而在每個任務運行前,CPU 都需要知道任務從哪里加載、又從哪里開始運行,也就是說,需要系統事先幫它設置好 CPU 寄存器和程序計數器
CPU 寄存器,是 CPU 內置的容量小、但速度極快的內存。而程序計數器,則是用來存儲CPU 正在執行的指令位置、或者即將執行的下一條指令位置。它們都是 CPU 在運行任何任務前,必須的依賴環境,因此也被叫做 CPU 上下文
CPU 上下文切換,就是先把前一個任務的 CPU 上下文(也就是 CPU 寄存器和程序計數器)保存起來,然后加
載新任務的上下文到這些寄存器和程序計數器,最后再跳轉到程序計數器所指的新位置,運行新任務。
根據任務的不同,CPU 的上下文切換就可以分為幾個不同的場景,也就是進程上下文切換、線程上下文切換以及中斷上下文切換。
進程上下文切換
Linux 按照特權等級,把進程的運行空間分為內核空間和用戶空間,CPU 特權等級的 Ring 0 和 Ring 3。進程既可以在用戶空間運行,又可以在內核空間中運行。進程在用戶空間運行時,被稱為進程的用戶態,而陷入內核空間的時候,被稱為進程的內核態。
從用戶態到內核態的轉變,需要通過系統調用來完成。比如,當我們查看文件內容時,就需要多次系統調用來完成:首先調用 open() 打開文件,然后調用 read() 讀取文件內容,並調用 write() 將內容寫到標准輸出,最后再調用 close() 關閉文件。
內核空間(Ring 0)具有最高權限,可以直接訪問所有資源;
用戶空間(Ring 3)只能訪問受限資源,不能直接訪問內存等硬件設備,必須通過系統調用陷入到內核中,才能訪問這些特權資源。
系統調用的過程有沒有發生 CPU 上下文的切換呢?答案自然是肯定的
CPU 寄存器里原來用戶態的指令位置,需要先保存起來。接着,為了執行內核態代碼,
CPU 寄存器需要更新為內核態指令的新位置。最后才是跳轉到內核態運行內核任務 >
而系統調用結束后,CPU 寄存器需要恢復原來保存的用戶態,然后再切換到用戶空間,繼續運行進程。所以,一次系統調用的過程,其實是發生了兩次 CPU 上下文切換。
系統調用過程中,並不會涉及到虛擬內存等進程用戶態的資源,也不會切換進程。這跟我們通常所說的進程上下文切換是不一樣的:
進程上下文切換,是指從一個進程切換到另一個進程運行。
而系統調用過程中一直是同一個進程在運行
所以,系統調用過程通常稱為特權模式切換,而不是上下文切換。但實際上,系統調用過程中,CPU 的上下文切換還是無法避免
進程上下文切換跟系統調用又有什么區別呢?
