賽題:1000張圖,在圖上貼補丁,最多不超過10個,導致檢測框失效就算得分。
比賽鏈接:https://tianchi.aliyun.com/competition/entrance/531806/information
數據描述:從MSCOCO 2017測試數據集中有條件的篩選了1000張圖像,這些圖像不會包含過多或者過少的檢測框(至少會有一個檢測框),並且檢測框的面積相對於整圖不會太小。每張圖都被resize到500 * 500的大小,並以.png的格式存儲。
攻擊的檢測器:Faster RCNN, YOLOv4,另外三個是黑盒
最近做了一段時間,分享一下思路,我做的分數不高,只是做個入門介紹。
首先介紹一下相關的論文:
- Adversarial Patch
- DPatch
- On Physical Adversarial Patches for Object Detection
- Fooling automated surveillance cameras: adversarial patches to attack person detection
Adversarial Patch
簡要思路
沒有接觸過對抗攻擊的可以從這篇入手,這是第一個在對抗攻擊中提出Patch的。傳統的對抗攻擊就是在原圖的基礎上加入肉眼不可見的噪音干擾分類器,用數學的方式定義就是,給定分類器\(\mathbb{P}\left[y\mid x\right]\),其中\(x\) 為樣本,\(y\) 為樣本自身的類別,假設我們需要誤判為的目標類別為\(\widehat{y}\) ,想要找到一個與\(x\) 相近的\(\hat{x}\) 最大化 \(\log (\mathbb{P}[\widehat{y} \mid \widehat{x}])\) , 相近的約束表示為存在一個 \(\varepsilon\)誤差滿足 \(\|x-\widehat{x}\|_{\infty} \leq \varepsilon\).
通俗點講,就是把Patch貼在圖上,跟原圖相差不大並且使分類器分類失誤,如下圖表示了Patch粘貼的方式:

損失函數
就是最大化目標類別的概率期望,導致分類器誤判即可,A就是apply函數,把Patch粘貼到圖中的方式,p為Patch的參數,x為原圖,l為位置。
但是這個與天池的比賽有點差距,因為是目標檢測的對抗攻擊,不是分類器的對抗攻擊,所以就有了下面DPatch的論文,其實道理變化不大。
DPatch
簡要思路
這篇是AAAI Workshop2019 的論文,這個思路是最貼切賽題而且非常簡單容易實現的,就是在原圖的基礎上直接添加Patch,固定住YOLO或者Faster R-CNN等檢測器的權重,反向傳播只更新Patch,文章只在圖片的左上角貼了Patch,這里需要看他的損失函數如何設計的。

如下圖所示,只在單車左上方貼上40*40的Patch,即可讓檢測器失效。

損失函數
為了訓練無目標的DPatch,這里的無目標DPatch是指只需要把檢測框失效,不需要把單車誤識別為人,這樣是有目標攻擊。所以我們希望找到一個Patch,假設把Patch貼上圖中的apply函數為A,我們需要最大化與真正的類標簽\(\hat{y}\) 和邊界框標簽\(\hat{B}\) 目標檢測器的損失:
如果是有目標攻擊,我們希望找到一個P,它能使目標類標簽\(y_t\)和邊界框標簽\(B_t\)的損失最小化:
GT的類別標簽在這個比賽中沒有提供,其實也很簡單,可以直接用未攻擊過的檢測器模型得到label存下來,我也直接用了官方給的YOLOv4的代碼跑了結果存下了類別標簽以及檢測框BBox的位置,大小。
論文效果

從指標上看,小物體如鳥這樣的無目標攻擊會比較困難。論文作者指出DPatch是具有泛化能力的,YOLO訓練出來的Patch給Faster-RCNN用也是沒問題的,反之也行。
有一份github的開源代碼https://github.com/veralauee/DPatch,我在這個基礎上把Patch與pytorch-yolov4結合,做了論文的思路,但是效果不是很好只有56分,如果把Patch貼在中心有200分左右。
On Physical Adversarial Patches for Object Detection
簡要思路
這是一篇ICML 2019 Workshop的論文,其實就是在DPatch的基礎上的一點改進,改進了參數更新的方式,應用對抗攻擊的手段,視頻效果非常好,先看效果吧。

