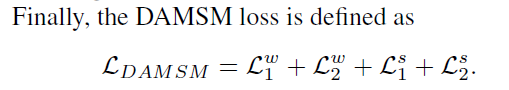AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks 筆記
這篇文章的任務是 “根據文本描述” 生成圖像。以往的常規做法是將整個句子編碼為condition向量,與隨機采樣的高斯噪音\(z\)進行拼接,經過卷積神經網絡(GAN,變分自編碼等)來上采樣生成圖像。這篇文章發現的問題是:僅通過編碼整個句子去生成圖像會忽略掉一些細粒度的信息,而這些細粒度的信息是由單詞層面來決定的(例如顏色、形狀等)。
解決的方法是在生成過程中引入對單詞的注意力機制,這種注意力機制需要把相關的單詞與對應的圖像區域匹配起來, 如果讓我自己去設計這種匹配關系,我的第一反應是要先進行大量的人工標注(根據單詞先人工框出來圖像中對應的區域),這樣搞的話光標注就需要巨大的人力與時間(特別是在COCO這么大的數據集上。。。)。
AttnGAN沒有對數據集進行額外的標注, 利用生成過程中的 \(C \times N \times N\) feature map ,有 \(N^{2}\) 個位置。每一位置的向量維度是 \(C\),為了表示某一位置與句子中某一單詞的相關性,可以根據 某一位置向量與單詞向量的內積 / 某一位置向量與句子中所有單詞向量內積之和 來得到與某一單詞的權重(相關)系數,那么在某一位置上的單詞表征可以表示為所有單詞向量的加權和。

方法

模型包含兩個部分,
- 注意力生成網絡
- 多模態注意力相似模型(DAMSM,是個匹配網絡)
注意力生成網絡包含多個階段的生成(這里是三次生成,只要計算資源足,還可以加), coarse-to-fine的圖像生成模式。 DAMSM需要在真實的數據對上預訓練,相當於給生成網絡加了一個監督信息,使生成的圖像能像真實圖像那樣與相應的文本匹配。
Attentional Generative Network(注意力生成網絡)
輸入文本,經過Text Encoder(用的是雙向LSTM)編碼輸出“整句特征”(global sentence vector)\(\bar{e}\) 和拼接起來的“單詞特征” \(e \in \mathbb{R}^{D \times T}\)。 \(\bar{e}\) 經過 Conditioning Augmentation(具體可以看stackgan和vae的文章,目的是為了降維以及增加多樣性) 進行降維轉換來作為條件向量,用 \(F^{ca}\) 來表示Conditioning Augmentation操作。
第一次的image features的生成過程為:
從圖中可以看出\(F_{0}\)代表着一系列的上采樣操作,但還沒有生成最后的圖像,輸出了一個隱含特征\(h_{0}\)。這個隱含特征已經初具圖像的位置和物體信息。后面的生成過程為:
這里面最重要的就是\(F_{i}^{attn}\)的操作,也是作者所提出的創新點,即如何將單詞信息融入到生成的過程中去,而且不同單詞對於圖像中不同區域的attention作用也是不同的。先來看看\(F^{attn}_{i}\)的操作,輸入是單詞向量矩陣 \(e\) 以及前一階段所得到的image features \(h_{i-1}\)(\(h \in \mathbb{R}^{\hat{D} \times N}\))。單詞向量要經過一次乘積轉換(可以加個全連接層)來改變維度到\(\hat{D}\)維,\(e^{'}=Ue\) where \(U\in\mathbb{R}^{\hat{D}\times D}\),與image features的維度保持一致, 有助於后面進行內積操作計算相似性。 \(h\) 中的每一列其實都代表着圖像的一個sub-region,其中\(N=\sqrt{N}\times \sqrt{N}\)。對於第 \(j\) 個sub-region,用句子中所有的單詞向量來進行表示,那么相關的單詞向量應具有更大的權重,不相關的單詞向量與其的相關權重應很小,每個sub-region進行單詞向量加權和的結果稱為“word-context”(相當於加入了具有側重點的文本condition)。每一個sub-region與所有的單詞向量權重計算以及最后的word-context計算過程為
