參考:
https://blog.csdn.net/u013007900/article/details/79008993
https://blog.csdn.net/u013007900/article/details/79049187
技術面試的系統設計題(一)
本文為課程翻譯和學習筆記,課程地址System Design for Tech Interviews。
關於課后題,這兒就不公布答案了。應該還是比較簡單的。
什么是系統設計題
在面試的時候,面試官經常會讓我們設計一些系統,比如:
- 設計一個像bit.ly一樣的URL縮短服務。
- 你將如何實現谷歌搜索?
- 設計一個C/S應用程序,允許人們互相下棋。
- 如何將關系存儲在Facebook這樣的社交網絡中呢?並實現一個當用戶的朋友喜歡與他們一樣的東西時,用戶會收到通知的功能。
這些問題起初似乎很嚇人。畢竟,我們怎么可能在20-30分鍾內設計出Google搜索。
這些問題的關鍵點是討論解題的過程。對面試官來說重要的是你解決問題的過程。這種討論的典型結果是一個高層次的架構,從而在有限制的情況下解決這個問題。也許面試官會選擇一個或多個他們想討論的系統瓶頸和其他常見問題來更加具體地詢問你。
請記住,沒有一個標准的正確的答案。系統可以用不同的方式建立。重要的是能夠證明你的想法。
最后,請記住,根據面試官的目標,關於同一個系統設計問題的討論可能會有不同的方向。他們可能願意看到你如何創建一個涵蓋系統各個方面的高層架構。也可能,他們會更關注一些特定的領域並深入研究。無論如何,你應該有一個如何處理不同情況的策略。
第一步:限制與用例
就像算法設計一樣,系統設計問題的細節也很可能會被弱化。考慮關於URL縮短服務的問題(“設計一個像bit.ly的URL縮短服務”)。題目的信息非常少,如果不知道更多限制和要求,是不可能設計一個合適的解決方案。事實上,面試官並不會一開始就告訴你所有的信息,很多人都忘記了這一點,並立即開始設計解決方案。
對任何系統設計問題你應該做的第一件事是明確系統的限制,並確定系統需要滿足哪些用例。花幾分鍾詢問你的面試官,並統一系統的規模。我們在討論算法設計時所討論的許多相同的規則也適用於此處。
通常情況下,面試者希望看到的是你能收集到關於問題的要求,並設計一個能很好地覆蓋這些要求的解決方案。永遠不要假設面試官沒有明確說明的事情。
例如,縮短網址的服務可能只能為幾千個用戶提供服務,但每個用戶都可以共享數百萬個網址。這可能意味着要處理數百萬次縮短網址。該服務可能需要提供有關每個縮短的URL的統計信息(這會增加需要處理的數據大小),或者根本不需要統計信息。