但是這里他是顯示了有目標的全圖攻擊,把所有的框都失效了,並且把Patch中檢測出斑馬,這個跟我們的賽題其實不太符合,天池的比賽是把框都失效才有分,如果失效一個又多一個別的框並不得分。
改進點
- 給Patch貼的方式發生一些變化,不只是左上的角落,而是增加一些旋轉,亮度,位置的變化
- 損失函數用了PGD的方式
第一點其實很容易實現,在貼Patch之前應用一些變換函數上去即可,\(\delta\)是Patch的參數,\(J\)是損失函數,權重的更新方式如下:
可以對照着DPatch的更新方式:
DPatch的損失函數的更新是直接的最小化目標類別,或者最大化GT的類別,並沒有用到對抗攻擊的手段,這里直接使用了PGD一階最強攻擊,可以理解為最大化GT類別的一種方式。仔細的看更新方式,最原始的SGD就是沿着梯度的負方向更新達到最小化loss的目的,如果要最大化loss就是得沿着梯度的正方向。PGD的方式,就是對同一樣本多次沿着梯度正方向更新,但是更新的值不能太大,所以clip成0到1,也就是每次沿着梯度正方向更新0到1的值數次,達到攻擊樣本的目的。
效果
論文指出這樣訓練要比DPatch快,可是他也更新了30w輪,而且每輪還多次攻擊。
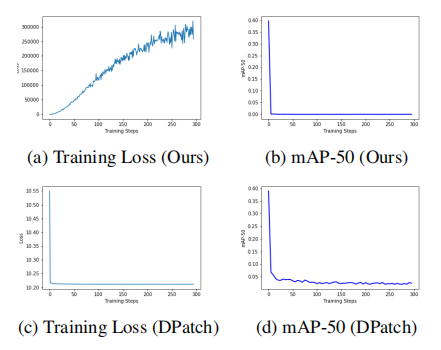
我改了以上的改進點發現並沒有太大的改變,也是200分左右。
Fooling automated surveillance cameras: adversarial patches to attack person detection
簡要思路
方法思路是差不多的,都是在原圖上貼Patch然后只更新Patch的部分,在於損失函數如何設計了。

損失函數
損失函數包含了三個,其中前兩個\(L_{n p s},L_{t v}\)是關於物理因素的,是可否打印出來進行物理攻擊的因素,在\(L_{nps}\) 中\(p_{patch}\) 是patch P中的一個像素,\(c_{print}\) 是一組可打印顏色C集合中的一種顏色。這loss 傾向於使模型中生成的Patch與我們的可打印顏色非常接近。而第二個loss是關於輪廓的smooth程度的,\(L_{t v}\) 確保了我們的加了Patch的圖像傾向於一個平滑的顏色轉換圖像。如果相鄰像素相似,則loss較低;如果相鄰像素不同,loss較高。那我們這個比賽其實不需要考慮可否打印或者平滑度,其實我在實踐中也沒有加入這兩個loss去訓練。
最后一項loss是關於有沒有物體的,其中YOLO的loss是有一項\(L_{obj}\)的,YOLO預測得到的output第四維channel就是該特征的\(L_{obj}\), 但是需要sigmoid后處理,而5到85維是coco數據集中的80類分類分數,需要softmax處理。另外0,1,2,3 維分別是x,y,w,h 用處不大。具體代碼如下,其中output為YOLOv4模型的輸出,n_ch為85維,fsize是特征圖大小,人類類別在coco數據集的80類中是第0類,所以confs_for_class只取了第0類的分類分數,最后loss是分類的分數和有無目標的分數的乘積。
output = output.view(batchsize, self.n_anchors, n_ch,
fsize * fsize)
output = output.transpose(1, 2).contiguous()
output = output.view(batchsize, n_ch,
self.n_anchors * fsize * fsize)
output_objectness = torch.sigmoid(output[:, 4, :]) # [batch, 1805]
output = output[:, 5:n_ch, :] # [batch, 80, 1805]
# perform softmax to normalize probabilities for object classes to [0,1]
normal_confs = torch.nn.Softmax(dim=1)(output)
# we only care for probabilities of the class of interest (person)
confs_for_class = normal_confs[:, 0, :]
confs_if_object = confs_for_class * output_objectness
但是作者最后也嘗試了多種組合方式,只用分類CLS的loss,只用有無目標OBJ的loss,以及代碼所示的兩個都用的loss,結果如下圖,AP應該越低越好。而用OBJ-CLS的AP值有42.8%,只用OBJ的AP值為25.53%,只用CLS的AP值為82.08%。所以要是無目標攻擊的話,最好只攻擊OBJ的loss。