進程是由內核來管理和調度的,進程的切換只能發生在內核態。所以,進程的上下文不僅包括了虛擬內存、棧、全局變量等用戶空間的資源,還包括了內核堆棧、寄存器等內核空間的狀態。
因此,進程的上下文切換就比系統調用時多了一步:在保存當前進程的內核狀態和 CPU 寄存器之前,需要先把該進程的虛擬內存、棧等保存下來;而加載了下一進程的內核態后,還需要刷新進程的虛擬內存和用戶棧。
如下圖所示,保存上下文和恢復上下文的過程並不是“免費”的,需要內核在 CPU 上運行才能完成
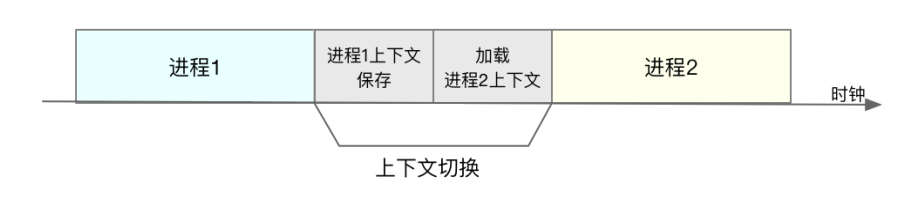
每次上下文切換都需要幾十納秒到數微秒的 CPU 時間。這個時間還是相當可觀的,特別是在進程上下文切換次數較多的情況下,很容易導致 CPU 將大量時間耗費在寄存器、內核棧以及虛擬內存等資源的保存和恢復上,進而大大縮短了真正運行進程的時間。這也正是上一節中我們所講的,導致平均負載升高的一個重要因素。
Linux 通過 TLB(Translation Lookaside Buffer)來管理虛擬內存到物理內存的映射關系。當虛擬內存更新后,TLB 也需要刷新,內存的訪問也會隨之變慢。特別是在多處理器系統上,緩存是被多個處理器共享的,刷新緩存不僅會影響當前處理器的進程,還會影響共享緩存的其他處理器的進程
什么時候會切換進程上下文
進程切換時才需要切換上下文,換句話說,只有在進程調度的時候,才需要切換上下文。Linux 為每個 CPU 都維護了一個就緒隊列,將活躍進程(即正在運行和正在等待CPU 的進程)按照優先級和等待 CPU 的時間排序,然后選擇最需要 CPU 的進程,也就是優先級最高和等待 CPU 時間最長的進程來運行
進程在什么時候才會被調度到 CPU 上運行呢?
就是進程執行完終止了,它之前使用的 CPU 會釋放出來,這個時候再從就緒隊列里,拿一個新的進程過來運行。其實還有很多其他場景,也會觸發進程調度,在這里我給你逐個梳理下。
其一,為了保證所有進程可以得到公平調度,CPU 時間被划分為一段段的時間片,這些時間片再被輪流分配給各個進程。這樣,當某個進程的時間片耗盡了,就會被系統掛起,切
換到其它正在等待 CPU 的進程運行。
其二,進程在系統資源不足(比如內存不足)時,要等到資源滿足后才可以運行,這個時候進程也會被掛起,並由系統調度其他進程運行。
其三,當進程通過睡眠函數 sleep 這樣的方法將自己主動掛起時,自然也會重新調度。