\(s^{'}_{j,i}=h^{T}_{j}e^{'}_{i}\), \(\beta_{j,i}\)表示當生成圖像第\(j\)個子區域時,第\(i\)個單詞所獲得的關注程度。\(c_{j}\)代表着第\(j\)個子區域的word-context向量,\(F^{attn}\)就是為了生成所有子區域的word-context向量:\(F^{attn}(e,h)=(c_{0},c_{1},\ldots,c_{N-1})\in \mathbb{R}^{\hat{D}\times N}\)。
圖像的生成是根據Image features \(h_{i}\)
在注意力生成網絡里的損失也就是常規的conditionGAN損失的變種(包含帶有文本條件與不帶有條件):
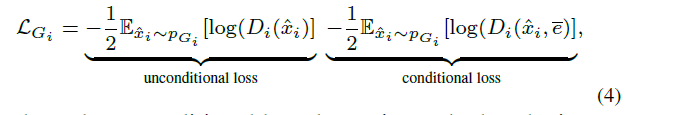
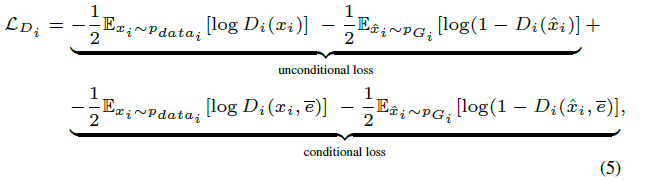
Deep Attentional Multimodal Similarity Model(匹配模型)
這一部分的提出相當於額外加了一個文本-圖像匹配的監督信息,由於DAMSM是在真實數據集上預訓練好的(即真實圖像與相關的文本匹配損失會比較小),在輸入生成的圖像與相關的文本信息時,它會倒逼着注意力生成網絡生成更加真實且與文本相關的圖像。在這一模型中,從兩個部分來計算匹配損失,分別是基於整個句子的和基於逐個單詞的。
圖像編碼器(image encode)將圖像下采樣到feature matrix \(f\in \mathbb{R}^{768\times 289}\)(這是從\(768\times 17\times 17\) reshape 過來的),為了度量圖像與文本的相似性,文本與圖像的特征維度應保持一致,在這里,是將圖像的特征進行轉換與單詞向量的維度保持一致:
\(v\)是圖像特征轉換過之后的特征\(v\in \mathbb{R}^{D\times 289}\),\(\bar{v}\in \mathbb{R}^{D}\)表示圖像的全局向量,\(\bar{f}\)是從Inception-v3網絡的最后一層(全連接分類層)提取出來的,作為全局特征。
經過維度統一之后,下面的單詞層面的匹配操作類似於attention生成過程中的word-context計算過程,只不過這里是針對每個單詞計算出相應的sub-region的加權和,也就是說每個單詞都有個視覺信息的加權表征。計算過程如下:
\(s\in \mathbb{R}^{T\times 289}\),表示單詞與sub-region的內積來度量相似性。這里搞了一個歸一化,說是能提升效果
也就是針對同一個sub-region,所有單詞相似性的歸一化。
針對每一個單詞所有的sub-region視覺信息加權和稱為“region-context”向量,記作\(c_{i}\),計算過程為
\(\gamma_{1}\)表示對於相關的sub-regions擴大它的影響(相似性值越大的占的比重更大)。這樣每一個單詞都有一個對應的region-context視覺信息,可以進行單詞-視覺信息相關的匹配度量,這里用余弦距離來衡量差異
基於單詞層面來衡量整個圖像與文本的相似性
之所以用這個形式,是為了突出最相關的word-to-region-context pair,用\(\gamma_{2}\)來調節突出程度,當\(\gamma_{2} \rightarrow \infty\) 時,上式結果
趨近於\(\max_{i=1}^{T-1}R(c_{i},e_{i})\)。
DAMSM的監督標簽是"圖片與整個句子是否匹配"。用圖片去匹配句子,目標函數的后驗概率形式為
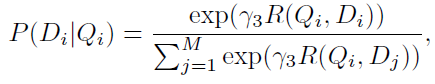
\(Q\)表示圖像,\(D\)表示句子
基於單詞水平的匹配損失函數為:
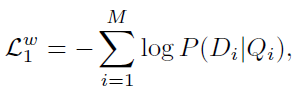
對應的,在以句子匹配圖像的情況下,損失函數為
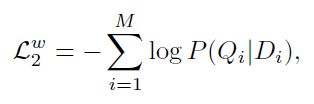
另外,基於整個句子的匹配損失設計與上面的類似,不同點是直接用全局向量計算相似距離。