我也在天池的比賽中嘗試過這篇論文的這個點,但是分數不升反降了。
結論
本次比賽重在學習,我也沒有做過對抗攻擊的研究,這番下來對目標檢測對抗攻擊領域其實有了一定的了解,也希望能夠幫助更多的人入門這個領域,我看到落地的demo有很多,攻擊的效果也是驚人,但是我的嘗試過后分數並沒有明顯的提升,也有可能是我訓練得次數太少了,目前我都是只訓練了最多500輪,論文中都是30w輪的迭代。想法十分有趣,攻擊的套路其實變化不大,都是在原圖貼Patch,然后設計loss反向傳播只更新Patch的參數,另外我發現Patch的位置其實對結果影響很大。# 【天池大賽】通用目標檢測的對抗攻擊方法一覽
作者 | 文永亮
學校 | 哈爾濱工業大學(深圳)
研究方向 | 時空序列預測,目標檢測
賽題:1000張圖,在圖上貼補丁,最多不超過10個,導致檢測框失效就算得分。
比賽鏈接:https://tianchi.aliyun.com/competition/entrance/531806/information
數據描述:從MSCOCO 2017測試數據集中有條件的篩選了1000張圖像,這些圖像不會包含過多或者過少的檢測框(至少會有一個檢測框),並且檢測框的面積相對於整圖不會太小。每張圖都被resize到500 * 500的大小,並以.png的格式存儲。
攻擊的檢測器:Faster RCNN, YOLOv4,另外三個是黑盒
最近做了一段時間,分享一下思路,我做的分數不高,只是做個入門介紹。
首先介紹一下相關的論文:
- Adversarial Patch
- DPatch
- On Physical Adversarial Patches for Object Detection
- Fooling automated surveillance cameras: adversarial patches to attack person detection
Adversarial Patch
簡要思路
沒有接觸過對抗攻擊的可以從這篇入手,這是第一個在對抗攻擊中提出Patch的。傳統的對抗攻擊就是在原圖的基礎上加入肉眼不可見的噪音干擾分類器,用數學的方式定義就是,給定分類器\(\mathbb{P}\left[y\mid x\right]\),其中\(x\) 為樣本,\(y\) 為樣本自身的類別,假設我們需要誤判為的目標類別為\(\widehat{y}\) ,想要找到一個與\(x\) 相近的\(\hat{x}\) 最大化 \(\log (\mathbb{P}[\widehat{y} \mid \widehat{x}])\) , 相近的約束表示為存在一個 \(\varepsilon\)誤差滿足 \(\|x-\widehat{x}\|_{\infty} \leq \varepsilon\).
通俗點講,就是把Patch貼在圖上,跟原圖相差不大並且使分類器分類失誤,如下圖表示了Patch粘貼的方式:
損失函數
就是最大化目標類別的概率期望,導致分類器誤判即可,A就是apply函數,把Patch粘貼到圖中的方式,p為Patch的參數,x為原圖,l為位置。
但是這個與天池的比賽有點差距,因為是目標檢測的對抗攻擊,不是分類器的對抗攻擊,所以就有了下面DPatch的論文,其實道理變化不大。
DPatch
簡要思路
這篇是AAAI Workshop2019 的論文,這個思路是最貼切賽題而且非常簡單容易實現的,就是在原圖的基礎上直接添加Patch,固定住YOLO或者Faster R-CNN等檢測器的權重,反向傳播只更新Patch,文章只在圖片的左上角貼了Patch,這里需要看他的損失函數如何設計的。
如下圖所示,只在單車左上方貼上40*40的Patch,即可讓檢測器失效。
損失函數
為了訓練無目標的DPatch,這里的無目標DPatch是指只需要把檢測框失效,不需要把單車誤識別為人,這樣是有目標攻擊。所以我們希望找到一個Patch,假設把Patch貼上圖中的apply函數為A,我們需要最大化與真正的類標簽\(\hat{y}\) 和邊界框標簽\(\hat{B}\) 目標檢測器的損失:
如果是有目標攻擊,我們希望找到一個P,它能使目標類標簽\(y_t\)和邊界框標簽\(B_t\)的損失最小化:
GT的類別標簽在這個比賽中沒有提供,其實也很簡單,可以直接用未攻擊過的檢測器模型得到label存下來,我也直接用了官方給的YOLOv4的代碼跑了結果存下了類別標簽以及檢測框BBox的位置,大小。
論文效果
從指標上看,小物體如鳥這樣的無目標攻擊會比較困難。論文作者指出DPatch是具有泛化能力的,YOLO訓練出來的Patch給Faster-RCNN用也是沒問題的,反之也行。
有一份github的開源代碼https://github.com/veralauee/DPatch,我在這個基礎上把Patch與pytorch-yolov4結合,做了論文的思路,但是效果不是很好只有56分,如果把Patch貼在中心有200分左右。
On Physical Adversarial Patches for Object Detection
簡要思路
這是一篇ICML 2019 Workshop的論文,其實就是在DPatch的基礎上的一點改進,改進了參數更新的方式,應用對抗攻擊的手段,視頻效果非常好,先看效果吧。