您還需要考慮預期會發生的用例,您的系統將根據預期的目標進行設計。
用例
- 縮短:將一個url轉化為縮短的url
- 重定向:得到一個縮短的url,跳轉到原url
- 用戶自己設計一個縮短的url
- CAP中,取高可用性
限制
一般來說,大部分限制是來自於數據規模的限制。比如每分鍾的數據量,訪問人數等等。
如果你去問面試官,他可能直接給你數據,比如,我們每秒要處理400個請求;或者,他會說一些更籠統的信息讓你去估計,比如,這個網站不是top 3但是卻是top 10的。
在估算的時候,一定要注意合理。通常而言,用二八定律是一個非常重要的准則。
- 系統每個月需要處理的數據是100×106100×106
- 推特一個月產生15×10915×109的推文
- 每個月需要進行縮短的新URL只占了10%,總計1.5×1091.5×109
- TOP3以下的縮短URL網站只處理了20%的數據,也就是300×106300×106的數據
- 我們的系統,需要處理100×106100×106的數據
- 5年之內會產生6×1096×109條URL,占用空間3TB;hash表占用空間36GB
- 每個縮短的URL占用500 bytes和6 bytes的hash
-
系統需要處理的請求是每個月1×1091×109
- 考慮URL的壽命,平均為1~2周,這兒可以假設10天
- 每天有一個請求
- 100 mln×10 days×1 click/day=1 bln100 mln×10 days×1 click/day=1 bln
- 請求的分類:10%是進行縮短,90%是進行重定向
- 每秒有400+的請求,40是進行縮短,360是進行重定向
-
每秒需要寫入的新數據:40×(500+6)=20 K40×(500+6)=20 K
- 每秒需要讀取的數據:360×506=180 K360×506=180 K
關於這些限制的估計,人為主觀因素有較大影響,不過在面試的時候除非估計得特別離譜,面試官一般不太會糾結於這方面,基本按照二八原則來估計就行了。
具體的估算過程見下圖。

第二步:抽象設計
一旦你確定了你要設計的系統,你應該描述一個高層次的抽象設計。這步的目標是概述您的架構將需要的所有重要組件,而不是深入到抽象設計的某個方面,或者,直接一部分一部分來設計。
你可以告訴面試官,你想這樣做,並畫出你的想法的簡單圖表。勾畫您的主要組件和它們之間的連接,在面試官面前證明你的想法,並試圖解決每一個約束和用例。
如果你這樣做,面試官會很快也很輕易地給你反饋。