其四,當有優先級更高的進程運行時,為了保證高優先級進程的運行,當前進程會被掛起,由高優先級進程來運行。
其五,發生硬件中斷時,CPU 上的進程會被中斷掛起,轉而執行內核中的中斷服務程序。
線程上下文切換
1,線程與進程最大的區別在於,線程是調度的基本單位,而進程則是資源擁有的基本單位。
所謂內核中的任務調度,實際上的調度對象是線程;而進程只是給線程提供了虛擬內存、全局變量等資源。
可以這么理解線程和進程:
當進程只有一個線程時,可以認為進程就等於線程。
當進程擁有多個線程時,這些線程會共享相同的虛擬內存和全局變量等資源。這些資源在上下文切換時是不需要修改的。
另外,線程也有自己的私有數據,比如棧和寄存器等,這些在上下文切換時也是需要保存的
線程的上下文切換其實就可以分為兩種情況:
第一種,前后兩個線程屬於不同進程。此時,因為資源不共享,所以切換過程就跟進程上下文切換是一樣。
第二種,前后兩個線程屬於同一個進程。此時,因為虛擬內存是共享的,所以在切換時,虛擬內存這些資源就保持不動,只需要切換線程的私有數據、寄存器等不共享的數據
同進程內的線程切換,要比多進程間的切換消耗更少的資源,而這,也正是多線程代替多進程的一個優勢
中斷上下文切換
為了快速響應硬件的事件,中斷處理會打斷進程的正常調度和執行,轉而調用中斷處理程序,響應設備事件。而在打斷其他進程時,就需要將進程當前的狀態保存下來,這樣在中斷結束后,進程仍然可以從原來的狀態恢復運行。
跟進程上下文不同,中斷上下文切換並不涉及到進程的用戶態。所以,即便中斷過程打斷了一個正處在用戶態的進程,也不需要保存和恢復這個進程的虛擬內存、全局變量等用戶態資源。
中斷上下文,其實只包括內核態中斷服務程序執行所必需的狀態,包括 CPU 寄存器、內核堆棧、硬件中斷參數等。對同一個 CPU 來說,中斷處理比進程擁有更高的優先級,所以中斷上下文切換並不會與進程上下文切換同時發生。同樣道理,由於中斷會打斷正常進程的調度和執行,所以大部分中斷處理程序都短小精悍,以便盡可能快的執行結束。另外,跟進程上下文切換一樣,中斷上下文切換也需要消耗 CPU,切換次數過多也會耗費大量的 CPU,甚至嚴重降低系統的整體性能。所以,當你發現中斷次數過多時,就需要注意去排查它是否會給你的系統帶來嚴重的性能問題
怎么查看系統的上下文切換情況
使用 vmstat 這個工具,來查詢系統的上下文切換情況 ,主要關注以下幾項
