Apache Flink 1.12.0 正式發布
Apache Flink 社區很榮幸地宣布 Flink 1.12.0 版本正式發布!近 300 位貢獻者參與了 Flink 1.12.0 的開發,提交了超過 1000 多個修復或優化。這些修改極大地提高了 Flink 的可用性,並且簡化(且統一)了 Flink 的整個 API 棧。其中一些比較重要的修改包括:
在 DataStream API 上添加了高效的批執行模式的支持。這是批處理和流處理實現真正統一的運行時的一個重要里程碑。
實現了基於Kubernetes的高可用性(HA)方案,作為生產環境中,ZooKeeper方案之外的另外一種選擇。
擴展了 Kafka SQL connector,使其可以在 upsert 模式下工作,並且支持在 SQL DDL 中處理 connector 的 metadata。現在,時態表 Join 可以完全用 SQL 來表示,不再依賴於 Table API 了。
PyFlink 中添加了對於 DataStream API 的支持,將 PyFlink 擴展到了更復雜的場景,比如需要對狀態或者定時器 timer 進行細粒度控制的場景。除此之外,現在原生支持將 PyFlink 作業部署到 Kubernetes上。
本文描述了所有主要的新功能、優化、以及需要特別關注的改動。
Flink 1.12.0 的二進制發布包和源代碼可以通過 Flink 官網的下載頁面獲得,詳情可以參閱 Flink 1.12.0 的官方文檔。我們希望您下載試用這一版本后,可以通過 Flink 郵件列表和 JIRA 網站和我們分享您的反饋意見。
Flink 1.12 官方文檔:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/
Flink 1.12 新的功能和優化
DataStream API 支持批執行模式
Flink 的核心 API 最初是針對特定的場景設計的,盡管 Table API / SQL 針對流處理和批處理已經實現了統一的 API,但當用戶使用較底層的 API 時,仍然需要在批處理(DataSet API)和流處理(DataStream API)這兩種不同的 API 之間進行選擇。鑒於批處理是流處理的一種特例,將這兩種 API 合並成統一的 API,有一些非常明顯的好處,比如:
-
可復用性:作業可以在流和批這兩種執行模式之間自由地切換,而無需重寫任何代碼。因此,用戶可以復用同一個作業,來處理實時數據和歷史數據。
-
維護簡單:統一的 API 意味着流和批可以共用同一組 connector,維護同一套代碼,並能夠輕松地實現流批混合執行,例如 backfilling 之類的場景。
考慮到這些優點,社區已朝着流批統一的 DataStream API 邁出了第一步:支持高效的批處理(FLIP-134)。從長遠來看,這意味着 DataSet API 將被棄用(FLIP-131),其功能將被包含在 DataStream API 和 Table API / SQL 中。
有限流上的批處理
您已經可以使用 DataStream API 來處理有限流(例如文件)了,但需要注意的是,運行時並不“知道”作業的輸入是有限的。為了優化在有限流情況下運行時的執行性能,新的 BATCH 執行模式,對於聚合操作,全部在內存中進行,且使用 sort-based shuffle(FLIP-140)和優化過的調度策略(請參見 Pipelined Region Scheduling 了解更多詳細信息)。因此,DataStream API 中的 BATCH 執行模式已經非常接近 Flink 1.12 中 DataSet API 的性能。有關性能的更多詳細信息,請查看 FLIP-140。
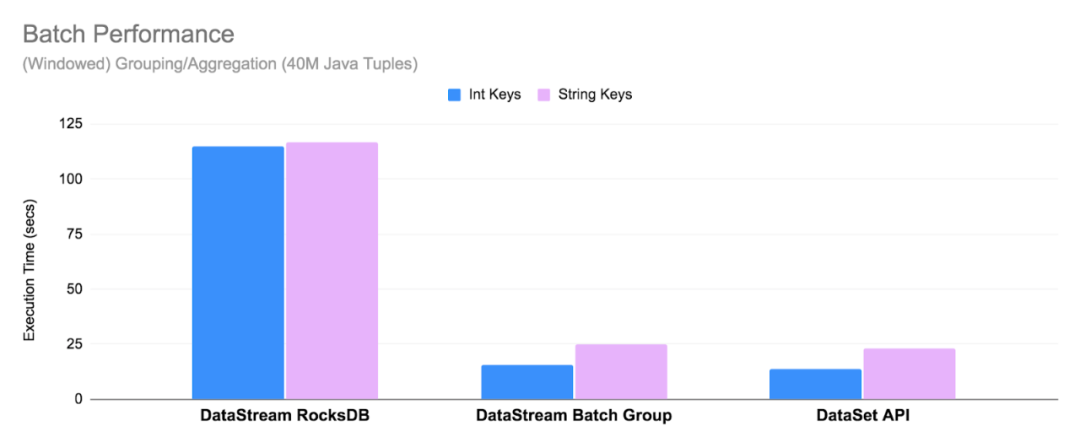
在 Flink 1.12 中,默認執行模式為 STREAMING,要將作業配置為以 BATCH 模式運行,可以在提交作業的時候,設置參數 execution.runtime-mode:
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
或者通過編程的方式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeMode.BATCH);
注意:盡管 DataSet API 尚未被棄用,但我們建議用戶優先使用具有 BATCH 執行模式的 DataStream API 來開發新的批作業,並考慮遷移現有的 DataSet 作業。
新的 Data Sink API (Beta)
之前發布的 Flink 版本中[1],已經支持了 source connector 工作在流批兩種模式下,因此在 Flink 1.12 中,社區着重實現了統一的 Data Sink API(FLIP-143)。新的抽象引入了 write/commit 協議和一個更加模塊化的接口。