通常,這種高級設計是人們已經開發的眾所周知的技術的組合,比如,緩存,數據庫讀寫分離等等。你必須確保你熟悉那里的東西,並且能夠流暢地使用這些知識。這個地方就需要大家去多看書或者技術博客了。
值得注意的是,如果您的設計不能改滿足面試官的要求,如,面試官要求高度的一致性約束,而您只能做到基本一致性,這是絕對不允許的。
- 應用服務層
- shortening server
- 可以簡單地解釋一下是如何實現的:使用hash,查看URL是否已經存在於存儲中,若是沒有,則進行hash和存儲
- redirection server
- shortening server
- 數據存儲層
- 用於存儲hash→→url的映射關系
- 不必提到具體的數據庫或者其他的細節,可以大致說明,它的運行方式像一個非常大的緩存系統:存儲新的映射關系,通過key得到value。
- 設計hash方式
第三部:理解瓶頸所在
考慮到問題的限制,您的高層設計有可能會有一個或多個瓶頸。這其實非常好。沒有人能夠一步到位地設計一個能夠直接處理世界上所有負載的系統。我們希望的是這個系統具有可擴展性,以便您能夠使用一些標准的工具和技術來改進它。
現在你有了高層次的設計,開始思考它有什么瓶頸。也許你的系統需要一個負載平衡器和許多機器來處理用戶請求。也許需要存儲的數據量太大了,系統應該使用分布式的數據庫。這樣做有什么缺點?分布式數據庫是否太慢,是否需要一些內存中的緩存?
這些只是為了使您的解決方案完整而必須回答的問題的示例。面試官可能會希望在一個特定的方向上進行討論。那么,也許你不需要解決所有的瓶頸問題,而是更深入地討論一個特定的領域。無論如何,您需要能夠之處系統的弱點,並能夠解決這些問題。
請記住,通常每個解決方案都是某種權衡:改善一些方面會導致其他方面的惡化。然而,重要的是要能夠談論這些權衡,並根據所定義的約束和用例來衡量它們對系統的影響。
- 應用服務層
- 縮短操作,每秒處理20k的數據,包輸入輸出和一個簡單的hash操作。這明顯不是瓶頸所在。
- 重定向操作,每秒處理180k的數據,包括輸入輸出。這明顯不是瓶頸所在。
- 數據存儲層
- 如何准確地得到key的value,我們的數據有5TB,所以系統不可能線性掃描整個數據集。
總結
當你和面試官就上面的問題達成一致,你可以深入到某些方面的細節。
技術面試的系統設計題(二)
可擴展性
基礎
現在您已經設計了一個可靠的抽象體系結構,下一步就是將其擴展。如果你從來沒有建立過大規模的系統,這個任務看起來有點令人生畏。
除了接下來的一個視頻和四篇博文的翻譯,你也可以看看An Unorthodox Approach To Database Design : The Coming Of The Shard
