Introduction
在transformer model出現之前,主流的sequence transduction model是基於循環或者卷積神經網絡,表現最好的模型也是用attention mechanism連接基於循環神經網絡的encoder和decoder.
Transformer model是一種摒棄了循環及卷積結構,僅僅依賴於注意力機制的簡潔的神經網絡模型。我們知道recurrent network是一種sequential model,不能很好地解決長距離依賴的問題(序列過長時,信息在序列模型中傳遞時容易一點點丟失),並且阻礙了parallelism within train example.而transform最引人矚目的一點正是很好地解決了長距離依賴的問題,通過引入自注意力機制(self-attention)使得對依賴的建模與輸入輸出序列的距離無關,並且支持train exmaple內部的並行化。注意力機制可以參考之前寫的notes of cs224n lecture8.
Model Architecture
下圖1是transformer的模型架構圖
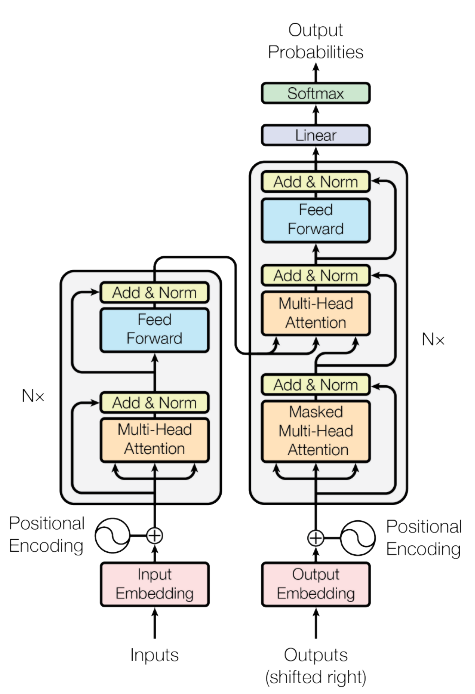
Attention
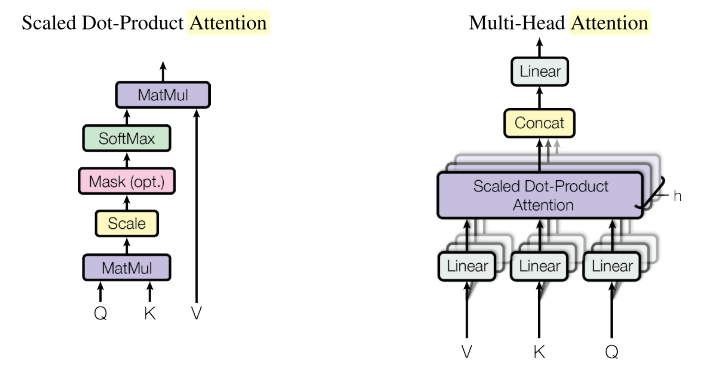
Scaled Dot-Producted Attention
如上圖2左邊所示即為dot-producted attention的一般形式,在transformer中,初始Q, K, V即為一個句子所有的subword編碼構成的矩陣(seq_len, d_model),其中d_model是subword的編碼長度。Deocder的第二個Multi-Head Attention中的Q, K, V會有所不同,在講解Multi-Head Attention是提到。下面是dot-producted attention的數學表達形式
這里除以\(\sqrt{d_k}\)是因為在與additive attention(之前寫的文章有提到)對比時發現\(d_k\)較小時,這兩種注意力機制表現相似,但是當\(d_k\)較大時dot-producted attention不如additive attention。最后分析原因發現\(d_k\)較大時\(QK^T\)點乘結果矩陣元素在數量級很大,使得softmax函數求導的梯度非常小。下面是原論文的一個解釋
To illustrate why the dot products get large, assume that the components of q and k are independent random variables with mean 0 and variance 1. Then their dot product, \(q \cdot d=\sum_{i=1}^{d_k}{q_{i}k_{i}}\), has mean 0 and variance dk.