Sink 的實現者只需要定義 what 和 how:SinkWriter,用於寫數據,並輸出需要 commit 的內容(例如,committables);Committer 和 GlobalCommitter,封裝了如何處理 committables。框架會負責 when 和 where:即在什么時間,以及在哪些機器或進程中 commit。
這種模塊化的抽象允許為 BATCH 和 STREAMING 兩種執行模式,實現不同的運行時策略,以達到僅使用一種 sink 實現,也可以使兩種模式都可以高效執行。Flink 1.12 中,提供了統一的 FileSink connector,以替換現有的 StreamingFileSink connector (FLINK-19758)。其它的 connector 也將逐步遷移到新的接口。
基於 Kubernetes 的高可用 (HA) 方案
Flink 可以利用 Kubernetes 提供的內置功能來實現 JobManager 的 failover,而不用依賴 ZooKeeper。為了實現不依賴於 ZooKeeper 的高可用方案,社區在 Flink 1.12(FLIP-144)中實現了基於 Kubernetes 的高可用方案。該方案與 ZooKeeper 方案基於相同的接口[3],並使用 Kubernetes 的 ConfigMap[4] 對象來處理從 JobManager 的故障中恢復所需的所有元數據。關於如何配置高可用的 standalone 或原生 Kubernetes 集群的更多詳細信息和示例,請查閱文檔[5]。
注意:需要注意的是,這並不意味着 ZooKeeper 將被刪除,這只是為 Kubernetes 上的 Flink 用戶提供了另外一種選擇。
其它功能改進
將現有的 connector 遷移到新的 Data Source API
在之前的版本中,Flink 引入了新的 Data Source API(FLIP-27),以允許實現同時適用於有限數據(批)作業和無限數據(流)作業使用的 connector 。在 Flink 1.12 中,社區從 FileSystem connector(FLINK-19161)出發,開始將現有的 source connector 移植到新的接口。
注意: 新的 source 實現,是完全不同的實現,與舊版本的實現不兼容。
Pipelined Region 調度 (FLIP-119)
在之前的版本中,Flink 對於批作業和流作業有兩套獨立的調度策略。Flink 1.12 版本中,引入了統一的調度策略, 該策略通過識別 blocking 數據傳輸邊,將 ExecutionGraph 分解為多個 pipelined region。這樣一來,對於一個 pipelined region 來說,僅當有數據時才調度它,並且僅在所有其所需的資源都被滿足時才部署它;同時也可以支持獨立地重啟失敗的 region。對於批作業來說,新策略可顯著地提高資源利用率,並消除死鎖。
支持 Sort-Merge Shuffle (FLIP-148)
為了提高大規模批作業的穩定性、性能和資源利用率,社區引入了 sort-merge shuffle,以替代 Flink 現有的實現。這種方案可以顯著減少 shuffle 的時間,並使用較少的文件句柄和文件寫緩存(這對於大規模批作業的執行非常重要)。在后續版本中(FLINK-19614),Flink 會進一步優化相關性能。
注意:該功能是實驗性的,在 Flink 1.12 中默認情況下不啟用。要啟用 sort-merge shuffle,需要在 TaskManager 的網絡配置[6]中設置合理的最小並行度。
Flink WebUI 的改進 (FLIP-75)
作為對上一個版本中,Flink WebUI 一系列改進的延續,Flink 1.12 在 WebUI 上暴露了 JobManager 內存相關的指標和配置參數(FLIP-104)。對於 TaskManager 的指標頁面也進行了更新,為 Managed Memory、Network Memory 和 Metaspace 添加了新的指標,以反映自 Flink 1.10(FLIP-102)開始引入的 TaskManager 內存模型的更改[7]。
Table API/SQL: SQL Connectors 中的 Metadata 處理
如果可以將某些 source(和 format)的元數據作為額外字段暴露給用戶,對於需要將元數據與記錄數據一起處理的用戶來說很有意義。一個常見的例子是 Kafka,用戶可能需要訪問 offset、partition 或 topic 信息、讀寫 kafka 消息中的 key 或 使用消息 metadata中的時間戳進行時間相關的操作。
在 Flink 1.12 中,Flink SQL 支持了元數據列用來讀取和寫入每行數據中 connector 或 format 相關的列(FLIP-107)。這些列在 CREATE TABLE 語句中使用 METADATA(保留)關鍵字來聲明。
CREATE TABLE kafka_table (
id BIGINT,
name STRING,
event_time TIMESTAMP(3) METADATA FROM 'timestamp', -- access Kafka 'timestamp' metadata