可擴展的Web開發
比較建議看一看視頻,視頻里面講的非常雜亂,感覺沒有什么邏輯,所以我整理的也是亂七八糟。他說的東西也是非常基礎的,但是鞏固一下也是很不錯的。
具體的一些技術方面的大致情況可以看看這篇博文,里面講到了Web服務器從基礎到復雜的擴展過程。比這個課更有邏輯。
垂直擴展
對於一台服務器使用更多的更好的硬件,如下資源
- CPU
- cores, L2 Cache, …
- Disk
- 接口:PATA, SATA, SAS, …
- RAID
- RAM
限制:沒有那么多物理資源
水平擴展
不同於垂直擴展那樣選用最貴最好的服務器,水平擴展接受了便宜的硬件設施,但是用了更多的便宜且更慢的服務器實現了擴展。也就是,使用了大規模的集群分布式。
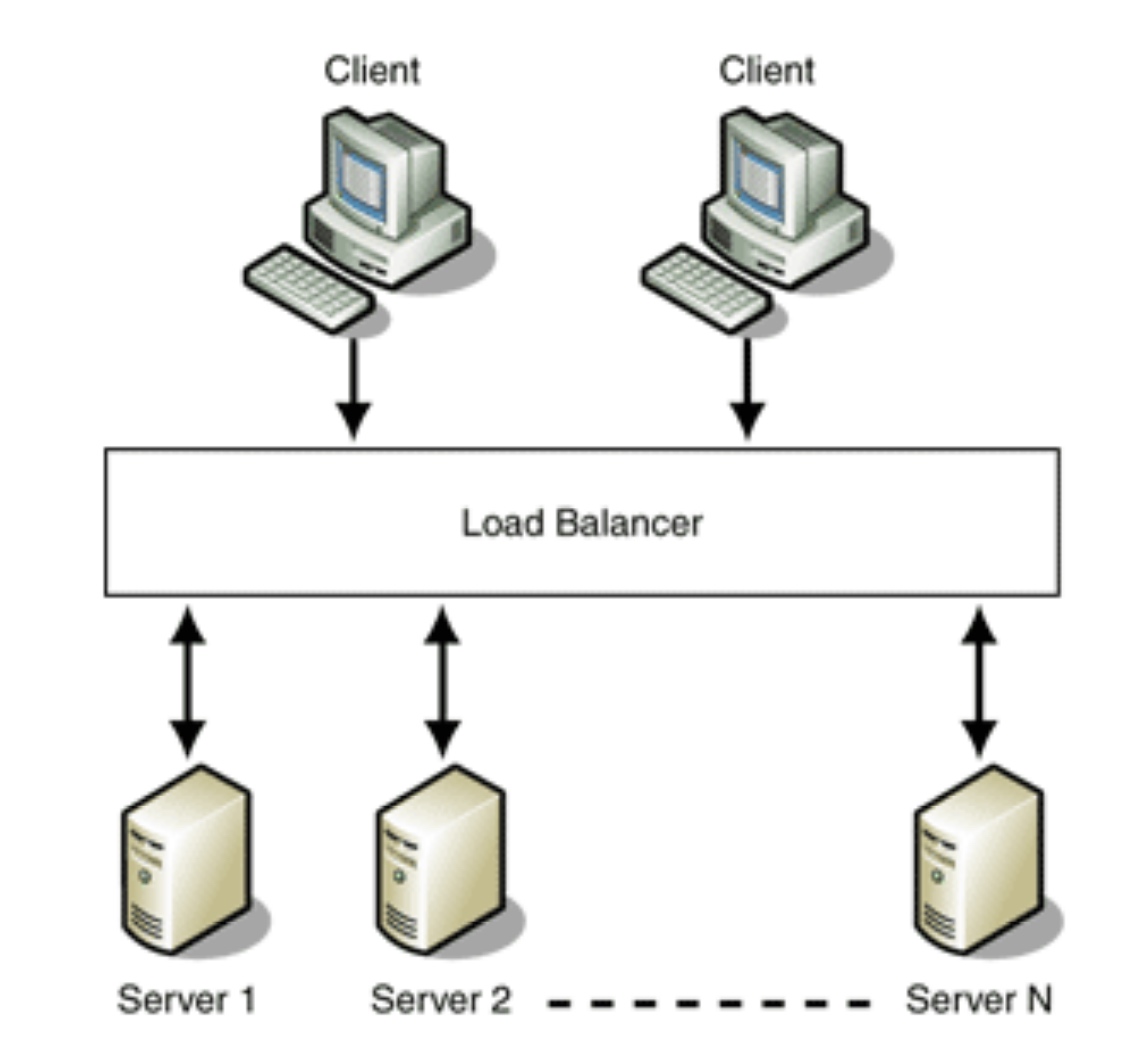
負載均衡
通過Load Balancer將服務集群黑盒化,那么對於外界而言,他們始終以為訪問的是一個服務器。
Load Balancer具有一個公開的IP地址,而后端服務器不需要公開的IP地址,而是用內網IP地址。類似NAT協議那樣。
關於負載均衡的算法由很多,比如,Round Robin算法(一種以輪詢的方式依次將一個域名解析到多個IP地址的調度不同服務器的計算方法。)
開源的DNS系統BIND對於同樣的域名請求,可能會返回不同的IP地址。
- 軟件
- ELB
- HAProxy
- LVS
- 硬件
- Barracuda
- Cisco
- Citrix
- F5
共享存儲
RR可能會導致服務器1總是受到請求,從而導致堵塞。即,因為負載均衡算法的缺陷,導致負載均衡效果不理想。
sticky session問題:如果你登陸一個網址好多次,你的cookies和session等信息會分布在不同的機器上。那么如果你的請求被分發到一個新的機器上,那么這些就不復存在了,你必須重新登陸,重新添加購物車,這明顯是不行的。
為了讓負載均衡器能夠明白每一個Server所處的狀態,為了讓所有Server的信息都保持一致,我們會使用共享存儲的設計。
但是同樣的共享存儲也是有一定缺陷的:
- 如果所有系統都使用一塊硬盤,如果這塊硬盤掛了,那么所有的服務器都不能使用了。
- 如果按照功能進行分機和存儲相應的數據,如,處理用戶登錄請求和用戶cookies的記錄,視頻媒體等存儲。如果最關鍵的那台服務器宕機了,整個服務也就都沒有用了。
