
BEGIN INITIAL;
}
<IFILE>.|\n {
fprintf(stderr, "%4d bad include line\n", yylineno);
yyterminate();
}
^. { fprintf(yyout, "%4d %s", yylineno, yytext); }
^\n { fprintf(yyout, "%4d %s", yylineno++, yytext); }
\n { ECHO; yylineno++; }
. { ECHO; }
<<EOF>> { if(!popfile()) yyterminate(); }
%%
2.5.2 嵌套输入文件
newfile(fn)在文件名为fn的文件的同时保存前面所有输入文件的信息。bufstack结构维护一个逆向链表,每一个节点保存了yylineno和文件名的信息。这个例程打开文件,创建并切换到flex的缓冲区,并且保存前一个打开的文件、文件名和缓冲区。
int
newfile(char *fn)
{
FILE *f = fopen(fn, "r");
struct bufstack *bs = malloc(sizeof(struct bufstack));
/* die if no file or no room */
if(!f) { perror(fn); return 0; }
if(!bs) { perror("malloc"); exit(1); }
/* remember state */
if(curbs)curbs->lineno = yylineno;
bs->prev = curbs;
/* set up current entry */
bs->bs = yy_create_buffer(f, YY_BUF_SIZE);
bs->f = f;
bs->filename = fn;
yy_switch_to_buffer(bs->bs);
curbs = bs;
yylineno = 1;
curfilename = fn;
return 1;
}
popfile和newfile刚好相反。它关闭打开的文件,删除当前的flex缓冲区,然后从前一个堆栈项恢复缓冲区、文件名和行号。恢复前一个缓冲区的时候它没有调用yyrestart(),如果调用了yyrestart(),将会丢失已经读入缓冲区的输入。
int
popfile(void)
{
struct bufstack *bs = curbs;
struct bufstack *prevbs;
if(!bs) return 0;
/* get rid of current entry */
fclose(bs->f);
yy_delete_buffer(bs->bs);
/* switch back to previous */
prevbs = bs->prev;
free(bs);
if(!prevbs) return 0;
yy_switch_to_buffer(prevbs->bs);
curbs = prevbs;
yylineno = curbs->lineno;
curfilename = curbs->filename;
return 1;
}
2.6 符号表和重要语汇索引生成器
基本上每个flex和bison都会使用符号表(symbol table)来记录输入中使用的名称。我们用一个非常简单的程序作为例子,会生成重要与会索引,也就是输入中出现的各个单词所在行号的列表,然后将其修改为一个能够读取C语言的交叉引用程序。
2.6.1 管理符号表
重要语汇索引的符号表只需要简答的记录每个单词以及其它们所在文件的行号。
%option noyywrap nodefault yylineno case-insensitive
/* the symbol table */
%{
struct symbol { /* a word */
struct ref *reflist;
char *name;
};
struct ref {
struct ref *next;
char *filename;
int flags;
int lineno;
};
/* simple symtab of fixed size */
#define NHASH 9997
struct symbol symtab[NHASH];
struct symbol *lookup(char*);
void addref(int, char*, char*, int);
char *curfilename; /* name of current input file */
%}
%%
%option行有两个以前没有见过的选项,都非常有用。选项%yylineno告诉flex定义一个名为yylineno的整形变量用来保存行号。(yylineno一般必须初始化为1),对于包含文件的情况,还需要额外的保存和恢复的动作。即使有这样一些规则,仍然比手动维护行号简单。
case-insensitice,他要求flex是一个大小写无关的词法分析器。
此处的符号表也就是一个symbol结构的数组,每个结构包含一个指向名称的指针以及引用列表。
/* skip common words */
a |
an |
and |
are |
as |
at |
be |
but |
for |
in |
is |
it |
of |
on |
or |
that |
the |
this |
to /* ignore */
[a-z]+(\'(s|t))? { addref(yylineno, curfilename, yytext, 0); }
.|\n /* ignore everything else */
%%
重要语汇索引通常不索引常见的短词,因此第一个模式将忽视它们( /* ignore */ )。包函数线的语义动作告知它与下一条规则的语义动作一致。最后一个忽略单词的语义动作并不做任何事情,这样就忽略了这个单词。
[a-z]+(\'(s|t))?是词法分析器的主体,大致匹配一个英文单词。后面接着's或者't。**每一个匹配的单词都会和当前文件名以及行号一起传递给稍后会讲到的addref()。
.|\n模式匹配所有前面没有匹配到的字符。
当两个模式都可以匹配的时候,flex将匹配更早出现的。所以要把忽略规则前置,全匹配后置。
main(argc, argv)
int argc;
char **argv;
{
int i;
if(argc < 2) { /* just read stdin */
