最近接手了一個“公共”服務,負責維護它的穩定性。代碼庫有很多人參與“維護”,其實就是各種業務方使勁往上堆邏輯。雖然入庫前我會進行 CR,但多了之后,也看不過來,還有一些人自己偷摸就把代碼合到 master 上去了。總之,代碼質量無法得到很好的保證。
當然了,如果把合代碼的權限收斂到我一個人,理論上是可行的。但是,一方面,業務迭代的速度很可能就 block 在我這了;另一方面,業務方的迭代邏輯涉及很多具體的業務,我也不太熟。所以,CR 的時候也只能看一些諸如 go 出去的 func 有沒有加 recover、有沒有異常使用空指針等等,對於業務相關的代碼提不出什么有用的意見。
其實有一些業務方的邏輯和其他業務方完全獨立(使用的接口和其他業務方獨立),后續會將當前的服務完全“復制”一份出來,交給業務方自行維護。
但眼下有一個問題需要解決:報警群里時不時來一個 recovered panic 的報警,我看到報警后就要登上機器看日志,執行 “grep -C 10 panic xxx.log” 這樣的命令看 panic 發生在哪里。再執行 git blame 看看究竟是誰寫的,再去群里 @ 他進行處理。但很多情況下是這些 panic 是由臟數據導致的,發生的也不頻繁,並且 panic 被 recover 住了,所以也不太着急。
問題是業務方寫完了代碼之后,基本也不太關心服務運行地怎么樣,但作為服務負責人得管。像前面提到的 panic 報警發生的多了,我“查日志,定位到代碼提交人再通知他處理”的事情多了之后,就想能不能寫一個 panic blame 機器人來做這件事。這樣就能省不少事,而且還顯得那么優雅。
想好了要做這件事,其實也並不困難。
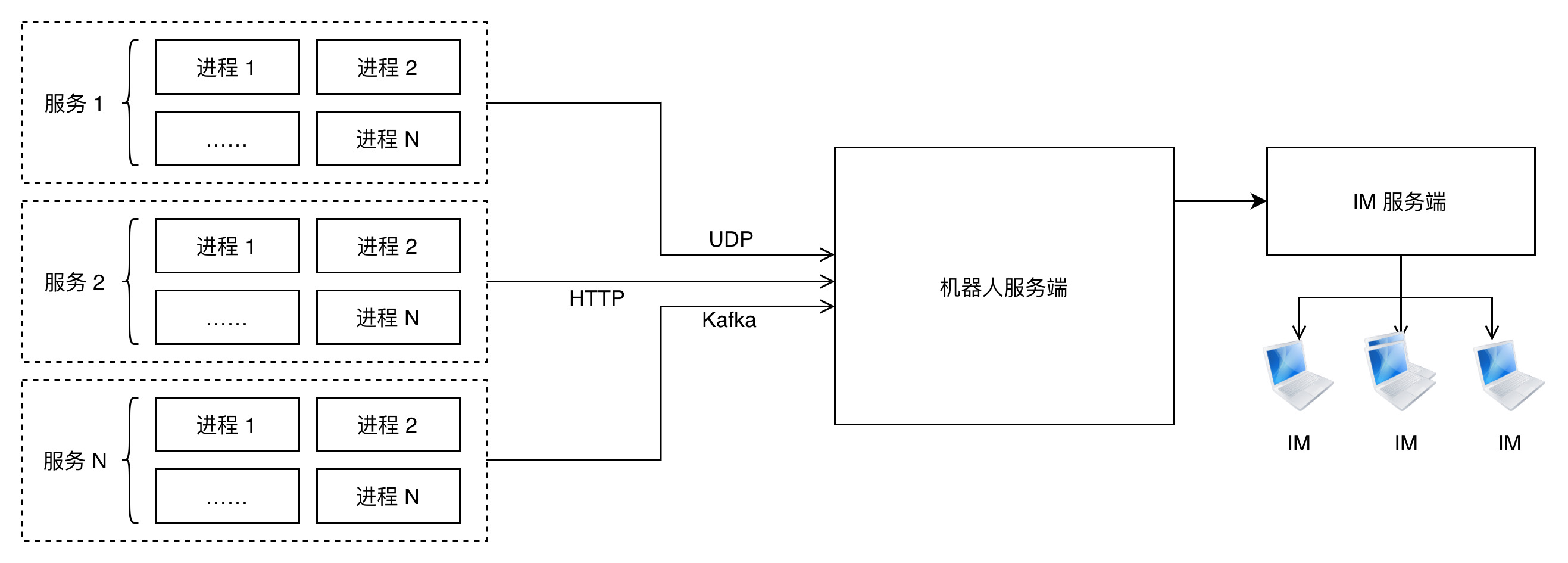
最朴素的思路就是在 recover 函數里把 panic 發生時的一些信息,例如 pod-name、機器 ip、服務名、stack 等通過 HTTP 請求發送到某個服務,這個服務收到 stack 后分析出 panic 的那行代碼,再請求 git 服務的某個接口,拿到提交人及提交時間。整體如下:
我們再看看具體代碼是怎么寫的。例如,Recover 函數是這樣的:
func RecoverFromPanic(funcName string) {
if e := recover(); e != nil {
buf := make([]byte, 64<<10)
buf = buf[:runtime.Stack(buf, false)]
logs.Errorf("[%s] func_name: %v, stack: %s", funcName, e, string(buf))
panicError := fmt.Errorf("%v", e)
panic_reporter_client.ReportPanic(panicError.Error(), funcName, string(buf))
}
return
}
向機器人服務端發送 panic 信息的 panic_reporter_client 代碼:
const url = "http://localhost:8888/report-panic"
// 為了避免造成 panic report 服務被打掛,降低發送 http 請求頻率,進程生命周期內只發一次
var panicReportOnce sync.Once
type PanicReq struct {
Service string `json:"service"`