於是,我們可以使用增加硬盤數量實現備份。比如,我們同時用兩塊硬盤存儲同一份數據的兩個副本,這樣雖然增加了一些overhead,但是能夠實現備份。(關於這點還有很多論文去解釋和設計相應的系統,比如raft一致性協議等等)。
同時我們也可以使用兩塊硬盤存儲一份數據的不同部分,當一塊在寫的時候,我們可以寫另一塊。並行地運行寫入程序。
Cacheing
HTML文件
簡單地將HTML存儲下來,或者以HTML模板的形式存儲一些不怎么需要更改的內容。
SQL Cache
查詢的緩存,可見其他數據庫的設計情況。
Memcached
其他第三方內存數據庫,用於緩存。還有比如,reids等等。
但是也需要一些別的協議或者機制來維護這類的緩存,如,同步問題, 垃圾回收
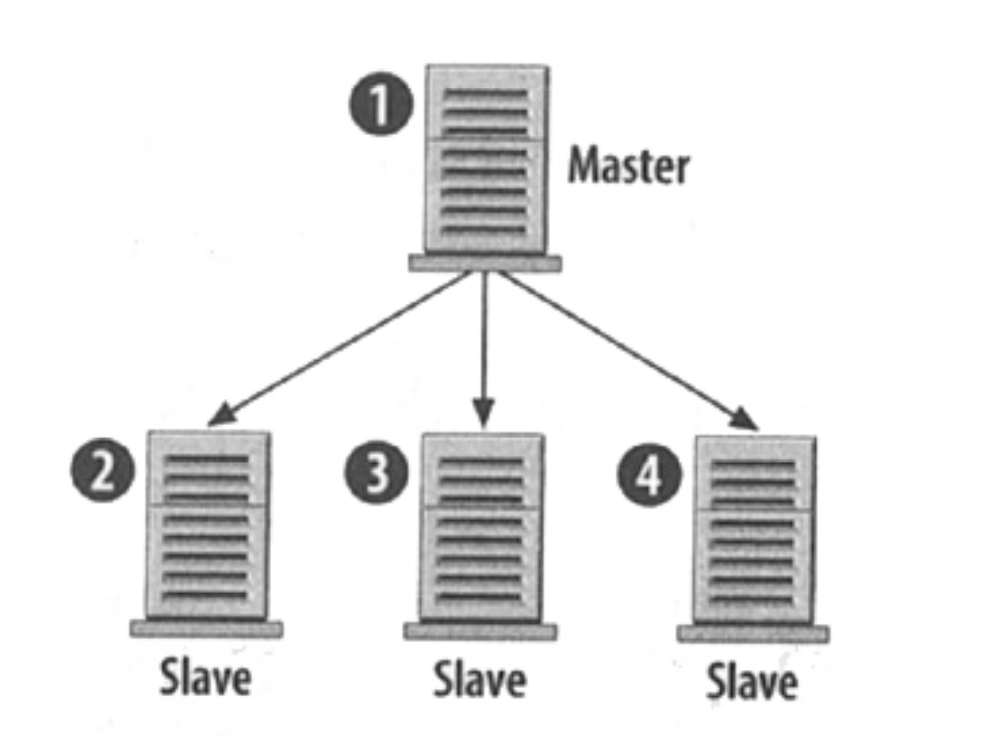
主從模式
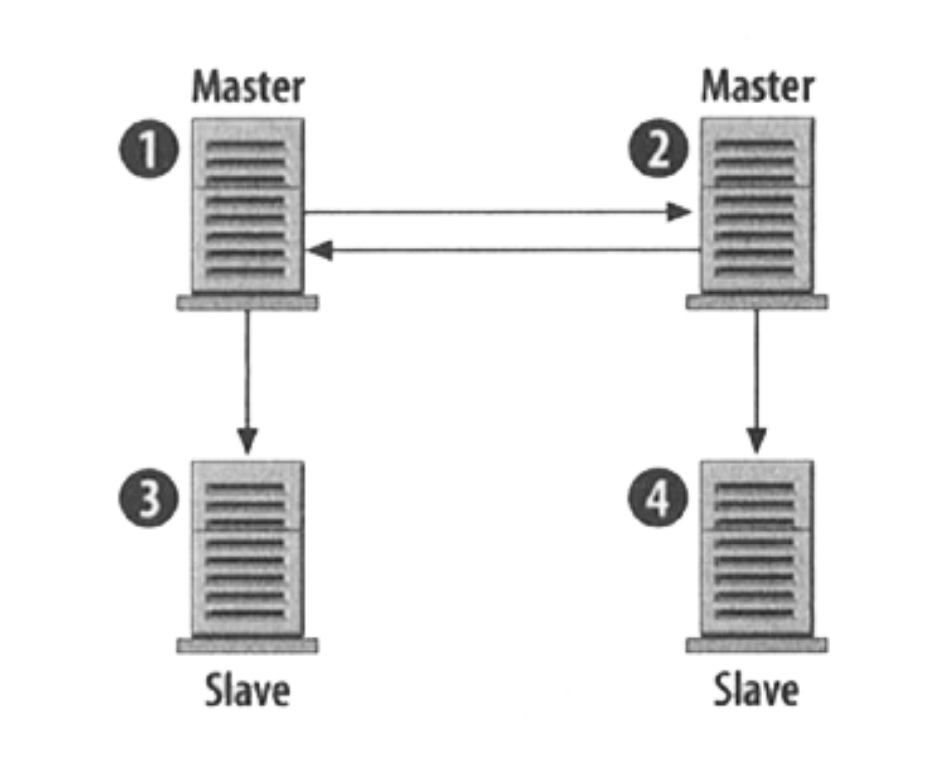
多主機模式
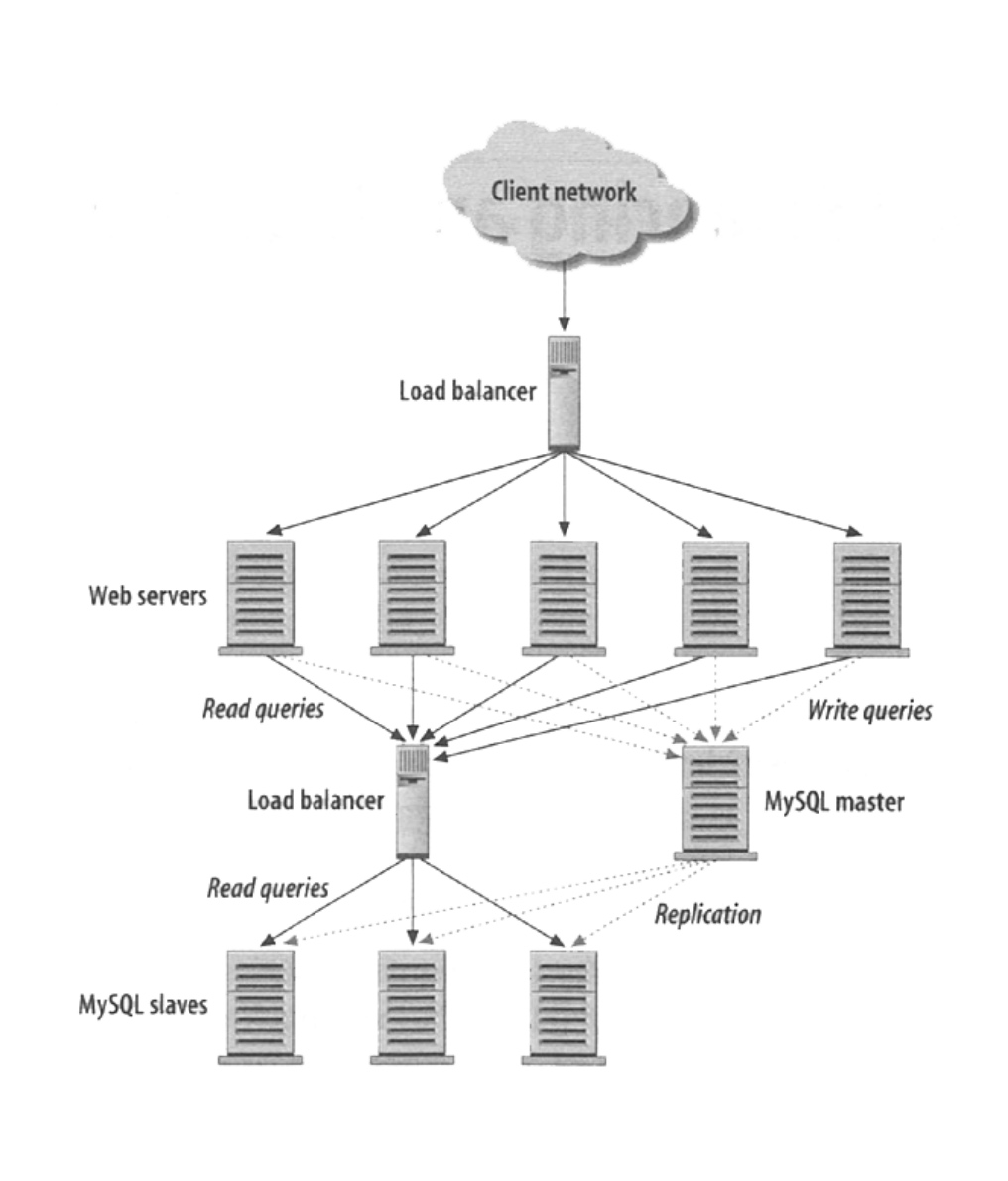
負載均衡+復制
有些類似數據庫讀寫分離或者數據庫的備份
數據分塊存儲
簡單易懂的可擴展
克隆
可擴展Web服務的公共服務器通常是做為黑盒,並隱藏在負載平衡器后面。此負載平衡器將負載(來自用戶的請求)平均分配到您的組/應用程序服務器群集上。這意味着,例如,如果小明與服務器進行交互,則他的第一個請求可能在服務器2進行處理,然后由服務器9處理第二請求,然后第三請求上再次由服務器2處理。
小明每次請求都應該得到相同(或者說一致)的結果,這與哪台服務器處理他的請求無關。
這是可擴展性的第一條黃金法則:每台服務器都包含完全相同的代碼庫,不會在本地磁盤或內存中存儲任何與用戶相關的數據,如會話或配置文件圖片。
會話需要存儲在所有應用程序服務器均可訪問的集中式數據存儲中。它可以是外部數據庫或外部持久性緩存,如Redis。外部持久緩存比外部數據庫具有更好的性能。換句歡說,通過外部存儲是數據存儲不駐留在應用程序服務器上。相反,它位於應用程序服務器的數據中心內或附近的節點。
但是如何同時部署多台呢?如何確保將代碼更改並成功發送到所有服務器,而不是有些服務器運行新代碼而有些服務器仍舊用舊代碼?幸運的是,這個棘手的問題已經由偉大的工具Capistrano解決了。這需要一些學習,特別是如果你的Ruby不夠熟練中。
在將您的會話“外包”並從所有服務器都能訪問的代碼塊提供相同的代碼后,就可以從這些服務器之一(AWS稱之為AMI - Amazon Machine Image)創建映像文件。將此AMI用作“超級克隆”所有的新實例都基於。每當你開始一個新的實例/克隆,只要做一個最新的代碼的初始部署就足夠了!
