概述
這篇文章主要介紹了JVM中Synchronized鎖實現的機制。
主要分為幾個部分:
- 虛擬機對Synchronized的處理以及鎖機制
- 虛擬機對Synchronized鎖的優化
- Synchronized鎖的膨脹過程圖解
- 查看對象頭在Synchronized的上鎖,釋放鎖,以及膨脹過程中的變化
虛擬機對Synchronized的處理
了解虛擬機類文件結構的同學們一定知道,對於synchronzied方法塊而言,虛擬機在塊內的方法前后會增加moniterenter和moniterexit兩個指令,而對於synchronized方法來說,在方法的ACCESS_FLAG中會出現一個ACC_SYNCHRONIZED的標志位,虛擬機會根據該標識位隱式的執行同步過程。
這兩種都是由管程(Monitor)支持實現的(應該說是在虛擬機未對鎖優化前)。一個線程在上鎖的時候會嘗試獲取對象關聯的monitor,如果該monitor未被其他線程獲取,那么該線程將會獲得此monitor,將ownership改為自己,並將鎖的計數器加1。否則線程將進入monitor的等待隊列,等待monitor被釋放后再嘗試獲取。
整個過程是基於mutex互斥量來實現的,因此需要涉及用戶態和內核態的切換,會消耗很多處理器時間。因此,基於該方式實現的synchronized鎖也被稱為重量級鎖。
虛擬機對Synchronized鎖的優化
JDK1.6之后對傳統的Synchronized的鎖做了很多優化,盡量避免重量級鎖的直接使用,提高線程在上鎖和釋放鎖時的效率。
重量鎖(互斥鎖)
上文已經介紹了傳統的synchronzied鎖是基於mutex互斥量的,其主要的缺點是是在上鎖過程中可能需要掛起線程,涉及用戶態和內核態的切換,浪費處理器時間。
輕量級鎖:
輕量級鎖的輕量級是相對於基於mutex互斥量實現的重量級鎖而言。
在我們大部分的程序中,線程間的競爭並不激烈,且線程並不會長時間的持有鎖。如果在不存在競爭並且鎖將立被釋放的情況下,也通過重量級鎖去上鎖和釋放鎖,那么對鎖的操作浪費的時間可能比代碼執行的時間更多。
輕量級鎖通過CAS設置加自選等待的方式解決了上述這種場景下重量級鎖低效的問題。
在使用輕量級鎖時,線程會嘗試通過CAS更新鎖對象的對象頭,如果更新成功,說明成功標記對象。如果更新失敗,則說明該對象已經被其他線程持有,線程會進入自選等待,因為通常一個線程不會長時間的持有鎖,因此很可能嘗試獲取鎖的線程只需要幾次自旋獲取鎖。
如果一段時間自選后,線程依舊無法獲取鎖,那么輕量級鎖才會被升級成為重量級鎖。
偏向鎖
雖然輕量級鎖已經極大的提升了鎖的效率,但是線程每次上鎖和釋放鎖依然會產生時間的浪費。而一種極端的情況下,一個鎖可能都是由某個線程去獲取的(也就是其他線程不太會去獲取這個鎖,也就是不存在競爭的情況)。