headers MAP<STRING, BYTES> METADATA -- access Kafka 'headers' metadata
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'format' = 'avro'
);
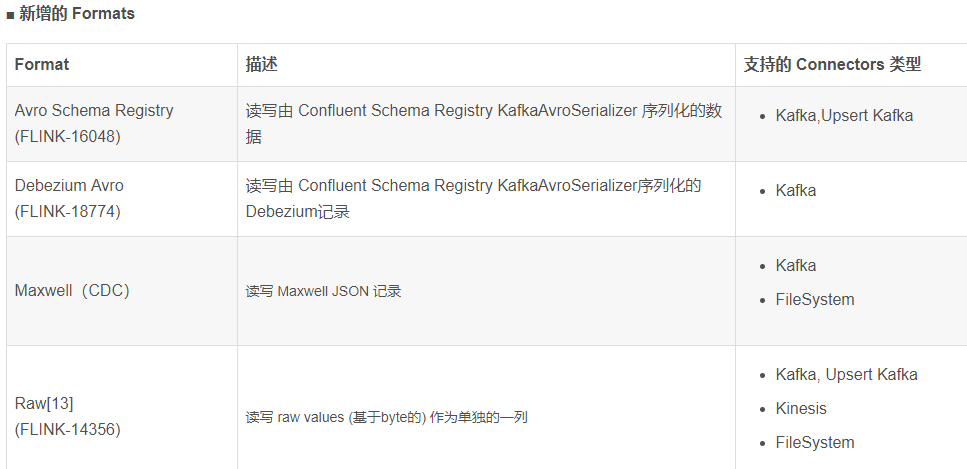
在 Flink 1.12 中,已經支持 Kafka 和 Kinesis connector 的元數據,並且 FileSystem connector 上的相關工作也已經在計划中(FLINK-19903)。由於 Kafka record 的結構比較復雜,社區還專門為 Kafka connector 實現了新的屬性[8],以控制如何處理鍵/值對。關於 Flink SQL 中元數據支持的完整描述,請查看每個 connector 的文檔[9]以及 FLIP-107 中描述的用例。
Table API/SQL: Upsert Kafka Connector
在某些場景中,例如讀取 compacted topic 或者輸出(更新)聚合結果的時候,需要將 Kafka 消息記錄的 key 當成主鍵處理,用來確定一條數據是應該作為插入、刪除還是更新記錄來處理。為了實現該功能,社區為 Kafka 專門新增了一個 upsert connector(upsert-kafka),該 connector 擴展自現有的 Kafka connector,工作在 upsert 模式(FLIP-149)下。新的 upsert-kafka connector 既可以作為 source 使用,也可以作為 sink 使用,並且提供了與現有的 kafka connector 相同的基本功能和持久性保證,因為兩者之間復用了大部分代碼。
要使用 upsert-kafka connector,必須在創建表時定義主鍵,並為鍵(key.format)和值(value.format)指定序列化反序列化格式。完整的示例,請查看最新的文檔[10]。
Table API/SQL: SQL 中 支持 Temporal Table Join
在之前的版本中,用戶需要通過創建時態表函數(temporal table function) 來支持時態表 join(temporal table join) ,而在 Flink 1.12 中,用戶可以使用標准的 SQL 語句 FOR SYSTEM_TIME AS OF(SQL:2011)來支持 join。此外,現在任意包含時間列和主鍵的表,都可以作為時態表,而不僅僅是 append-only 表。這帶來了一些新的應用場景,比如將 Kafka compacted topic 或數據庫變更日志(來自 Debezium 等)作為時態表。
CREATE TABLE orders (
order_id STRING,
currency STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '30' SECOND
) WITH (
…
);
-- Table backed by a Kafka compacted topic
CREATE TABLE latest_rates (
currency STRING,
rate DECIMAL(38, 10),
currency_time TIMESTAMP(3),
WATERMARK FOR currency_time AS currency_time - INTERVAL ‘5’ SECOND,
PRIMARY KEY (currency) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
…
);
-- Event-time temporal table join
SELECT
o.order_id,
o.order_time,
o.amount * r.rate AS amount,
r.currency
FROM orders AS o, latest_rates FOR SYSTEM_TIME AS OF o.order_time r
ON o.currency = r.currency;
上面的示例同時也展示了如何在 temporal table join 中使用 Flink 1.12 中新增的 upsert-kafka connector。
使用 Hive 表進行 Temporal Table Join
用戶也可以將 Hive 表作為時態表來使用,Flink 既支持自動讀取 Hive 表的最新分區作為時態表(FLINK-19644),也支持在作業執行時追蹤整個 Hive 表的最新版本作為時態表。請參閱文檔,了解更多關於如何在 temporal table join 中使用 Hive 表的示例。
Table API/SQL 中的其它改進
Kinesis Flink SQL Connector (FLINK-18858)
