對於指針分析尤其是Java指針分析來說,上下文敏感是最有效的提升精度的方法,上下文敏感的指針分析是指針分析領域最近幾年研究的熱點,上下文敏感不是指針分析獨有的技術,理論上所有跨函數間的分析都會涉及到上下文敏感。我們當前先研究上下文敏感的指針分析。
1.上下文不敏感指針分析的缺陷
我們用一個例子來說明為什么我們需要上下文敏感技術,示例程序如下圖所示:

我們使用之前的指針分析來分析上面的程序,這個程序很簡單,入口是main函數,然后定義了一個接口Number,定義了兩個類One和Two分別繼承了這個接口,main中創建了兩個對象n1和n2,並將這兩個對象傳導方法id里(id是identity的縮寫)並分別返回x和y,我們要分析的是i的值是多少。動態運行時i的值明顯為1,靜態分析時用常量傳播方式來判斷i的值。
要知道i的值,我們需要先知道x.get()調用的對象,使用指針分析方法解決x.get的調用。
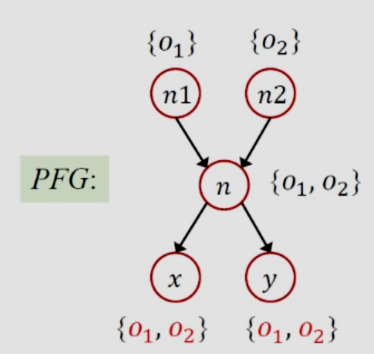
如上圖所示,x來自於id方法的返回值,因為id方法有兩個實參n1和n2,做指針分析時候做PFG,n1和n2都會留給形參n,二者分別指向o1和o2,因此這兩個對象都留到了n的指針集里,又根據n分別返回了x和y,因此o1和o2返回了x和y,因此分析結果如下:
可得x.get()調用了兩個方法(分別是One和Two中的get()方法),因此返回值就是1和2,因此結論i的值為NAC,這個結果肯定是不准的,分析過程中多了一條調用邊,上下文不敏感就是這樣對於調用語句不做區分,因此造成了精度的下降,因此我們提出了上下文敏感的指針分析,對於該實例的上下文敏感分析如下:

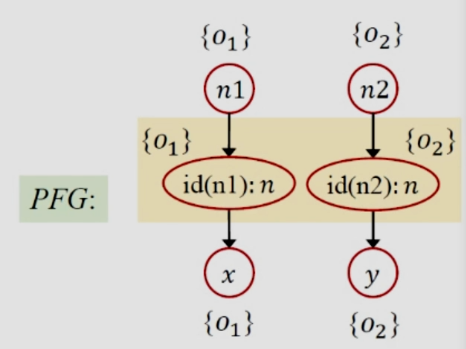
從代碼來看,id方法有兩個調用(前面已經提到),上下文敏感就是將這兩個調用區分開,id(n1)這次分析就是將n1參數傳遞給id(n1)中的形參n,id(n2)同理,二者分開分析,返回值也是如法炮制,將一個方法的不同調用區分開,這樣就可以得到更精確的結果。

2.Introduction
2.1上下文不敏感精度低的原因
上下文不敏感(簡稱C.I.)在動態執行過程中一個方法可能會被調用很多次,但是每次調用的上下文可能會不同(在指針分析中通常就是參數和返回點不一樣),在C.I.中對於一個方法所有的調用都傳給了同一個形參,它們混在一起不做區分,之后會通過返回值等方式將所有的調用的數據流都傳回去,副作用就是假設我們對於傳回來的對象的field進行修改,如果不區分的話所有的數據流都會被修改,被錯誤修改的數據流會傳到程序的其他部分,這樣就會形成假的數據流(spurious data flows)。
2.2上下文敏感(C.S.)
為了克服上面的問題,我們采用上下文敏感的方式,上下文敏感可以區分不同上下文下的數據流。
最經典的上下文敏感技術是call-site sensiticity(call-string ),對於方法的上下文,它將調用點的相關信息用一個串串起來,串的內容如下:
- call site
- call site所在方法的caller
- call site所在方法caller的caller
這個上下文實際上就是對於動態執行過程的一個抽象。我們用一個例子來理解該方法:

對於id(Number)這個方法有哪些上下文呢?
一個call site就是一個語句,在該示例中,id方法有兩個call site id(n1)和id(n2),因此id方法就有兩個上下文id(n1)和id(n2)
2.3Cloning-Based C.S
實現上下文最基本的策略是使用克隆的方法,在C.S.中,對於所有的方法都要用上下文加以修飾,對於所有變量也需要加上上下文的修飾(該上下文來自於變量所在的方法),給每個方法和變量修飾之后就相當於對它們進行了“克隆”。上面的代碼用這種方法分析就可以得到:
這樣就能避免上下文非敏感導致的精度的丟失。
2.4Context-Sensitive Heap
OO語言(如Java)會頻繁對對象進行操作,我們將這種行為稱為heap-intensive,為了取得較好的操作,我們也要給堆加上下文,稱之為heap contexts。
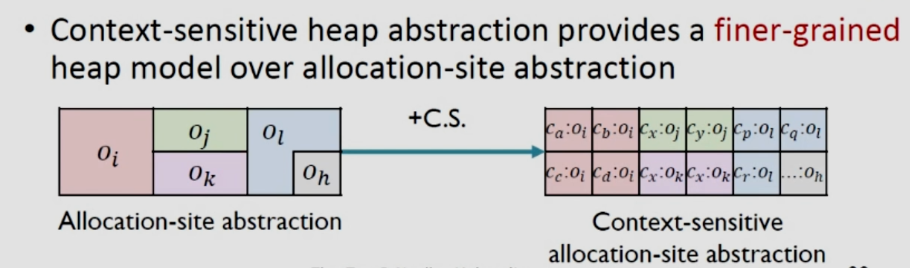
就是將上下文敏感技術應用到堆抽象之上,上圖左邊是將五個調用點堆抽象,而在右邊用不同上下文對它們進行細分,提高了粒度。
原理
程序動態執行時一個調用點在不同的上下文時會創建不同的對象,如果上下文不敏感的話會導致假的數據流,這也就是為什么我們需要利用上下文敏感進行堆抽象。
示例
我們用一個例子來解釋上下文敏感堆這個概念:
n1 = new One();
n2 = new Two();
x1 = newX(n1);
x2 = newX(n2);
n = x1.f;
XnewX(Number p){
X x = new X();
x.f = p;
return x;
}
class X{
Number f;
}
在函數newX中創建了一個對象x,然后將x的field設置成p再將它返回,n指向哪個對象呢?很明顯動態執行時指向的是n1所指向的new One()對象,下面我們分別用上下文敏感堆和不敏感堆對n的指向進行分析。
C.S.,no C.S.heap

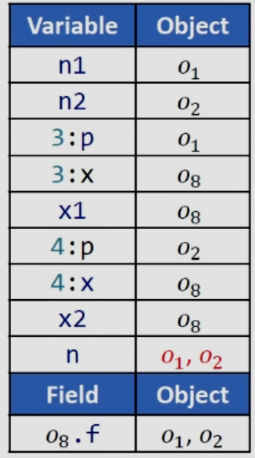
可以看到,在分析完x1和x2的指向之后,o8.f指向o1和o2,n從x1中讀取,而從表格中可知x1指向o8,因此最終得到n的指向是o1和o2,我們知道動態運行時n不會指向o2,這里就產生了假的數據流。這是因為在newX中因為參數的不同我們是創建了兩個不同的對象x,在當前的做法下沒有區分這兩個對象,這就會導致問題的出現。
C.S.+C.S.heap
通過分析第八行,對於3:x就指向了3:o8,對應的3:o8.f就指向了o1,同理分析x2,可得結果如下:

可以很明顯的看到,采用C.S.heap方法能夠顯著的提高分析精度。
C.I.+C.S.heap
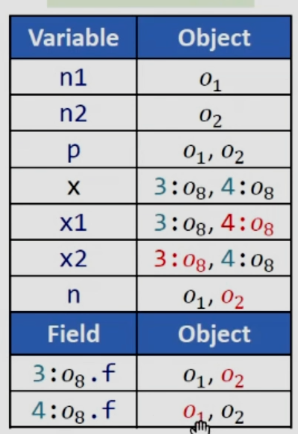
可以看到如果沒有變量的上下文只是用堆上下文也不能實際上提高精度。
總結
heap上下文和變量上下文是相輔相成缺一不可的,二者缺了哪一個都不能有效的提升精度。
3.Rules
3.1Domains and Notations

在上下文敏感的指針分析中,程序中的所有部件都用上下文分析。C代表指針分析中的所有上下文,具體的上下文用小寫的c來分別表示。
- 上下文敏感方法:對於域M進行擴展,將它與所有上下文C相乘
- 上下文變量同上
- 上下文對象同上
- Field本身不需要上下文,但是在引用某個具體的實例Field的時候就將它們拓展(即掛靠)。
- 上下文敏感指針,指針有兩種類型,變量和field,因此上下文敏感指針就由這兩部分組成
- 指向關系pt,將上下文敏感的指針指向帶着上下文對象的集合
3.2指針分析的規則
3.2.1綜述
以下是上下文敏感指針分析中前四種語句的規則,這其實就是之前不敏感指針分析的變種(添加了上下文)
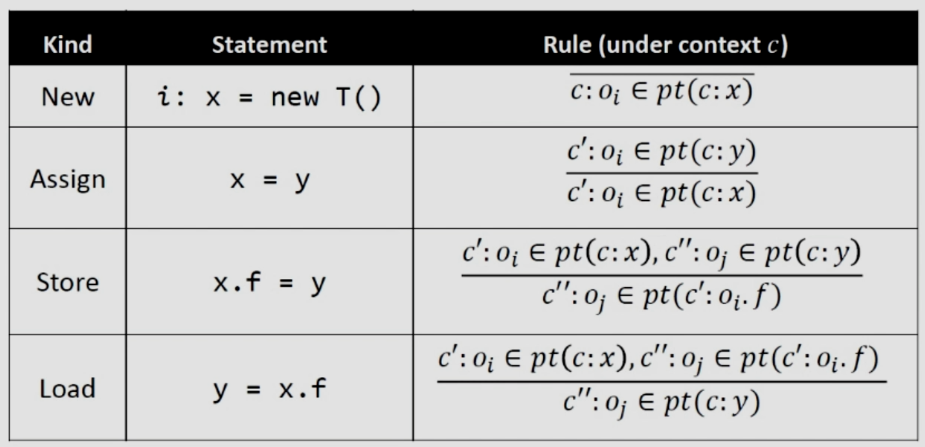
首先假設語句都是屬於某個方法的,語句就會從對應的方法獲取上下文進行對應的操作,下面我們分開來看這四種語句。
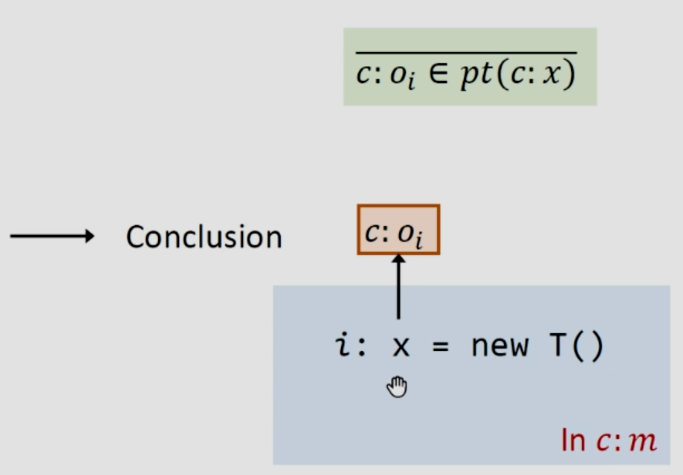
3.2.2Rule:New
就是一個對象的創建,假設語句屬於某個方法m,在上下文c之下。該變量也就是上下文c之下的變量
 如上圖所示,c之下創建出來的對象用c:oi表示,並且用c之下的x指針指向c:oi。
如上圖所示,c之下創建出來的對象用c:oi表示,並且用c之下的x指針指向c:oi。
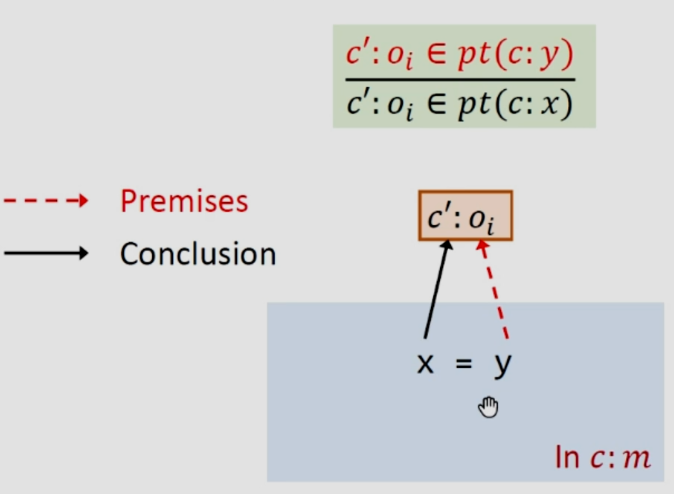
3.2.3Rule:Assign
就是賦值語句,就是將y的值給了x。

