簡介
在商業應用中,時間是最重要的因素,能夠提升成功率。然而絕大多數公司很難跟上時間的腳步。但是隨着技術的發展,出現了很多有效的方法,能夠讓我們預測未來。不要擔心,本文並不會討論時間機器,討論的都是很實用的東西。
本文將要討論關於預測的方法。有一種預測是跟時間相關的,而這種處理與時間相關數據的方法叫做時間序列模型。這個模型能夠在與時間相關的數據中,尋到一些隱藏的信息來輔助決策。
當我們處理時序序列數據的時候,時間序列模型是非常有用的模型。大多數公司都是基於時間序列數據來分析第二年的銷售量,網站流量,競爭地位和更多的東西。然而很多人並不了解的時間序列分析這個領域。
所以,如果你不了解時間序列模型。這篇文章將會想你介紹時間序列模型的處理步驟以及它的相關技術。
本文包含的內容如下所示:
目錄
* 1、時間序列模型介紹
* 2、使用R語言來探索時間序列數據
* 3、介紹ARMA時間序列模型
* 4、ARIMA時間序列模型的框架與應用
讓我們開始吧
1、時間序列模型介紹
Let’s begin。本節包括平穩序列,隨機游走,Rho系數,Dickey Fuller檢驗平穩性。如果這些知識你都不知道,不用擔心-接下來這些概念本節都會進行詳細的介紹,我敢打賭你很喜歡我的介紹的。
平穩序列
判斷一個序列是不是平穩序列有三個評判標准:
1. 均值 ,是與時間t 無關的常數。下圖(左)滿足平穩序列的條件,下圖(右)很明顯具有時間依賴。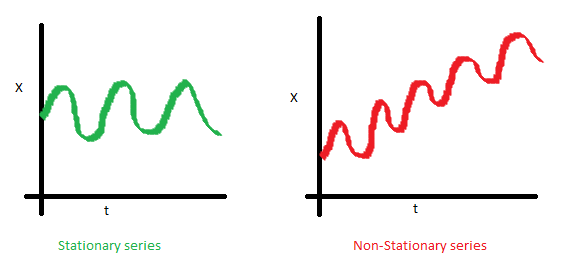
-
方差 ,是與時間t 無關的常數。這個特性叫做方差齊性。下圖顯示了什么是方差對齊,什么不是方差對齊。(注意右手邊途中的不同分布。)
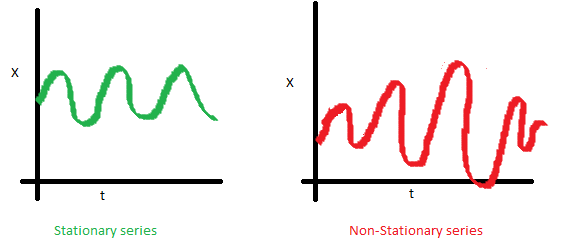
-
協方差 ,只與時期間隔k有關,與時間t 無關的常數。如下圖(右),可以注意到隨着時間的增加,曲線變得越來越近。因此紅色序列的協方差並不是恆定的。
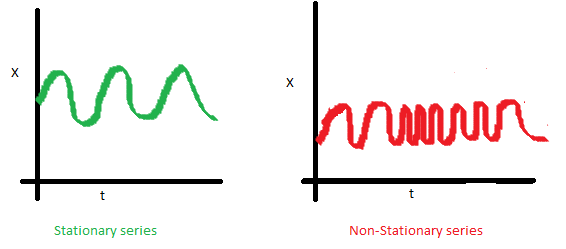
我們為什么要關心平穩時間序列呢?
除非你的時間序列是平穩的,否則不能建立一個時間序列模型。在很多案例中時間平穩條件常常是不滿足的,所以首先要做的就是讓時間序列變得平穩,然后嘗試使用隨機模型預測這個時間序列。有很多方法來平穩數據,比如消除長期趨勢,差分化。
隨機游走
這是時間序列最基本的概念。你可能很了解這個概念。但是,很多工業界的人仍然將隨機游走看做一個平穩序列。在這一節中,我會使用一些數學工具,幫助理解這個概念。我們先看一個例子
例子:想想一個女孩隨機的在想象一個女孩在一個巨型棋盤上面隨意移動。這里,下一個位置只取決於上一個位置。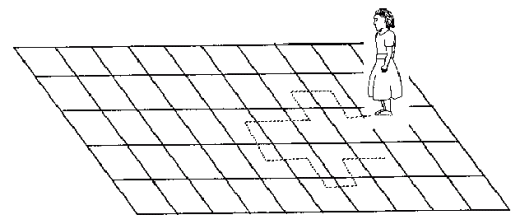
現在想象一下,你在一個封閉的房間里,不能看見這個女孩。但是你想要預測不同時刻這個女孩的位置。怎么才能預測的准一點?當然隨着時間的推移你預測的越來越不准。在t=0時刻,你肯定知道這個女孩在哪里。下一個時刻女孩移動到附件8塊方格中的一塊,這個時候,你預測到的可能性已經降為1/8。繼續往下繼續預測,現在我們將這個序列公式化:
|
1
2
|
$X(t) = X(t-1) + Er(t)$
這里的$Er_t$代表這這個時間點隨機干擾項。這個就是女孩在每一個時間點帶來的隨機性。
|
現在我們遞歸所有x時間點,最后我們將得到下面的等式:
|
1
|
$X(t) = X(0) + Sum(Er(1),Er(2),Er(3).....Er(t))$
|
現在,讓我們嘗試驗證一下隨機游走的平穩性假設:
1. 是否均值為常數?