curfilename = "(stdin)";
yylineno = 1;
yylex();
} else
for(i = 1; i < argc; i++) {
FILE *f = fopen(argv[i], "r");
if(!f) {
perror(argv[1]);
return (1);
}
curfilename = argv[i]; /* for addref */
yyrestart(f);
yylineno = 1;
yylex();
fclose(f);
}
printf("old = %d, new = %d, total = %d, probes = %d, avg = %1.2f\n",
nold, nnew, nold+nnew, nprobe, (float)nprobe / (nold+nnew));
printrefs();
}
主函数和读取多个文件的字数的程序非常相似。依次打开每个文件,使用yyrestart安排读取文件,然后调用yylex。额外的工作是把curfilename设置为文件名,便于构造引用列表,并且为每个文件设置yylineno为1(否则行号将会从一个文件到另一个文件进行累加)最后,printrefs会把符号表按顺序排列并打印出可引用的信息。
2.6.2 使用符号表
词法分析器的代码包含了一个简单的符号表例程,一个添加单词到符号表的历程以及一个在所有输入被运行后打印出重要语汇索引的例程。
lookup获取一个字符串并返回用于这个字符串名称的符号表目的位置,如果名字不存在的话就创建它。名字查找技术称为线性探测的哈希算法。使用哈希函数吧字符串转化为符号表中的条目号,然后检查这个条目,如果该条目会被一个不同符号占用时就顺序检查下一个条目直到有可用的为止。
哈希函数对于每个字符,首先用9乘以一个哈希值,然后再xor这个字符,所有的操作都基于无符号数以避免溢出的情况。查找例程通过把哈希值对符号表的大小取模来得到符号表的索引。
/* hash a symbol */
static unsigned
symhash(char *sym)
{
unsigned int hash = 0;
unsigned c;
while(c = *sym++) hash = hash*9 ^ c;
return hash;
}
int nnew, nold;
int nprobe;
struct symbol *
lookup(char* sym)
{
struct symbol *sp = &symtab[symhash(sym)%NHASH];
int scount = NHASH; /* how many have we looked at */
while(--scount >= 0) {
nprobe++;
if(sp->name && !strcmp(sp->name, sym)) { nold++; return sp; }
if(!sp->name) { /* new entry */
nnew++;
sp->name = strdup(sym);
sp->reflist = 0;
return sp;
}
if(++sp >= symtab+NHASH) sp = symtab; /* try the next entry */
}
fputs("symbol table overflow\n", stderr);
abort(); /* tried them all, table is full */
}
每当lookup创在一个新的条目,他就会调用strup来产生字符串的拷贝并放到符号表条目中。flex和bison程序会经常存在难以跟踪的字符串存储管理问题。主要是因为yytext中的字符串会在下个词法记号被分析师被替换掉。
void
addref(int lineno, char *filename, char *word, int flags)
{
struct ref *r;
struct symbol *sp = lookup(word);
/* don't do dups */
if(sp->reflist &&
sp->reflist->lineno == lineno && sp->reflist->filename == filename) return;
r = malloc(sizeof(struct ref));
if(!r) {fputs("out of space\n", stderr); abort(); }
r->next = sp->reflist;
r->filename = filename;
r->lineno = lineno;
r->flags = flags;
sp->reflist = r;
}
接下来是addref,词法分析器用它来调用来添加对特定单词的引用,这个例程基于引用结构的链表来实现。为了让报告可以变得更短一些,如果符号已经有一个对同行好和文件名的应用,则它不会添加为这个引用。这里不会创建文件名的拷贝,因为知道这个字符串在调用放并不会改变。也不会拷贝单词,因为lookup会帮我们处理它。每一个引用都有一个flag值,他将会在下个例子中被使用。
/* aux function for sorting */
static int
symcompare(const void *xa, const void *xb)
{
const struct symbol *a = xa;
const struct symbol *b = xb;
if(!a->name) {
if(!b->name) return 0; /* both empty */
return 1; /* put empties at the end */
}
if(!b->name) return -1;
return strcmp(a->name, b->name);
}
void
printrefs()
{
struct symbol *sp;
qsort(symtab, NHASH, sizeof(struct symbol), symcompare); /* sort the symbol table */
for(sp = symtab; sp->name && sp < symtab+NHASH; sp++) {
char *prevfn = NULL; /* last printed filename, to skip dups */
/* reverse the list of references */