數據庫
現在,所需的更改比僅添加更多克隆的服務器更為激進,甚至可能需要一些勇氣。你可以選擇2個路徑:
路徑#1:是堅持使用MySQL,並保持野蠻的運行。聘請數據庫管理員告訴他做主從復制和讀寫分離(從從機讀取,寫入主機),並通過添加RAM來升級主服務器。在幾個月的時間里,你的數據庫管理員會想出“分片”,“反規范化”和“SQL調優”這樣的詞匯,並且會在接下來的幾周里擔心必要的加班。那時,每一個新的動作來保持你的數據庫運行將比以前更昂貴和耗時。如果您選擇了Path#2,而您的數據集仍然很小並且易於遷移,那么您可能會變得更好。
路徑#2:從頭開始正確反規范化,並且在任何數據庫查詢中不再包含連接。你可以使用MySQL,像NoSQL數據庫一樣使用它,或者你可以切換到一個更好,更容易擴展的NoSQL數據庫,比如MongoDB或者CouchDB。現在需要在應用程序代碼中完成聯接。越早執行此步驟,您將來必須更改的代碼越少。但即使您成功切換到最新,最好的NoSQL數據庫,並讓您的應用程序執行數據集連接,您的數據庫請求很快也會變得越來越慢。你將需要引入一個緩存。(關於這一點,我不是很贊同,還是要根據應用場景分類,不是所有的場景適合使用NoSQL的,而且不同的NoSQL適用的地方也不同,HBase和Redis就很不一樣)
緩存
對於“緩存”,這兒指像Memcached或Redis這樣的內存緩存(或者說,內存數據庫)。不要執行基於硬盤文件的緩存,它會使服務器的克隆和自動擴展付出高昂的代價。
內存緩存通常是一個簡單的KV鍵值存儲,它應該作為應用程序和數據存儲之間的緩沖層。無論何時您的應用程序必須讀取數據,它應該首先嘗試從緩存中檢索數據。只有當它不在緩存中時,才會嘗試從主數據源獲取數據。
緩存將每個數據集保存在RAM中,所以能夠盡可能快地處理請求。例如,Redis可以在標准服務器上托管時每秒執行幾十萬次讀取操作。還寫操作,特別是增量。
有兩種緩存數據的模式。一個舊的和一個新的:
#1 - 緩存的數據庫查詢
這仍然是最常用的緩存模式。每當您對數據庫執行查詢時,都會將結果數據集存儲在緩存中。key是我們查詢的hash值。下次運行查詢時,首先檢查它是否已經在緩存中。
這種模式有幾個問題。主要問題是數據到期。緩存復雜查詢時,很難刪除緩存的結果。當一條數據發生變化時(例如一個表格單元格),您需要刪除可能包含該表格單元格的所有緩存查詢。這樣將會非常混亂。
#2 - 緩存的對象
這是我強烈的建議,我總是喜歡這種模式。一般來說,將數據視為一個對象,就像你已經在你的代碼(類,實例等)中做的那樣。讓您的類從您的數據庫中組合一個數據集,然后將該類的完整實例或組合數據集存儲在緩存中。
聽起來很理論,我知道,但看看你通常的代碼。例如,您有一個名為“Product”的類,它有一個名為“data”的屬性。這是包含產品的價格,文本,圖片和客戶評論的數組。屬性“data”由類中的幾個方法填充,執行多個難以緩存的數據庫請求,因為許多事情相互關聯。
現在,請執行以下操作:當您的類完成數據數組的“組裝”時,直接將數據數組或更好的類的完整實例存儲在緩存中!這樣,只要有事情發生變化,就可以輕松地擺脫對象,並使代碼的整體操作更加快速和合理。
最好的部分是:它使異步處理成為可能!應用程序只訪問最新的緩存對象,幾乎從不接觸數據庫!
緩存對象的一些想法:
- 用戶會話(user sessions)從不使用數據庫
- 完全呈現的博客文章
- 活動流
- 用戶< - >朋友關系
一般來說,我更喜歡Redis的Memcached,因為我喜歡Redis的額外數據庫特性,如持久性和內置的數據結構,如列表和集合。有了Redis和一個聰明的鑰匙,你甚至有可能完全擺脫一個數據庫。但是如果你只是需要緩存,就可以使用Memcached。
異步(Asynchronism)
請想象一下,你想在你最喜歡的面包店買面包。所以你走進面包店,點了一個面包,但那里沒有面包!相反,在你點了的兩個小時之后,你的面包才能被做好。這很煩人,不是嗎?