|
1
|
E[X(t)] = E[X(0)] + Sum(E[Er(1)],E[Er(2)],E[Er(3)].....E[Er(t)])
|
我們知道由於隨機過程的隨機干擾項的期望值為0.到目前為止:E[X(t)] = E[X(0)] = 常數
2. 是否方差為常數?
|
1
2
|
Var[X(t)] = Var[X(0)] + Sum(Var[Er(1)],Var[Er(2)],Var[Er(3)].....Var[Er(t)])
Var[X(t)] = t * Var(Error) = 時間相關
|
因此,我們推斷,隨機游走不是一個平穩的過程,因為它有一個時變方差。此外,如果我們檢查的協方差,我們看到協方差依賴於時間。
我們看一個更有趣的東西
我們已經知道一個隨機游走是一個非平穩的過程。讓我們在方程中引入一個新的系數,看看我們是否能制定一個檢查平穩性的公式。
Rho系數
|
1
|
X(t) = Rho * X(t-1) + Er(t)
|
現在,我們將改變Rho看看我們可不可以讓這個序列變的平穩。這里我們只是看,並不進行平穩性檢驗。
讓我們從一個Rho=0的完全平穩序列開始。這里是時間序列的圖:
將Rho的值增加到0.5,我們將會得到如下圖: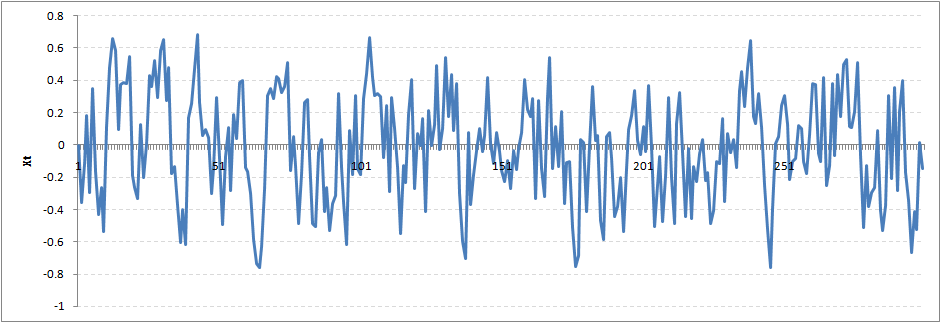
你可能會注意到,我們的周期變長了,但基本上似乎沒有一個嚴重的違反平穩性假設。現在讓我們采取更極端的情況下ρ= 0.9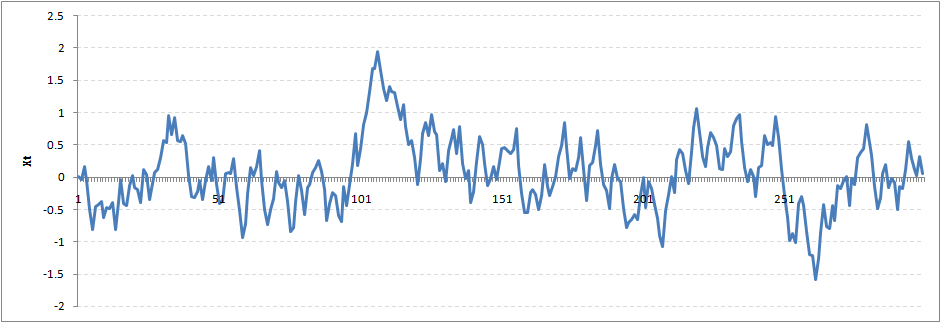
我們仍然看到,在一定的時間間隔后,從極端值返回到零。這一系列也不違反非平穩性明顯。現在,讓我們用ρ= 1隨機游走看看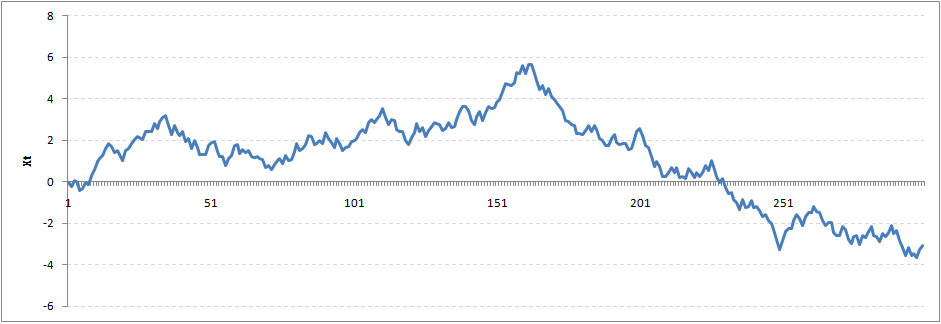
這顯然是違反固定條件。是什么使rho= 1變得這么特殊的呢?,這種情況並不滿足平穩性測試?我們來找找這個數學的原因
公式X(t) = Rho * X(t-1) + Er(t)的期望為:
|
1
|
E[X(t)] = Rho *E[ X(t-1)]
|
這個公式很有意義。下一個X(或者時間點t)被拉到Rho*上一個x的值。
例如,如果x(t–1)= 1,E[X(T)] = 0.5(Rho= 0.5)。現在,如果從零移動到任何方向下一步想要期望為0。唯一可以讓期望變得更大的就是錯誤率。當Rho變成1呢?下一步沒有任何可能下降。
Dickey Fuller Test平穩性
這里學習的最后一個知識點是Dickey Fuller檢驗。。在統計學里,Dickey-Fuller檢驗是測試一個自回歸模型是否存在單位根。這里根據上面Rho系數有一個調整,將公式轉換為Dickey-Fuller檢驗
|
1
2
|
X(t) = Rho * X(t-1) + Er(t)
=> X(t) - X(t-1) = (Rho - 1) X(t - 1) + Er(t)