struct ref *rp = sp->reflist;
struct ref *rpp = 0; /* previous ref */
struct ref *rpn; /* next ref */
do {
rpn = rp->next;
rp->next = rpp;
rpp = rp;
rp = rpn;
} while(rp);
/* now print the word and its references */
printf("%10s", sp->name);
for(rp = rpp; rp; rp = rp->next) {
if(rp->filename == prevfn) {
printf(" %d", rp->lineno);
} else {
printf(" %s:%d", rp->filename, rp->lineno);
prevfn = rp->filename;
}
}
printf("\n");
}
}
最后一部分对符号表进行排序和打印。使用qsort函数对符号表按照字母表顺序进行排序。由于符号表不一定被用完,所以排序函数把没有使用的条目放到使用的条目后面,这样排序后的使用条目在符号表的前端。
接着printrefs自上而下打印符号表中对每个单词的引用。引用被存储在一个链表中,由于每个引用被压入链表前端,事实上是倒序的。所以要翻转整个链表来使他变成顺序排列,然后进行打印。为了让重要语汇索引可读性更好一点,仅在文件名有变化时才打印文件名。同时只是比较文件名的置身,因为照理来说用于相同条目蒋志祥同一个文件名拷贝。
2.7 C语言的交叉引用
/* fb2-5 C cross-ref */
%option noyywrap nodefault yylineno
%x COMMENT
%x IFILE
/* some complex named patterns */
/* Universal Character Name */
UCN (\\u[0-9a-fA-F]{4}|\\U[0-9a-fA-F]{8})
/* float exponent */
EXP ([Ee][-+]?[0-9]+)
/* integer length */
ILEN ([Uu](L|l|LL|ll)?|(L|l|LL|ll)[Uu]?)
/* the symbol table */
第一个模式匹配通用字符名称,一种在字符串和标识符中放置非ASCII码字符的方法:通用字符名由跟在\u后的4个16进制或者跟在\u 后面的8个十六进制数表示。
第二个模式是浮点类型的指数部分。
第三个模式表示无符号的整形数字。
%{
struct symbol { /* 变量名称 */
struct ref *reflist;
char *name;
};
struct ref {
struct ref *next;
char *filename;
int flags; /* 01 - definition */
int lineno;
};
/* 简单的固定大小的符号表 */
#define NHASH 9997
struct symbol symtab[NHASH];
struct symbol *lookup(char*);
void addref(int, char*, char*, int);
char *curfilename; /* 当前输入文件的名称 */
int defining; /* 名称是否是定义 */
/* 文件堆栈 */
struct bufstack {
struct bufstack *prev; /* 前一个条目 */
YY_BUFFER_STATE bs; /* 保存的缓冲区 */
int lineno; /* 保存文件的行号 */
char *filename; /* 文件名 */
FILE *f; /* 当前文件 */
} *curbs;
int newfile(char *fn);
int popfile(void);
%}
接下来规则部分
%%
/* comments */
"/*" { BEGIN(COMMENT) ; }
<COMMENT>"*/" { BEGIN(INITIAL); }
<COMMENT>([^*]|\en)+|.
/* C++ comment, a common extension */
"//".*\n
独占的起始状态使词法分析器更容易被匹配注释。
第一个规则在看到/*时激活comment状态,而第二个规则在遇到*/时会切换回正常的INITIAL状态。
第三个规则匹配两者之间的一切字符。
之所以采取([^*]|\n)+,是因为这种方式一次就匹配一长串文本。这是因为这个方式排除了*,因此第二个规则才能够匹配*/。
C语言注释的模式
虽然单一的flex模式可以匹配C语言注释,但是这也做并不是一个好主意。可以参考如下模式:
/\*([^*]|\*+[^/*])*\*+/他匹配开始一个注释的两个字符,
/\*;接着是一连串的不带星号的字符或者尾部不带星号和斜线的一连串星号,([^*]|\*+[^/*])*;最后是一个或者多个星号外加一个结束的斜线,\*+/。有两个原因让我们更倾向于使用多个模式和其实状态。一个原因是注释可能更长,在注释占据了若干代码时候会有问题,因为flex的记号有一定的输入缓冲的长度限制,通常是16K(这种错误不太会被测试到)。另外一个原因是多个模式更容易发现和诊断没有结束的注释。虽然通过修改前面的模式可以匹配到,但是这更容易发成超过16K长度限制的情况。
/* declaration keywords */
_Bool |
_Complex |
_Imaginary |
auto |
char |
const |
double |
enum |
extern |
float |
inline |
int |
long |
register |
restrict |
short |
signed |
static |
struct |
typedef |
union |
unsigned |
void |
volatile { defining = 1; }
/* keywords */
break
case
continue
default
do
else
for
goto
if
return
sizeof
switch
while
下面是匹配所有C语言关键字的模式。对于引入声明或者定义的关键字我们将设置defining标志,对其他关键字不需要做任何事情。
/* 常量 */
/* 整数 */
0[0-7]*{ILEN}?