偏向鎖就是出於對上述這種情況而進行的優化,希望將無競爭下的同步過程消除。
偏向鎖會偏向第一個獲取他的線程,之后就算該線程退出同步方法,偏向鎖對該線程的標記依舊在,這樣做的好處是該線程之后獲取鎖和釋放鎖都不需要進行CAS更新操作。只需要對比偏向鎖的標記是否未自己。
直到有其他線程獲取該鎖時,發現該鎖標記的對象不是自己,則會要求該鎖升級。
編譯器對鎖的優化
除了上述鎖實現機制的優化外,編譯器還通過自旋,鎖消除,鎖粗化的方式對鎖進行優化。
自旋
自旋在介紹輕量級鎖時也介紹到了,當線程發現鎖被持有時,線程不會立即掛起,而是嘗試自選等待。
這樣做的好處是,避免了操作系統在用戶態和內核態的來回切換。但是缺點是自旋等待會白白占用處理器的運行時間。
鎖消除
鎖消除是指在一些不存在競爭的情況下,編譯器會取消掉同步的過程。
鎖粗化
鎖粗化是指某一線程在一個方法內頻繁的上鎖和釋放鎖,編譯器會主動擴大一次上鎖覆蓋的范圍,減少上鎖和釋放鎖的次數。
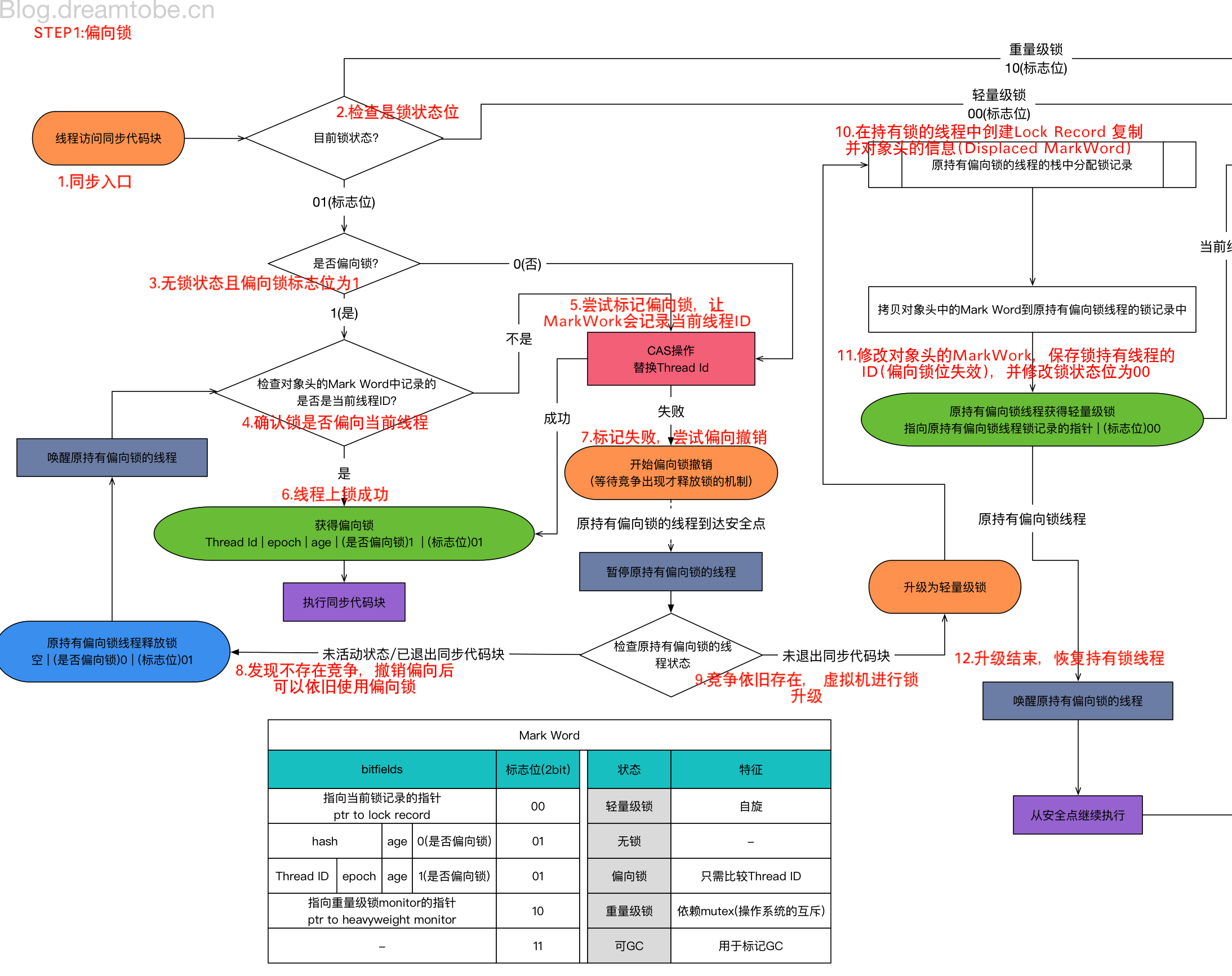
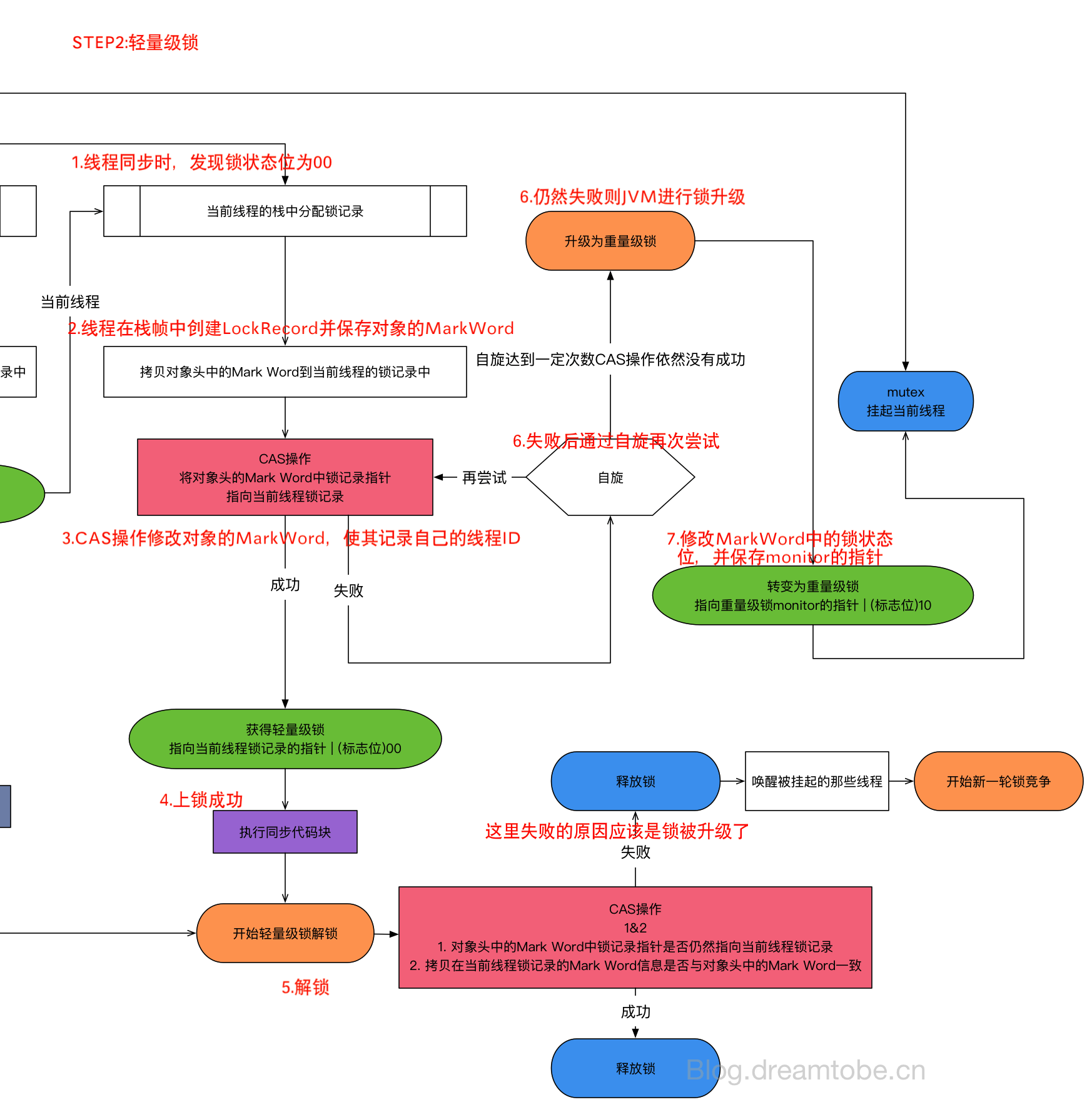
鎖的膨脹過程圖解
上文介紹了虛擬機對Synchronized鎖做了優化。
在開啟了偏向鎖的情況下,先會使用偏向鎖,當有線程競爭偏向鎖時,會發生鎖的升級,偏向鎖會升級為輕量級鎖。
如果輕量級鎖超過一定自旋次數,仍舊無法獲取,那么會發生鎖膨脹,變成重量級鎖,通過mutex的方式實現互斥。
並且這一過程中會造成對象頭中Mark Word的改變,或者說對象頭中的Mark Word會記錄着這一過程的變化。
那么什么是Mark Word?OpenJDK中給出的定義如下:
mark word:The first word of every object header. Usually a set of bitfields including synchronization state and identity hash code. May also be a pointer (with characteristic low bit encoding) to synchronization related information. During GC, may contain GC state bits.
Mark Word:是每個對象頭中第一個字。用一組位表示同步鎖狀態和哈希值等,也可能指向同步鎖相關的信息(如遇字符,則用小端)。在GC階段,還包含了GC狀態。
從這里我們基本可以了解到 MarkWord 是一個標志對象諸多狀態的一字長的數據(32位虛擬機和64位虛擬機所占位數不同)。
更具體的,我們可以通過下圖(原圖出處)了解下對象頭中Mark Word在各種鎖狀態下的結構(這里以64位虛擬機為例,32位虛擬機基本類似)。

處於節約內存的目的考慮,MarkWord的一字長的數據會在不同狀態下用來表示不同的信息。