Multi-Head Attention
如上圖2右邊所示即為Multi-Head Attention的結構圖。它的中心思想就是將原來的\((Q, K, V)\)轉換成num_heads個shape為(seq_len, d_model/num_heads)的\((Q_i, K_i, V_i)\),然后再為每個head執行dot-producted attention的操作,最后再將所有head的輸出在最后一個維度上進行拼接得到與對原始輸入\((Q, K, V)\)執行單個dot-producted attention操作后shape一致的結果。下面是Multi-Attention的數學表達形式
其中,\(W^{Q}_{i} \in \mathbb{R}^{d_{model} \times d_k}, W^{K}_{i} \in \mathbb{R}^{d_{model} \times d_k}, W^{V}_{i} \in \mathbb{R}^{d_{model} \times d_k}\),而\(W^{O}_{i} \in \mathbb{R}^{hd_{v} \times d_{model}}\)
在transformer中使用h=8個parallel attention heads.對於每個head使用\(d_k=d_v=d_{model}/h=64\). 我看tf official tutorial of transformer實現中並沒有為每個head學習轉換矩陣\(W^{Q}_{i},W^{K}_{i},W^{V}_{i}\),而是直接對\(d_{model}\)的編碼表示進行划分成h份,然后輸入到各自的head中進行處理。Multi-Head Attention機制允許模型在不同位置共同關注來自不同表示子空間的信息。
Decoder中包含兩層的Multi-Head Attention(MHA),第二層的MHA不再使用初始的\((Q, K, V)\)作為輸入,而是使用上一層MHA的輸出作為\(Q\),Encoder最后一層(第6層)的輸出作為\(K, V\).
Masking
無論encoder還是decoder都需要使用mask屏蔽掉不必要的信息干擾。
對於encoder,由於我們傳入的數據是padded batch,因此需要對padded的信息進行mask,具體mask的位置放置在dot-producted attention的scale即\(\frac{Qk^T}{\sqrt{d_k}}\)之后softmax之前,對需要mask的位置賦值為1e-9,這樣在softmax之后需要mask的位置就變成了0,就像是指定mask的位置進行dropout.
對於decoder,每一層包含兩個Multi-Head Attention(MHA),第一個MHA同樣需要對padded信息進行mask,除此之外還要對output中還未出現的詞進行mask,保證只能根據前面出現的詞信息來預測后面還未出現的詞。將兩個mask矩陣疊加之后輸入到dot-producted attention單元中的scale之后用於屏蔽非必要信息。第二個MHA由於使用Encoder最后一層的輸出作為\(K, V\),所以需要對Encoder初始輸入的padded信息進行mask,同樣是在dot-producted attention單元中的scale之后操作。
Embeddings
encoder和decoder的輸入是兩套獨立的embedding(例如translation task,分別是原語和目標語subword的Embeddings),embedding的維度為\(d_{model}\),論文中的base model設為512,big model設為1024.在embedding輸入模型前逐元素乘以\(\sqrt{d_{model}}\),因為在dot-producted attention中 \(\frac{QK^T}{\sqrt{d_{model}}}\).
Positional Encoding
由於transform model不包含循環和卷積網絡,為了使模型能利用sequence的順序信息,必須加入序列中每個subword的相對或者絕對位置信息。因此引入了Positional Encoding,它保持和embedding一樣維度\(d_{model}\),具體encoding的方式有很多種,主要分為學習的和固定的(learned and fixed)。在論文中使用了固定的無須學習的positional embedding,使用不同頻率的cos和sin函數如下
其中,pos是token position in sequence,i是dimension position.之所以選擇cos和sin函數是因為對於固定的偏置量\(k,PE_{pos+k}\)能夠表示為\(PE_{pos}\)的線性函數,假設它可以很容易學習到相對位置引入的信息。使用cos和sin的另一個原因是它允許模型推斷比訓練過程中遇到的更長的序列。論文中作者表示也使用了learned positional embeddings,但是與上述的fixed positional embeddings結果基本一致,所以最終采用了fixed positional embedings,這種方式更高效,減少訓練開銷。
最終作為模型輸入的是token embeddings + positional embeddings,然后套一層dropout.
Why Self-Attention

如上圖所示,使用self-attention機制主要有三點原因
- 相比convolutional和recurrent,當sequence length n比representation dimensionality d更小時(SOTA的機器翻譯模型都符合),每一層的計算開銷都更少
- self-attention相比recurrent和convolutional更適合並行化,可並行化的粒度更小(measured by the minimum sequential operations required)
- 最重要的一點self-attention解決了長距離依賴(long -range denpendency)的問題。對於sequence transduction task,影響這種依賴的關鍵因素就是前向或者后向信號要在網絡中遍歷的路徑長度。而self-attention的Q(query)直接與K(key),V(value)中每個token直接產生聯系,無須信號序列式傳遞,所以如上圖中self-attention的sequential operations和maximum path length常數級別的。
由於self-attention的complexity per layer為\(O(n^2 \cdot d)\),考慮非常長序列的極限情況,可以限制self-attention在計算時只考慮輸入序列K,V中的r個鄰居即可將complexity per layer限制在\(O(r \cdot n \cdot d)\),這就是上圖2中的Self-Attention(restricted).