[1-9][0-9]*{ILEN}?
0[Xx][0-9a-fA-F]+{ILEN}?
/* 十进制 浮点数 */
([0-9]*\.[0-9]+|[0-9]+\.){EXP}?[flFL]?
[0-9]+{EXP}[flFL]?
/* 十六进制 浮点数 */
0[Xx]([0-9a-fA-F]*\.[0-9a-fA-F]+|[0-9a-fA-F]+\.?)[Pp][-+]?[0-9]+[flFL]?
数字的模式非常复杂,我们的命名模式ILEN和EXP可以使处理变得更为简单。
接下来是字符常量,和字符串常量。字符常量由单引号开始,其后面可以使一个或者多个非单引号和反斜线的普通字符,或者是通过反斜线转义的字符比如\n,或者是以转义符开始的最多三个八进制数字,或者是以转义符开始的一定数量的十六进制数字,或者是通过通用字符名称,最后都以单引号结尾。字符串字面量基本类似,除了它通过双引号引起,并且带有一个可选的前缀L来表明一个宽字符串,并且它也可以为空。
/* 字符常量 */
\'([^'\\]|\\['"?\\abfnrtv]|\\[0-7]{1,3}|\\[Xx][0-9a-fA-F]+|{UCN})+\'
/* 字符串字面量 */
L?\"([^\"\\]|\\['"?\\abfnrtv]|\\[0-7]{1,3}|\\[Xx][0-9a-fA-F]+|{UCN})+\"
C语言将操作符和标点都称为标点符号。这里我们额外定义了表明变量名或者函数定义结束的三种模式,其余的无需特别处理。
标识符由字母、下划线与通用字符名开头,后面是可选的更多字母、下划线、通用字符名以及数字、当我们遇到一个标识符时,就在符号表中添加一个对其的引用。
/* 标点符号 */
"{"|"<%"|";" { defining = 0; }
"["|"]"|"("|")"|"{"|"}"|"."|"->"
"++"|"--"|"&"|"*"|"+"|"-"|"~"|"!"
"/"|"%"|"<<"|">>"|"<"|">"|"<="|">="|"=="|"!="|"^"|"|"|"&&"|"||"
"?"|":"|";"|"..."
"="|"*="|"/="|"%="|"+="|"-="|"<<="|">>="|"&="|"^=""|="
","|"#"|"##"
"<:"|":>"|"%>"|"%:"|"%:%:"
/* 标识符 */
([_a-zA-Z]|{UCN})([_a-zA-Z0-9]|{UCN})* {
addref(yylineno, curfilename, yytext, defining); }
/* 空白字符 */
[ \t\n]+
/* 续行符 */
\\$
/* some preprocessor stuff */
"#"" "*if.*\n
"#"" "*else.*\n
"#"" "*endif.*\n
"#"" "*define.*\n
"#"" "*line.*\n
/* recognize an include */
^"#"[ \t]*include[ \t]*[\"<] { BEGIN IFILE; }
<IFILE>[^>\"]+ {
{ int c;
while((c = input()) && c != '\n') ;
}
newfile(strdup(yytext));
BEGIN INITIAL;
}
<IFILE>.|\n { fprintf(stderr, "%s:%d bad include line\n",
curfilename, yylineno);
BEGIN INITIAL;
}
<<EOF>> { if(!popfile()) yyterminate(); }
最后一个模式就是匹配之前所有没有处理到的字符。由于这个模式覆盖了有效C程序中可能出现的每个记号,所以事实上不应该被匹配到。
/* invalid character */
. { printf("%s:%d: Mystery character '%s'\n",
curfilename, yylineno, yytext);
}
%%
接下来是代码部分
/* hash a symbol */
static unsigned
symhash(char *sym)
{
unsigned int hash = 0;
unsigned c;
while(c = *sym++) hash = hash*9 ^ c;
return hash;
}
struct symbol *
lookup(char* sym)
{
struct symbol *sp = &symtab[symhash(sym)%NHASH];
int scount = NHASH; /* how many have we looked at */
while(--scount >= 0) {
if(sp->name && !strcmp(sp->name, sym)) { return sp; }
if(!sp->name) { /* new entry */
sp->name = strdup(sym);
sp->reflist = 0;
return sp;
}
if(++sp >= symtab+NHASH) sp = symtab; /* try the next entry */
}
fputs("symbol table overflow\n", stderr);
abort(); /* tried them all, table is full */
}
void
addref(int lineno, char *filename, char *word, int flags)
{
struct ref *r;
struct symbol *sp = lookup(word);
/* don't do dups */
if(sp->reflist &&
sp->reflist->lineno == lineno && sp->reflist->filename == filename) return;
