Separate to Adapt: Open Set Domain Adaptation via Progressive Separation論文筆記
Abstract
Domain adaptation問題在利用源域的標注數據為未標記的目標域學習准確的分類器方面已經有較大成功,但是Open Set Domain Adaptation問題中的目標域中存在未知類,而未知類所占的比例對解決問題的方案的性能影響很大。在源域與目標域對齊的時候,如果不將目標域中的未知類排除,會造成已知類與未知類的不匹配而形成負遷移。
本文提出分離適配(Separate to Adapt (STA)),一種端到端的開集域適配方法。這種方法采用由粗到細的加權機制,逐步分離未知類和已知類的樣本,同時加權它們對特征分布對齊的影響。
經過驗證,該方法適用於目標域的各種開放類型且效果很好。
Introduction
背景
目前計算機視覺方面的提升大多數是得益於大量帶注釋的訓練數據,而在實際的運用中這樣的數據並不多。而不同領域的數據又來自不同的分布。領域差距可能導致模型在目標領域做出錯誤預測。而現有的領域適應方法無論是通過特征級還是像素級的分布匹配來彌補領域差距,其方法大都假設源域和目標域共享相同的標簽,即封閉集域適應。
本文研究的背景是在開集域適應(OSDA)中,目標域擁有源域中所有的類,而且目標域中存在未知類。
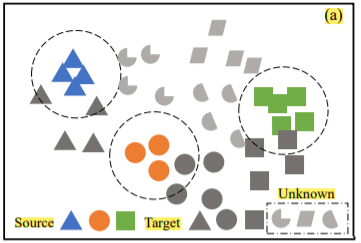
開集域適配的兩個挑戰
(1)減輕域間差異的影響
(2)未知類的存在可能會造成負遷移
已知處理OSDA問題的少數方法的缺陷:
迭代分配變換(Assign-and-Transform-Iteratively (ATI) ):使用一個基於距離的度量來迭代地標記未知樣本
開集反向傳播(Open Set Back-Propagation (OSBP) ):嘗試解決源域中沒有未知類的問題
兩種方法都需要一些閾值超參數來區分已知類和未知類,而設置超參數還需要目標域類別的先驗知識,而在現實中的開放性可能是變化比較大的,所以超參數難以選擇,而且依賴於預定義超參數的方法需要大量的超參數選擇工作
⭐作者的方法
文章提出分離適應( Separate to Adapt (STA)),在不同的開放程度下解決開集域適應問題。
作者使用域間對抗學習的框架,並且為源域中的分類器添加了一個類:unknown class。
目標域中的已知類與未知類的主要區別在於:目標域的已知類與源域的已知類區別僅在於分布偏移,而目標域的未知類與源域的未知類區別更大,既有域間隙,也有語義間隙。
由此,作者開發了一個由粗到細的分離管道組成的漸進分離機制。
第一步是用源數據訓練多二元分類器,以估計目標域中的數據和每個源類之間的相似性。
第二步中,我們選擇相似度極高和極低的數據作為已知和未知類別的數據,並用它們訓練細粒度二元分類器,對所有目標域樣本進行精細分離
在這兩個步驟之間迭代,並使用實例權重來拒絕對抗域適應中未知類的樣本
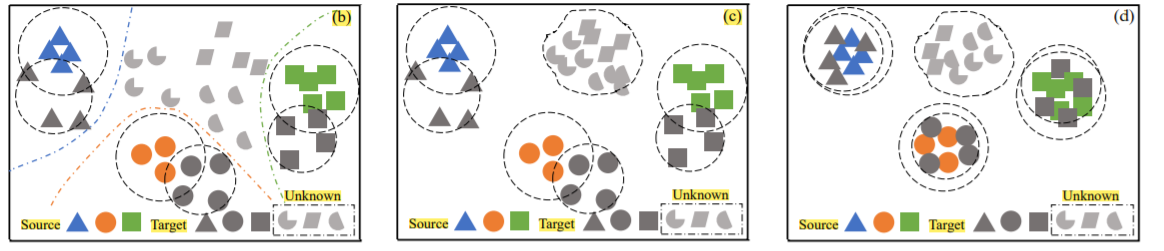
圖中左邊表示在進行了源數據訓練多二元分類器之后,通過產生的初步權值來從目標域中區分出未知類。圖中的虛線是二元分類器為每個類產生的決策邊界。
圖中中間是訓練細粒度二元分類器來得到更精確的權重,目標域中的已知類以及未知類都已經分離開來。
圖中的右邊表示經過最后的分布對齊,目標域中的共享類已經域源域的相應類別對齊。
Related Work