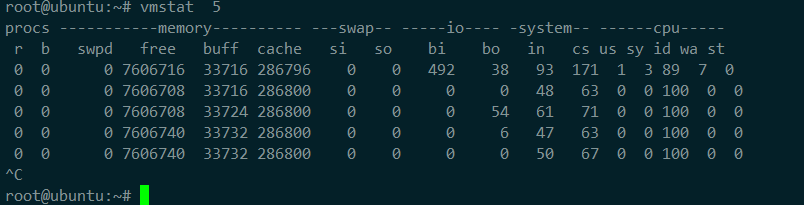
cs(context switch)是每秒上下文切換的次數。
in(interrupt)則是每秒中斷的次數。
r(Running or Runnable)是就緒隊列的長度,也就是正在運行和等待 CPU 的進程數。
b(Blocked)則是處於不可中斷睡眠狀態的進程數
另外
free 空閑的物理內存的大小
buff 設備和設備之間的緩沖
Linux/Unix系統是用來存儲,目錄里面有什么內容,權限等的``緩存
cache cpu和內存之間的緩沖
cache直接用來記憶我們打開的文件,給文件做緩沖,我本機大概占用300多M(這里是Linux/Unix的聰明之處,把空閑的物理內存的一部分拿來做文件和目錄的緩存,是為了提高 程序執行的性能,當程序使用內存時,buffer/cached會很快地被使用。)
si 每秒從磁盤讀入虛擬內存的大小,如果這個值大於0,表示物理內存不夠用或者內存泄露了,要查找耗內存進程解決掉。我的機器內存充裕,一切正常。
so 每秒虛擬內存寫入磁盤的大小,如果這個值大於0,同上。
bi 塊設備每秒接收的塊數量,這里的塊設備是指系統上所有的磁盤和其他塊設備,默認塊大小是1024byte
我本機上沒什么IO操作,所以一直是0,但是我曾在處理拷貝大量數據(2-3T)的機器上看過可以達到140000/s,磁盤寫入速度差不多140M每秒
bo 塊設備每秒發送的塊數量,例如我們讀取文件,bo就要大於0。bi和bo一般都要接近0,不然就是IO過於頻繁,需要調整。
us 用戶CPU時間
我曾經在一個做加密解密很頻繁的服務器上,可以看到us接近100,r運行隊列達到80(機器在做壓力測試,性能表現不佳)。
sy 系統CPU時間,如果太高,表示系統調用時間長,例如是IO操作頻繁。
id 空閑 CPU時間,一般來說,id + us + sy = 100,一般我認為id是空閑CPU使用率,us是用戶CPU使用率,sy是系統CPU使用率。
wa 等待IO CPU時間。
查看每個進程的詳細情況
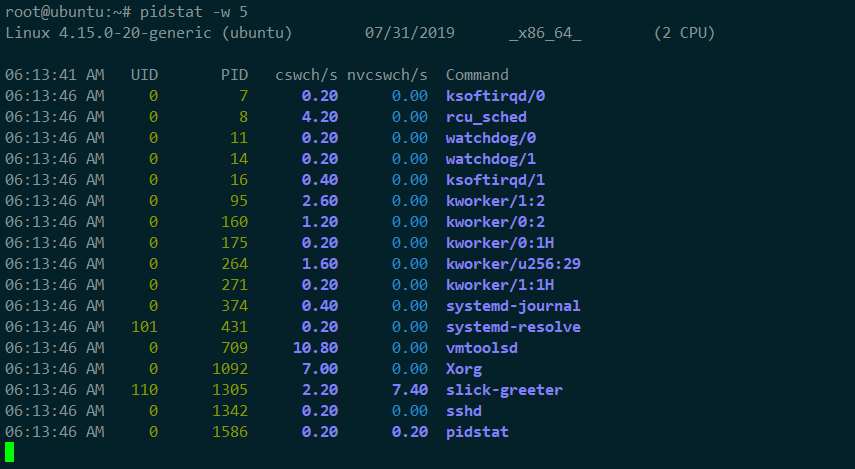
cswch ,表示每秒自願上下文切換(voluntary context switches)的次數,
nvcswch ,表示每秒非自願上下文切換(non voluntary context switches)的次數