從右往左看,最后兩位是鎖狀態的標志位。結合鎖標志位和偏向鎖標識位,我們就可以區分當前對象鎖的狀態,其余的位可能會用來記錄線程或是其他相關的指針信息。
大致了解完 Mark Word結構后,我們通過另一張圖片(原圖出處)了解鎖膨脹的過程,結合過程中Mark Word的改變。關於Mark Word的詳細說明將在下文介紹。

這幅圖非常詳細,我們可以拆成三部分逐個過程分析:
偏向鎖的上鎖與釋放過程,以及鎖升級
輕量級鎖的上鎖與釋放過程,以及鎖升級
重量級鎖的上鎖與釋放
這部分流程比較簡單,不再贅述。
對象頭查看
上面從理論上介紹了鎖的升級過程,但是對於對象頭這種看不見摸不着的信息,可能依然有同學看的懵里懵懂。
好在openjdk提供了一個利器幫助我們打印對象頭信息——jol-core庫。
可以通過 maven添加到我們的庫中:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
在開始測試前,有一點需要明確:32位虛擬機和64位虛擬機對象頭的結構是有一些差異的(本文測試均是基於64位虛擬機),且結構是以小端的方式存儲數據。
測試准備:
以下是我們測試的一些基礎類:;Monitor類作為對象鎖的類,主要是驗證MarkWord關於HashCode的內容:
Foo類
保存上鎖的方法
public class Foo {
private Monitor lock = new Monitor();
public void sync(){
synchronized (lock){
System.out.println("------------in sync()-------------");
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
}
}
public void syncAndSleep() throws InterruptedException {
synchronized (lock){
System.out.println("------------take time sync()-------------");
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
Thread.sleep(5000);
}
}
public void printLockObjectHeader(){
System.out.println("Thread:" + Thread.currentThread().getName() + ";" +ClassLayout.parseInstance(lock).toPrintable());
}
public void calculateHashAndPrint(){
