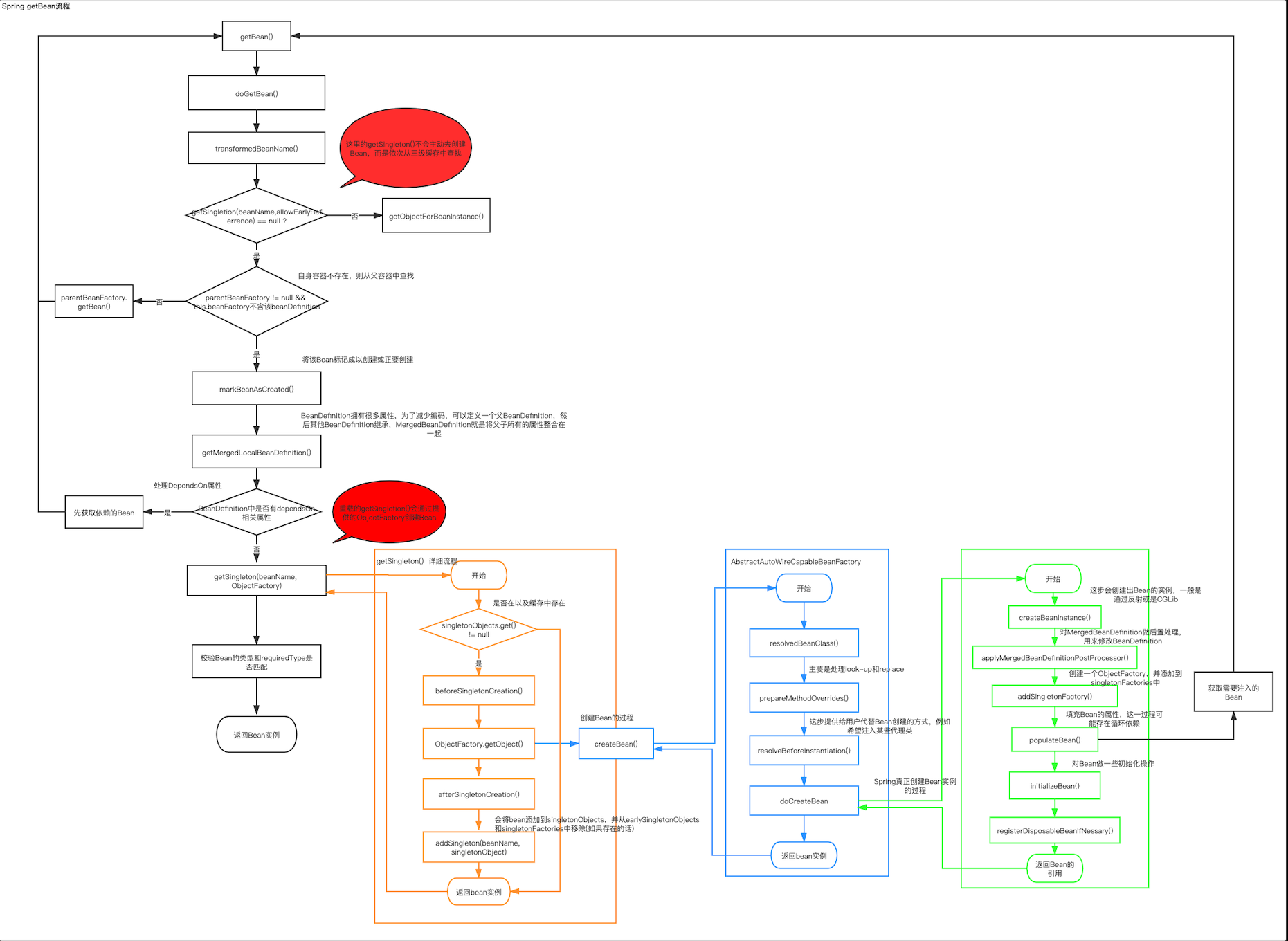
getBean流程介紹(以單例的Bean流程為准)
getBean(beanName)
從BeanFactory中獲取Bean的實例對象,真正獲取的邏輯由doGetBean實現。
doGetBean(beanName, requiredType, args, typeCheckOnly)
獲取Bean實例的邏輯。
1 transformedBeanName(beanName)——處理Bean的名字
transformedBeanName()對BeanName做一層轉換,這層轉換主要設計兩方面的處理,一是對BeanFactory的Name做一些處理(通常FactoryBean前面會增加一個&符號用來和BeanName區分,例如假設一個FactoryBean的name為&myFactoryBean,那么我們它創建的bean的name就為myFactoryBean),另一個是針對別名的處理。
2 getSingleton(beanName, allowEarlyReferrence)——從三級緩存中搜索
getSingletion()方法會先檢查BeanFactory.singletionObjects是否已經存在這個Bean的單例。
singletionObjects是BeanFactory內部的一個Map,存放已經是初始化完成的bean對象,其中key存放的是beanName,而value存放的是Bean實例。
如果singletionObjects中不存在但是該Bean是否正在創建中,則會嘗試從earlySingletionObjects中獲取。earlySingletionObjects也是一個map,存放的是已經創建出對象,但是還未設置屬性的bean。
如果在earlySingletonObjects中依舊找不到Bean對象,那么要繼續考慮通過ObjectFactory創建Bean對象的情況。
這里就引出了Spring中關於解決循環依賴問題的三級緩存。關於循環依賴的處理我們最后再分析。
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
3 getParentBeanFactory().getBean()——從父容器中獲取Bean
我們知道HierarchicalBeanFactory提供了BeanFactory父子容器的關系。子容器可以獲取父容器中的Bean。
當我們從子容器中的三級緩存中獲取不到Bean,且找不到該Bean的定義時,Spring會轉而去父容器中查找,如果父容器中依舊沒能找到,則說明該Bean不存在。如果父容器中存在,則從父容器中獲得Bean。
4 markBeanAsCreated(beanName)
這步只是對這個BeanName做個標記,表示這個BeanName對應的Bean已經被創建或是正在被創建。
5 getMergedLocalBeanDefinition(beanName)
BeanDefinition是Spring中對Bean的定義和描述,其中難免會有很多屬性和配置。在早起的xml時代,這些配置都需要人員編碼,因此Spring對BeanDefition做了一種繼承的機制,可以定義一個父定義,然后子類通過繼承獲得父定義中的屬性(當然也支持覆蓋父定義中的屬性)。有點類似先定義一個宏。
而這個方法就是將父子BeanDefition整合一下,得到一個MergedBeanDefition。
6 getDependsOn()——處理DependsOn
Bean可以通過DependsOn來顯示控制Bean的初始化順序(和依賴注入時的隱式初始化順序略有不同,顯示的DependsOn不用要求兩個Bean之間存在引用關系)。
Spring會優先創建DependsOn指定的Bean,這一過程中,也可能存在"循環依賴"的問題,但是這種情況下的"循環依賴"問題Spring是無法內部自己解決的(因為通常使用DependsOn,就是想強制讓否個Bean優先啟動)。
7 getSingleton(beanName, ObjectFactory)——獲取Bean實例
這是對getSingleton方法的重載,前文版本中的getSingleton方法只會從三級緩存中搜索Bean的實例,而這個重載方法會真正去創建Bean的實例。