為了避免這樣的“請稍等” - 情況,需要完成異步。面包店有什么好處,也許對你的網絡服務或網絡應用也有好處。
一般來說,有兩種方法/范例可以完成不同步。
異步#1
讓我們想想前面的面包店例子。異步處理的第一種方式是“晚上烘烤面包,早上賣”的方式。沒有等待時間。提到一個網絡應用程序,這意味着提前完成耗時的工作,並以較低的請求時間完成完成的工作。
很多時候,這個范例被用來將動態內容轉化為靜態內容。一個網站的頁面(可能是用一個巨大的框架或CMS構建的)在每次更改時都被預先渲染並作為靜態HTML文件存儲在本地。通常這些計算任務是定期完成的,也可能是由cronjob每小時調用一次的腳本。整體通用數據的預先計算可以極大地改善網站和網絡應用程序,並使其具有很高的可擴展性和性能。試想一下,如果腳本會將這些預渲染的HTML頁面上傳到AWS S3或Cloudfront或其他付款雲網絡,就可以想象網站的可擴展性!您的網站將可以達到超級響應,可以處理數以每小時百萬計的游客!
異步#2
回到面包店。不幸的是,有時顧客有特殊的要求,比如生日蛋糕-“生日快樂,小明”!面包店無法預見到這種客戶的意願,所以當客戶在面包店時要開始工作,並告訴他在第二天回來。引用一個Web服務,意味着異步處理任務。
這是一個典型的工作流程:
用戶來到您的網站,並開始一個非常計算密集的任務,這將需要幾分鍾時間完成。因此,您的網站前端將作業發送到任務隊列,並立即發回給用戶:您的任務正在被執行(或者等待執行),請繼續瀏覽頁面。任務隊伍被一群worker檢查,如果有新的任務出現,那么worker就干這個任務,幾分鍾后發出一個信號表明任務已經完成。前端不斷地檢查新的“任務已經完成” - 信號,看到任務完成並通知用戶。(這只是一個簡單的例子,檢查的機制也有很多,可以參見數據庫並發執行里面如何執行查詢任務的。)
如果你現在想深入細節和實際的技術設計,我建議你看看RabbitMQ網站上的前3個教程。 RabbitMQ是幫助實現異步處理的許多系統之一。你也可以使用ActiveMQ或簡單的Redis列表。基本的想法是有一個worker可以處理的任務或任務隊列。
異步似乎很復雜,但絕對值得您花時間來了解它並自己實現。后端變得幾乎可以無限擴展,前端變得活潑,這對整體用戶體驗是有利的。
如果你做了一些耗時的事情,試着總是異步地做。
例子
課程提供了一些公司的擴展性例子,參見原網址
https://www.hiredintech.com/classrooms/system-design/lesson/61
綜合
一切都是一個權衡
這是系統設計中最基本的概念之一。
希望在這一點上,這對你來說不是一個驚喜。如果你看過真實的架構,就會發現很少有一種完美的方式來做事。每家公司都有不同的架構。設計一個可擴展的系統是一個優化任務:有大量的約束(時間,預算,知識,復雜性,當前可用的技術等等),並且你需要建立適合這些約束的最好的東西。每一種技術,每種模式對某些事物都是有益的,而對其他事物則不是那么好。了解這些優點和缺點,優點和缺點是關鍵。
記住:沒有一個最佳的系統設計。
當然,有最好的做法,你可以使用。但是最后,這一切都歸結為在市場時間,系統復雜性,開發成本,維護成本,可用性等諸多方面之間的平衡。
能夠理解和討論這些權衡是系統設計(以及系統設計問題)的全部內容。
在你的准備中,不要試圖找到完美的東西。相反,關注每個可伸縮性模式的優點,缺點是什么,以及為什么人們比其他模式更喜歡它。
把它放在一起,保持最新狀態
在這一點上,你可以做的最有用的事情是拿出一個或兩個系統,其中包含你學到的可擴展性課程。
最后,你將在整個職業生涯中得到良好的服務,以便及時了解可伸縮性如何演變。例如,10年前,沒有亞馬遜網絡服務,公司被迫管理自己的基礎設施。如今,使用EC2,RDS,S3,Elastic MapReduce等服務,您可以建立一個巨大的公司。所以,雖然AWS沒有改變基本的可擴展性原則,但它確實改變了人們在擴展時需要熟悉的技術格局。因此,保持最新是非常重要的(否則你會重新發明輪子)。
面試
那么面試時你應該做什么?