|
我們要測試如果Rho–1=0是否差異顯著。如果零假設不成立,我們將得到一個平穩時間序列。
平穩性測試和將一個序列轉換為平穩性序列是時間序列模型中最重要的部分。因此需要記住本節提到的所有概念方便進入下一節。
接下來就看看時間序列的例子。
2、使用R探索時間序列
本節我們將學習如何使用R處理時間序列。這里我們只是探索時間序列,並不會建立時間序列模型。
本節使用的數據是R中的內置數據:AirPassengers。這個數據集是1949-1960年每個月國際航空的乘客數量的數據。
在入數據集
下面的代碼將幫助我們在入數據集並且能夠看到一些少量的數據集。

1 > data(AirPassengers)#在入數據 2 > class(AirPassengers) 3 [1] "ts" 4 #查看AirPassengers數據類型,這里是時間序列數據 5 > start(AirPassengers) 6 [1] 1949 1 7 #這個是Airpassengers數據開始的時間 8 > end(AirPassengers) 9 [1] 1960 12 10 #這個是Airpassengers數據結束的時間 11 > frequency(AirPassengers) 12 [1] 12 13 #時間序列的頻率是一年12個月 14 > summary(AirPassengers) 15 Min. 1st Qu. Median Mean 3rd Qu. Max. 16 104.0 180.0 265.5 280.3 360.5 622.0
矩陣中詳細數據
1 #The number of passengers are distributed across the spectrum 2 > plot(AirPassengers) 3 #繪制出時間序列 4 >abline(reg=lm(AirPassengers~time(AirPassengers))) 5 # 擬合一條直線
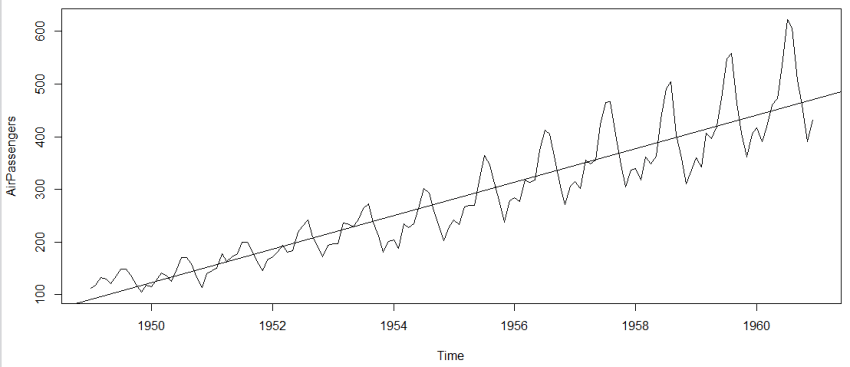
1 > cycle(AirPassengers) 2 Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec 3 1949 1 2 3 4 5 6 7 8 9 10 11 12 4 1950 1 2 3 4 5 6 7 8 9 10 11 12 5 1951 1 2 3 4 5 6 7 8 9 10 11 12 6 1952 1 2 3 4 5 6 7 8 9 10 11 12 7 1953 1 2 3 4 5 6 7 8 9 10 11 12 8 1954 1 2 3 4 5 6 7 8 9 10 11 12 9 1955 1 2 3 4 5 6 7 8 9 10 11 12 10 1956 1