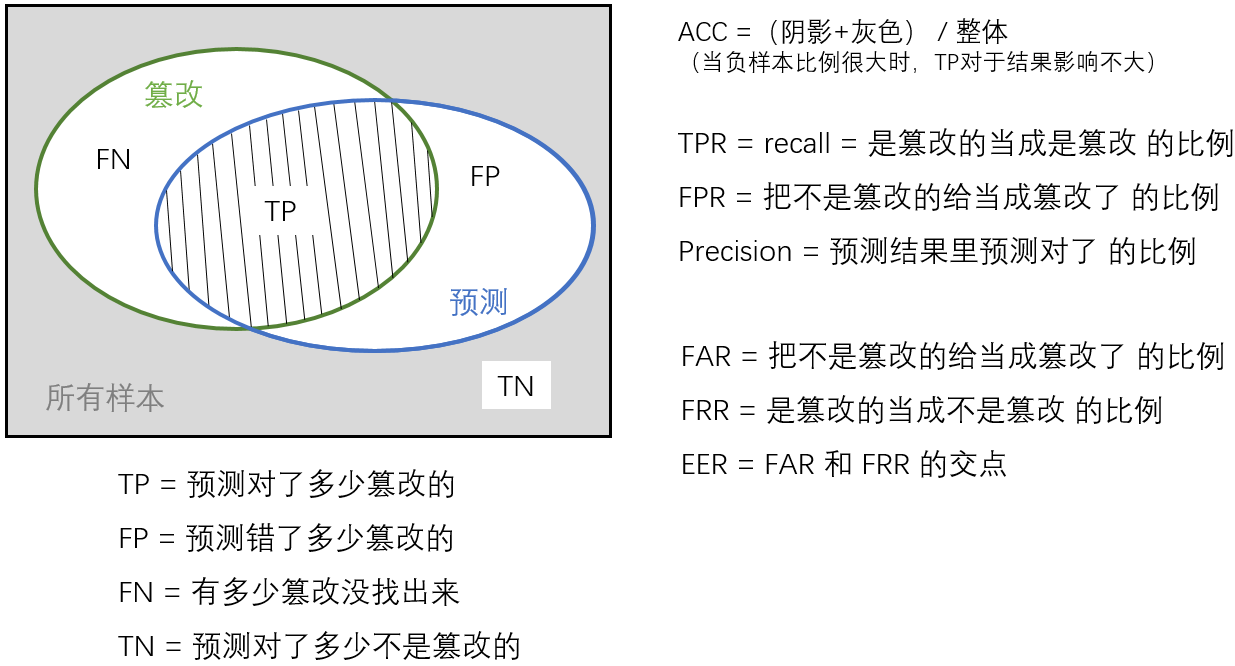
分類評估
對於一個二分類問題,分類結果如下
| 預測\實際 | 正例 | 反例 |
|---|---|---|
| 正例 | TP(真正例) | FP(假反例) |
| 反例 | FN(假正例) | TN(真反例) |
1. accuracy 准確率
意為 預測對的樣本數除以所有的樣本數。實際沒有用。
比如,正負樣本不均衡時,假設負樣本很少,即使所有樣本預測為正樣本,一個負樣本都沒有找出來,acc也很高。
2. TPR(recall)、FPR
TPR 真正例率 = recall 召回率 :預測正確的正例占所有預測的正例的比率
是針對原樣本而言的
FPR 假正例率:預測錯誤的正例占所有預測的反例的比率
3. precision
precision 精確度:預測的正例中實際的正例比率
是針對預測結果而言的
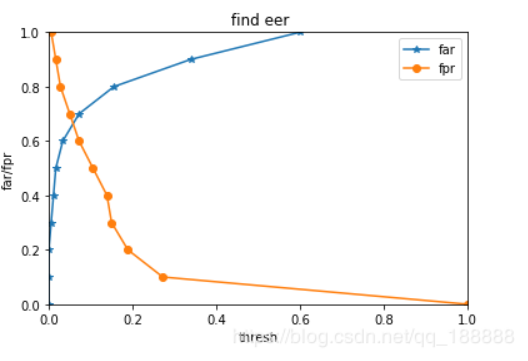
4. EER
FAR 錯誤接受率 不該接受的樣本里你接受的比例
FRR 錯誤拒絕率 不該拒絕的樣本里你拒絕的比例
EER (Equal Error Rate )等錯誤率 :取一組0到1之間的等差數列,分別作為識別模型的判別界限,畫出FFR和FAR的坐標圖,交點就是EER值(FAR與FRR相等的點)
用檢測篡改的思路看:
正樣本是篡改區域。在生成的一個通道的二進制結果上計算。(還有多通道情況)
用極端例子(下圖)解釋 ACC 不好用:
檢測篡改時會有總樣本量大而篡改圖像很少的情況,
假設陰影部分相同,負樣本比例很大時,用 ACC 公式並不能很好描述篡改檢測器的性能
5. f_score
理想狀態下追求 precision 和 recall 都高,但事實上這兩者在某些情況下是矛盾的。這樣就需要綜合考慮它們,F_score 是 precision 和 recall 的加權調和平均:
當\(\alpha\)<1時,代表精確率比召回率重要
當\(\alpha\)>1時,代表召回率比精確率重要
當\(\alpha\)=1時,代表精確率和召回率都很重要,權重相同。即F1_score,
由於 precision 和 recall 越大越好,所以,F1 值越大越好
6. ROC curve
ROC的全名叫做Receiver Operating Characteristic (受試者特征),是一個畫在平面上的曲線。
橫坐標是false positive rate(FPR),縱坐標是true positive rate(TPR)
當測試集中的正負樣本分布發生變化時,ROC曲線能夠保持不變,因此能進行客觀地分析

7. AUC
AUC:Aera Under Curve,即ROC曲線下的面積,值域為(0,1)
AUC是一個數值
從AUC判斷分類器的標准
- AUC=1,是完美分類器,通常不存在完美分類器
- 0.5<AUC<1,優於隨機猜測
- AUC=0.5,跟隨機猜測一樣,相當於拋硬幣
- AUC<0.5,比隨機猜測還差,但如果反預測而行,就優於隨機猜測

AUC值越大,對應的分類器的性能越好
舉個栗子
假設有一個二分類模型,對 30 個樣本分類,輸出概率 p ,當 p>0.5 時,預測的標簽為1(真)

根據結果,得到混淆矩陣
| 預測 \ 實際 | 正例 | 反例 |
|---|---|---|
| 正例 | 13 | 6 |
| 反例 | 6 | 5 |
把預測概率從大到小排序
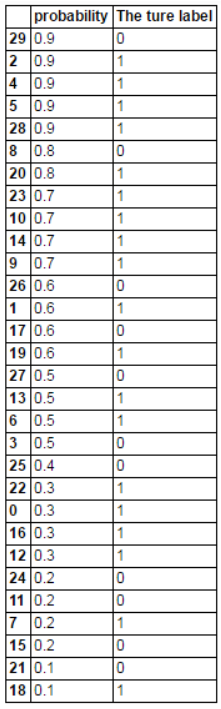
從上到下,依次計算 TPR 和 FPR
比如 4 號,p=0.9,在他之前的結果中,1個FP,2個TP,故TPR=2/(13+6)=0.11,FPR=2/(6+5)=0.09