ErrorInfo string `json:"error_info"`
Stack string `json:"stack"`
LogId string `json:"log_id"`
FuncName string `json:"func_name"`
Host string `json:"host"`
PodName string `json:"pod_name"`
}
func ReportPanic(errInfo, funcName, stack string) (err error) {
panicReportOnce.Do(func() {
defer func() {recover()}()
go func() {
panicReq := &PanicReq {
Service: env.Service(),
ErrorInfo: errInfo,
Stack: stack,
FuncName: funcName,
Host: env.HostIP(),
PodName: env.PodName(),
}
var jsonBytes []byte
jsonBytes, err = json.Marshal(panicReq)
if err != nil {
return
}
var req *http.Request
req, err = http.NewRequest("GET", url, bytes.NewBuffer(jsonBytes))
if err != nil {
return
}
req.Header.Set("Content-Type", "application/json")
client := &http.Client{Timeout: 5 * time.Second}
var resp *http.Response
resp, err = client.Do(req)
if err != nil {
return
}
defer resp.Body.Close()
return
}()
})
return
}
解析出 panic 消息的代碼也不難,我們需要看一下如何從 stack 信息中找到 panic 的那一行。
舉一個例子來說明:
package main
import (
"fmt"
"runtime"
)
func a() {
fmt.Println("a")
b()
}
func b() {
fmt.Println("b")
c()
}
type Student struct {
Name int
}
func c() {
defer RecoverFromPanic("fun c")
fmt.Println("c")
var a *Student
fmt.Println(a.Name)
}
func main() {
a()
}
func RecoverFromPanic(funcName string) {
if e := recover(); e != nil {
buf := make([]byte, 64<<10)
buf = buf[:runtime.Stack(buf, false)]
fmt.Printf("[%s] func_name: %v, stack: %s", funcName, e, string(buf))
}
return
}
這是一個有幾層調用關系的例子,假裝我們年幼無知直接解引用了一個空指針,導致 panic,但被 recover 了,輸出的調用棧信息如下:
goroutine 1 [running]:
main.RecoverFromPanic(0x4c4551, 0x5)
/home/raoquancheng/go/src/hello/test.go:36 +0xb5
panic(0x4a9340, 0x55b8d0)
/usr/local/go/src/runtime/panic.go:679 +0x1b2
main.c()
/home/raoquancheng/go/src/hello/test.go:26 +0xd4
main.b()
/home/raoquancheng/go/src/hello/test.go:15 +0x7a
main.a()
/home/raoquancheng/go/src/hello/test.go:10 +0x7a
main.main()
/home/raoquancheng/go/src/hello/test.go:30 +0x20
棧信息中,首先是 runtime.Stack 函數那一行;接着是 /usr/local/go/src/runtime/panic.go:679,也就是 runtime 里的 gopanic 函數;下一行就是真正引起 panic 的使用空指針的那一行代碼,這是罪魁禍首,panic blame 機器人主要關注這個;之后的信息就是調用鏈關系,會一直追溯到 main 函數里調用 a() 的源頭。
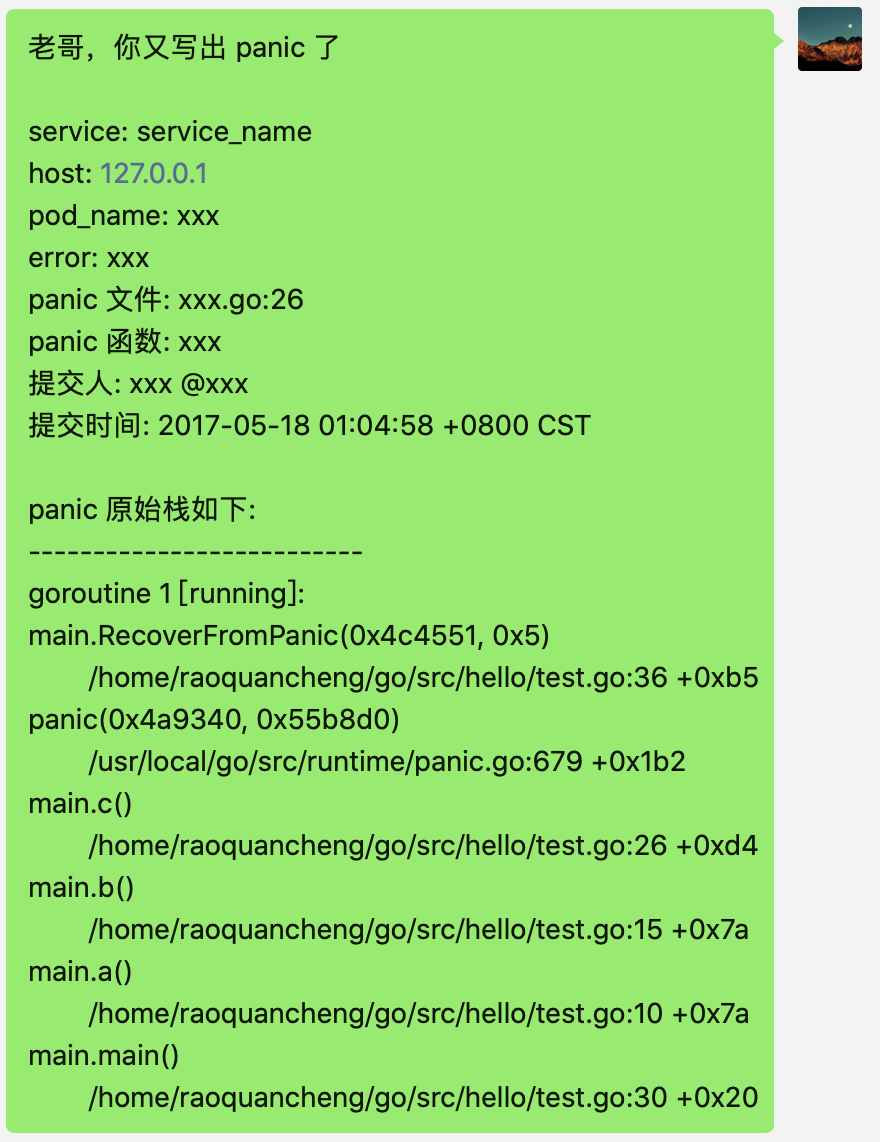
分析出來這些信息后,向 IM 提供的機器人 webhook 地址發送 panic 消息,並順帶 @ 剛才找到的代碼提交人,老哥,你又寫出 panic 了:
這樣是不是就是萬事大吉了?
並不是,還有一些關鍵問題需要考慮。首先業務進程不能阻塞在發送 panic 信息的過程中,且發送 panic 信息的代碼不能再發次發生 panic,以免給業務進程帶來二次傷害。這樣就需要以異步的方式發送消息,並且最好是通過消息隊列或者 UDP 這種“我發完了就不管了”的姿態發送。
機器人服務端用生產者消費者的形式來解析業務進程發送上來的消息。無論業務進程是以 HTTP,還是 UDP 或者消息隊列發過來的 panic 報告請求最終都要進入一個“池子”,HTTP、UDP、消息隊列也就是所謂的生產者,消費者協程則從“池子”里取出 panic 報告請求,解析、發送報警@人處理。
還有一個需要考慮的是機器人服務端不要被打跨了,尤其是考慮到一些業務跑在幾千個實例上的時候,更要注意了。
分別從客戶端和服務端兩方面來看。
對於客戶端,在一個進程生命周期內,同時發生多“種” panic 的情況並不多見,因此我們只需要在進程生命周期內發送一次就行了,用 sync.Once。
在服務端,對同一個業務發送的請求進行限流和聚合,例如每秒只處理同一個業務的一個請求,對被限流的請求做聚合,報告一個總的 panic 數量就行了。
另一個可能需要考慮的是如果 panic 代碼提交者離職了怎么辦?或者說我只是做了一下 format,真實的提交者並不是我,怎么辦?
我們並不能做到 100% 的准確,現實有很多的邊角沒法解決。比如代碼提交者並沒有離職,但他轉崗了……有個可以考慮的方法是看 panic 那一行代碼附近的最近修改過代碼的人是誰,找他,或者直接找服務負責人好了。不求完美,只要能解決大部分問題就行了。
實現一個 panic blame 機器人比較簡單,但考慮服務穩定性的話,還是有一些點要注意的。