首先,請遵循系統設計流程。你已經知道如何應用它,所以我們將會簡短。不要跳過步驟,不要做假設,當問及時開始廣泛深入。
其次,請記住,系統設計問題是一個觀念交流平台。准備討論權衡利弊。准備提供替代方案,提出問題,找出並解決瓶頸問題,根據面試者的偏好進行廣泛深入的討論。
不要保守:每當面試者挑戰你的架構選擇,承認很少一個想法是完美的,並概述了你的選擇的優點和缺點。開放討論期間面試官提出的新約束,並即時調整架構。
最重要的是,玩得開心。夢想建築是一個非常刺激的心理過程 - 享受和保持積極。你已經具備了正確的知識,只要在面試中應用,你就會做得很好。
Tiny URL
在上一章中,我們說到了我們的系統面臨着幾個挑戰:
- 每秒400個請求
- 有3TB的數據去存儲並且快速查詢
那么我們就要在抽象設計的基礎上進行修改,使其成為可擴展的設計,並能夠解決上面的限制:
- 應用服務層:
- 從單獨一台服務器可以處理多少數據開始
- 用負載測試去測試速率
- 增加一個負載均衡器,以及逐漸增加集群:解決通信量,增加可用性
- 數據存儲
- 數據特性
- 上億個對象
- 每個對象都特別小(<1k)
- 對象與對象之間沒有關系
- 讀 是 寫 的9倍(每秒360次讀,40次寫)
- 5TBs urls,36GBs hashes
- MySQL
- 廣泛使用
- 成熟的技術
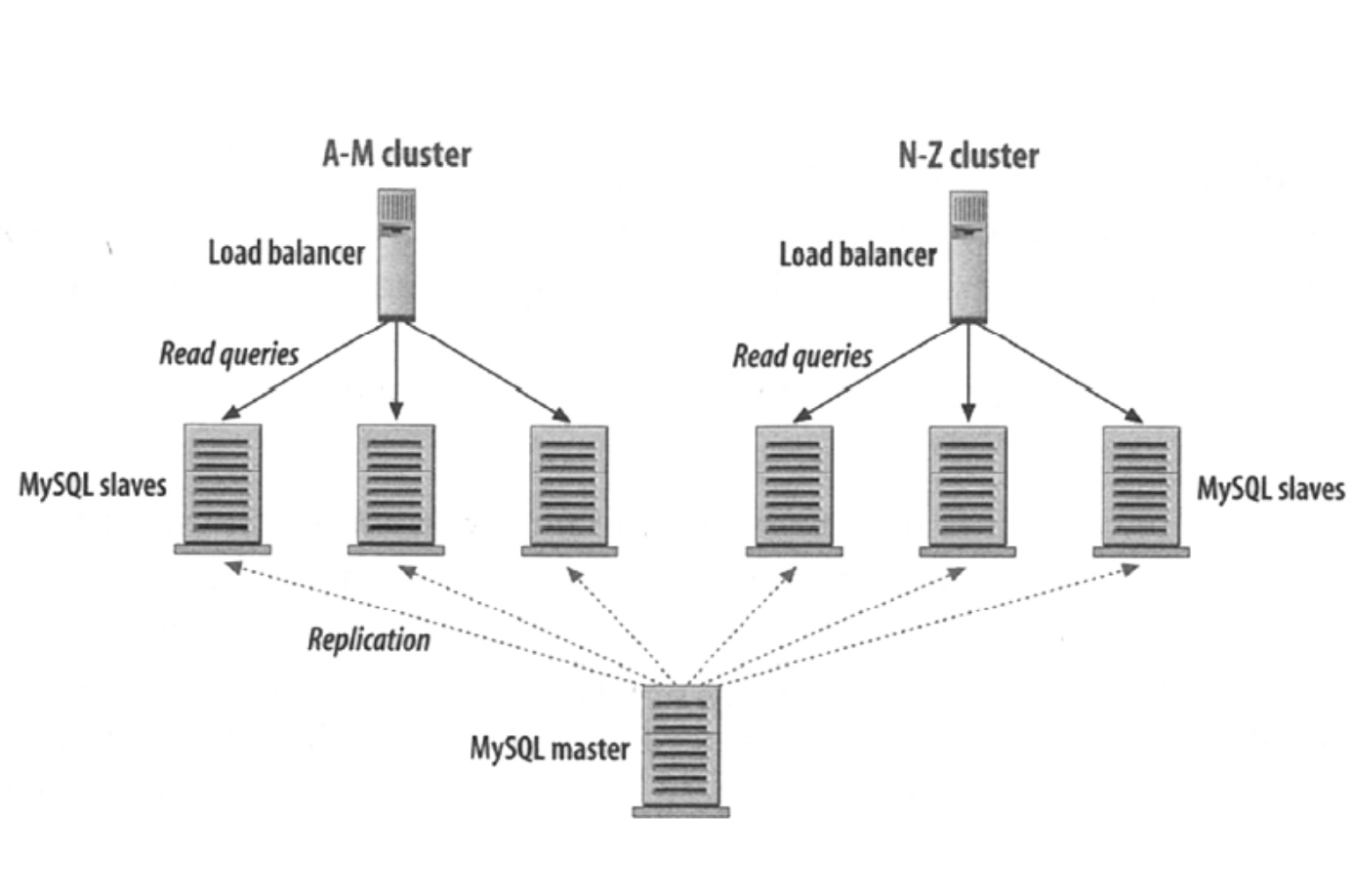
- 清晰的可擴展技術(sharding分片,master/slave replication, master/master replication)
- 索引查詢非常快
- 映射表
- hash: varchar(6)
- origin: varchar(512)
- 在hash屬性上建立聚集索引(36GB+),我們希望將這個索引存在內存中。
- 垂直擴展MySQL服務器
- 數據分片:5片數據,600GBs數據,8GB索引
- 讀寫分離,主從復制(從多台從機讀取,寫入主機,由主機更新數據到從機)
- 數據特性