System.out.println("Calculate Hash:" +Integer.toHexString(lock.hashCode()));
System.out.println("After invoke hashcode, print Object again");
System.out.println(ClassLayout.parseInstance(lock).toPrintable());
}
}
Monitor類
Monitor類是測試中用作對象鎖的類簡單的繼承了Object類,僅可能會對hashCode方法做一些修改(用來驗證MarkWord中哈希值的相關信息)。
public class Monitor {
//我們可能處於特定的測試目的考慮,會注釋掉這個方法,使用仍使用父類的方法
@Override
public int hashCode() {
//必須要調用父類的hashCode方法 mark work中才會存hashCode
return 0xff;
}
}
SynchronizedUpgradeTest類
測試主入口,內部的幾個方法之后幾個測試的內容,之后我們將會依次運行這些方法對比對象頭的信息:
public class SynchronizedUpgradeTest {
static Foo foo = new Foo();
public static void main(String[] args) throws InterruptedException {
hashCodeTest();
// biasedLock();
// biasedLockInvalidAfterCalculate();
// biasedLockUpgradeToLightLock();
// lightLockToWeightLock();
}
protected static void hashCodeTest(){
foo.printLockObjectHeader();
foo.calculateHashAndPrint();
}
/**
* JVM OPTIONS: -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
*/
protected static void biasedLock(){
foo.printLockObjectHeader();
foo.sync();
System.out.println("Exit sync()");
foo.printLockObjectHeader();
}
/**
* JVM OPTIONS: -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
*/
protected static void biasedLockInvalidAfterCalculate(){