假設我們在上下文c之下分析這個賦值語句,就認為這里的x和y都是在c之下的,如果某個對象被c之下的y所指向,就將它加入到c之下x指向的集合中
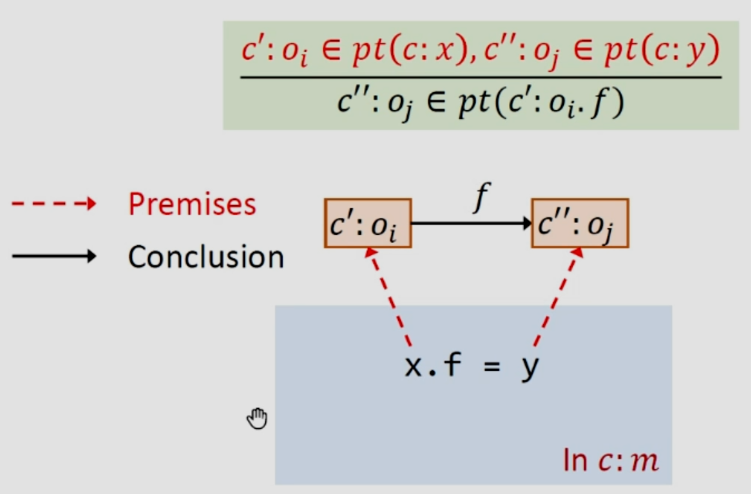
3.2.4Rule:Store
如下圖,還是假設這條語句是在上下文c之中,c‘和c''可能相同也可能不同,x和y的c一定是一樣的。