r = malloc(sizeof(struct ref));
if(!r) {fputs("out of space\n", stderr); abort(); }
r->next = sp->reflist;
r->filename = filename;
r->lineno = lineno;
r->flags = flags;
sp->reflist = r;
}
/* print the references
* sort the table alphabetically
* then flip each entry's reflist to get it into forward order
* and print it out
*/
/* aux function for sorting */
static int
symcompare(const void *xa, const void *xb)
{
const struct symbol *a = xa;
const struct symbol *b = xb;
if(!a->name) {
if(!b->name) return 0; /* both empty */
return 1; /* put empties at the end */
}
if(!b->name) return -1;
return strcmp(a->name, b->name);
}
void
printrefs()
{
struct symbol *sp;
qsort(symtab, NHASH, sizeof(struct symbol), symcompare); /* sort the symbol table */
for(sp = symtab; sp->name && sp < symtab+NHASH; sp++) {
char *prevfn = NULL; /* last printed filename, to skip dups */
/* reverse the list of references */
struct ref *rp = sp->reflist;
struct ref *rpp = 0; /* previous ref */
struct ref *rpn; /* next ref */
do {
rpn = rp->next;
rp->next = rpp;
rpp = rp;
rp = rpn;
} while(rp);
/* now print the word and its references */
printf("%10s", sp->name);
for(rp = rpp; rp; rp = rp->next) {
if(rp->filename == prevfn) {
printf(" %d", rp->lineno);
} else {
printf(" %s:%d", rp->filename, rp->lineno);
prevfn = rp->filename;
}
if(rp->flags & 01) printf("*");
}
printf("\n");
}
}
接下来主程序调用newfile,如果成果的话,为每个文件执行yylex。
int
main(argc, argv)
int argc;
char **argv;
{
int i;
if(argc < 2) {
fprintf(stderr, "need filename\n");
return 1;
}
for(i = 1; i < argc; i++) {
if(newfile(argv[i])) yylex();
}
printrefs();
return 0;
}
newfile无法打开一个文件时候,只是打印一个错误消息;能够在打开文件时返回1,反正则返回0;而规则处理部分包含文件的代码将继续处理下一行。
/* nested input files */
int
newfile(char *fn)
{
FILE *f = fopen(fn, "r");
struct bufstack *bs;
/* check if no file */
if(!f) {
perror(fn);
return 0;
}
bs = malloc(sizeof(struct bufstack));
if(!bs) { perror("malloc"); exit(1); }
/* remember state */
if(curbs) curbs->lineno = yylineno;
bs->prev = curbs;
bs->f = f;
bs->filename = fn;
/* set up current entry */
bs->bs = yy_create_buffer(f, YY_BUF_SIZE);
yy_switch_to_buffer(bs->bs);
curbs = bs;
yylineno = 1;
curfilename = fn;
return 1;
}
int
popfile(void)
{
struct bufstack *bs = curbs;
struct bufstack *prevbs;
if(!bs) return 0;
/* get rid of current entry
fclose(bs->f);
yy_delete_buffer(bs->bs);
/* switch back to previous */
prevbs = bs->prev;
free(bs);
if(!prevbs) return 0;
yy_switch_to_buffer(prevbs->bs);
curbs = prevbs;
yylineno = curbs->lineno;
curfilename = curbs->filename;
return 1;
}