從 Flink 1.12 開始,Table API / SQL 原生支持將 Amazon Kinesis Data Streams(KDS)作為 source 和 sink 使用。新的 Kinesis SQL connector 提供了對於增強的Fan-Out(EFO)以及 Sink Partition 的支持。如需了解 Kinesis SQL connector 所有支持的功能、配置選項以及對外暴露的元數據信息,請查看最新的文檔。
在 FileSystem/Hive connector 的流式寫入中支持小文件合並 (FLINK-19345)
很多 bulk format,例如 Parquet,只有當寫入的文件比較大時,才比較高效。當 checkpoint 的間隔比較小時,這會成為一個很大的問題,因為會創建大量的小文件。在 Flink 1.12 中,File Sink 增加了小文件合並功能,從而使得即使作業 checkpoint 間隔比較小時,也不會產生大量的文件。要開啟小文件合並,可以按照文檔[11]中的說明在 FileSystem connector 中設置 auto-compaction = true 屬性。
Kafka Connector 支持 Watermark 下推 (FLINK-20041)
為了確保使用 Kafka 的作業的結果的正確性,通常來說,最好基於分區來生成 watermark,因為分區內數據的亂序程度通常來說比分區之間數據的亂序程度要低很多。Flink 現在允許將 watermark 策略下推到 Kafka connector 里面,從而支持在 Kafka connector 內部構造基於分區的 watermark[12]。一個 Kafka source 節點最終所產生的 watermark 由該節點所讀取的所有分區中的 watermark 的最小值決定,從而使整個系統可以獲得更好的(即更接近真實情況)的 watermark。該功能也允許用戶配置基於分區的空閑檢測策略,以防止空閑分區阻礙整個作業的 event time 增長。
利用 Multi-input 算子進行 Join 優化 (FLINK-19621)
Shuffling 是一個 Flink 作業中最耗時的操作之一。為了消除不必要的序列化反序列化開銷、數據 spilling 開銷,提升 Table API / SQL 上批作業和流作業的性能, planner 當前會利用上一個版本中已經引入的N元算子(FLIP-92),將由 forward 邊所連接的多個算子合並到一個 Task 里執行。
Type Inference for Table API UDAFs (FLIP-65)
Flink 1.12 完成了從 Flink 1.9 開始的,針對 Table API 上的新的類型系統[2]的工作,並在聚合函數(UDAF)上支持了新的類型系統。從 Flink 1.12 開始,與標量函數和表函數類似,聚合函數也支持了所有的數據類型。
PyFlink: Python DataStream API
為了擴展 PyFlink 的可用性,Flink 1.12 提供了對於 Python DataStream API(FLIP-130)的初步支持,該版本支持了無狀態類型的操作(例如 Map,FlatMap,Filter,KeyBy 等)。如果需要嘗試 Python DataStream API,可以安裝PyFlink,然后按照該文檔[14]進行操作,文檔中描述了如何使用 Python DataStream API 構建一個簡單的流應用程序。
from pyflink.common.typeinfo import Types
from pyflink.datastream import MapFunction, StreamExecutionEnvironment
class MyMapFunction(MapFunction):
def map(self, value):
return value + 1
env = StreamExecutionEnvironment.get_execution_environment()
data_stream = env.from_collection([1, 2, 3, 4, 5], type_info=Types.INT())
mapped_stream = data_stream.map(MyMapFunction(), output_type=Types.INT())
mapped_stream.print()
env.execute("datastream job")
PyFlink 中的其它改進
PyFlink Jobs on Kubernetes (FLINK-17480)
除了 standalone 部署和 YARN 部署之外,現在也原生支持將 PyFlink 作業部署在 Kubernetes 上。最新的文檔中詳細描述了如何在 Kubernetes 上啟動 session 或 application 集群。
用戶自定義聚合函數 (UDAFs)