但是這里他是顯示了有目標的全圖攻擊,把所有的框都失效了,並且把Patch中檢測出斑馬,這個跟我們的賽題其實不太符合,天池的比賽是把框都失效才有分,如果失效一個又多一個別的框並不得分。
改進點
- 給Patch貼的方式發生一些變化,不只是左上的角落,而是增加一些旋轉,亮度,位置的變化
- 損失函數用了PGD的方式
第一點其實很容易實現,在貼Patch之前應用一些變換函數上去即可,\(\delta\)是Patch的參數,\(J\)是損失函數,權重的更新方式如下:
可以對照着DPatch的更新方式:
DPatch的損失函數的更新是直接的最小化目標類別,或者最大化GT的類別,並沒有用到對抗攻擊的手段,這里直接使用了PGD一階最強攻擊,可以理解為最大化GT類別的一種方式。仔細的看更新方式,最原始的SGD就是沿着梯度的負方向更新達到最小化loss的目的,如果要最大化loss就是得沿着梯度的正方向。PGD的方式,就是對同一樣本多次沿着梯度正方向更新,但是更新的值不能太大,所以clip成0到1,也就是每次沿着梯度正方向更新0到1的值數次,達到攻擊樣本的目的。
效果
論文指出這樣訓練要比DPatch快,可是他也更新了30w輪,而且每輪還多次攻擊。
我改了以上的改進點發現並沒有太大的改變,也是200分左右。
Fooling automated surveillance cameras: adversarial patches to attack person detection
簡要思路
方法思路是差不多的,都是在原圖上貼Patch然后只更新Patch的部分,在於損失函數如何設計了。
損失函數
損失函數包含了三個,其中前兩個\(L_{n p s},L_{t v}\)是關於物理因素的,是可否打印出來進行物理攻擊的因素,在\(L_{nps}\) 中\(p_{patch}\) 是patch P中的一個像素,\(c_{print}\) 是一組可打印顏色C集合中的一種顏色。這loss 傾向於使模型中生成的Patch與我們的可打印顏色非常接近。而第二個loss是關於輪廓的smooth程度的,\(L_{t v}\) 確保了我們的加了Patch的圖像傾向於一個平滑的顏色轉換圖像。如果相鄰像素相似,則loss較低;如果相鄰像素不同,loss較高。那我們這個比賽其實不需要考慮可否打印或者平滑度,其實我在實踐中也沒有加入這兩個loss去訓練。
最后一項loss是關於有沒有物體的,其中YOLO的loss是有一項\(L_{obj}\)的,YOLO預測得到的output第四維channel就是該特征的\(L_{obj}\), 但是需要sigmoid后處理,而5到85維是coco數據集中的80類分類分數,需要softmax處理。另外0,1,2,3 維分別是x,y,w,h 用處不大。具體代碼如下,其中output為YOLOv4模型的輸出,n_ch為85維,fsize是特征圖大小,人類類別在coco數據集的80類中是第0類,所以confs_for_class只取了第0類的分類分數,最后loss是分類的分數和有無目標的分數的乘積。
output = output.view(batchsize, self.n_anchors, n_ch,
fsize * fsize)
output = output.transpose(1, 2).contiguous()
output = output.view(batchsize, n_ch,
self.n_anchors * fsize * fsize)
output_objectness = torch.sigmoid(output[:, 4, :]) # [batch, 1805]
output = output[:, 5:n_ch, :] # [batch, 80, 1805]
# perform softmax to normalize probabilities for object classes to [0,1]
normal_confs = torch.nn.Softmax(dim=1)(output)
# we only care for probabilities of the class of interest (person)
confs_for_class = normal_confs[:, 0, :]
confs_if_object = confs_for_class * output_objectness
但是作者最后也嘗試了多種組合方式,只用分類CLS的loss,只用有無目標OBJ的loss,以及代碼所示的兩個都用的loss,結果如下圖,AP應該越低越好。而用OBJ-CLS的AP值有42.8%,只用OBJ的AP值為25.53%,只用CLS的AP值為82.08%。所以要是無目標攻擊的話,最好只攻擊OBJ的loss。
我也在天池的比賽中嘗試過這篇論文的這個點,但是分數不升反降了。
結論
本次比賽重在學習,我也沒有做過對抗攻擊的研究,這番下來對目標檢測對抗攻擊領域其實有了一定的了解,也希望能夠幫助更多的人入門這個領域,我看到落地的demo有很多,攻擊的效果也是驚人,但是我的嘗試過后分數並沒有明顯的提升,也有可能是我訓練得次數太少了,目前我都是只訓練了最多500輪,論文中都是30w輪的迭代。想法十分有趣,攻擊的套路其實變化不大,都是在原圖貼Patch,然后設計loss反向傳播只更新Patch的參數,另外我發現Patch的位置其實對結果影響很大。