在真正實例化對象前,依舊會先從singletonObjects檢查一次對象是否已經被創建,如果沒有,方法就上鎖,並進入實例化對象的流程。
7.1 beforeSingletonCreation(beanName)——創建前的處理
這步通常是做一些校驗,並把該Bean標記成正在創建。
7.2 singletonFactory.getObject()——通過ObjectFactory創建對象
具體的對象創建過程會調用AbstractAutoWireCapableBeanFactory.createBean(beanName, beanDefinition, args)方法。
7.2.1 resolvedClass()——解析bean類型
這步主要針對bean類型做解析。
7.2.2 preparedMethodOverrides()——overrideMethod的處理
這里的overrideMthod主要是針對bean中的look-up和replace等配置。有興趣的讀者可以自己展開了解。
7.2.3 resolveBeforeInstantiation()——在真正創建bean前,給用戶一次控制bean創建的過程
用戶可以通過InstantiationAwarePostProcessor.postProcessBeforeInstantiation(beanClass, beanName)方法先行創建出Bean對象。
InstantiationAwarePostProcessor接口繼承自BeanPostProcessor,主要是針對Bean的實例化前后階段設置了回調。
如果在這步中返回了Bean的實例,那么Spring不會再執行默認的創建策略。
這步留給用戶的拓展還是比較有用的,用戶可以根據該特性為某個Bean設置代理。
7.2.4 doCreateBean(beanName, mbd, args)——創建bean的過程
Bean的創建過程可以分成兩個步驟:
1).實例化Bean的對象
2).針對Bean實例做初始化
7.2.4.1 createBeanInstance()——創建bean實例
這個方法主要是對Bean實例的創建,創建方式順序是BeanDefition的Supplier>BeanDefinition的FactoryMethod>構造器反射創建。
7.2.4.2 applyMergedBeanDefinitionPostProcessors()
應用MergedBeanDefinitionPostProcessor,對MergedBeanDefinition做后處理。
7.2.4.3 addSingletonFactory(beanName, ObjectFactory)
將創建的Bean封裝到ObjectFactory中,然后添加到singletonFactories中(三級緩存)。
這樣在出現循環依賴的時候,可以從三級緩存中獲取到這個Bean的引用,雖然此時這個Bean還未完全准備好。
7.2.4.4 poplulateBean(beanName, mdb, instanceWrapper)
填充Bean的屬性。被創建出來的Bean對象會在這一步被設置屬性。
Spring會根據Bean的AutoWireType進行屬性的裝配。
注意裝配的過程中可能發生循環依賴。
7.2.4.5 initializeBean(beanName, exposedObject, mdb)——調用初始化方法
經過7.2.4.4 其實Bean對象已經創建的差不多了,之所以還需要在進行初始化是因為一些Bean可能指定了init方法,做一些特殊的初始化動作。這一步就是為了能夠執行這些邏輯。
7.2.4.6 registerDisposableBeanIfNecessary()
為Bean注冊銷毀時的回調。
7.3 afterSingletonCreation(beanName)——創建后的處理
同樣是做一些校驗,並且將bean從正在創建的狀態中移除。
7.4 addSingleton()——添加單例
這一步Spring會將創建好的Bean添加到singletonObjects中(一級緩存,用來存放已經創建好的bean),並從earlySingletonObjects和singletonFactories(二級緩存和三級緩存)中移除這個bean的引用。
8 校驗類型