store是將y指向的對象存給x指向對象的一個field:f,首先我們去除x在c之下指向的對象和c之下y指向的對象,接下來將后者添加到前者的field:f所指向的集合中。
3.2.5Rule:Load
Load和Store是對稱的。理解了Store再理解Load就很簡單了,這里就不展開說了。
3.2.6Rule:Call
這是最復雜的上下文敏感分析。
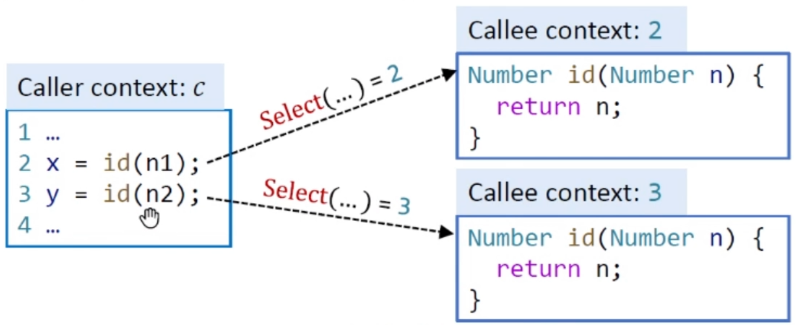
Call語句決定了上下文是怎樣產生的,所以對於Call語句的上下文分析是最重要的。
我們先假設調用是在某個方法里,該方法上下文是c,我們可以先求出c'.oi,這個是recieve object,然后進行Dispatch,根據對象類型以及方法簽名k可以得到目標方法,用m表示,接下來我們要選擇上下文,我們定義了一個Select函數,對於一個目標函數m,根據call site l這一點能拿到的信息選擇上下文,得到ct,用我們前面的例子來解釋如下:
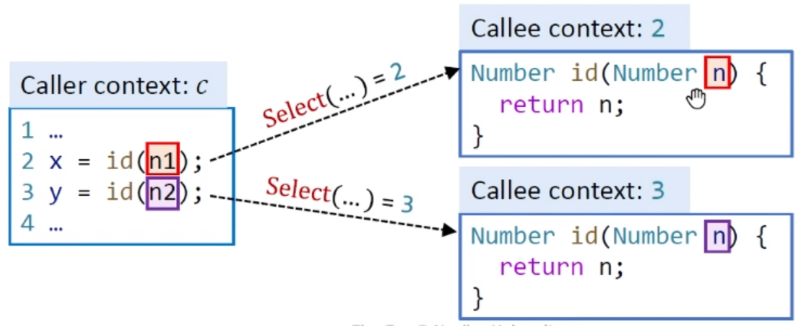
假設我們出去左邊的代碼,上下文為c,先處理第二行代碼,假設我們使用Select方法對語句2得到的結果是2,那么我們就說對於第二行的上下文就是2,同理對第三行進行一樣的操作(這里沿襲了clone-based的方法),這樣就將語句的上下文就取出來了,我們真正的目標方法就是這個上下文之下的該方法。
接下來我們要開始傳recieve object,將它傳給ct之下的mthis,然后就是傳參,這個過程跟recieve object類似,將c之下所有的實參取出來,將它們傳給特定上下文的形參。如下圖所示
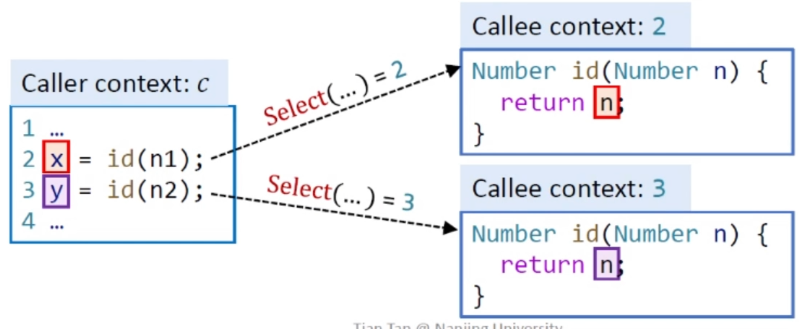
我們要將n1傳給上下文2中的n(即2:n),n2傳給上下文3中的n(即3:n),二者不會混合和沖突。
最后一步是傳返回值,如果是ct中返回值指向的就將它傳給當前上下文c中等號左邊的變量。
還是之前的例子,在處理第二行調用時,上下文2中的返回值n應該傳給第二行中的x,同理上下文3中的返回值n應該傳給第三行中的y。