封閉域自適應(Closed Set Domain Adaptation)
封閉集域自適應方法尋求減輕由域差異帶來的性能下降。典型的方法是最小化特征分布之間的距離
- 深度自適應網絡(Deep Adaptation Network (DAN) ):增加了自適應層,最小化分布的內核嵌入之間的最大平均差異(MMD)
- 中心矩差異(Central Moment Discrepancy (CMD) ):通過僅匹配一階和二階矩同樣實現了域自適應。
- 剩余轉移網絡(Residual Transfer Network (RTN)):通過增加一個快捷連接和熵最小化標准來改進DAN
- 聯合適應網絡(Joint Adaptation Network (JAN)):匹配源域和目標域的特征和標簽的聯合分布。
- 領域對抗神經網絡(Domain Adversarial Neural Network (DANN))、對抗性區分域適應(Adversarial Discriminative Domain Adaptation (ADDA)):使用領域鑒別器來區分兩個領域,同時學習特征提取器來混淆領域對抗訓練范例中的領域鑒別器
- 條件域對抗網絡(Conditional Domain Adversarial Network (CDAN)):通過匹配標簽和特征的聯合分布來改進DANN
開集識別(Open Set Recognition)
即如何能正確的區分已知類別並拒絕其它未知類別。
- 1-vs-set模型:從邊際距離描繪決策空間,開放集SVM分配概率分數以拒絕未知樣本,進一步改進了緊湊的減少概率模型。
- 引入OpenMax層:利用深層神經網絡進行開集識別
在開放集識別場景中,存在不屬於訓練數據集中的類的離群值。然而,在開放集域自適應中,兩個域的共享類中的目標樣本和源樣本進一步遵循不同的分布,使得任務更具挑戰性。
開集域自適應(Open Set Domain Adaptation)
分配和變換迭代(Assign-and-Transform-Iteratively (ATI))利用每個目標域樣本的特征和每個源類別的中心之間的距離來決定目標樣本屬於源類別之一還是未知類別。
開集反向傳播(Open Set Back-Propagation (OSBP) ):訓練特征生成器來衡量目標域的樣本偏離預訓練的閾值而被分為未知類的概率。在對抗訓練框架中訓練其特征提取器和分類器。
兩種方法在開集的開放度變化很大的情況下會出現問題。
作者開發的分離適配網絡(Separate to Adapt (STA) )不需要在已知類和未知類之間手動選擇閾值參數。
Method
Open Set Domain Adaptation
基本的符號說明
\(D_s = {(X_i^s,Y_i^s)}^{n_s}_{i=1}\)表示源域的\(n_s\)個有標注的數據;\(D_t = \{{X_j^t}\}^{n_t}_{j=1}\) 表示\(n_t\)個無標簽的數據。
\(C_s\)表示源域中的類別;\(C_t\)表示目標域中的類別,而且\(C_s⊂C_t\);而\(C_{t/s}\)統一表示目標域中的未知類
源域所在的分布:p ; 目標域所在的分布:q
在標准的域適應中,q!=p ;在開集自適應中,p!=q\(C_s\) ,\(C_s\) 表示目標域中的已知類所在的分布
定義的開放度:O=1 - |\(C_s\)|/|\(C_t\)|
Separate to Adapt
開放域自適應存在淺顯的兩個挑戰:負遷移以及已知類與未知類的分離,而這兩個挑戰之間也是有聯系的。