foo.printLockObjectHeader();
foo.calculateHashAndPrint();
foo.sync();
System.out.println("out sync()");
foo.printLockObjectHeader();
}
/**
* JVM OPTIONS: -XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
*/
protected static void biasedLockUpgradeToLightLock(){
foo.printLockObjectHeader();
foo.sync();
System.out.println("out sync()");
foo.printLockObjectHeader();
System.out.println("---Another Thread Use Biased Lock");
Thread thread = new Thread(()->{
foo.sync();
System.out.println("---Another Thread Out sync");
foo.printLockObjectHeader();
});
thread.start();
}
/**
* JVM OPTIONS: -XX:UseBiasedLocking -XX:BiasedLockingStartupDelay=10
*/
protected static void lightLockToWeightLock() throws InterruptedException {
foo.printLockObjectHeader();
new Thread(()->{
try {
foo.syncAndSleep();
foo.printLockObjectHeader();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
Thread.sleep(1000L);
foo.sync();
foo.printLockObjectHeader();
}
}
以上全部測試代碼都可以在我的GitHub中找到。同時為了保證測試的正確性,需要確保虛擬機運行參數和測試方法上的配置一致!
開始測試
測試1:MarkWord中哈希值——hashCodeTest()

可以從測試的圖片中看到,對象鎖MarkWord中關於鎖的那幾位確實是101,說明是偏向鎖沒錯。但是在無論在調用hashCode前還是后的打印,MarkWord中都沒有記錄對象的Hash值。這似乎和我們值錢了解到的不太一樣。其實這是因為我們重寫了hashCode()方法。只有調用原生的hashCode()才會將哈希值記錄在MarkWord中!