在getSingleton()執行完成之后,已經得到了bean的對象,這一步主要是針對Bean類型校驗,看是否得到的實例是否是期望的類型,如果不是就對類型進行轉換。
轉換失敗,則拋出異常。
9 返回bean
將得到的Bean返回給調用者。完成獲取Bean的過程。
通過流程圖加深印象:
循環依賴
什么是循環依賴
循環依賴是Spring容器在初始化Bean時,發現兩個Bean互相依賴的一種特殊情況。
假設這么一種情況:
ComponentA和ComponentB為同一容器中的兩個bean,且他們裝配時都需要裝配對方的引用:
@Component
public class ComponentA {
@Autowired
ComponentB b;
}
@Component
public class ComponentB {
@Autowired
ComponentA a;
}
那么在創建ComponentA時,發現需要裝配ComponentB,轉而去創建ComponentB時,又發現需要裝配ComponentA。
那么是否會引起Spring創建Bean失敗呢?Spring是如何解決這種問題的?
Spring解決循環依賴的方式
為了解決這種問題,Spring引入了三級緩存,分別存放不同時期的Bean引用。
singletonObjects:一級緩存用來存放完全初始化完成的Bean。
earlySingletonObjects:二級緩存用來存放實例化,但初始化完成的Bean。
sngletonFactories:三級緩存用來存放ObjectFactory,ObjectFactory通常會持有已經實例化完成的Bean引用,並在getObject()時可能加工一下Bean,並返回Bean引用。
回到之前的問題:
- Spring在創建
ComponentA時,先實例化了ComponentA,並通過ObjectFactory持有着ComponentA的引用。在singletonFactories中(第三級緩存)添加緩存。 - 然后開始裝配
ComponentA,發現需要依賴ComponentB,由於ComponentB在三級緩存中都找不到,於是轉而開始創建ComponentB。 - 同樣實例化了
ComponentB,並在singletonFactories中添加緩存。 - 開始對
ComponentB進行裝配,發現又需要ComponentA,Spring第二次去getBean(ComponentA) - 這次由於第三級緩存中已經存在了
ComponentA的緩存,因此能夠取到ComponentA實例的引用。同時,由於此次的獲取,三級緩存的關系也發生了變化,第三級緩存singletonFacotries移除了關於ComponentA的引用,而是第二級緩存earlySingletonObjects會放入ComponentA的引用(因為此時已經通過ObjectFactory獲取過ComponentA的實例了)。 ComponentB得到了ComponentA的引用,完成了裝配。被添加到第一級緩存singletonObjects中,表示已經初始化完成,可以供其他Bean使用。- 回到第一個
getBean(ComponentA)的地方,因為已經能夠得到ComponentB的引用了,所以ComponentA也能被正常初始化完成。於是也被添加進了第一級緩存singletonObejcts中。
通過一個流程圖幫助讀者加深下印象:

無法解決的循環依賴的情形
上述循環依賴的情況是兩個Bean在通過屬性注入時產生的,而針對構造器注入的循環依賴Spring是無法解決的。
原因很簡單,Spring之所以能解決循環依賴是因為它將Bean的創建過程分成了實例化和初始化兩個階段。實例化完成后Spring就通過三級緩存允許其他Bean先獲取到該Bean的緩存。
而針對構造函數注入產生的循環依賴而言,由於在創建階段就依賴了其他Bean,因此無法先創建實例供其他Bean引用。
疑惑
最后拋出一個問題:為什么解決循環依賴需要三級緩存的設計,個人認為二級緩存也能夠解決循環依賴的問題,能否把第二級緩存和第三級緩存合並成一級?
其實是因為二級緩存最主要的一個用途是用作動態代理,如果一個對象需要被動態代理加工。那么當它從三級緩存取出,放入二級緩存的時候,這里的Bean實例會被動態代理包裝,返回的是代理類。從而保證后續的過程中,對外暴露的引用是經過代理的引用,實現動態代理的注入。