比如26號,p=0.6,在他之前的結果中,3個FP,9個TP,故TPR=9/(13+6)=0.47,FPR=3/(5+6)=0.27
以此類推,得到(TPR,FPR)矩陣
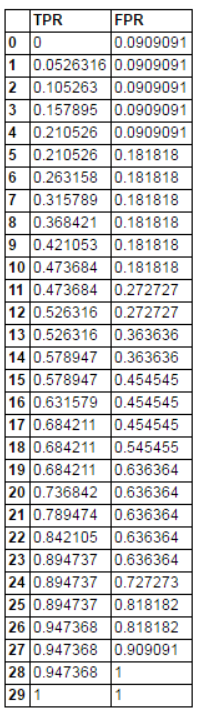
畫 ROC 曲線
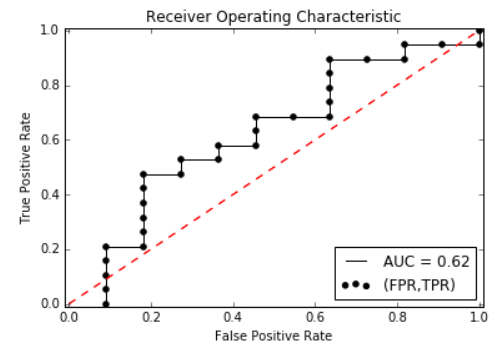
測試樣本數量越多,曲線越光滑
黑色曲線下的面積即為 AUC
5. MCC
馬修斯相關系數(Matthews correlation coefficient)
MCC本質上是一個描述實際分類與預測分類之間的相關系數
它的取值范圍為[-1,1]
取值為1時表示對受試對象的完美預測
取值為0時表示預測的結果還不如隨機預測的結果
取值-1是指預測分類和實際分類完全不一致
MCC衡量不平衡數據集的指標比較好
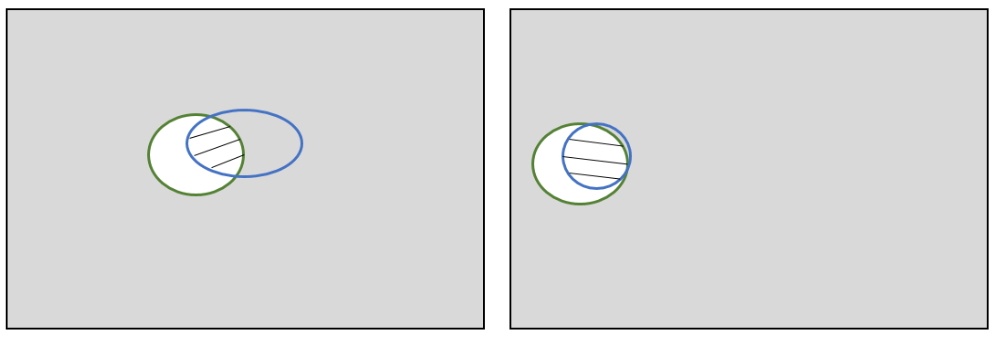
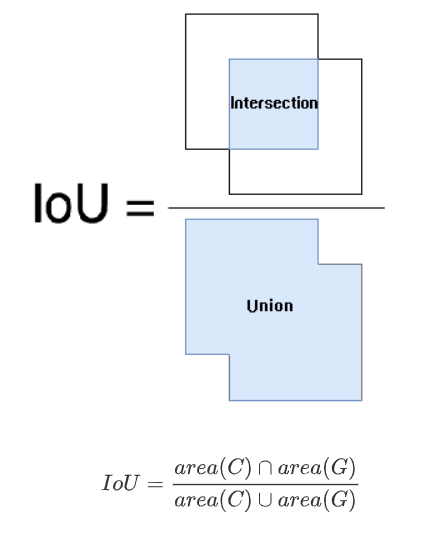
IoU
交並比 Intersection over Union ,是目標檢測中的一個概念。
IOU表示產生的候選框(candidate bound)與原標記框(ground truth bound)兩者的交集與並集的比值。
用上面那個圖看是:陰影 / ( 陰影 + 白色 )
IoU 值越大越好
NMM
nimble mask metric
參考鏈接
https://www.plob.org/article/12476.html
https://blog.csdn.net/u014061630/article/details/82818112
https://blog.csdn.net/qq_18888869/article/details/84942224
[ROC]https://zhuanlan.zhihu.com/p/25212301