從 Flink 1.12 開始,您可以在 PyFlink 作業中定義和使用 Python UDAF 了(FLIP-139)。普通的 UDF(標量函數)每次只能處理一行數據,而 UDAF(聚合函數)則可以處理多行數據,用於計算多行數據的聚合值。您也可以使用 Pandas UDAF[15](FLIP-137),來進行向量化計算(通常來說,比普通 Python UDAF 快10倍以上)。
注意: 普通 Python UDAF,當前僅支持在 group aggregations 以及流模式下使用。如果需要在批模式或者窗口聚合中使用,建議使用 Pandas UDAF。
其它重要改動
-
[FLINK-19319] The default stream time characteristic has been changed to EventTime, so you no longer need to call StreamExecutionEnvironment.setStreamTimeCharacteristic() to enable event time support.
-
[FLINK-19278] Flink now relies on Scala Macros 2.1.1, so Scala versions < 2.11.11 are no longer supported.
-
[FLINK-19152] The Kafka 0.10.x and 0.11.x connectors have been removed with this release. If you’re still using these versions, please refer to the documentation[16] to learn how to upgrade to the universal Kafka connector.
-
[FLINK-18795] The HBase connector has been upgraded to the last stable version (2.2.3).
-
[FLINK-17877] PyFlink now supports Python 3.8.
-
[FLINK-18738] To align with FLIP-53, managed memory is now the default also for Python workers. The configurations python.fn-execution.buffer.memory.size and python.fn-execution.framework.memory.size have been removed and will not take effect anymore.
詳細發布說明
如果你想要升級到1.12的話,請詳細閱讀詳細發布說明[17]。與之前所有1.x版本相比,1.12可以保證所有標記為 @Public 的接口的兼容性。
原文鏈接:
https://flink.apache.org/news/2020/12/10/release-1.12.0.html
參考鏈接:
[1] https://flink.apache.org/news/2020/07/06/release-1.11.0.html#new-data-source-api-beta
[2] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/types.html#data-types
[4] https://kubernetes.io/docs/concepts/configuration/configmap/
[5] https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/ha/kubernetes_ha.html
[7] https://flink.apache.org/news/2020/04/21/memory-management-improvements-flink-1.10.html
[9] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/
[10] https://ci.apache.org/projects/flink/flink-docs-master/dev/table/connectors/kinesis.html
[13] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/formats/raw.html
[14] https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/python/datastream_tutorial.html
[16] https://ci.apache.org/projects/flink/flink-docs-master/dev/connectors/kafka.html
[17] https://ci.apache.org/projects/flink/flink-docs-stable/release-notes/flink-1.12.html