首先一味地將整個目標域與源域進行匹配,而不將目標域的未知類分離,將導致預測結果在目標域效果不佳(出現負遷移),而要想解決負遷移的問題就要解決已知類與未知類的分離。
所以正確的邏輯應該是分離目標域中的已知類和未知類,只對已知類樣本進行特征自適應。
STA結構
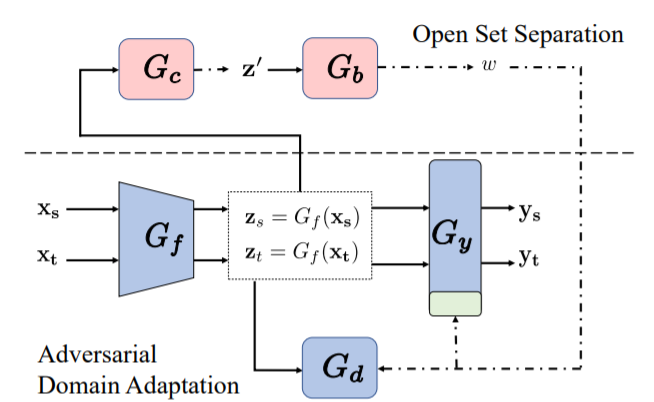
作者的網絡架構由圖中的虛線分為兩部分:
上面的\(G_c\)表示多二元分類器,\(G_b\)表示二元分類器:生成拒絕目標域未知類的權值w。
下面的\(G_f\)表示特征提取器,而\(G_y\)表示分類器,\(G_d\)表示對抗域自適應。
\(Z_s\) \(Z_t\)表示提取器提取到的特征;\(\hat{y}_s\) \(\hat{y}_t\)表示預測的標簽
Progressive Separation(漸進式分離)⭐
為了將目標域中的未知類數據從已知類中分離出來,作者設計了一個由粗到細的過濾措施。作者使用多二元分類器來衡量目標域的樣本域源域中的類相似性。每一個二元的分類器都是只由源域的數據訓練的。
所有分類器的loss表示為:
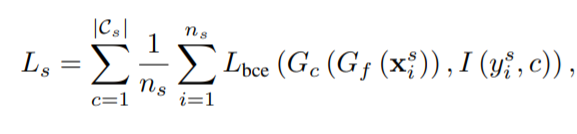
\(L_{bce}\)表示二值交叉熵的loss,如果\(y^s_i\)=c,則I(\(y^s_i\),c)=1,\(y^s_i\)!=c,則I(\(y^s_i\),c)=0
filtering strategy one
分類器\(G_c\)輸出的為目標域樣本被分類為源域中該類的概率,即可表示目標域數據與源域該類的相似性。可以預知:目標域中的未知類的概率一定比目標域的已知類概率要低,而作者使用這些概率的最大值來表示該樣本對應的源域中的類別,相應的未知類的相似性就沒有已知類的高。
於是作者將目標域中的所有樣本的相似性進行排序,分別使用排序最高的與最低的輸入\(G_b\)二元分類器進行訓練。
優點:
- 由於只使用了相似性在極限值的數據,所以過濾相對粗糙但是擁有較高的可信度
- 無需手動調整超參數,魯棒性強
filtering strategy two
將目標域中的所有樣本的相似性分為highest(\(S_h\)), midium lowest(\(S_l\))三類,當\(S_j>S_h\)則標為已知類;當\(S_j<S_l\)則標為未知類。之后將判斷后的已知類與未知類輸入\(G_b\)二元分類器進行訓練。
\(G_b\)二元分類器的loss表示為:
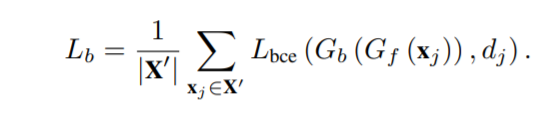
(\(X^‘\)表示多二元分類器過濾樣本集;\(d_j\)表示樣本是已知類(0)還是未知類(1))
這樣一來,通過\(G_c\)多二元分類器以及\(G_b\)二元分類器,作者實現了由粗到細的過濾,將目標域中的已知類與未知類成功分開。
Weighted Adaptation(加權適應)
在模型的對抗域適應部分,左側定義的源域的損失為:
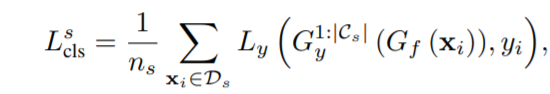
\(L_y\)是交叉熵的loss,而\(G_y\)表示添加到源域中的那一個表示為unknown class的特定分類器
\(G_y^{1:|C_s|}\)表示將每個樣本分配給已知類的概率。
在上面\(G_b\)的過濾后,作者並沒有將\(G_b\)分類的輸出作為最后結果,而是作為一個權值wj,使用wj來定義共享標簽空間Cs中特征分布的對抗性適應的加權損失
於是運用該權值為\(G_d\)定義loss:
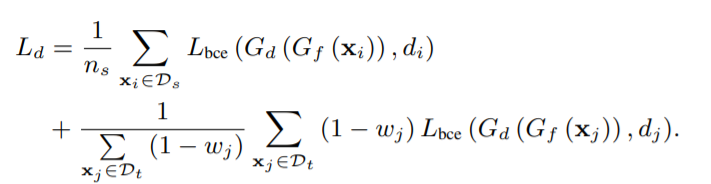
另外還需要在目標域中選取未知類的樣本,以訓練\(G_f\)獲得額外的unknown類。基於度量已知類和未知類分離度的權重wj,判別unknown類的加權損失定義為:
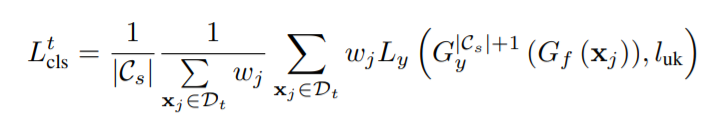
其中\(l_{uk}\)表示為unknown類,而\(G_y^{|C_s|+1}\)表示目標域的樣本為分類為未知類的概率。
進一步在已知的目標域類上加入熵最小化損失\(L_e\),以保證決策邊界包裹目標域中的低密度區域
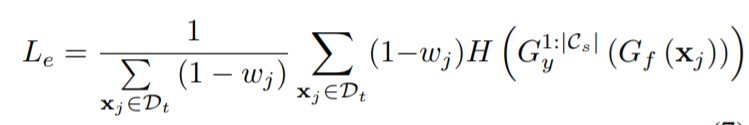
作者只將目標樣本預測為已知類的進行熵最小化,所以使用了wj作為權重。
Training Procedure
known/unknown separation step
- 首先開始訓練特征提取器\(G_f\)以及對源域進行分類的分類器\(G_y\),而多二元分類器是目標域樣本與源域所有類別進行一對多的訓練。
- 之后進一步選擇目標域中相似性高的、低的輸入細粒度\(G_b\)二元分類器進行訓練。
\(G_f\)輸出的參數:\(θ_f\) \(G_y\)輸出的參數:\(θ_y\) \(G_b\)輸出的參數:\(θ_b\) \(G_c^{|C_s|}\)輸出的參數:\(θ_c|^{|C_s|}_{c=1}\)
最優的參數\(\hat{θ}_f\) \(\hat{θ}_y\) \(\hat{θ}_b\) \(\hat{θ}_c|^{|C_s|_{c=1}}\)的選擇是:
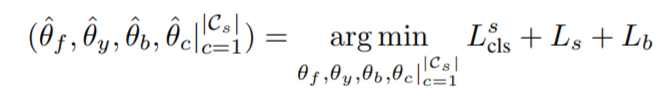
weighted adversarial adaptation step
實現對抗性自適應,使目標域中已知類的特征分布與源域保持一致,並利用未知類中的數據為額外類訓練Gy
\(θ_d\)表示\(G_d\)的參數:
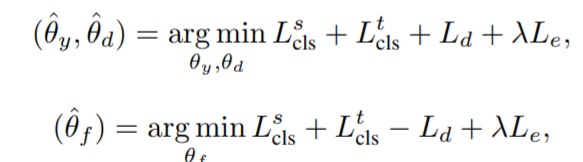
(λ是一個用於權衡熵損失的超參數)
利用分離適配(STA)模型,可以有效分離目標域中已知類和未知類的數據。
步驟1拒絕異常值以避免在步驟2中分散未知類的注意力,而步驟2執行對抗性調整以使步驟1中的拒絕管道更准確。
由於在整個過程中不需要手動選擇閾值超參數,所以在實際場景中,當開放度O變化時,我們可以避免痛苦的調整。
Experiments
Setup
數據集
Office-31:Amazon來自商場的2817張辦公室用品圖片;webcam795張低分辨率的圖片與DSLR498張高分辨率的圖片。(各個域間共享31個分類)
Office-Home:通過網絡爬取,其中包括4個域,Artistic (Ar), Clipart (Cl), Product (Pr) and Real-World (Rw)。每個域包含來自65個類別的圖像,前25個類設置為源域域目標域的共享類,而剩下的屬於未知類。4個域兩兩互換順序作為源域域目標域,共12個任務,由於未知類的個數比已知類多,所以該數據集的域間差異較大,難度也較大。
VisDA-2017:擁有兩個域,其中一個擁有152397張合成的2D圖像,另外一個包括55388張真實的圖片,兩個域擁有12個共享類。
Digits:擁有三個標准的數據集:MNIST , USPS and SVHN.作者構建了三個任務:SVHN → MNIST, MNIST → USPS 和USPS → MNIST.