為了驗證我們的猜測,我們注釋掉Monitor類中的hashCode()方法,在測試一次。

當我們使用Object中的hashCode()方法時,MarkWord確實保存了哈希值。但是,另一個有趣的事情發生了,偏向鎖直接升級成了輕量級鎖。
測試2:偏向鎖上鎖與解鎖測試——biasedLock()
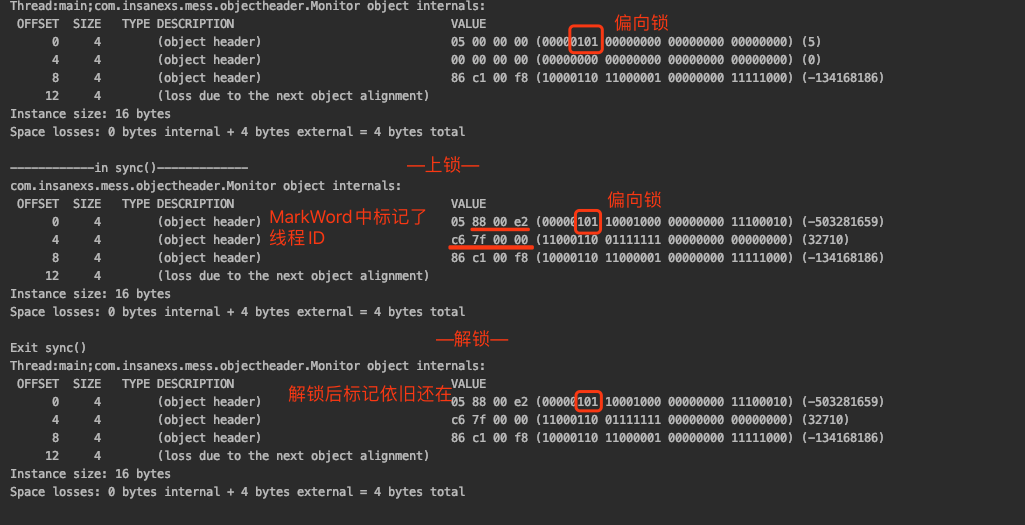
從這里結果我們可以看出,解釋線程釋放了偏向鎖,偏向鎖依舊保存着線程的ID。
測試3:偏向鎖升級為輕量級鎖——biasedLockUpgradeToLightLock()
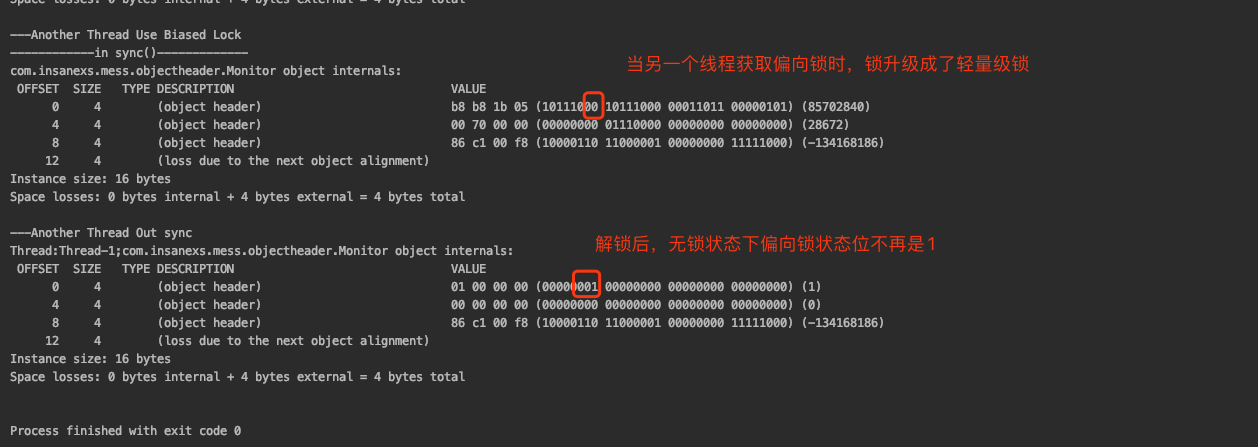
當偏向鎖被標記過后,另一個線程再去獲取鎖時,鎖會被升級成輕量級鎖。並且在解鎖后,也沒有重新回到偏向鎖的狀態。
測試4:輕量級鎖膨脹為重量鎖———lightLockToWeightLock()
測試開始前,我們通過JVM參數設置讓偏向鎖一開始先不生效。

從測試結果中,我們可以看到輕量級鎖膨脹為重量鎖的過程。並且MarkWord中記錄的信息也由棧幀的指針改為了monitor的指針。