所謂自願上下文切換,是指進程無法獲取所需資源,導致的上下文切換。比如說,
I/O、內存等系統資源不足時,就會發生自願上下文切換。
而非自願上下文切換,則是指進程由於時間片已到等原因,被系統強制調度,進而發生
的上下文切換。比如說,大量進程都在爭搶 CPU 時,就容易發生非自願上下文切換
案例分析
1,查看正常情況下的上下文切換情況

2,模擬多線程切換
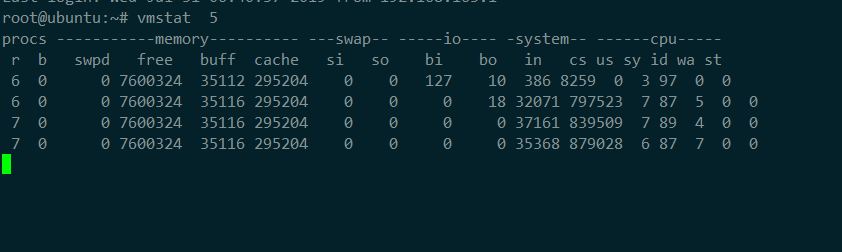
3,查看此時的上下文切換情況
4,使用pidstat查看上下文切換的情況
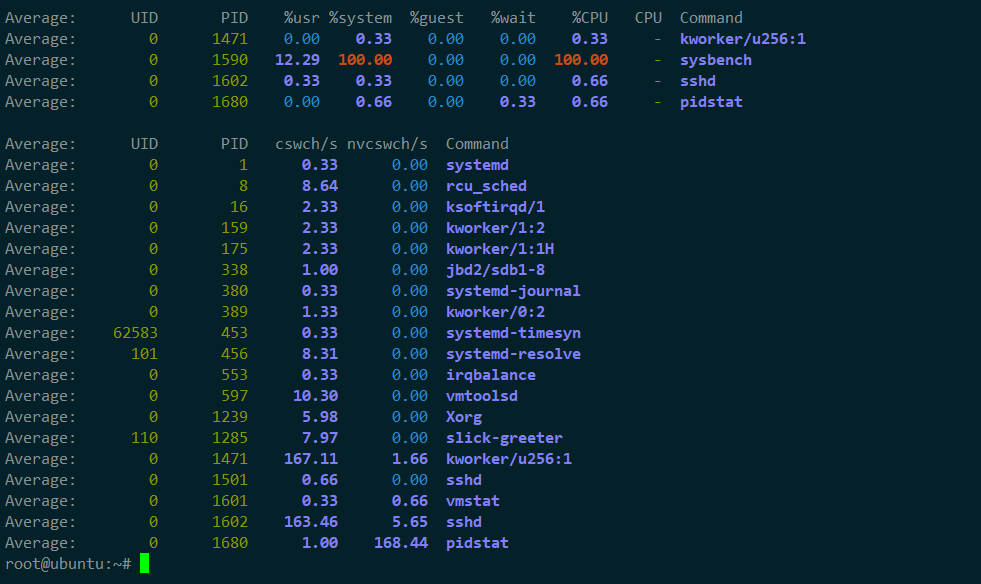
分析
1,發現cs列的上下文切換從66已經漲到了87萬多
R列:就緒隊列長度已經到了7,遠遠超過了cpu的個數2,所以會產生大量的cpu競爭
us和sy列:cpu使用率加起來已經到100%其中系統 CPU 使用率,也就是 sy 列高達 87%,說明 CPU 主要是被內核占用了
in 列:中斷次數也上升到了 3 萬左右,說明中斷處理也是個潛在的問題
綜合這幾個指標,可以知道,系統的就緒隊列過長,也就是正在運行和等待 CPU 的進程數過多,導致了大量的上下文切換,而上下文切換又導致了系統 CPU 的占用率升高
2,從 pidstat 的輸出你可以發現,CPU 使用率的升高果然是 sysbench 導致的,它的 CPU使用率已經達到了 100%。但上下文切換則是來自其他進程,包括非自願上下文切換頻率最高的 pidstat ,以及自願上下文切換頻率最高的內核線程 kworker 和 sshd
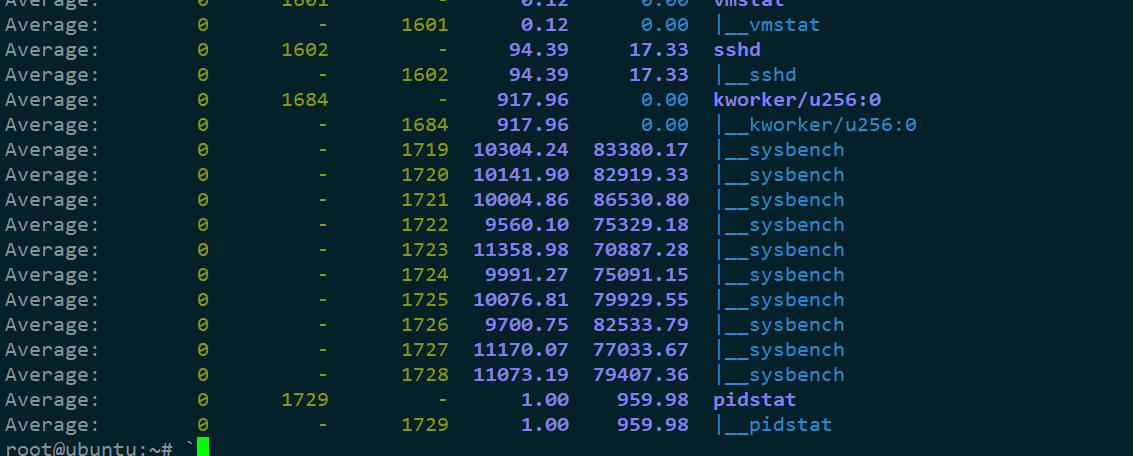
3,**使用-wt 參數表示輸出線程的上下文切換指標 **
雖然 sysbench 進程(也就是主線程)的上下文切換次數看起來並不多,但它的子線程的上下文切換次數卻有很多。看來,上下文切換罪魁禍首,還是過多的sysbench 線程
4,查看/proc/interrupts ,查看中斷使用情況
/proc 實際上是 Linux 的一個虛擬文件系統,用於內核空間與用戶空間之間的通信。/proc/interrupts 就是這種通信機制的一部分,提供了一個只讀的中斷使用情
watch -d cat /proc/interrupts
可以通過vmstat 、 pidstat 和 /proc/interrupts 等工具,來輔助排查性能問題的根源