Training
Dataset
WMT 2014 English-German datasset和WMT 2014 English-French dataset,數據集官網download,論文使用其中的newstest2013作為驗證集(development dataset),newstest2014作為測試集(test dataset)。base model平均最后5個checkpoint的結果,big model平均最后20個checkpoint的結果。由於數據集太過龐大,訓練代價很大。論文中使用8 NVIDIA P100 GPUs,base model訓練100000 steps耗時12h,big model訓練300000 steps耗時3.5 days.
Regularization
論文中主要使用了兩種正則化手段來避免過擬合並加速訓練過程。
Residual Dropout
在每一residual Multi-Head Attention之后,Add&Norm之前進行dropout,以及add(token embedding,positional encoding)之后進行dropout,FFN中沒有dropout,base model的dropout rate統一設置為0.1,big model在wmt14 en-fr數據集上設置為0.1,在en-de數據集上設置為0.3
Label Smothing
Label Smothing Regularization(LSR)是2015年發表在CoRR的paper:Rethinking the inception architecture for computer vision中的一個idea,這個idea簡單又實用。假設數據樣本x的針對label條件概率的真實分布為
這使得模型對自己給出的預測太過自信,容易導致過擬合並且自適應能力差(easy cause overfit and hard to adapt)。解決方案:給label分布加入平滑分布\(u(k)\),一般取均勻分布\(u(k)=\frac{1}{k}\)就好,於是得到
映射到損失函數cross entropy有
由上式可知,LSR使得不僅要最小化原來的交叉熵H(q,p),還要考慮預測分布\(p\)與\(u(k)\)之間差異最小化,使得模型預測泛化能力更好。transformer的論文中指定\(\epsilon_{ls}=0.1\)。下表是使用LSR和未使用LSR在tensorflow datasets的ted_hrlr_translate/pt_to_en dataset上bleu score對比
可以看到使用了LSR在驗證集和測試集上都取得了比更好的bleu score.但是LSR對perplexity不利,因為模型的學習目標變得更不確切了。
LayerNormalization
在multi-head attention之后使用layer normlization可以加速參數訓練使得模型收斂,並且可以避免梯度消失和梯度爆炸。相比BatchNormalization,LayerNormalization更適用於序列化模型比如RNN等,而BatchNormalization則適用於CNN處理圖像。
Learning Rate with Warmup
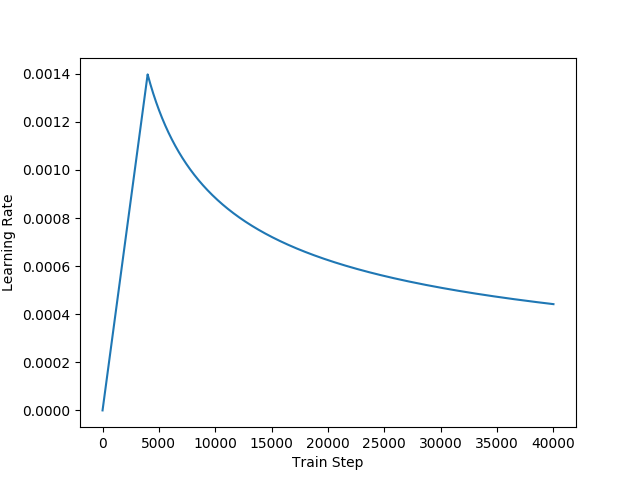
Transformer使用Adam optimizer with \(\beta_{1}=0.9,\beta_{2}=0.98,\epsilon=10^{-9}\).學習率在訓練過程中會變動,先有一個預熱,學習率呈線性增長,然后呈冪函數遞減如上圖所示,下面是學習率的計算公式
論文中設置warmup_steps=4000.也就是說訓練的前4000步線性增長,4000步后面呈冪函數遞減。這么做可以加速模型訓練收斂,先以上升的較大的學習率讓模型快速落入一個局部收斂較優的狀態,然后以較小的學習率微調參數慢慢逼近更優的狀態以避免震盪。
Conclusion
Transformer是NLP在深度學習發展歷程上的一座里程碑,目前主流的預訓練語言模型都是基於transformer的,逐漸取代了LSTM的位置,深入理解transformer的細節對后續NLP的學習非常重要。
Transformer最大的亮點在於不依靠RNN和CNN,通過引入self-attention機制,很好地解決了讓人頭疼的長距離依賴問題,使得輸入和輸出直接關聯,沒有了RNN那樣的序列傳遞信息損失,輸入輸出之間經過的的路徑長為常數級,與輸入序列長度無關,上下文信息保留更完整。因此tranformer是非常強大的文本生成模型,應用於MT, 成分句法分析(constituency parsing)等效果非常好。