Caltech-ImageNet:由ImageNet-1K與Caltech-256 datasets構建。已知類設置為84個類,而未知類從0~916變化區測試不同開放度中模型的魯棒性。
baseline
Open Set SVM (OSVM) :OSVM是一種基於支持向量機的方法,對每個類使用閾值來識別樣本和剔除異常值
MMD+OSVM 、DANN+OSVM:是OSVM的兩個變體,包含最大平均差異OSVM中的域對抗網絡
OpenMax :是一種深開放集識別方法,其模塊設計用於異常值剔除
ATI-λ:通過將目標域中的圖像分配給已知類別,將源域的特征空間映射到目標域(在作者設置中,沒有特定於源代碼的類。因此通過交叉驗證手動選擇ATI-λ的超參數λ)
OSBP:是最新的一種開放集域自適應方法,通過對抗性分類器來處理未知類的樣本,達到了最先進的性能
對於閉集方法,我們使用置信閾值來判斷樣本是否來自未知類。在我們的實驗中,我們運行每種方法三次,並報告平均精度
說明
OS:所有類的標准化精度,包括unknown 類
OS*:僅在已知類上的標准化精度
all:所有實例的精度(不包括類的平均精度)
UNK:未知樣本的精度。
對比實驗
- 使用Digits 與VisDA-2017 數據集,在OSBP方法上進行實驗作為比較。
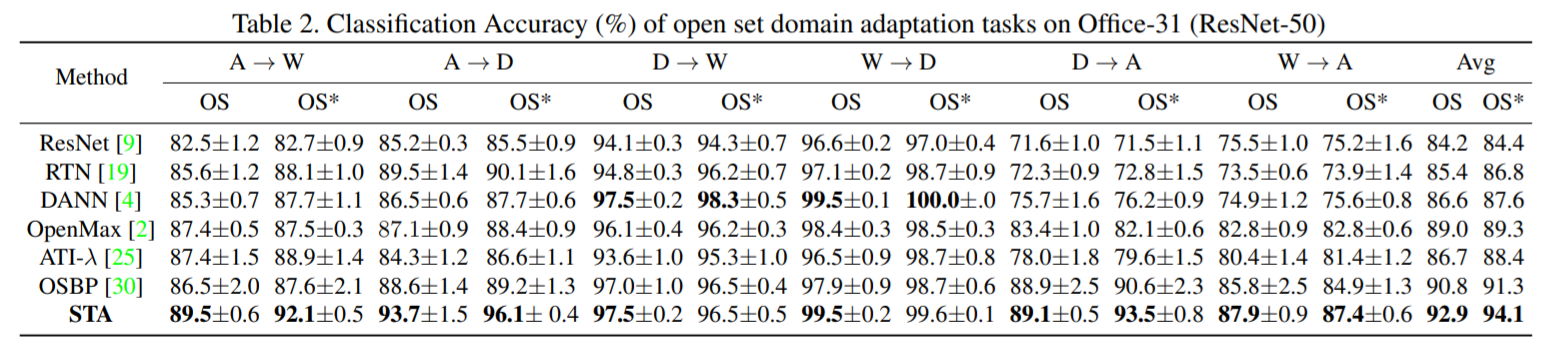
- 在所有的對比方法上用Office-31數據集做對比,使用resnet50網絡作為主干網絡
- 在Office-Home 與Caltech-ImageNet數據集上使用resnet50網絡研究OS的精度。
對於非數字的數據集,作者使用在ImageNet上預訓練的模型VGGNet 與 ResNet50進行訓練。
對於數字數據集,作者使用了LeNet網絡模型。
對抗域的網絡域DANN 是一樣的,從零開始訓練的所有層的學習率是預先訓練層的10倍。
Results
STA在digits數據集上的表現優異,而且在SVHN → MNIST情況中域間差異是比較大的,但是STA比OSBP效果好很多。
STA在VisDA-2017數據集中在大部分的類別的識別中得分較高,表示STA在大尺寸的圖片以及域間差異較大(合成圖片與真實圖片)的數據集上表現較好。

在office31數據集上STA基本在每個類上都得到了最高的分數,而我們可以看到一些在封閉集經常使用的方法在這里甚至還不如直接使用resnet網絡的效果好,原因就是在目標域的未知類較多的時候,此時的未知類不能忽略,否則就會發生負遷移。
在Office-Home數據集上,STA同樣基本在每個類上都得到了最高的分數,而一些在封閉集經常使用的方法在這里依然還不如直接使用resnet網絡的效果好,STA算法在分布匹配前分離未知類樣本,對較大的域間隔和標簽空間差異具有較強的魯棒性。
Analysis
Ablation Study
1.STA優於STA w/o w(缺少對抗域訓練的目標域樣本的權重→對已知類和未知類的樣本進行加權分離是必要的
2.STA優於STA w/o c(缺少多二元分類器中的softmax分類層)→多二元分類器可以產生更好的相似度,獨立地度量目標樣本與每個源類之間的關系
3.STA優於STA w/o b(缺少二元分類器\(G_b\))→二元分類器可以根據多個二元分類器的結果來細化未知類和已知類樣本之間的分離
4.STA優於STA w/o j(缺少Training Procedure中的兩個steps的迭代)→聯合分離和適應的有效性

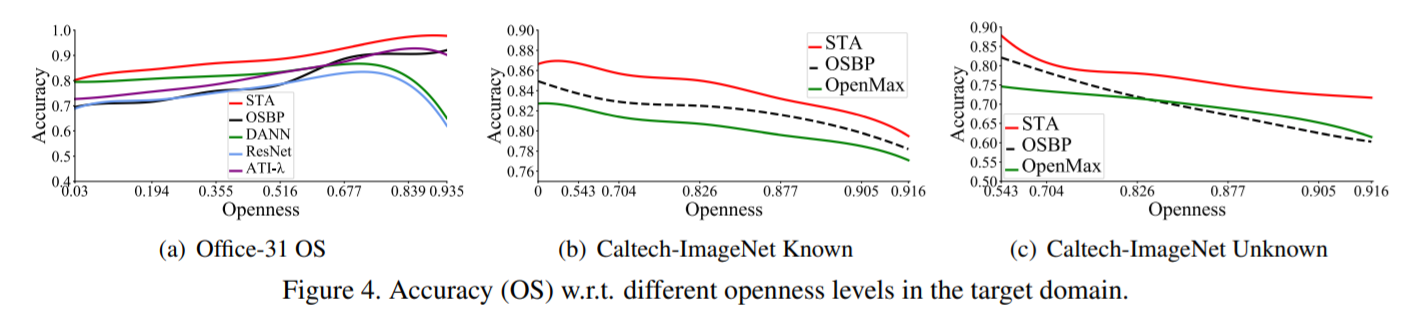
Openness
為了驗證STA在不同程度的開放度下的魯棒性,作者在office31數據集以及Caltech-ImageNet數據集上,讓開放度:O=1 - |\(C_s\)|/|\(C_t\)|從0~1變化。
結果顯示傳統的OSDA方法在開放度於0.5左右的表現較好,當開放性接近0或1時,性能會急劇下降,因為這些方法容易混淆已知類和未知類。而 ATI-λ於OSBP雖然表現較好,但在訓練之前需要先驗知識,這種方法在顯示世界中是不太可行的。
而STA在開放度的變化中表現的比較穩定,而且當開放度為0的時候,STA的得分比DANN好,表示該噪聲分離機制可以在已知的樣本中均勻地輸出。
Weight Quality
作者在任務A → W以及VisDA-2017數據集上進行了有關\(G_b\)二元分類器輸出的權重w大小與相應目標域的分類情況的變化:當源域與目標域的數據你叫相似時,w接近於1,相反則是0.

Feature Visualization
作者在Amazon → DSLR任務中展示了 ResNet, DANN, OSBP 與STA的最后一層的特征數據。
其中(a)(b)未知類特征與一些已知類的特征已經混合在一起,表示ResNet 與DANN並不能很好的區分已知類與未知類。
(c)目標域的已知類並沒有很好的分開,因為OSBP在不穩定的源域與目標域的關系中表現不是很好。
(d)STA精確地將目標域的樣本與源域對齊,並且分離目標域中的未知類。

(綠色的為源域的特征,藍色的為目標域特征,紅色的為未知類特征)
Conclusions
本文提出了一種新的分離適配(STA)模型,解決了開放集域自適應中的關鍵挑戰,即開放性。該模型以遞進機制清晰地分離未知類和已知類的樣本,並在源域和目標域之間匹配已知類樣本的特征。通過在不同的基准數據集上的驗證,該模型能夠在不同的領域差異和不相交的類下實現開放性健壯的開放集域適應。